产品研发链路里,最容易消耗时间的环节往往不是写代码本身,而是把业务诉求翻译成研发能执行的材料。
一个需求从提出到落地,通常会经历几层转换:
flowchart LR
A[业务诉求] --> B[MRD 市场需求文档]
B --> C[PRD 产品需求文档]
C --> D[系统分析文档]
D --> E[接口设计 / 数据模型 / 模块拆分]
E --> F[代码骨架]
MRD(Market Requirements Document,市场需求文档)偏业务和市场视角,描述为什么要做、目标用户是谁、业务价值在哪里。PRD(Product Requirements Document,产品需求文档)需要进一步落到产品功能、页面交互、流程规则和验收标准。系统分析文档则继续把 PRD 拆成研发视角的模块、接口、数据表、状态流转和异常处理。
传统方式下,这些转换大量依赖人工理解和人工整理,常见问题包括:
| 问题 | 具体表现 | 影响 |
|---|---|---|
| 理解偏差 | 产品、研发、测试对同一句需求有不同理解 | 后续反复沟通、返工 |
| 文档不统一 | 不同人写出的 PRD 或系分结构差异大 | 评审成本高,信息容易遗漏 |
| 重复劳动多 | 背景、目标、流程图、接口草案经常重复整理 | 占用产品和研发时间 |
| 上下文不足 | 新需求没有自动关联历史 PRD、业务百科、产品资料 | 容易漏掉已有规则和边界条件 |
| 交付断层 | PRD 写完后,系统分析和代码骨架仍需重新拆解 | 需求到研发之间存在额外转换成本 |
大模型适合介入的不是“替人拍板需求”,而是把大量结构化、半结构化的分析工作自动化:提取重点、补全文档结构、检索历史知识、生成流程图、拆分模块、产出接口和代码骨架。人仍然负责判断业务目标、确认边界和审核结果,但不必把时间都花在模板填充和重复整理上。
端到端目标:从业务诉求直接推进到研发材料
一个可落地的智能化研发链路,需要覆盖“业务诉求 → 需求 → 研发”三个阶段,而不是只做一个孤立的文档生成器。
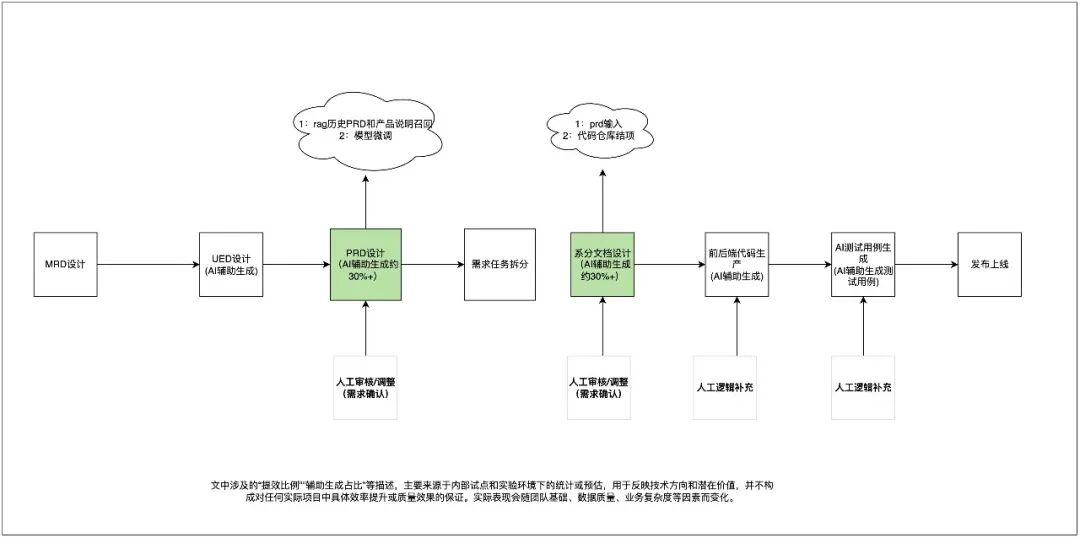
这条链路的关键目标是:让业务输入能够被逐层加工成研发可执行材料。业务侧可以输入自然语言描述、MRD、流程说明、截图或其他附件;需求侧生成 PRD、流程图、功能清单和验收规则;研发侧继续生成系统分析文档、接口草案、数据结构和后端代码骨架。
抽象后可以分成四类能力:
| 能力 | 输入 | 输出 | 价值 |
|---|---|---|---|
| 需求理解 | 自然语言、MRD、附件 | 需求背景、目标、用户场景、约束条件 | 把分散信息整理成结构化需求 |
| PRD 生成 | 需求大纲、历史资料、业务知识 | 标准化 PRD、流程图、功能说明 | 减少产品文档编写成本 |
| 系统分析 | PRD、领域知识、技术规范 | 模块拆分、接口、数据表、数据流 | 降低产品到研发的转换成本 |
| 代码骨架 | 系统分析结果、项目模板 | Controller、Service、DAO、DTO、Entity 等 | 帮研发快速进入业务实现 |
这里的重点不是让大模型一次性输出最终答案,而是通过多个 Agent 分工协作,把复杂任务拆成可检查、可迭代的小任务。
整体架构:RAG、PRD Agent 和系分 Agent 协同工作
完整方案可以分成三层:知识增强层、需求生成层、研发转化层。
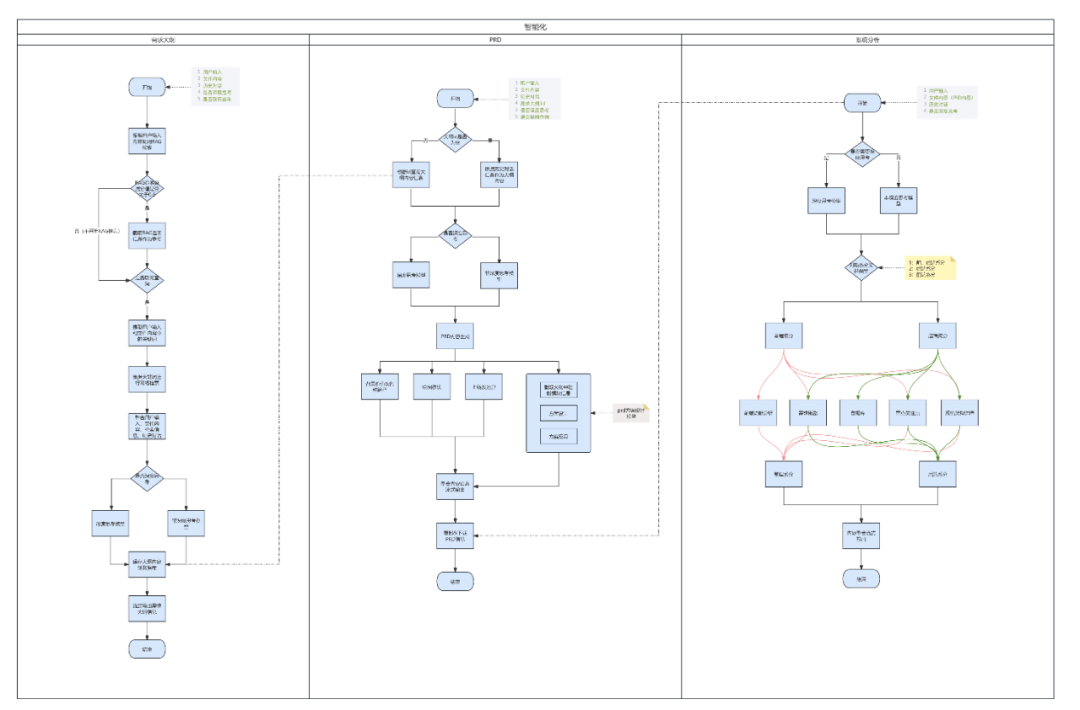
图中的流程可以理解为一个流水线:用户输入进入系统后,先通过 RAG(Retrieval-Augmented Generation,检索增强生成)补充业务上下文,再由多个 PRD Agent 生成产品需求文档,随后交给系统分析 Agent 拆解成研发侧材料,最终进入代码骨架生成环节。
