Tencent-HY-MT1.5 是腾讯混元开源的机器翻译模型系列,包含两个尺寸:
| 模型 | 参数规模 | 主要定位 | 典型场景 |
|---|---|---|---|
| Tencent-HY-MT1.5-1.8B | 1.8B | 端侧、离线、低延迟翻译 | 手机、PC 客户端、即时通讯、客服辅助 |
| Tencent-HY-MT1.5-7B | 7B | 更高质量翻译、云侧推理 | 专业文档、复杂长文本、多语种服务 |
这个系列支持 33 个语种互译,并覆盖 5 种民汉语言或方言场景。除了中文、英语、日语等常见语言,也包含捷克语、马拉地语、爱沙尼亚语、冰岛语等相对低资源语种。
它的核心价值不只是“能翻译”,而是把机器翻译模型拆成了两个可落地的形态:小模型负责低成本、低延迟和离线能力,大模型负责更高准确率和复杂场景质量。对于真实产品来说,这种组合比单独追求一个大模型更容易部署。
两个模型分别解决什么问题
1.8B:面向端侧实时翻译
Tencent-HY-MT1.5-1.8B 的重点是端侧部署。经过量化后,它可以在约 1GB 内存条件下运行,适合放到手机、桌面客户端或边缘设备上做离线翻译。
端侧翻译有几个明显好处:
| 能力 | 对产品的意义 |
|---|---|
| 离线可用 | 没有网络时仍能翻译 |
| 低延迟 | 用户输入后可以快速返回结果 |
| 隐私更可控 | 文本不一定需要上传到云端 |
| 成本低 | 高频短文本不必全部调用云服务 |
在处理 50 个 token(模型处理文本的基本单元)时,HY-MT1.5-1.8B 的平均耗时约为 0.18 秒,而一些商用翻译 API(应用程序编程接口)的耗时大约在 0.4 秒。对即时通讯、客服对话、输入法翻译这类场景来说,0.2 秒以内的响应会明显改变交互体验,因为用户几乎不需要等待。
7B:面向质量和复杂文本
Tencent-HY-MT1.5-7B 是质量优先的版本,也是此前在 WMT25(Workshop on Machine Translation,机器翻译评测赛事)中获得多个语种翻译第一的模型升级版。
它重点改善了两个常见问题:
| 问题 | 表现 | 改善方向 |
|---|---|---|
| 译文夹带注释 | 模型把解释、提示语、括号说明混进翻译结果 | 更严格输出目标语言译文 |
| 语种混杂 | 翻译结果里出现源语言或其他语言片段 | 增强语言控制和目标语一致性 |
这类问题在聊天机器人、文档翻译、网页翻译中很常见。翻译模型不只要“知道意思”,还要稳定遵守输出格式和目标语言要求,否则工程系统还要额外做清洗、检测和重试。
端云协同:小模型和大模型不是二选一
1.8B 和 7B 可以组合使用。常见做法是把 1.8B 放在端侧处理高频、短文本、低风险内容,把 7B 放在云侧处理长文本、专业内容或质量要求更高的请求。
flowchart LR
A[用户输入文本] --> B{请求类型判断}
