Hermes Agent 是 Nous Research 推出的开源 Agent(智能体)项目。它和普通聊天机器人最大的区别,不是多接了几个工具,而是能把任务过程中的经验保存下来,变成后续可复用的 Skills,并在不断使用中修正这些 Skills。
普通 AI(人工智能)助手通常是“一次会话解决一次问题”。会话结束后,除非额外做记忆系统,否则它不会稳定记住用户偏好、项目结构、操作习惯和任务复盘。Hermes Agent 试图解决的正是这个问题:让 Agent 能长期运行,跨会话记忆上下文,把重复任务越做越熟。
它适合部署在本地机器或云端环境中,并接入 Telegram、Slack、Discord、WhatsApp、iMessage 等聊天入口。用户不需要打开单独的工作台,在常用聊天窗口里发出自然语言指令,Agent 就可以在后台调用工具、拆解任务、执行计划并沉淀经验。
相关入口:
- Hermes Agent 官网:
hermes-agent.nousresearch.com - GitHub 仓库:
github.com/NousResearch/hermes-agent - MiniMax M2.7 接入说明:
platform.minimaxi.com/docs/token-plan/hermes-agent
Hermes Agent 解决的核心问题
长期运行的 Agent 工作流通常会遇到四类麻烦:
| 问题 | 普通聊天模型的表现 | Hermes Agent 的处理思路 |
|---|---|---|
| 经验无法复用 | 每次都重新解释任务背景和操作步骤 | 将成功经验整理成 Skills,后续按需加载 |
| 跨会话上下文断裂 | 新会话不知道旧任务、偏好和项目状态 | 使用持久化记忆保存长期信息 |
| 定期任务依赖人工触发 | 每天、每周的例行任务需要手动提醒 | 用自然语言定义定时任务,让 Agent 自动执行 |
| 复杂任务执行慢 | 单个 Agent 串行处理所有子任务 | 多个子代理并行工作,提高复杂任务吞吐 |
可以把 Hermes Agent 理解成一个“长期在线的任务运行时”,它不只负责回答问题,还负责维护记忆、组织 Skills、调度工具和执行周期性任务。
整体结构可以抽象成这样:
flowchart LR
U[用户<br/>聊天入口] --> C[Telegram / Slack / Discord 等]
C --> R[Hermes Agent Runtime]
R --> P[任务规划与指令理解]
P --> T[工具调用]
P --> M[(持久化记忆)]
P --> S[(Skills 文档库)]
P --> A[子代理并行执行]
P --> Q[定时任务调度]
T --> E[外部系统<br/>GitHub / 浏览器 / API / 文件系统]
A --> T
Q --> P
P --> L[任务复盘与经验提炼]
L --> S
L --> M
R --> C
C --> U
这里有两个关键存储:记忆和 Skills。记忆偏向“事实”和“偏好”,例如用户关注哪些领域、某个代码仓库的部署方式、团队常用命名规范;Skills 偏向“可重复执行的方法”,例如如何生成日报、如何处理某类 Issue、如何检查某个服务的健康状态。
自我进化的关键:任务执行后生成 Skills
Hermes Agent 的学习闭环不是训练模型权重,而是在应用层沉淀可复用操作经验。一次复杂任务完成后,Agent 会分析执行过程,把其中稳定有效的步骤整理成 Skill 文档。后续遇到类似任务时,它不需要从零推理,而是先检索已有 Skills,再结合当前上下文执行。
