OpenClaw 值得关注的地方,不在于它把一个聊天机器人包装成了更有个性的个人助理,而在于它把近几年 AI Agent 领域的一批关键工程实践组合到了一起:动态提示词、文件化人格与配置、技能渐进加载、上下文压缩、长期记忆、工具调用、Hook 钩子、安全沙箱和人在环路控制。
这些能力单独看并不神秘,真正有意思的是它们如何被组织成一个可长期运行的 Agent 系统。一个成熟的 Agent 不是只靠一段 System Prompt 工作,而是要同时回答三个问题:
- Prompt Engineering(提示词工程):如何把角色、规则、工具和任务要求清晰地告诉模型?
- Context Engineering(上下文工程):如何让模型在有限窗口里看到最需要的信息?
- Harness Engineering(驾驭工程 / 脚手架工程):如何用外部机制约束模型,让它安全、可控、可恢复地执行任务?
三者的关系可以用一张图概括:
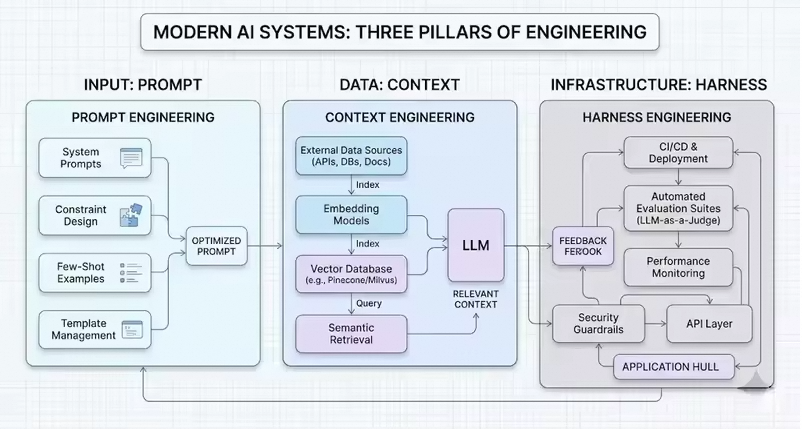
Prompt 决定模型“应该怎么想、怎么说、怎么行动”,Context 决定模型“能看到哪些信息”,Harness 则决定模型“在什么边界内行动”。Prompt 和 Context 主要发生在模型输入侧,Harness 更偏系统侧,它通过工具权限、Hook、沙箱、审批、测试和状态机等机制,把 Agent 从“会回答问题”推进到“能可靠执行任务”。
flowchart TB
U[用户 / 外部事件] --> H[Harness: Hook、沙箱、审批、测试]
H --> P[Prompt Builder: 动态组装系统提示词]
P --> C[Context Manager: 历史、技能、记忆、工具结果]
C --> M[LLM 大语言模型]
M --> T[Tools 工具调用]
T --> H
H --> C
M --> R[回复 / 行动结果]
Prompt Engineering:从固定提示词到动态组装系统
在早期应用里,System Prompt 往往是一段手写文本,例如“你是一个有帮助的助手”。这种方式适合简单问答,但不适合长期运行的 Agent。Agent 需要知道自己的身份、工具能力、安全边界、工作目录、当前渠道、可用技能、记忆读取规则、消息发送方式、沙箱状态等信息。把所有内容硬编码成一个巨大字符串,会带来三个问题:
- 指令难维护,改一处可能影响很多场景;
- 所有场景都加载全量提示词,浪费上下文窗口;
- 工具、技能、用户信息不断变化,固定提示词跟不上运行时状态。
OpenClaw 的做法是把 System Prompt 当成一个运行时构建产物。最终传给模型的仍然是一段完整系统提示词,但它不是提前写死的,而是由多个模块按条件拼接出来。
三种 PromptMode:不同任务加载不同提示词
OpenClaw 把提示词加载分成三种模式:
| 模式 | 适用场景 | 加载内容 |
|---|---|---|
full | 主 Agent 与用户直接对话 | 身份、工具、安全规则、技能、记忆、消息系统、工作区、运行时信息等完整模块 |
minimal | 子 Agent 执行独立任务 | 保留工具、工作区、运行时信息等必要模块,去掉主会话相关内容 |
none | 极简内部场景 | 基本只保留身份标识和运行时必要信息 |
这种区分的原因很直接:上下文窗口是有限资源。主 Agent 需要完整人格、记忆和消息规则;子 Agent 只需要完成被分配的任务,不应该背负过多历史和个性化配置;极简任务甚至不需要完整系统设定。
一个简化后的构建逻辑可以写成这样:
type PromptMode = "full" | "minimal" | "none";
function buildAgentSystemPrompt(ctx: RuntimeContext) {
const parts: string[] = [];
// 永远存在:身份和运行时信息
parts.push("You are OpenClaw, a personal AI assistant.");
if (ctx.mode !== "none") {
parts.push(renderAvailableTools(ctx.tools));