用 mermaid 表达这个架构会更清楚:
flowchart TD
A[用户输入<br/>自然语言 / MRD / 附件] --> B[RAG 检索业务知识]
B --> C[需求大纲分析]
C --> D[PRD 多 Agent 生成]
D --> E[PRD 总结与优化]
E --> F[系统分析 Agent]
F --> G[模块拆分]
F --> H[接口设计]
F --> I[数据结构设计]
G --> J[代码骨架生成]
H --> J
I --> J
J --> K[研发交付材料]
L[历史 PRD / 产品介绍 / 知识百科] --> B
M[文档测评] --> E
M --> F
每一层都承担不同职责:
| 层级 | 主要组件 | 核心职责 |
|---|---|---|
| 知识增强层 | RAG、知识库、排序策略 | 从历史资料中找出和当前需求最相关的上下文 |
| 需求生成层 | 目标价值 Agent、需求价值 Agent、流程图 Agent、方案设计 Agent | 把业务输入转成结构化 PRD |
| 研发转化层 | 问答 Agent、系分生成 Agent、总结 Agent、内容优化 Agent | 把 PRD 拆成研发可执行的系统设计 |
| 质量保障层 | 人工测评、模型测评、格式约束、微调数据 | 检查文档准确性、完整性和规范性 |
这种架构的好处在于,每个 Agent 的目标都比较明确。与其让一个大模型同时完成“理解业务、写 PRD、画流程图、做系统设计、生成代码”,不如把任务拆成多个节点,并在关键节点加入检索、测评和人工校正。
MRD 到 PRD:把业务描述变成产品需求文档
MRD 到 PRD 的转换,本质上是把偏业务目标的材料转成偏产品执行的材料。PRD 不只描述“要做什么”,还要解释功能范围、用户路径、业务规则、异常情况、验收口径和相关模块关系。
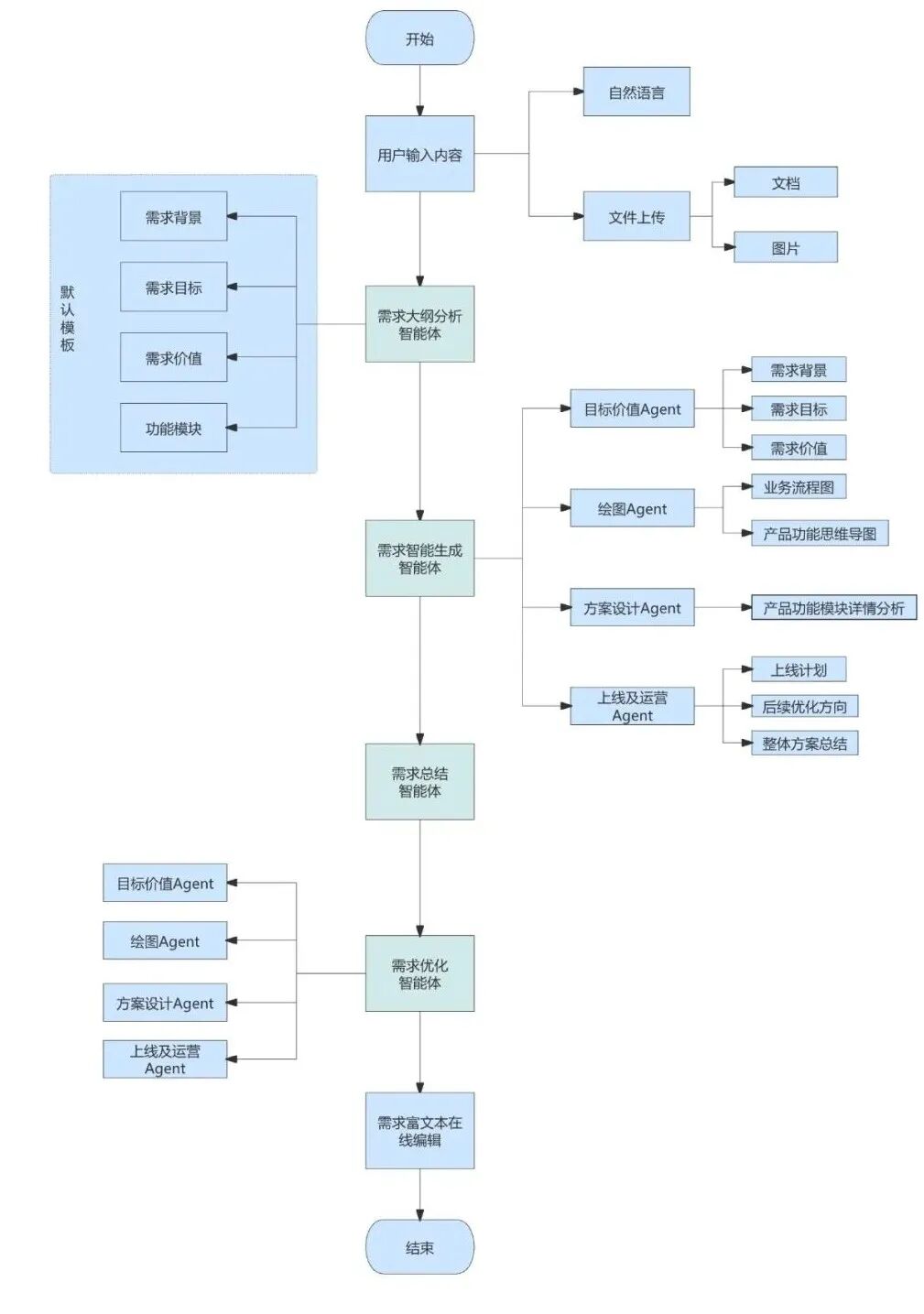
图中的 PRD 生成流程可以拆成五个阶段。
1. 用户输入阶段
输入可以来自两类信息:
| 输入类型 | 示例 | 作用 |
|---|---|---|
| 自然语言 | “希望给订单列表增加批量导出能力” | 快速表达需求意图 |
| 文件资料 | MRD、业务流程文档、产品截图、竞品说明 | 补充背景、流程、约束和已有规则 |
自然语言适合描述新增诉求,附件适合提供上下文。如果只有一句简单描述,大模型容易生成泛化内容;如果能同时读取历史文档、业务规则和页面截图,输出的 PRD 会更贴近真实业务。
2. 需求大纲分析阶段
需求大纲分析负责先搭建 PRD 的骨架,而不是直接生成长文档。常见结构包括:
1. 需求背景
2. 目标与价值
3. 用户角色
4. 使用场景
5. 功能范围
6. 功能流程
7. 业务规则
8. 异常处理
9. 数据口径
10. 验收标准
这一阶段可以安排多个 Agent 分工:
| Agent | 职责 | 输出 |
|---|---|---|
| 目标价值 Agent | 识别需求要解决的业务问题 | 目标、收益、成功指标 |
| 需求价值 Agent | 判断需求重要程度和优先级 | 优先级、影响范围、依赖项 |
| 业务流程图 Agent | 梳理业务流转和模块关系 | 流程图、节点说明 |
| 模板 Agent | 套用标准 PRD 结构 | 文档目录和字段约束 |
先生成大纲有两个好处:一是便于人快速检查方向是否正确,二是能约束后续生成结果,避免内容散乱。
3. PRD 智能生成阶段