这张图展示了 Hermes Agent 的学习闭环:任务执行、经验提炼、Skills 保存、后续加载与再改进构成一个持续循环。
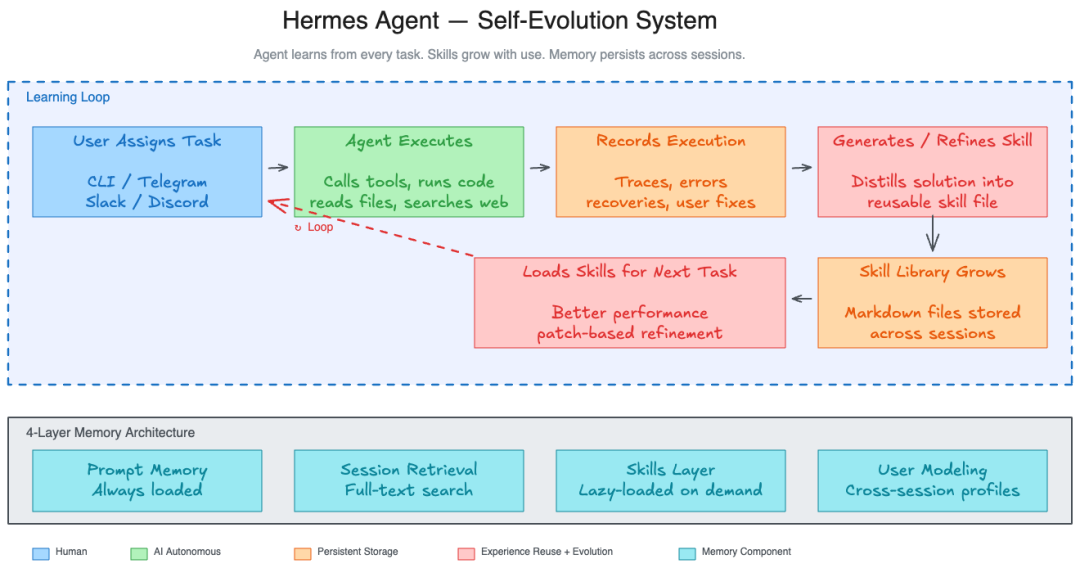
图里的核心逻辑可以拆成五步:
- 用户发出任务,例如“每天早上汇总 AI 行业热点并推送到 Telegram”。
- Agent 拆解任务,调用搜索、浏览器、消息推送等工具完成执行。
- 任务结束后,Agent 复盘哪些步骤有效,哪些约束需要保留。
- 复盘结果被写成 Skill,保存到 Skills 文档库。
- 后续相似任务触发时,Agent 加载对应 Skill,并根据新的反馈继续修订。
用流程图表示更直观:
flowchart TD
A[接收任务] --> B[规划步骤]
B --> C[调用工具执行]
C --> D[得到结果与反馈]
D --> E{是否有可复用经验}
E -- 是 --> F[提炼 Skill]
F --> G[(Skills 文档库)]
E -- 否 --> H[仅记录必要上下文]
H --> I[(持久化记忆)]
G --> J[后续任务检索]
I --> J
J --> K[加载相关 Skill 和记忆]
K --> B
这种设计有一个重要好处:Agent 的能力增长不依赖每次重新训练模型。只要任务轨迹、复盘结果和 Skills 管理做得好,系统就能在使用过程中积累“工作方法”。
Skill 到底是什么
Skill 可以理解为一份面向 Agent 的操作手册。它不是普通笔记,也不是简单提示词,而是对某类任务的稳定执行方法进行结构化描述。
一个质量较高的 Skill 通常包含这些内容:
| 组成部分 | 作用 |
|---|---|
| 名称 | 让 Agent 知道这个 Skill 解决什么任务 |
| 触发条件 | 描述什么情况下应该加载它 |
| 输入信息 | 当前任务需要哪些参数、文件或上下文 |
| 执行步骤 | 具体怎么拆任务、调用哪些工具 |
| 验证方式 | 如何判断任务完成得是否正确 |
| 注意事项 | 避免重复踩坑,例如 API 限流、格式约束、权限要求 |
| 可更新区域 | 允许 Agent 根据新反馈修订经验 |
一个用于生成日报的 Skill 可以写成类似这样的结构:
# Skill: 生成 AI 行业日报
## 适用场景
当用户要求定期汇总 AI 行业新闻、论文、开源项目或产品动态时使用。
## 输入
- 时间范围,例如最近 24 小时
- 关注领域,例如大模型、Agent、推理加速、开源模型
- 推送渠道,例如 Telegram
## 执行步骤
1. 从指定信息源抓取候选内容。
2. 去重并过滤低相关信息。
3. 按领域分组,每组保留 3~5 条高价值内容。
4. 为每条内容生成一句摘要,避免夸张评价。
5. 生成适合聊天工具阅读的简报格式。
6. 调用消息推送工具发送结果。
## 验证
- 每条内容必须包含来源或链接。
- 摘要不能超过指定字数。
- 不推送重复内容。
- 如果信息源不可用,需要说明失败原因。
## 更新规则
如果用户连续忽略某类主题,降低该主题优先级;
如果用户明确收藏某类内容,提高相似内容权重。
这种 Skill 的价值在于,它把“做过一次的复杂任务”变成了“以后可以稳定复用的工作流”。随着任务次数增加,Skill 里会沉淀越来越多具体约束,例如用户喜欢的摘要长度、常用信息源、哪些内容应该过滤。
持久化记忆让 Agent 跨会话工作
Skills 解决的是“怎么做”的问题,持久化记忆解决的是“记住什么”的问题。
例如在技术开发场景中,一个长期运行的编程 Agent 需要记住:
- 代码仓库的目录结构;
- 后端服务、前端服务、任务队列分别在哪里;
- 项目采用什么代码风格;