parts.push(renderWorkspace(ctx.workspace));
parts.push(renderRuntime(ctx.runtime));
}
if (ctx.mode === "full") {
parts.push(renderToolCallStyle());
parts.push(renderSafetyGuidelines());
parts.push(renderCliCommands());
parts.push(renderSkills(ctx.skills));
parts.push(renderMemoryRecall(ctx.memory));
parts.push(renderMessaging(ctx.channels));
parts.push(renderHeartbeats(ctx.heartbeat));
parts.push(renderSilentMode());
}
parts.push(renderMarkdownProjectContext(ctx.workspaceFiles));
return parts.filter(Boolean).join("\n\n");
}
这个伪代码表达的是一种架构思想:System Prompt 不是一段文本,而是一组可组合模块。每个模块有明确职责,并且受模式、工具可用性、配置文件、运行环境共同控制。
System Prompt 的模块分层
OpenClaw 的系统提示词模块很多,但可以归为几类:
| 模块类型 | 代表内容 | 作用 |
|---|---|---|
| 身份与行为准则 | 身份标识、安全准则、回复风格 | 定义 Agent 是谁、能做什么、不能做什么 |
| 工具与执行规则 | 工具清单、工具调用风格、命令说明 | 告诉模型可以调用哪些工具,以及何时调用 |
| 技能系统 | Skills 列表、SKILL.md 读取规则 | 支持按需加载专业能力 |
| 工作区上下文 | Workspace、项目 Markdown 文件、文档链接 | 让模型理解当前工作目录和项目约束 |
| 记忆系统 | Memory Recall、MEMORY.md、每日记忆 | 支持跨会话连续性 |
| 通信系统 | Reply Tags、Messaging、群聊回复、TTS | 支持多渠道交互 |
| 运行控制 | Silent Mode、Heartbeats、Runtime | 支持后台任务、心跳任务和环境感知 |
| 安全与权限 | 沙箱、授权发送者、外部动作限制 | 限制越权访问和敏感数据泄露 |
模块化之后,提示词不再是“越长越保险”,而是变成“按场景加载最小必要信息”。
flowchart LR
A[运行时配置] --> B[Prompt Builder]
C[工具列表] --> B
D[Workspace 文件] --> B
E[Skills 元数据] --> B
F[Memory 配置] --> B
G[Channel 信息] --> B
B --> H[完整 System Prompt]
H --> I[LLM]
Markdown 驱动:把人格、规则和环境从代码里解耦
OpenClaw 很多关键信息不是写在代码里,而是放在工作区根目录的 Markdown 文件中。Markdown 的好处是:
- 对人友好,用户和开发者都能直接阅读和编辑;
- 比纯文本更适合表达结构,例如标题、列表、强调;
- 能被文件系统、Shell、Git、搜索工具自然管理;
- 可以作为 Agent 的长期配置和可演化文档。
常见文件可以这样理解:
| 文件 | 角色 | 主要内容 | 加载方式 |
|---|---|---|---|
AGENTS.md | 总纲 | 工作区规则、启动流程、记忆策略、红线、安全边界 | 启动或构建 Prompt 时注入 |
SOUL.md | 人格 | 性格、语气、价值倾向、行为边界 | 存在时注入,并要求 Agent 体现对应风格 |
IDENTITY.md | 身份卡 | 名字、类型、标志性 Emoji、头像等 | 作为外在身份信息 |
USER.md | 用户档案 | 称呼、时区、偏好、项目背景 | 用于个性化服务 |