大纲确认后,再进入正文生成。此时不应让模型自由发挥,而要给它明确的输入、输出格式和边界条件。
一个 PRD 生成 Agent 的输入可以设计成类似结构:
{
"requirement_name": "订单批量导出",
"business_background": "运营人员需要定期导出订单明细,用于对账和分析",
"target_users": ["运营人员", "财务人员"],
"related_docs": [
"历史订单查询 PRD",
"订单状态说明",
"导出权限规范"
],
"constraints": [
"只允许导出本人权限范围内的数据",
"单次导出最多 5 万条",
"导出任务需要异步处理"
],
"output_sections": [
"需求背景",
"功能说明",
"业务流程",
"权限规则",
"异常处理",
"验收标准"
]
}
输出时可以要求模型使用固定结构:
{
"background": "...",
"goals": ["..."],
"user_roles": ["..."],
"feature_list": [
{
"name": "创建导出任务",
"description": "...",
"rules": ["...", "..."],
"exceptions": ["...", "..."]
}
],
"flowchart": "mermaid flowchart ...",
"acceptance_criteria": ["...", "..."]
}
结构化输出便于后续系统分析 Agent 继续消费。如果只输出一段自然语言,后面的接口设计、数据表设计和代码骨架生成都会更难稳定。
4. 需求总结与优化阶段
PRD 初稿生成后,需要进行合并、去重、补漏和润色。这里可以设置一个总结优化 Agent,专门处理以下问题:
| 检查项 | 处理方式 |
|---|---|
| 内容重复 | 合并相同规则,删除重复描述 |
| 逻辑断裂 | 补充前置条件、后置结果和状态变化 |
| 口径不清 | 把“支持大量数据”改成明确限制,例如“单次最多 5 万条” |
| 缺少异常 | 补充权限不足、数据为空、任务超时等场景 |
| 格式不统一 | 按标准模板重新排版 |
这一阶段非常适合引入人工反馈。产品经理可以直接指出“这里不符合业务规则”“这个流程缺少审批节点”,系统再根据反馈进行多轮修订。
5. 在线编辑与最终输出
PRD 生成系统不能只给一个静态结果,还需要支持在线编辑。原因很简单:产品文档最终要服务协作,必须允许人修改、批注、补充和确认。
比较合理的交互方式是:
sequenceDiagram
participant U as 产品人员
participant A as PRD Agent
participant R as RAG 服务
participant E as 编辑器
U->>A: 输入需求描述和附件
A->>R: 检索历史资料和业务知识
R-->>A: 返回相关文档片段
A-->>E: 生成 PRD 初稿
U->>E: 修改、批注、补充规则
E->>A: 提交优化指令
A-->>E: 返回修订版本
U->>E: 确认终稿
最终输出的 PRD 应该具备三个特点:结构统一、规则明确、能被研发继续拆解。
PRD 到系统分析:把产品语言转成研发语言
PRD 描述的是产品功能,系统分析文档描述的是软件实现方式。两者关注点不同。
| PRD 关注点 | 系统分析关注点 |
|---|---|
| 用户能做什么 | 系统需要哪些模块 |
| 页面和流程如何交互 | 前后端如何调用 |
| 业务规则是什么 | 规则落在哪些服务和表里 |
| 哪些情况算验收通过 | 如何设计接口、数据、异常和日志 |