- 测试命令和部署流程是什么;
- 哪些文件通常不能直接修改;
- 用户习惯先看实现方案还是直接要补丁。
这些信息如果每次都重新输入,Agent 的使用成本会很高;如果全部塞进提示词,又会浪费上下文窗口。持久化记忆更适合保存长期稳定的信息,并在任务相关时加载。
记忆和 Skills 的区别可以这样理解:
| 类型 | 保存内容 | 示例 |
|---|---|---|
| 持久化记忆 | 事实、偏好、长期上下文 | “用户关注 Agent 工程化”“仓库使用 pnpm”“部署脚本在 scripts/deploy.sh” |
| Skills | 可复用任务方法 | “如何生成日报”“如何处理 GitHub Issue”“如何检查服务状态” |
两者配合后,Agent 不只知道用户是谁、项目是什么,还知道某类任务应该怎么做。
自然语言定时任务
Hermes Agent 支持用自然语言定义定时任务,这对长期运行很关键。很多自动化需求并不是一次性任务,而是周期性任务:
- 每天早上推送行业简报;
- 每周汇总 GitHub Issues;
- 每隔一段时间检查服务状态;
- 每天收集某个关键词的新论文;
- 每周生成项目进展报告。
用户可以用接近日常表达的方式描述任务:
每天早上 9 点,汇总过去 24 小时内大模型和 Agent 方向的重要新闻,
过滤重复内容,通过 Telegram 发给我。摘要控制在 800 字以内。
Agent 接到这种任务后,需要做的不只是设置闹钟,还要保存任务目标、执行时间、输出格式、推送渠道和失败处理方式。下一次执行时,它还要结合已有记忆和 Skills,避免重复推送用户不感兴趣的内容。
定时任务的运行链路可以抽象为:
sequenceDiagram
participant User as 用户
participant Agent as Hermes Agent
participant Scheduler as 定时调度器
participant Tools as 外部工具
participant Memory as 记忆与 Skills
User->>Agent: 用自然语言创建周期任务
Agent->>Scheduler: 保存触发时间和任务定义
Scheduler-->>Agent: 到时间触发
Agent->>Memory: 加载相关记忆和 Skills
Agent->>Tools: 搜索、抓取、整理、推送
Tools-->>Agent: 返回执行结果
Agent->>Memory: 记录反馈并更新经验
Agent-->>User: 推送结果
这个链路对底层模型的要求比普通问答高得多,因为模型要长期稳定理解任务定义,并且在多次执行中保持格式和约束一致。
多个子代理并行处理复杂任务
复杂任务往往可以拆成多个相对独立的子任务。比如“为一个开源项目搭建运行状态 Dashboard(仪表盘)”,可能包含这些工作:
- 阅读项目结构;
- 找到服务启动方式;
- 设计监控指标;
- 编写数据采集脚本;
- 搭建前端页面;
- 写部署说明;
- 检查运行结果。
如果所有事情都让一个 Agent 串行完成,耗时会很长,而且上下文容易膨胀。子代理并行机制可以把任务分发出去,每个子代理处理一部分,再由主 Agent 汇总。
flowchart TD
A[主 Agent 接收复杂任务] --> B[拆分子任务]
B --> C1[子代理 1<br/>阅读代码结构]
B --> C2[子代理 2<br/>设计监控指标]
B --> C3[子代理 3<br/>编写脚本]
B --> C4[子代理 4<br/>生成文档]
C1 --> D[汇总结果]
C2 --> D
C3 --> D
C4 --> D
D --> E[主 Agent 检查一致性]