TOOLS.md | 本地工具笔记 | 摄像头名、SSH 别名、TTS 偏好、设备名称等 | 与通用 Skill 分离,避免泄露环境信息 |
HEARTBEAT.md | 心跳任务 | 周期性检查、提醒、维护任务 | 心跳触发时读取 |
BOOTSTRAP.md | 首次启动脚本 | 初始化身份、用户信息、初始人格 | 首次启动后删除 |
BOOT.md | 启动任务 | 每次启动时要执行的短指令 | 可配合 Hook 使用 |
MEMORY.md | 长期记忆 | 高价值、长期稳定的事实和偏好 | 主会话中加载或检索 |
这里有一个重要的分离原则:共享能力和本地环境要分开。例如某个 TTS Skill 可以是通用的,但“默认音箱叫 Kitchen HomePod”“某台服务器 SSH 别名是 home-server”属于本地隐私配置,应该写进 TOOLS.md,不能混进可分享的 Skill 包。
提示词措辞:短、准、可执行
提示词不是越长越好。很多系统提示词会把同一个约束解释好几遍,结果既浪费 token,又让模型抓不住重点。OpenClaw 的提示词风格更接近操作手册:短句、强约束、少废话。
| 啰嗦写法 | 更适合 Agent 的写法 |
|---|---|
| 在群聊中,你需要根据上下文判断是否有必要回复,不应该频繁参与,否则可能干扰用户交流。 | Humans don't respond to every message. Neither should you. Quality > quantity. |
| 如果你对某个操作是否安全存在不确定性,建议你先询问用户。 | When in doubt, ask. |
| 如果用户要求你记住某件事,你应该把它存储到文件中,因为会话结束后你无法保证记住。 | No mental notes. Write it to a file. |
短提示词不是省略约束,而是把约束压缩成模型容易遵循的指令。对于 Agent 系统来说,token 应该优先留给任务上下文、工具结果和必要记忆,而不是消耗在重复解释上。
Context Engineering:在有限窗口里管理技能、历史和记忆
Prompt 解决“规则是什么”,Context 解决“模型现在应该看什么”。Agent 运行时间越长,上下文越容易膨胀,主要来源包括:
- System Prompt 本身;
- 多轮对话历史;
- 工具调用输入与输出;
- Skill 文档;
- 项目文件内容;
- 记忆召回片段。
如果所有内容都塞进上下文,会出现成本上升、延迟增加、关键信息被淹没等问题。更麻烦的是 Lost in the Middle 现象:模型对上下文开头和结尾更敏感,中间位置的信息容易被忽略。OpenClaw 用三类机制处理这个问题:Skills 渐进披露、对话压缩与工具结果修剪、双层记忆系统。
Skills:让能力无限扩展,但上下文按需加载
Agent Skills 的核心思想是渐进式披露(Progressive Disclosure)。系统不把所有技能说明一次性塞给模型,而是先给模型看技能名称和简短描述。只有当某个技能明显适用时,模型才读取对应的 SKILL.md。
flowchart TD
A[收到任务] --> B[扫描 available_skills 的名称和描述]
B --> C{是否有明确匹配的 Skill?}
C -- 无 --> D[不读取 SKILL.md]
C -- 一个 --> E[读取对应 SKILL.md]
C -- 多个 --> F[选择最具体的一个]
E --> G[按 Skill 指令执行任务]
F --> G
D --> H[使用基础工具处理]
这种设计解决了两个问题:
- 能力扩展问题:Agent 可以通过 Skill 包获得 PPT 生成、语音合成、特定云服务运维等新能力。
- 上下文爆炸问题:日常运行只加载技能目录,不加载所有技能细节。
Skill 机制也带来安全风险。因为 Skill 包可能包含脚本、依赖和工具调用逻辑,恶意 Skill 理论上可以植入后门、窃取环境变量或执行危险命令。能力市场和插件机制必须配套来源校验、签名、权限声明、沙箱执行和人工确认,不能把第三方 Skill 当成普通文档处理。