| 产品边界在哪里 | 技术边界、依赖系统、性能约束在哪里 |
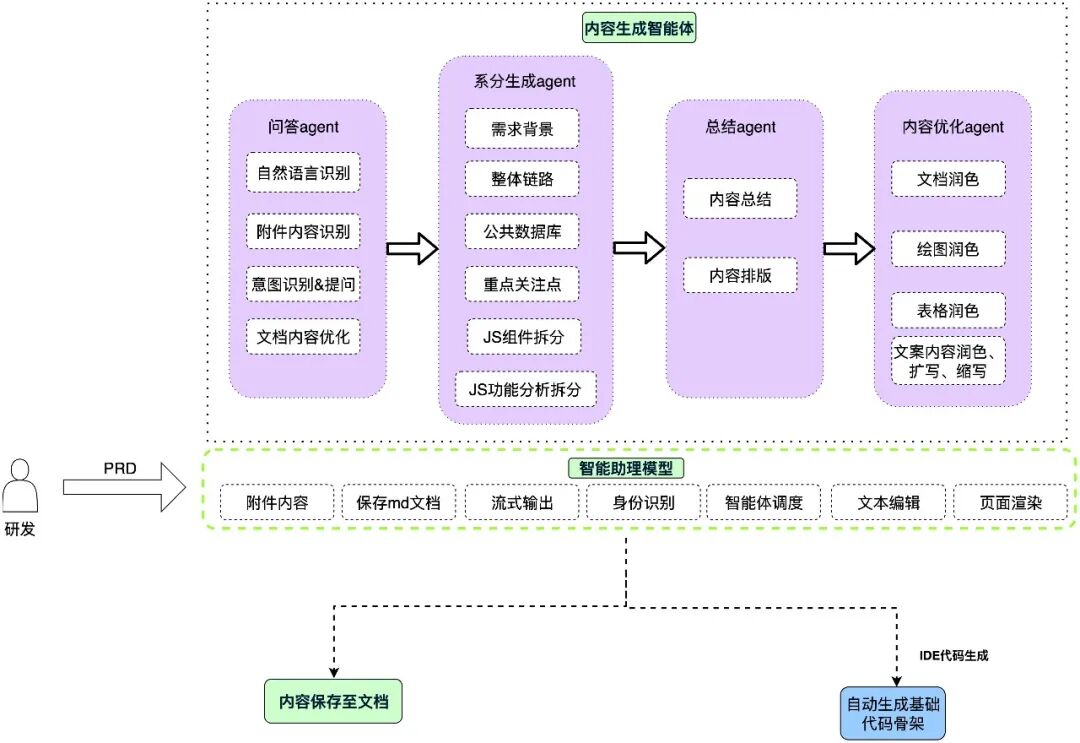
图中的流程从研发人员输入 PRD 开始,系统通过问答 Agent、系分生成 Agent、总结 Agent 和内容优化 Agent,逐步生成系统分析文档,并进一步产出代码骨架。
问答 Agent:解析 PRD 和附件
问答 Agent 的职责是把 PRD 中的自然语言内容转成可处理的信息单元。它需要识别:
- 需求背景
- 功能列表
- 业务规则
- 用户角色
- 权限要求
- 数据字段
- 外部系统依赖
- 附件中的补充信息
例如 PRD 中有一句话:
运营人员可以按订单状态和下单时间筛选订单,并异步导出符合条件的数据。
问答 Agent 应该提取出:
{
"actor": "运营人员",
"operation": "异步导出订单",
"filters": ["订单状态", "下单时间"],
"data_scope": "符合筛选条件的数据",
"process_type": "异步任务"
}
这些结构化信息会进入后续系统分析环节。
系分生成 Agent:拆模块、定接口、建数据模型
系统分析 Agent 要把产品需求拆成技术设计。以“订单批量导出”为例,可能得到这样的模块划分:
| 模块 | 职责 |
|---|---|
| 导出任务模块 | 创建导出任务、查询任务状态、取消任务 |
| 权限校验模块 | 校验用户是否有导出权限和数据访问范围 |
| 查询条件模块 | 解析订单状态、时间范围、分页条件 |
| 异步执行模块 | 执行导出任务,生成文件 |
| 文件存储模块 | 保存导出文件,生成下载地址 |
| 通知模块 | 导出完成后通知用户 |
对应的接口草案可以这样设计:
POST /api/order-export/tasks
GET /api/order-export/tasks/{taskId}
GET /api/order-export/tasks/{taskId}/download
POST /api/order-export/tasks/{taskId}/cancel
数据表草案可以这样描述:
| 字段 | 类型 | 说明 |
|---|---|---|
| id | bigint | 导出任务 ID |
| creator_id | bigint | 创建人 |
| filter_condition | json | 筛选条件 |
| status | varchar | 任务状态 |
| file_url | varchar | 导出文件地址 |
| error_message | text | 失败原因 |
| created_at | datetime | 创建时间 |
| finished_at | datetime | 完成时间 |
系统分析 Agent 不一定要直接给出最终设计,但应该提供一个足够完整的初稿,让研发评审时有明确讨论对象。
总结 Agent:把分析结果整理成规范文档
系统分析过程会产生很多碎片信息,例如模块说明、接口列表、数据字段、异常情况和流程图。总结 Agent 负责把这些内容整理成统一格式。
一个系统分析文档可以采用这样的结构:
1. 需求概述
2. 业务流程
3. 系统边界
4. 模块设计
5. 接口设计
6. 数据库设计
7. 状态机设计
8. 异常处理
9. 日志与监控
10. 安全与权限
11. 风险点与待确认事项
其中“待确认事项”很重要。大模型无法确定的信息不应该被伪装成确定结论,而应该显式列出,例如:
| 待确认项 | 需要确认的人 | 原因 |
|---|---|---|
| 单次导出最大条数 | 产品 / 架构 | 影响异步任务和存储设计 |