E --> F[调用工具验证]
F --> G[输出最终结果]
并行不是简单地多开几个模型请求。主 Agent 必须能清楚定义每个子任务的边界,否则多个子代理可能重复工作,甚至产生互相冲突的结果。这里同样依赖模型的复杂指令遵循能力。
典型使用场景
Hermes Agent 的能力更适合长期任务,而不是一次性闲聊。几个典型场景如下。
日常效率:自动化报告和消息推送
用户可以让 Agent 定期从多个平台收集 AI 热点,去重、筛选、摘要后推送到 Telegram。运行一段时间后,Agent 会逐渐记录用户关注哪些方向,比如 Agent 工程、推理加速、开源模型,推送内容会越来越贴近实际偏好。
技术开发:跨会话编程伙伴
在开发场景中,Agent 可以记住代码库结构、编码规范和部署流水线。它还能监控 GitHub Issues 和 PR(Pull Request,拉取请求),在发现新任务时尝试分类、摘要、分派或生成修复建议。
这类场景的重点不是“写一段代码”,而是长期理解一个项目。Agent 必须知道哪些目录重要、哪些测试必须跑、哪些改动有风险。
长程创作:大型内容生产流程
长篇小说、课程大纲、技术手册这类任务需要长期一致性。Agent 可以保存世界观、人物设定、章节规划、排版要求,并把“如何续写”“如何校对”“如何生成封面提示词”等流程沉淀成 Skills。
更进阶的自训练实验
有开发者会让 Agent 生成合成样本,再用这些样本更新本地模型的 LoRA(Low-Rank Adaptation,低秩适配)模块。这已经超出了普通应用层自动化,属于让 Agent 参与模型适配流程的实验方向。这里的风险也更高,需要严格评估数据质量和训练结果,不能只依赖 Agent 自己判断。
为什么底层模型很关键
Hermes Agent 的上层机制再完整,也离不开底层模型的稳定表现。长期运行的 Agent 和普通聊天对模型的要求不同,尤其体现在工具调用、复杂指令遵循、成本和响应速度上。
| 能力 | 对 Agent 的影响 | 如果能力不足会怎样 |
|---|---|---|
| 工具调用准确度 | 决定 Agent 能否正确选择工具、填参数、解析返回值 | 调错工具、参数缺失、任务中断 |
| 复杂指令遵循 | 决定 Agent 能否长期遵守格式、约束和流程 | 定时报告格式漂移,子任务边界混乱 |
| 长程稳定性 | 决定多步骤任务能否坚持到完成 | 中途忘记目标,重复执行,遗漏检查 |
| 响应速度 | 影响多代理并行和高频任务的体验 | 调度慢,任务堆积 |
| 运行成本 | 决定 Agent 能否 24 小时在线 | 高频任务费用不可控 |
| Agent Harness 适配 | 决定模型在 Agent 框架内是否顺手 | 工具协议、消息格式、调用链路不稳定 |
Agent Harness 可以理解为 Agent 运行框架中的测试和适配环境,它会检查模型在真实 Agent 链路里的表现,而不只是看单轮问答分数。对 Hermes Agent 这种工具密集型系统来说,Harness 适配比单纯聊天能力更重要。
MiniMax M2.7 在 Hermes Agent 中的角色
MiniMax M2 系列的优化方向集中在 Agent 场景所需的几个能力上:工具调用、复杂 Skills 遵循、Agent Harness 适配、响应速度和成本控制。M2.7 在复杂 Skills 遵循上继续加强,这正好对应 Hermes Agent 的核心机制。
Hermes Agent 的自我进化发生在应用层:任务轨迹被复盘成 Skills,后续任务再加载 Skills。MiniMax M2.7 的迭代发生在模型层:围绕 Agent 任务中的失败样本、工具调用表现和复杂指令遵循能力持续改进。