上下文压缩:把早期历史变成高密度摘要
长会话中最容易膨胀的是历史消息。OpenClaw 的压缩策略可以理解为:保留最近几轮完整对话,把更早的历史压缩成摘要。这类似开卷考试只能带十页纸,最近必考内容原样保留,早期内容整理成重点笔记。
压缩有两种触发方式:
| 触发方式 | 说明 |
|---|---|
| 手动触发 | 用户执行 /compact,也可以要求特别保留某些信息 |
| 自动触发 | 系统监控 token 用量,超过水位线后自动压缩旧历史 |
自动触发通常遵循这样的判断:
当前 token 用量 > 上下文窗口大小 - 预留缓冲区
例如上下文窗口为 200,000 token,系统预留 20,000 token 给后续交互和工具结果,当当前用量超过 180,000 token,就触发压缩。
压缩过程可以用图表示:
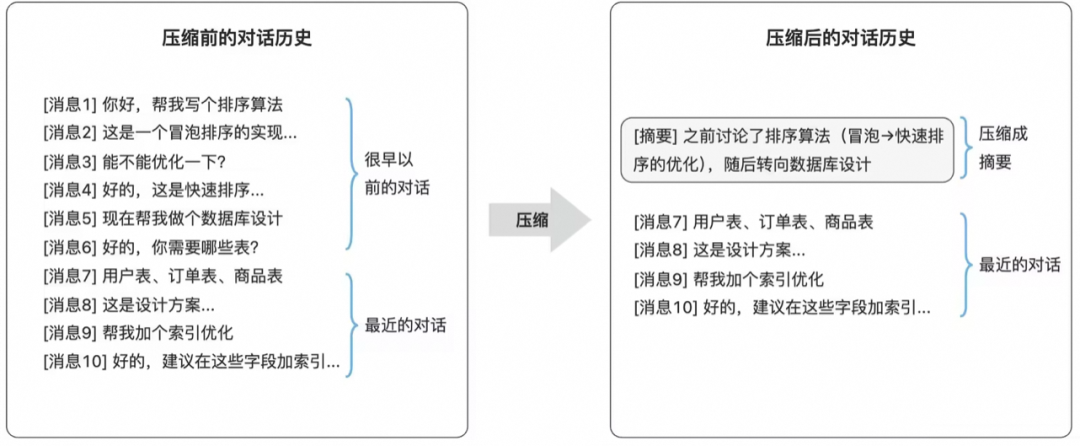
图中的关键点是:最近消息保持原样,因为它们最可能影响当前任务;旧消息不会直接删除,而是先切块、摘要,再把摘要作为历史背景继续保留。这样既释放了上下文空间,又尽量保存任务连续性。
OpenClaw 的压缩逻辑包含几个工程细节:
| 机制 | 作用 |
|---|---|
| 自适应分块 | 按 token 数把旧消息切成多个 chunk,避免单次摘要输入过大 |
| 分阶段摘要 | 先对每个 chunk 摘要,再合并成最终摘要 |
| 兜底策略 | 摘要失败时排除超大消息重试,再失败则返回默认空历史 |
| 工具结果预处理 | 摘要前移除工具输出里过长的 details 字段 |
| 超时保护 | 压缩任务有最长执行时间,避免主流程被卡住 |
| 写锁 | 压缩会话文件时防止并发写入导致数据损坏 |
| 标识符严格保留 | UUID、哈希、文件名、实例 ID 等不透明标识符必须原样保留 |
| 压缩模型可配置 | 可以用成本更低的模型专门做摘要 |
摘要时要保留的信息通常包括:
- 当前活跃任务;
- 已经做出的重要决策;
- 待办事项;
- 对用户做出的承诺;
- 文件路径、实例 ID、哈希值、UUID 等不透明标识符;
- 工具调用导致的关键结果。
标识符尤其重要。模型如果把 i-abc123 摘成“某个 ECS 实例”,后续工具调用就无法继续执行;如果把哈希值或文件名改写,排查问题会变得非常困难。
工具结果修剪:长输出保留头尾,中间截断
工具调用结果是上下文消耗大户。读取一个大文件、返回一个复杂 JSON、打印一段长日志,都可能瞬间占用数万 token。压缩适合处理历史对话,但工具结果往往需要更快、更低成本的处理方式,于是 OpenClaw 使用规则化修剪。
典型策略是保留开头和结尾,截断中间:
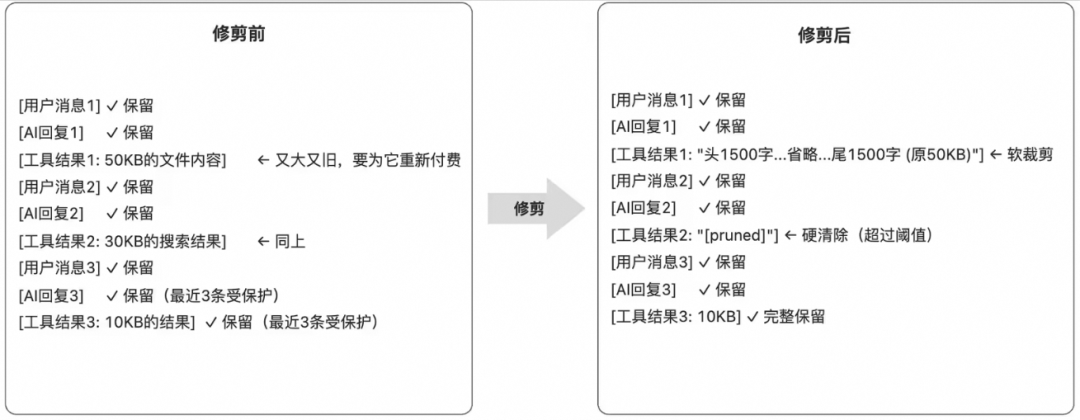
这张图表达的是一种实用经验:错误堆栈、异常名称、命令输出摘要通常在开头;最终失败原因、退出码、最后几行日志常在结尾;中间大量重复日志可以截断。对于 JSON 或 XML,头部往往包含结构定义和关键字段,也比中间重复数组更有价值。
压缩和修剪的区别很明显:
| 特性 | 压缩 Compaction | 修剪 Pruning |
|---|---|---|
| 核心操作 | 调用模型生成摘要,替换旧消息 | 用规则裁剪工具结果或旧片段 |
| 信息保留方式 | 语义保留,细节可能被概括 | 被截断部分直接丢失 |
| 成本 | 需要额外 LLM 调用 | 规则处理,成本低 |
| 适合场景 | 长对话历史太多 | 工具输出过长、日志过大、JSON 过大 |
| 风险 | 摘要遗漏或改写细节 | 中间关键信息可能被截掉 |
实际系统里两者通常配合使用:先用修剪控制单次工具结果,再用压缩管理长周期会话历史。
KV Cache 不是无限上下文的解药
很多模型服务支持 KV Cache 或 Prefix Caching。当前缀上下文相同,服务端可以复用缓存,加快推理并降低部分成本。但缓存通常有时间窗口,例如几分钟到十几分钟。窗口过期后,长上下文仍然会重新计费,并且推理延迟会明显增加。
所以,即使模型支持超长上下文和缓存,Agent 仍然需要主动压缩和修剪。长上下文不是免费的,延迟也是用户体验的一部分。