| 文件保留时间 | 产品 / 运维 | 影响存储成本和清理策略 |
| 是否支持跨组织导出 | 产品 / 安全 | 影响权限模型 |
内容优化 Agent:补图、补表、补约束
内容优化 Agent 不负责重新理解需求,而是提升文档的可读性和完整性。常见工作包括:
- 把长段文字改成表格;
- 生成数据流图、模块关系图、状态机图;
- 对接口参数补充说明;
- 对异常场景补充处理方式;
- 检查文档章节是否缺失。
例如导出任务状态可以用状态机表达:
stateDiagram-v2
[*] --> CREATED: 创建任务
CREATED --> RUNNING: 开始执行
RUNNING --> SUCCESS: 文件生成成功
RUNNING --> FAILED: 执行失败
CREATED --> CANCELED: 用户取消
RUNNING --> CANCELED: 用户取消
SUCCESS --> EXPIRED: 文件过期
这种图比文字更容易帮助研发、测试和产品对齐边界。
从系统分析到代码骨架
系统分析结果足够结构化后,就可以进一步生成代码骨架。这里的“代码骨架”不是完整业务代码,而是项目结构、类、接口、方法、数据对象和基础注释。
以典型后端分层为例,可以生成:
order-export/
├── controller/
│ └── OrderExportController.java
├── service/
│ ├── OrderExportService.java
│ └── impl/
│ └── OrderExportServiceImpl.java
├── repository/
│ └── OrderExportTaskRepository.java
├── domain/
│ └── OrderExportTask.java
├── dto/
│ ├── CreateExportTaskRequest.java
│ ├── ExportTaskResponse.java
│ └── ExportTaskQuery.java
└── enum/
└── ExportTaskStatus.java
Controller 层可以先生成接口骨架:
@RestController
@RequestMapping("/api/order-export/tasks")
public class OrderExportController {
private final OrderExportService orderExportService;
public OrderExportController(OrderExportService orderExportService) {
this.orderExportService = orderExportService;
}
@PostMapping
public ExportTaskResponse createTask(@RequestBody CreateExportTaskRequest request) {
return orderExportService.createTask(request);
}
@GetMapping("/{taskId}")
public ExportTaskResponse getTask(@PathVariable Long taskId) {
return orderExportService.getTask(taskId);
}
@GetMapping("/{taskId}/download")
public String getDownloadUrl(@PathVariable Long taskId) {