这张图描述的是 M2.7 的模型迭代机制,重点在于模型并不是只面向单轮聊天做优化,而是围绕 Agent 工作流中的真实执行链路进行评估和更新。
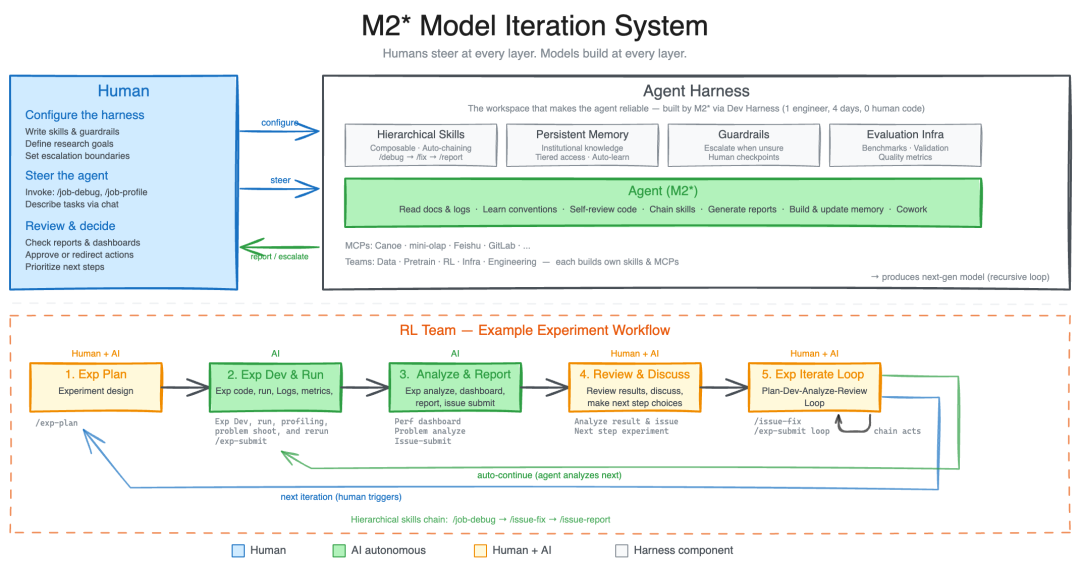
可以把这个机制理解成一个模型层的闭环:
flowchart LR
A[Agent 任务轨迹] --> B[失败案例与高价值样本分析]
B --> C[构造评测与训练数据]
C --> D[模型训练与对齐]
D --> E[Agent Harness 回归测试]
E --> F{是否满足工具调用和 Skills 遵循要求}
F -- 是 --> G[上线到 Agent 场景]
F -- 否 --> B
G --> A
Hermes Agent 在应用层积累 Skills,M2.7 在模型层改进工具调用和指令遵循。两个闭环结合后,Agent 的使用体验会更稳定:上层工作流减少重复摸索,底层模型减少执行偏差。
适合和不适合的场景
Hermes Agent 更像一个长期自动化工作伙伴,而不是所有任务都必须使用的通用入口。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 定期信息汇总 | 适合 | 任务重复、格式稳定,适合沉淀 Skills |
| GitHub 仓库监控 | 适合 | 需要跨会话记住项目结构和处理习惯 |
| 长期研究跟踪 | 适合 | 需要持续收集资料、更新偏好和结论 |
| 多步骤开发辅助 | 适合 | 可拆分子任务,并能复用项目经验 |
| 一次性闲聊 | 不太适合 | 普通聊天模型即可完成,长期记忆价值不大 |
| 强实时交易决策 | 谨慎 | 自动化执行风险高,需要额外风控和人工审核 |
| 高权限生产操作 | 谨慎 | Agent 误调用工具可能造成线上事故,需要权限隔离 |
| 需要严格法律、医疗判断的任务 | 不适合直接自动化 | 必须有人类专家审核,不能交给 Agent 独立决策 |
长期运行的 Agent 最怕权限过大、验证不足。让 Agent 读数据和生成建议是一回事,让它直接修改生产环境、执行资金操作或发出不可撤销指令,是另一回事。
上手时的工程配置思路
Hermes Agent 可以自托管,适合放在本地电脑、个人服务器或云主机上运行。实际落地时需要关注几个配置点。
1. 选择运行环境
本地运行适合个人工作流,优点是调试方便;云端运行适合长期在线任务,优点是不依赖个人电脑开机。
| 部署位置 | 适合场景 | 注意事项 |
|---|---|---|
| 本地电脑 | 个人开发、临时实验 | 电脑关机后任务无法持续运行 |
| 云服务器 | 定时任务、长期监控 | 需要管理日志、密钥和权限 |
| 私有环境 | 代码仓库、内部数据处理 | 需要限制外部网络和工具访问 |
2. 接入模型
在 Hermes Agent 中使用 MiniMax M2.7,需要按照 MiniMax Token Plan 和 Hermes Agent 的模型接入说明配置模型供应商、密钥和模型名称。不要把密钥写进仓库,建议使用环境变量或密钥管理服务。
配置可以按这个思路检查:
模型供应商:MiniMax
模型版本:M2.7
认证方式:API Key
使用位置:Hermes Agent 模型配置
重点验证:
- 能否正常响应
- 能否稳定进行工具调用
- 是否遵守 Skills 中的格式和步骤
- 高频任务成本是否可接受
3. 连接聊天入口
选择常用聊天工具作为入口,例如 Telegram、Slack 或 Discord。聊天入口的价值在于降低触发成本,用户不需要打开 Agent 控制台,直接在熟悉的对话窗口里下达任务。