Memory:长期记忆和每日笔记分层管理
对 Agent 来说,记忆不是把所有聊天记录永久塞进提示词,而是要区分“长期稳定事实”和“可检索日常细节”。
OpenClaw 采用双层记忆:
| 层级 | 文件 | 内容 | 访问方式 |
|---|---|---|---|
| 长期记忆 | MEMORY.md | 高价值、稳定、需要长期保留的事实和偏好 | 主会话中注入或按需读取 |
| 每日笔记 | memory/YYYY-MM-DD.md | 某天发生的细节、过程日志、临时上下文 | 通过搜索和行号读取 |
可以用这个结构理解:
flowchart TB
A[当前会话] --> B{是否有值得记住的信息?}
B -- 用户明确要求记住 --> C[写入 MEMORY.md 或每日笔记]
B -- 会话结束 / 压缩触发 --> D[Memory Flush 提炼关键信息]
D --> E[长期事实写入 MEMORY.md]
D --> F[过程细节追加到 memory/YYYY-MM-DD.md]
G[用户询问过去事项] --> H[memory_search]
H --> I[BM25 文本匹配]
H --> J[Embedding 向量召回]
I --> K[候选片段]
J --> K
K --> L[memory_get 精确读取原文件行号]
MEMORY.md 适合存放不应频繁变化的内容,例如:
- 用户常用技术栈;
- 当前长期项目名称和目标;
- 明确表达过的工作偏好;
- 需要长期遵守的沟通边界;
- 关键账号或环境的非敏感说明。
每日笔记适合记录当天上下文,例如:
- 今天讨论了某个 API 的重构;
- 某次排障尝试过哪些命令;
- 某个临时 TODO;
- 一段任务过程日志。
两层记忆的差异可以整理成表:
| 特性 | MEMORY.md 长期记忆 | memory/日期.md 每日笔记 |
|---|---|---|
| 文件数量 | 一个 | 每天一个 |
| 写入方式 | 整理后编辑 | 追加为主 |
| 内容类型 | 稳定事实、长期偏好、高价值结论 | 日常过程、细节、临时上下文 |
| 注入方式 | 主会话中可被注入,通常有行数限制 | 不全量注入,通过检索访问 |
| 时间衰减 | 不衰减 | 检索权重随时间降低 |
| 适合记录 | 用户偏好、长期项目、重要原则 | 今天聊过什么、做过什么尝试 |
记忆检索不能只靠关键词,也不能只靠向量。OpenClaw 使用类似“双路召回”的思路:BM25 负责精确词匹配,Embedding 负责语义相似度,两者结合后再读取原始文件的具体行号。这样既能找到“ECS 实例 ID”这种精确对象,也能找到“上次那个部署问题”这种语义模糊的回忆。
每日笔记还有时间衰减。一个简单的衰减公式是:
衰减系数 = e^(-λ × 天数)
λ = ln(2) / 半衰期天数
默认半衰期:30 天
当半衰期为 30 天时:
| 时间 | 衰减系数 | 含义 |
|---|---|---|
| 1 天前 | 约 0.977 | 几乎不变 |
| 7 天前 | 约 0.851 | 略微降低 |
| 30 天前 | 0.5 | 权重减半 |
| 60 天前 | 0.25 | 权重剩四分之一 |
| 90 天前 | 0.125 | 权重剩八分之一 |
这不是删除旧记忆,而是在检索排序时降低旧日常细节的优先级。长期记忆不衰减,每日笔记逐渐淡出,能让 Agent 更关注近期和高价值信息。
Harness Engineering:把 Agent 放进可控运行环境
Prompt 和 Context 都发生在模型输入层面,但 Agent 真正执行任务时,还会调用工具、读写文件、执行命令、发送消息、访问网络。如果只依赖模型“自觉遵守规则”,系统很容易出问题。
Harness Engineering 关注的是模型外部的工程约束。它不只是提示模型“请小心”,而是用系统机制让危险操作被拦截、错误结果被反馈、任务流程能恢复、人类随时能接管。
可以把三类工程这样区分:
| 工程类型 | 解决的问题 | 主要手段 |
|---|---|---|
| Prompt Engineering | 模型应该遵守什么规则 | 系统提示词、角色设定、行为准则 |