B -->|短文本/实时/离线| C[端侧 HY-MT1.5-1.8B]
B -->|长文本/专业术语/高质量| D[云侧 HY-MT1.5-7B]
C --> E[返回译文]
D --> E
F[术语库] --> C
F --> D
G[上下文信息] --> C
G --> D
这种架构的关键不是简单地“端侧一个、云侧一个”,而是让两个模型共享相同的术语库、语言规则和上下文组织方式。这样端侧和云侧的结果不会出现明显风格割裂,用户在不同网络状态、不同文本长度下得到的翻译也更一致。
评测表现:质量和速度要一起看
机器翻译模型不能只看一个分数。质量、速度、部署成本和语言覆盖范围都要放在一起比较。
HY-MT1.5 的评测覆盖了 FLORES-200、多语种 WMT25 测试集,以及民汉语言翻译测试集。FLORES-200 是常用的多语种翻译基准,适合观察模型在大量语言方向上的平均能力。
下面两组评测图展示了 HY-MT1.5-1.8B、HY-MT1.5-7B、部分开源模型、商用翻译 API 和 Gemini-3.0-Pro 等模型之间的效果对比。
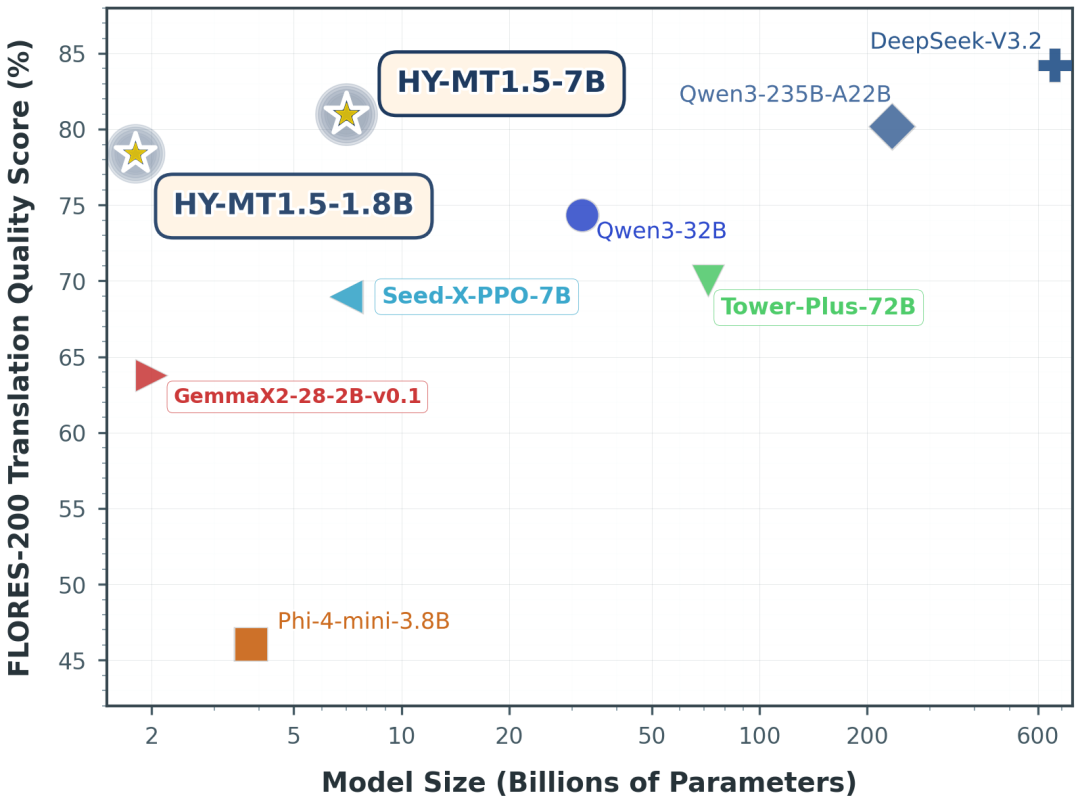
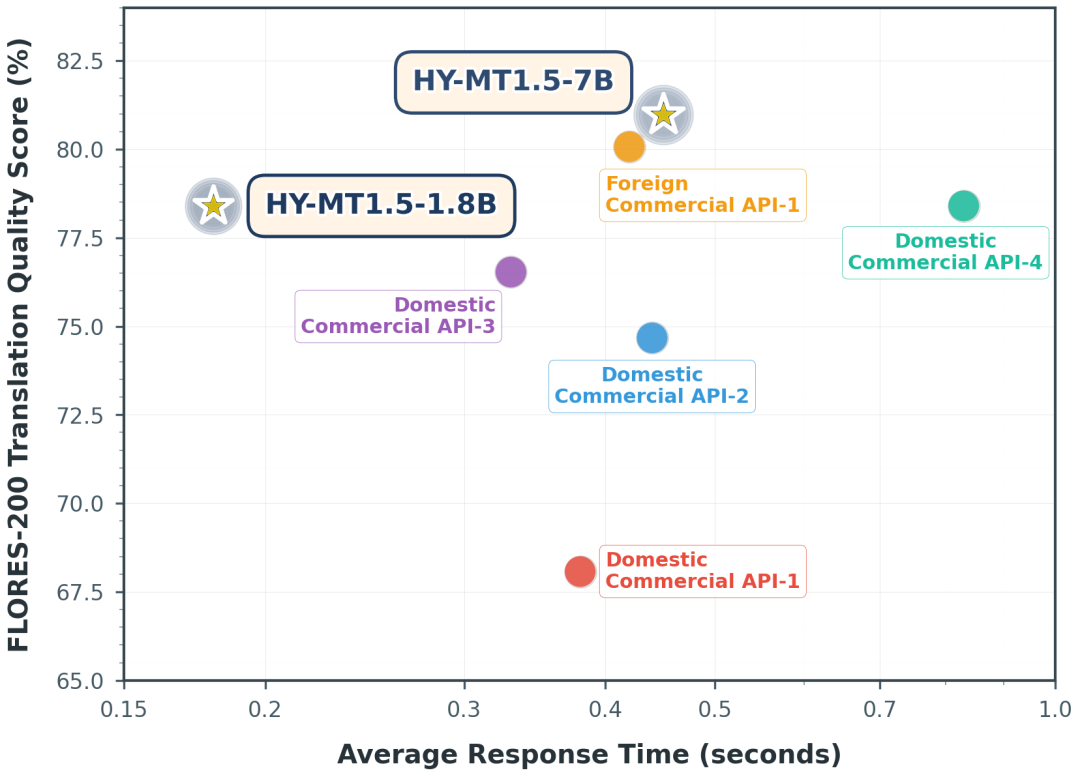
从结果关系看,HY-MT1.5-1.8B 在常用中外互译、英外互译以及民汉语言翻译任务中,超过了不少中等尺寸开源模型和主流商用翻译 API。在 WMT25 和民汉语言测试集上,它与 Gemini-3.0-Pro 这类超大闭源模型仍有差距,但已经接近其较高分位水平。
对 1.8B 模型来说,这个结果比较关键:它不是用大规模算力换质量,而是在小参数量和端侧可运行条件下尽量靠近大模型效果。工程落地时,这种模型更适合处理大量实时翻译请求,因为它节省的是推理资源和用户等待时间。
三类实用能力:术语、上下文、格式
通用翻译模型进入真实业务后,最容易遇到的不是“完全不会翻译”,而是以下细节不稳定:
- 专业词汇翻译不一致;
- 多轮对话里指代关系丢失;
- HTML、Markdown、表格等格式被破坏。
HY-MT1.5 针对这些问题提供了三类能力。
术语库:让专业词汇保持一致
术语库适合医学、法律、金融、科技等专业场景。它的作用是提前规定一些词怎么翻译,模型在生成译文时优先采用这些指定表达。
示例:
| 源语言术语 | 指定译法 |
|---|---|
| 大语言模型 | large language model |
| 向量数据库 | vector database |
| 召回率 | recall |
| 合规审查 | compliance review |
如果没有术语库,小模型在专业文本中可能会把同一个词翻成多个版本。比如“召回率”有时翻成 recall,有时翻成 retrieval rate,技术文档就会变得不统一。术语库可以把这类词固定下来,让合同、说明书、技术手册的翻译更稳定。