return orderExportService.getDownloadUrl(taskId);
}
@PostMapping("/{taskId}/cancel")
public void cancelTask(@PathVariable Long taskId) {
orderExportService.cancelTask(taskId);
}
}
Service 层可以保留待实现逻辑:
public interface OrderExportService {
ExportTaskResponse createTask(CreateExportTaskRequest request);
ExportTaskResponse getTask(Long taskId);
String getDownloadUrl(Long taskId);
void cancelTask(Long taskId);
}
DTO 可以根据系统分析中的字段自动生成:
public class CreateExportTaskRequest {
private List<String> orderStatusList;
private LocalDateTime startTime;
private LocalDateTime endTime;
private Map<String, Object> extraFilters;
// getter/setter
}
生成代码骨架的价值在于减少“从空项目开始搭结构”的时间。业务逻辑、边界条件、事务一致性、性能优化和安全校验仍然需要研发人员审核和实现。
细节创作能力:让文档支持局部改写
除了完整生成 PRD 或系统分析文档,大模型还适合做局部创作。常见能力有四类:
| 能力 | 输入 | 输出 | 适合场景 |
|---|---|---|---|
| 自定义对话 | 用户指令和选中文本 | 按要求修改后的内容 | 调整语气、补充规则、改写段落 |
| 润色 | 粗糙描述 | 更清晰、规范的描述 | PRD 评审前统一表达 |
| 扩写 | 简短需求点 | 更完整的说明 | 补充背景、异常、验收口径 |
| 缩写 | 长段内容 | 摘要或要点 | 评审纪要、需求摘要 |
例如原始需求点是:
支持订单导出。
扩写后可以变成:
系统支持运营人员在订单列表中按照订单状态、下单时间等条件筛选订单,并创建异步导出任务。导出任务创建后,用户可以查看任务状态;任务完成后,系统提供文件下载入口。若用户无导出权限、筛选结果为空或任务执行失败,系统需要给出明确提示。
局部创作能力看似简单,但在日常协作中很实用。它能把零散表达快速整理成可评审的需求描述。
RAG:给大模型补充业务上下文
大模型本身不掌握企业内部的历史 PRD、产品规则、接口规范和业务百科。直接让它生成需求文档,容易出现泛化表达,甚至把不存在的规则写进去。RAG 的作用就是在生成前先检索相关业务知识,把检索结果作为上下文交给模型。
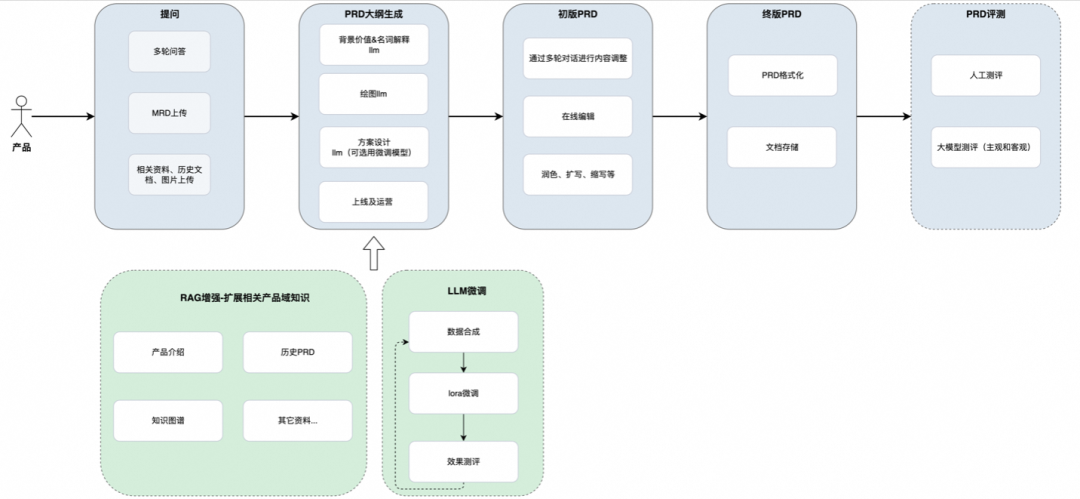
图中的支撑模块主要包含两部分:一是 RAG 检索业务知识,二是 LLM(Large Language Model,大语言模型)微调与文档测评。RAG 负责解决上下文不足的问题,微调和测评负责持续改善模型在特定业务场景下的输出质量。
RAG 辅助智能体的流程
RAG 链路可以拆成六步:
flowchart TD
A[用户输入需求] --> B[选择或匹配知识库]
B --> C{数据集是否为空}
C -- 是 --> D[使用默认知识库全部文档]
C -- 否 --> E[使用指定数据集文档]
D --> F[文档切块与向量检索]