| Context Engineering | 模型应该看到什么信息 | 检索、压缩、修剪、记忆、技能加载 |
| Harness Engineering | 模型如何被约束地行动 | Hook、沙箱、权限、审批、测试、状态机、评估 |
没有 Harness 的 Agent 常见问题包括:
- 写完代码就停止,不运行测试;
- 工具调用失败后在同一个错误上反复尝试;
- 删除文件、发送消息、调用外部 API 时没有确认;
- 遇到不确定参数仍然强行执行;
- 被 Prompt Injection 诱导泄露本地文件或密钥;
- 后台任务没有可观测性,出错后难以恢复。
Harness 的核心目标不是剥夺模型规划能力,而是给它装上外部约束。模型仍然可以决定下一步做什么,但必须在工具权限、执行规则、校验逻辑和人工审批范围内行动。
Workflow 和 Harness 的区别
Workflow 和 Harness 都能提升可控性,但主导权不同。
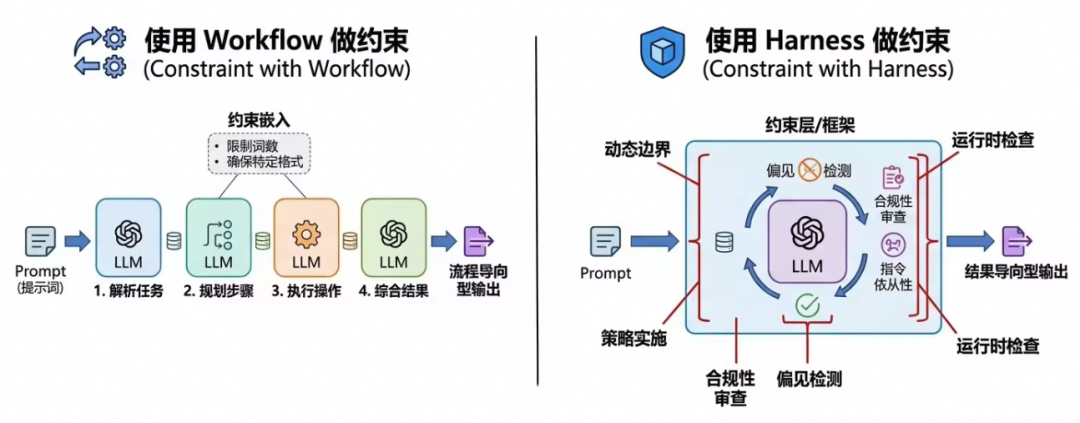
图中的差异可以归纳为:Workflow 更像预先写好的流程图,大模型只是流程里的一个节点;Harness 更像一套运行边界和反馈机制,Agent 仍然有自主规划空间,但行动会被校验、约束和纠偏。
| 维度 | Workflow | Harness |
|---|---|---|
| 主导权 | 人写好的流程主导 | Agent 自主规划,系统外部约束 |
| 执行路径 | 固定步骤较多 | 动态路径较多 |
| 适合任务 | 规则明确、分支有限、结果格式稳定 | 长周期、开放式、多工具、多轮迭代任务 |
| 优点 | 确定性高、易调试、速度快 | 灵活性高、能处理未知分支、能自我修复 |
| 缺点 | 遇到未知情况容易断裂 | 工程复杂度更高,需要监控和护栏 |
| 模型角色 | 流程节点 | 规划者和执行者 |
企业系统里不需要二选一。稳定业务流程可以用 Workflow,开放式复杂任务可以用 Harness,关键节点再用 Workflow 固化。例如“创建云资源”可以由 Agent 收集信息和排查错误,但真正下单前必须进入固定审批流程。
Hook:在 Agent 生命周期插入校验和纠偏
OpenClaw 的 Hook 系统是典型 Harness 能力。Hook 允许开发者在 Agent 运行关键节点插入自定义逻辑,例如构建 Prompt 前注入上下文、工具调用前校验参数、工具调用后处理结果。
| Hook 名称 | 触发时机 | 典型用途 |
|---|---|---|
before_prompt_build | 构建提示词之前 | 注入业务上下文、用户权限、环境状态 |
before_tool_call | 执行工具之前 | 参数校验、权限检查、危险命令拦截 |
after_tool_call | 工具执行之后 | 结果清洗、错误分类、追加诊断信息 |
before_compaction | 上下文压缩之前 | 标记必须保留的信息 |
after_compaction | 上下文压缩之后 | 检查摘要是否遗漏关键标识符 |
message_received | 收到消息时 | 消息预处理、渠道鉴权、敏感信息识别 |
message_sending | 发送消息前 | 防泄露检查、格式转换、人工审批 |
一个云服务运维 Agent 很容易混淆不同资源 ID。例如 ECS 实例 ID 可能以 i- 开头,某些轻量应用服务器 ID 可能是 32 位字母数字组合。如果没有工具调用前校验,模型传错参数后只能等 API 报错,再由模型尝试修复,容易浪费轮次甚至进入循环。
可以在 before_tool_call 中做参数拦截:
type HookResult =
| { action: "continue" }
| { action: "reject"; message: string };
export async function beforeToolCall(event: {
toolName: string;
args: Record<string, unknown>;
}): Promise<HookResult> {