4. 配置工具权限
Agent 常见工具包括:
- 浏览器或网页抓取工具;
- GitHub API(应用程序编程接口);
- 文件系统读写;
- 消息推送;
- 数据库查询;
- 部署脚本;
- 自定义内部 API。
权限应该按最小化原则配置。比如只需要读 GitHub Issues,就不要给仓库写权限;只需要生成报告,就不要给生产数据库删除权限。
5. 明确定义 Skills 存储和记忆边界
Skills 和记忆不能无限增长。运行一段时间后,需要清理重复、过时或错误的内容。比较稳妥的做法是:
- 重要 Skills 允许人工审核;
- 高风险任务的 Skills 不允许自动改写;
- 记忆中保存事实和偏好,避免保存敏感凭证;
- 让 Agent 在更新关键 Skill 时说明改动原因。
6. 从低风险任务开始
适合起步的任务有:
每天 9 点汇总过去 24 小时的 AI Agent 开源项目动态,
按项目名称、核心变化、链接三列输出,通过 Telegram 推送。
每天下午检查指定 GitHub 仓库的新 Issues,
把 bug、feature request、question 三类分别汇总,不要自动回复。
每周五生成一次项目周报,
内容包括已关闭 Issues、新增 PR、未解决阻塞项和下周建议。
这些任务有明确输入、明确输出、低破坏性,也容易观察 Agent 是否真的在学习用户偏好。
使用 Hermes Agent 时容易踩的坑
Skill 过于宽泛
如果一个 Skill 写成“帮用户完成开发任务”,几乎没有复用价值。好的 Skill 应该面向具体任务,例如“处理 Node.js 项目依赖升级 PR”或“生成 Agent 领域日报”。
记忆污染
Agent 可能把一次性的上下文误认为长期偏好。比如用户临时要求“这次报告短一点”,不代表所有报告都要短。持久化记忆需要区分“临时任务要求”和“稳定偏好”。
工具权限过大
Agent 可以调用工具不等于应该拥有所有权限。文件删除、生产部署、资金交易、外部消息群发都应该有人工确认或沙箱限制。
定时任务缺少失败处理
定时任务不能只定义“什么时候做什么”,还要定义失败时怎么办:
如果抓取失败,不要编造内容。
请发送失败原因、失败时间和需要人工处理的步骤。
多代理并行导致结果冲突
并行子代理需要清晰边界。让多个子代理同时修改同一批文件,很容易产生冲突。主 Agent 应该负责合并、检查和验证,而不是简单拼接结果。
一个可落地的长期 Agent 工作流
一个相对稳妥的 Hermes Agent 工作流可以按这样的方式组织:
flowchart TD
A[低风险周期任务] --> B[观察输出质量]
B --> C[生成初版 Skill]
C --> D[人工检查 Skill]
D --> E[允许 Agent 后续加载]
E --> F[收集用户反馈]
F --> G{是否需要更新 Skill}
G -- 是 --> H[修订 Skill 并记录原因]
H --> E
G -- 否 --> I[继续运行]
这个流程的重点是控制增长速度。Agent 可以自我改进,但关键 Skills 最好保留可审计记录。这样既能利用自动化带来的积累,又能避免错误经验被长期复用。
Hermes Agent 的核心价值在于把 Agent 从“一次性问答工具”推进到“长期任务系统”。它通过 Skills 保存做事方法,通过持久化记忆保存长期上下文,通过定时任务和多代理机制执行更复杂的工作流。MiniMax M2.7 这类面向 Agent 场景优化的模型,则负责提供稳定的工具调用、复杂指令遵循和可持续运行的成本结构。两者结合后,长期在线、持续学习的个人或团队 Agent 才更接近工程化落地。