上下文翻译:让长对话和长文档不断裂
短句翻译只需要处理当前句子,长文本翻译还需要理解前后关系。比如“它”“该系统”“上述方案”这些指代词,如果没有上下文,模型可能不知道它们指向什么。
上下文翻译通常会把前文摘要、历史对话或相邻段落一起传给模型:
sequenceDiagram
participant U as 用户
participant S as 翻译服务
participant M as HY-MT1.5
U->>S: 输入第 N 句话
S->>S: 读取历史上下文和术语库
S->>M: 当前文本 + 上下文 + 目标语言
M-->>S: 返回保持语义连贯的译文
S-->>U: 输出翻译结果
这种方式适合会议记录、访谈、小说章节、技术文档和多轮客服对话。模型不仅翻译当前句子,还会参考前面的表达方式,从而减少风格突然变化、指代不清和语义断裂。
带格式文本翻译:只翻译内容,不破坏结构
网页、Markdown、表格和富文本不适合直接当纯文本翻译,因为标签、占位符、链接、代码块都可能被模型改坏。
带格式翻译需要模型遵守两条规则:
| 内容类型 | 处理方式 |
|---|---|
| 普通自然语言 | 翻译成目标语言 |
| HTML 标签、Markdown 标记、变量占位符 | 保持不变 |
| 链接、代码、数字编号 | 按规则保留 |
| 表格结构 | 保持行列关系 |
例如:
<p>Hello, <strong>world</strong>!</p>
理想输出不是把标签也翻译掉,而是:
<p>你好,<strong>世界</strong>!</p>
这类能力对网页国际化、产品说明书、多语言知识库尤其重要,因为格式一旦损坏,后续渲染、发布和检索都会受影响。
小模型为什么能接近大模型:On-Policy Distillation
HY-MT1.5-1.8B 能在小尺寸下获得较好的翻译质量,关键训练方法是 On-Policy Distillation,可以理解为“在模型自己生成的过程中做蒸馏”。
传统蒸馏经常让学生模型直接学习教师模型的标准答案,这种方式容易让学生模型记住目标句子,却不一定能学会如何修正自己的生成路径。On-Policy Distillation 的思路不同:让 1.8B 学生模型在生成过程中暴露自己的预测偏差,再由 7B 教师模型实时引导它修正。
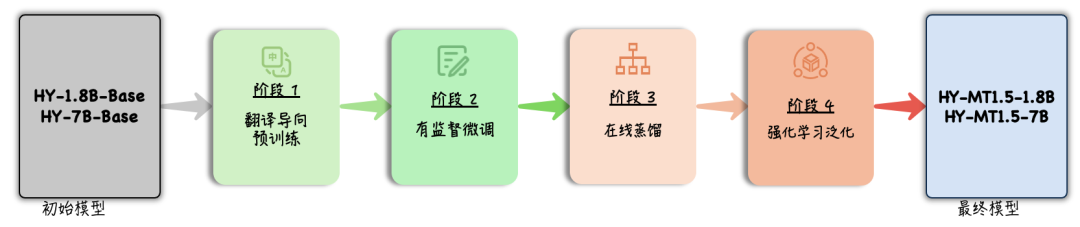
这个过程可以抽象成下面的训练闭环:
flowchart TD
A[源语言句子] --> B[1.8B Student 生成候选译文]
B --> C[检查生成分布和偏移]
C --> D[7B Teacher 给出更优分布或修正信号]
D --> E[Student 更新参数]
E --> B