if (event.toolName === "ecs.rebootInstance") {
const instanceId = String(event.args.instanceId ?? "");
if (!/^i-[a-zA-Z0-9]+$/.test(instanceId)) {
return {
action: "reject",
message:
"instanceId 格式不符合 ECS 实例 ID 规则。ECS 实例 ID 应以 i- 开头,请重新确认资源类型和参数。",
};
}
}
return { action: "continue" };
}
这类校验不应该完全依赖 Prompt,因为模型可能忘记规则,也可能被复杂上下文干扰。Hook 的优势是强制执行:只要工具调用经过这个入口,就一定会被校验。
AI Coding 场景:从“写完即止”变成“写完必测”
Harness 在代码生成任务里非常有价值。裸 Agent 常见行为是:生成代码、解释修改、宣布完成。但代码是否能运行、测试是否通过、Lint 是否报错,都不一定检查。
一个更可靠的执行链路应该这样设计:
flowchart TD
A[生成或修改代码] --> B[自动运行格式化 / Lint]
B --> C{是否通过?}
C -- 否 --> D[把错误日志反馈给模型]
D --> A
C -- 是 --> E[运行单元测试]
E --> F{是否通过?}
F -- 否 --> G[反馈失败用例和堆栈]
G --> A
F -- 是 --> H[生成变更摘要]
H --> I[等待用户验收或提交]
这条链路里,模型仍然负责修代码,但是否进入下一步不由模型自己宣布,而由外部测试结果决定。这样可以明显减少“看起来完成,实际不能运行”的交付。
安全沙箱:把权限边界做在系统层
OpenClaw 的能力扩展到本地文件、命令执行和网络访问后,安全边界就不能只写在提示词里。一个更稳妥的 Agent 运行环境至少需要三层沙箱:
| 层级 | 控制对象 | 典型策略 |
|---|---|---|
| 文件系统沙箱 | 读写路径 | 限制在 Workspace 内,禁止访问系统根目录和敏感目录 |
| 命令执行沙箱 | Shell 命令 | 白名单、黑名单、Ask 模式、危险命令拦截、只读命令豁免 |
| 网络访问沙箱 | 外部连接 | 域名白名单、出站流量控制、防止敏感数据外传 |
底层还需要操作系统最小权限原则兜底:Agent 进程不应该拥有超过任务所需的权限,插件和工具最好独立进程运行,避免一个工具被攻破后直接获得整个系统控制权。
安全护栏要覆盖几类风险:
- Prompt Injection:外部网页或文件诱导模型忽略系统规则;
- 越权调用:模型调用未授权工具或访问不该访问的资源;
- 敏感泄露:API Key、密码、私有文件被发到外部渠道;
- 破坏性修改:删除文件、覆盖配置、执行危险命令;
- 供应链风险:第三方 Skill 包含恶意脚本或依赖。
关键原则是:安全规则能放在系统层,就不要只放在提示词里。提示词是软约束,沙箱、权限和审批才是硬边界。
人在环路:高风险动作必须能暂停和接管
Agent 越接近真实业务,越需要人在环路(Human-in-the-Loop)。外部发送消息、删除文件、修改生产配置、购买资源、执行高成本操作,都应该进入确认流程。
一个简单的审批策略可以这样设计:
| 操作类型 | 默认策略 |
|---|---|
| 读取 Workspace 内文件 | 允许 |
| 整理本地笔记、生成草稿 | 允许 |
执行只读命令,如 ls、cat、git status | 允许或低风险提示 |
| 修改文件 | 根据目录和文件类型决定是否确认 |
| 删除文件 | 必须确认,优先使用可恢复删除 |
| 发送邮件、群消息、公开发布 | 必须确认 |
| 调用生产 API、购买资源、重启实例 | 必须确认或走审批流 |
| 访问未知域名 | 默认拒绝或确认 |
人在环路不是为了让用户每一步都点确认,而是把确认集中到真正有外部影响或不可逆的动作上。低风险内部动作放开,高风险外部动作收紧,Agent 才既能工作,又不会失控。
心跳和启动任务:把周期性行为变成规定动作