E --> F
F --> G[稠密向量召回 BGE]
F --> H[稀疏向量召回 SPLADE]
G --> I[综合排序]
H --> I
I --> J[返回相关文档片段]
J --> K[交给 Agent 生成或优化文档]
核心细节有三个。
1. 数据集选择
知识库不一定只有一个。不同产品线、业务域、系统模块可能有各自的数据集。用户输入需求后,系统可以自动匹配知识库,也可以让用户手动选择。
例如:
| 需求 | 合适知识库 |
|---|---|
| 订单导出 | 订单中心 PRD、权限规范、导出任务技术方案 |
| 会员等级 | 会员体系说明、积分规则、权益配置文档 |
| 发票开具 | 财务规则、税务字段说明、历史发票 PRD |
如果知识库选择错误,后面的检索结果再准确也没有意义。
2. 混合检索
单一检索方式很难覆盖所有场景。稠密向量适合语义相近的内容,稀疏向量适合关键词匹配强的内容。
| 检索方式 | 代表模型 | 擅长场景 | 不足 |
|---|---|---|---|
| 稠密向量检索 | BGE 向量模型 | 语义相近但关键词不同的内容 | 对精确术语、编号、字段名不一定敏感 |
| 稀疏向量检索 | SPLADE 稀疏词项扩展模型 | 字段名、专有名词、规则编号等关键词检索 | 对语义改写的召回能力较弱 |
| 混合检索 | BGE + SPLADE | 同时兼顾语义和关键词 | 需要设计排序和融合策略 |
例如用户输入“批量导出订单明细”,稠密向量可能召回“订单报表下载”,稀疏向量可能召回包含“导出”“订单明细”的规则文档。两类结果融合后,召回质量通常更稳。
3. 综合排序
检索出的文档片段需要重新排序,否则模型可能拿到大量弱相关上下文。排序可以综合考虑:
- 语义相似度;
- 关键词命中;
- 文档类型;
- 更新时间;
- 所属业务域;
- 用户选择的数据集权重;
- 历史对话中的意图。
一个简化的打分方式可以写成:
def rank_score(dense_score, sparse_score, doc_type_weight, freshness_weight):
return (
0.45 * dense_score +
0.35 * sparse_score +
0.10 * doc_type_weight +
0.10 * freshness_weight
)
真实场景里,权重不一定固定,可以根据业务域和测评结果不断调整。
文档测评与模型微调
只搭建生成链路还不够,还需要判断输出质量。否则系统看起来能生成很多内容,但无法确定哪些内容可靠。
文档测评
PRD 和系统分析文档可以从几个维度评估:
| 维度 | 检查问题 |
|---|---|
| 准确性 | 是否符合输入需求和历史规则 |
| 完整性 | 是否覆盖背景、流程、规则、异常、验收标准 |
| 一致性 | 前后描述是否冲突 |
| 可执行性 | 研发是否能据此拆接口、建表、估工作量 |
| 规范性 | 是否符合模板、字段和格式要求 |
| 可追溯性 | 关键结论是否能追溯到输入或知识库片段 |
测评可以结合人工和模型自动评估。人工适合判断业务正确性,模型适合检查格式、缺漏、重复和一致性问题。
模型微调
当业务有稳定模板、固定表达和大量领域术语时,可以考虑对模型做轻量微调。LoRA(Low-Rank Adaptation,低秩适配)是一种常见方式,它不需要全量更新模型参数,而是在较小参数规模上适配特定任务。
适合微调的数据包括:
| 数据类型 | 示例 | 用途 |
|---|---|---|
| 高质量 PRD | 已评审通过的产品需求文档 | 学习文档结构和表达方式 |
| 系统分析文档 | 已落地的技术设计 | 学习模块拆分和接口描述 |