重点在“候选译文来自学生模型自己”。学生模型不是只看正确答案,而是在自己的错误轨迹上学习:哪里容易跑偏、哪里容易混入其他语言、哪里容易添加多余注释。经过这种训练,小模型在真实推理时更容易保持稳定输出。
适合和不适合的场景
| 场景 | 适合模型 | 原因 |
|---|---|---|
| 手机离线翻译 | 1.8B | 内存占用低,响应快,不依赖网络 |
| 即时通讯短句翻译 | 1.8B | 高频短文本更看重低延迟 |
| 客服实时辅助 | 1.8B 或端云混合 | 普通对话走端侧,复杂问题走云侧 |
| 专业合同、论文、技术文档 | 7B | 长文本和专业术语更需要质量 |
| 网页和富文本翻译 | 1.8B 或 7B | 取决于文本长度和质量要求 |
| 多语种大规模服务 | 端云协同 | 成本、延迟和质量可以分层控制 |
不太适合直接只用 1.8B 的场景也很明确:极长文档、法律级别高风险文本、需要严格审校的出版内容,以及包含大量行业黑话的新领域语料。这些任务可以先用模型生成初稿,再引入人工校对或使用 7B 版本做二次处理。
上手方式
模型已经开放在腾讯混元官网、GitHub 和 HuggingFace。开发者可以根据部署目标选择下载方式。
- 混元官网:https://hunyuan.tencent.com/modelSquare/home/list
- GitHub:https://github.com/Tencent-Hunyuan/HY-MT
- HuggingFace Collection:https://huggingface.co/collections/tencent/hy-mt15
典型流程如下:
# 获取推理代码
git clone https://github.com/Tencent-Hunyuan/HY-MT.git
cd HY-MT
# 如果从 HuggingFace 下载模型,先启用 Git LFS
git lfs install
# 在模型页面复制对应仓库地址后下载
git clone <HF_MODEL_REPO_URL> models/Tencent-HY-MT1.5-1.8B
工程封装时,可以把翻译请求统一整理成这样的结构:
{
"source_language": "zh",
"target_language": "en",
"text": "向量数据库适合存储文本嵌入,并支持相似度检索。",
"terminology": {
"向量数据库": "vector database",
"文本嵌入": "text embedding",
"相似度检索": "similarity search"
},
"context": [
"前文正在介绍检索增强生成系统。"
],
"preserve_format": true
}
端云协同时,可以让路由层根据文本长度、网络状态和质量要求决定调用哪个模型:
def choose_model(text: str, online: bool, high_quality: bool) -> str:
token_count = estimate_tokens(text)
if not online:
return "Tencent-HY-MT1.5-1.8B"
if high_quality or token_count > 512:
return "Tencent-HY-MT1.5-7B"
return "Tencent-HY-MT1.5-1.8B"
这里的代码只是工程封装思路,实际推理参数、量化方式和运行后端需要以模型仓库提供的说明为准。
部署时需要注意的细节
量化会影响质量,需要按业务验收
1.8B 能在较低内存下运行,离不开量化。量化会降低权重精度,通常能换来更低内存占用和更快推理速度,但也可能让少数语言方向、专业术语或长句翻译质量下降。
比较稳妥的做法是准备一批真实业务样本,覆盖常见语种、专业词、长句、格式文本和异常输入,再决定量化等级。
术语库要处理冲突
同一个词在不同领域可能有不同译法。例如 “charge” 在法律、金融、物理场景里含义差异很大。如果术语库没有领域隔离,模型可能会强行使用错误译法。
术语库最好带上领域、优先级和适用语言方向:
{
"domain": "finance",
"source_language": "en",
"target_language": "zh",
"terms": {
"charge": "费用",
"equity": "权益"
}
}
格式翻译要做后置校验
即使模型支持带格式翻译,也建议在工程上增加校验。例如 HTML 翻译后检查标签是否闭合,Markdown 翻译后检查代码块数量是否一致,变量占位符是否丢失。
flowchart LR
A[带格式文本] --> B[模型翻译]
B --> C[格式校验]
C -->|通过| D[返回结果]
C -->|失败| E[重试或降级处理]
端侧模型要关注平台适配
HY-MT1.5 支持 Arm、高通、Intel、沐曦等平台部署。不同平台的推理引擎、量化格式和算子支持并不完全一致,部署前需要确认:
- 模型权重格式是否兼容目标推理引擎;
- 量化版本是否适配 CPU、NPU 或 GPU;
- 内存峰值是否满足设备限制;
- 多线程推理是否会影响前台应用体验;
- 离线包体积是否能被产品接受。
小结
Tencent-HY-MT1.5 的设计思路很清晰:1.8B 负责把翻译能力带到端侧,7B 负责提供更高质量的云侧翻译,两者通过同一模型体系降低端云结果差异。术语库、上下文翻译和格式保持能力解决的是工程落地中最容易出问题的细节,而 On-Policy Distillation 则是小模型接近大模型效果的关键训练方法。
如果目标是移动端离线翻译、实时对话翻译或低成本多语种服务,1.8B 版本更值得优先验证;如果目标是专业文档、长文本和质量要求更高的翻译任务,7B 版本或端云协同方案更合适。