HEARTBEAT.md 和 BOOT.md 体现了另一类 Harness:系统主动触发的规定动作。
BOOT.md适合放启动时要执行的短任务,例如检查工作区状态、读取必要配置、恢复后台任务。HEARTBEAT.md适合放周期性任务,例如检查日历、整理记忆、查看项目状态、执行轻量巡检。
心跳机制要控制频率和范围,否则会变成 token 消耗黑洞。一个合理的心跳文件应该短小,只放当前确实需要周期检查的事项,并记录上次检查时间,避免每次唤醒都重复做同样的事。
把 OpenClaw 的设计迁移到自己的 Agent 系统
OpenClaw 的个人助理形态不一定适合直接搬进企业生产环境。企业场景通常有更严格的数据边界、权限模型、审计要求、响应时延和稳定性指标。真正可迁移的是设计方法。
可以从四张清单开始设计自己的 Agent。
1. Prompt 模块清单
| 模块 | 是否需要 | 设计建议 |
|---|---|---|
| 身份与目标 | 必需 | 一句话说明 Agent 角色和目标 |
| 行为准则 | 必需 | 写成短规则,避免长篇解释 |
| 工具清单 | 必需 | 工具名、用途、参数要求要准确 |
| 安全边界 | 必需 | 外部动作、敏感数据、破坏性操作要明确 |
| 工作区信息 | 按需 | 注入当前目录、项目规则、文档入口 |
| 用户偏好 | 按需 | 只注入和任务相关的信息 |
| 技能说明 | 按需 | 先注入名称和描述,再按需读取详情 |
| 运行时信息 | 必需 | 渠道、模型、系统时间、权限状态等 |
2. Context 预算清单
| 上下文来源 | 管理方式 |
|---|---|
| System Prompt | 模块化、按模式加载 |
| 历史对话 | 最近保留,旧历史压缩 |
| 工具结果 | 长输出修剪,必要时让模型按行读取 |
| 项目文件 | 不全量注入,通过检索或明确文件读取 |
| Skills | 渐进式披露 |
| 长期记忆 | 精简高价值内容,避免流水账 |
| 每日记忆 | 切片、索引、检索、时间衰减 |
3. Memory 写入规则
| 情况 | 写入位置 |
|---|---|
| 用户明确说“记住” | 优先写长期记忆或指定文件 |
| 长期偏好、稳定事实 | MEMORY.md |
| 当天任务过程 | memory/YYYY-MM-DD.md |
| 工具使用经验 | TOOLS.md 或对应 Skill 文档 |
| 失败教训和项目规则 | AGENTS.md 或项目规则文件 |
| 敏感信息 | 默认不写,除非用户明确要求且存储位置安全 |
4. Harness 约束清单
| 风险点 | 外部约束 |
|---|---|
| 参数错误 | before_tool_call 校验 |
| 工具失败循环 | 最大重试次数、错误分类、切换策略 |
| 代码不可运行 | 强制测试、Lint、构建检查 |
| 删除或覆盖文件 | 人工确认、可恢复删除 |
| 外部消息发送 | 发送前审批 |
| 访问敏感目录 | 文件系统沙箱 |
| 访问未知网站 | 网络白名单 |
| 第三方插件风险 | 签名、来源校验、权限声明、沙箱执行 |
| 记忆泄露 | 群聊不加载私人长期记忆,回复前做敏感检查 |
可落地的结论
OpenClaw 的价值不是某一个炫目的功能,而是一组工程取舍:
- System Prompt 要模块化、动态组装,不要写成不可维护的大段文本;
- Markdown 文件适合作为 Agent 的人格、规则、环境和记忆载体;
- Skills 要按需披露,能力可以扩展,但上下文不能无限膨胀;
- 长会话必须有压缩,长工具结果必须有修剪;
- 记忆要分层,长期事实和每日细节不能混在一起;
- Harness 要做成系统级约束,不能只靠模型自觉;
- 高风险动作必须有人在环路;
- 企业落地时,优先迁移方法论,而不是复制个人助理形态。
一个好用的 Agent 系统,本质上是在“模型能力”和“工程约束”之间找平衡。Prompt 让模型理解任务,Context 让模型拿到信息,Harness 让模型在安全边界内行动。三者组合起来,Agent 才能从一次性问答工具,变成能够长周期执行复杂任务的工程系统。