| 修订记录 | 初稿与终稿差异 | 学习常见错误和改写方式 |
| 格式约束样本 | 标准模板、字段规范 | 提升输出格式稳定性 |
| 业务术语表 | 产品名、字段名、状态枚举 | 减少术语误用 |
微调不能替代 RAG。RAG 解决“拿到最新知识”的问题,微调解决“更像目标任务、更符合格式和表达习惯”的问题。两者配合使用更合理。
关键挑战与优化方向
RAG 链路需要更懂用户意图
用户输入往往不是标准查询语句,而是模糊诉求。例如:
想优化一下退款流程,减少客服介入。
如果直接检索,系统可能同时召回退款规则、客服工单、售后流程、支付渠道说明等大量资料。更合理的做法是在调用 RAG 前先做意图拆解:
{
"main_intent": "优化退款流程",
"sub_questions": [
"当前退款流程包含哪些节点?",
"哪些节点需要客服介入?",
"是否存在自动审核规则?",
"退款失败或超时如何处理?"
],
"target_docs": [
"退款 PRD",
"售后流程",
"客服工单规则",
"支付渠道退款说明"
]
}
拆解后再检索,召回会更聚焦。检索完成后,还需要结合历史对话进行总结,避免把多个文档片段简单拼接给生成 Agent。
高质量领域数据需要持续沉淀
模型微调和自动测评都依赖高质量数据。真正有价值的数据不是随便收集的文档,而是经过业务确认、研发落地、线上验证的材料。尤其是以下数据非常关键:
- 评审通过的 PRD;
- 实际研发采用的系统分析文档;
- 需求变更记录;
- 评审意见和修改原因;
- 线上问题对应的需求遗漏点;
- 标准模板和格式规范。
这些数据可以帮助系统知道“什么样的输出才算好”,而不只是生成看起来完整的文档。
复杂业务仍然需要多轮灰度
复杂业务里,需求经常涉及多个系统、多个角色和多套历史规则。大模型一次生成的结果很难直接作为最终设计,需要通过灰度方式逐步验证:
flowchart LR
A[小范围试用] --> B[人工评审]
B --> C[收集错误类型]
C --> D[优化 Prompt / RAG / 模型]
D --> E[扩大业务范围]
E --> B
错误类型要被结构化记录,例如:
| 错误类型 | 示例 | 优化手段 |
|---|---|---|
| 规则遗漏 | 忘记导出权限限制 | 增强 RAG 召回和测评规则 |
| 格式不稳定 | 输出章节缺失 | 加强模板约束 |
| 术语不一致 | 同一状态使用多个名称 | 引入业务术语表 |
| 过度推断 | 写入输入中不存在的规则 | 要求结论引用来源 |
| 系统边界不清 | 把外部系统能力写成本系统能力 | 增加系统依赖识别 |
通过这种方式,智能体系统会逐步从“能生成”走向“可稳定协作”。
落地时的边界
大模型智能体适合承担需求分析和设计中的结构化辅助工作,包括检索上下文、整理文档、生成初稿、补充图表、拆分模块和产出代码骨架。它不适合替代产品决策、架构决策和最终代码审核。
更可靠的定位是:
| 适合交给 AI 的工作 | 仍需人工负责的工作 |
|---|---|
| 整理需求背景 | 判断需求是否值得做 |
| 补全 PRD 模板 | 确认业务目标和优先级 |
| 生成流程图初稿 | 确认真实业务流程 |
| 生成接口和表结构草案 | 决定最终架构和技术方案 |
| 检查文档缺漏 | 对交付结果负责 |
| 生成代码骨架 | 实现核心业务逻辑和质量保障 |
当输入足够完整、知识库质量较高、输出格式有约束、测评机制能持续反馈时,大模型智能体可以把大量需求分析和设计工作前移并自动化。产品和研发的主要工作会从“从零编写材料”变成“审核、修订和确认关键决策”,协作成本也会随之降低。