OpenClaw 的定位不是普通聊天机器人,而是一个面向 AI Agent(智能体)的运行系统。
大语言模型负责“想”,OpenClaw 负责让它“长期在线、接收任务、调用工具、执行动作、保存上下文”。如果只看模型能力,它不一定比 Claude Code、Codex 这类工具更强;但如果看长期运行、多平台接入、主动触发任务这些能力,OpenClaw 的工程设计就很有代表性。
它的核心结构可以拆成三块:
- Agent Loop:负责推理、规划、决定下一步动作。
- Tools:负责执行文件操作、命令运行、网页访问、外部 API(应用程序编程接口)调用等动作。
- Gateway:负责让 Agent 持续在线,接入外部消息平台,管理会话、队列、定时任务和状态恢复。
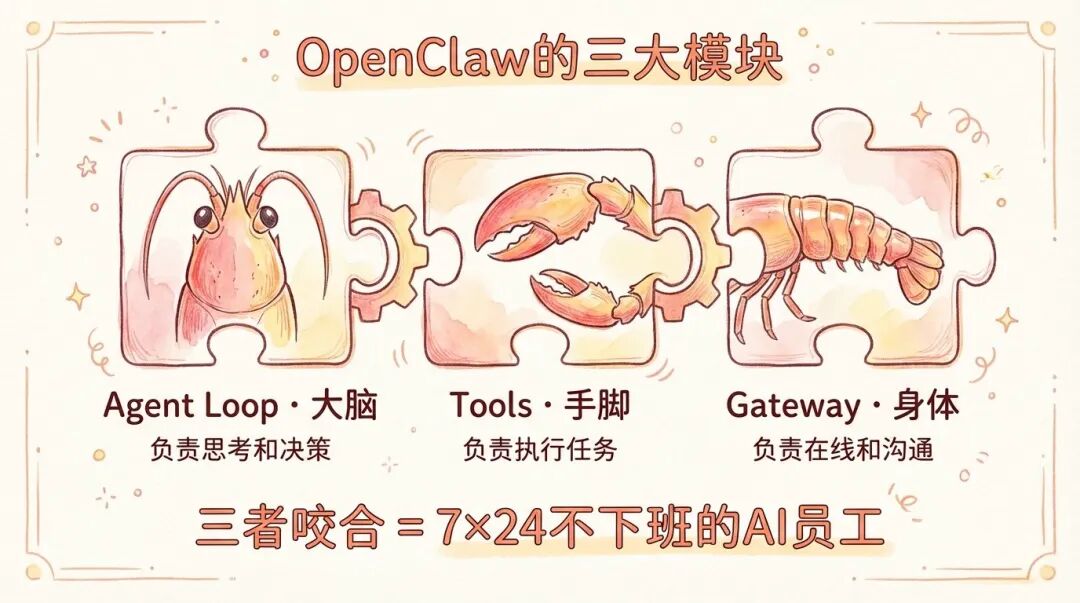
这张架构图的重点是三层职责分离:Agent Loop 像大脑,Tools 像手脚,Gateway 像身体和神经系统。只有三者配合起来,AI 才不只是一个“问一句答一句”的模型,而是能被消息平台唤醒、能执行任务、能长期保存状态的在线 Agent。
用一张流程图表示,OpenClaw 的典型工作方式大致是这样:
flowchart LR
U[用户或定时任务] --> C[消息渠道<br/>飞书 / Telegram / 钉钉等]
C --> G[Gateway<br/>消息适配 / 会话管理 / 队列控制]
G --> L[Agent Loop<br/>思考 / 规划 / 决策]
L --> T[Tools<br/>文件 / 命令 / 浏览器 / API / Skills]
T --> L
L --> G
G --> C
C --> U
为什么 OpenClaw 容易形成传播
OpenClaw 的吸引力主要来自两个因素叠加。
| 因素 | 具体含义 | 带来的结果 |
|---|---|---|
| 长期运行的 Agent 架构 | 不只依赖大语言模型,还提供 Gateway、会话、队列、任务调度、状态恢复等运行设施 | AI 可以像一个在线服务一样持续接收任务,而不是只在终端里临时执行 |
| 开源 | 代码、数据流、工具接入方式都可以检查和修改 | 用户可以自部署、改造工具、接入自己的平台,也更容易形成社区生态 |
开源尤其重要。AI Agent 往往会接触文件、账号、内部文档、任务记录和第三方服务密钥,如果所有数据都进入一个黑盒服务,很多团队很难放心使用。OpenClaw 允许用户部署在自己的环境里,至少可以把数据、权限和日志控制在可管理范围内。
另外,Agent 系统的能力很依赖工具生态。工具越多,能做的事情越多;Skills 越丰富,处理任务时越接近人类工作流。开源社区可以不断补充工具适配器、任务模板和平台集成,让系统能力持续扩展。
Agent Loop:让 AI 一步一步把任务做完
Agent Loop 是 AI Agent 的基本工作机制。它不是一次性生成答案,而是在“思考—调用工具—观察结果—继续决策”之间循环,直到任务完成或需要用户补充信息。
以“创建一个登录页面”为例,Agent Loop 的执行过程可能是:
- 分析任务:需要 HTML、CSS、JavaScript 三部分。
- 调用写文件工具:生成
index.html。 - 观察结果:文件创建成功,但页面没有样式。
- 决定下一步:创建
style.css。 - 再次调用工具:写入样式代码。
- 观察结果:样式已有,但缺少表单校验。
- 继续决策:创建
main.js。 - 执行校验:检查文件是否完整,必要时运行本地预览或测试命令。
这个过程可以抽象成下面的循环:
flowchart TD
A[接收任务] --> B[读取当前上下文]
B --> C[大语言模型思考下一步]
C --> D{是否需要调用工具}
D -- 是 --> E[选择工具并生成参数]
E --> F[执行工具]
F --> G[观察执行结果]
G --> B
D -- 否 --> H{任务是否完成}
H -- 未完成 --> B
H -- 已完成 --> I[返回结果]
用伪代码表示会更直观:
while not task.finished:
context = load_context(task)
decision = llm.plan(
goal=task.goal,
context=context,
available_tools=tools.list()
)
if decision.need_tool:
result = tools.call(
name=decision.tool_name,
args=decision.tool_args
)
context.add_observation(result)
else:
task.finish(decision.final_answer)
OpenClaw 的 Agent Loop 基于 Pi SDK(软件开发工具包)。这意味着它没有从零实现完整的 Agent 推理框架,而是把已有的 Agent Loop 能力集成到自己的系统中。
这也说明一个关键点:Agent Loop 本身不是 OpenClaw 独有的能力。Claude Code、Codex 这类工具同样具备类似机制。OpenClaw 真正不同的地方,不在“会不会循环思考”,而在“能不能让这个循环长期在线运行,并被不同平台触发”。
Tools:让 Agent 真正能做事
只会思考的 Agent 没法完成实际任务。Tools 的作用是把模型的决策变成真实动作。
OpenClaw 的工具体系可以分成三层:
flowchart BT
A[基础工具<br/>文件读写 / 命令执行 / 网页浏览 / 搜索抓取] --> B[Skills<br/>任务经验 / 操作步骤 / 工作规范]
B --> C[外部工具<br/>第三方 API / SaaS 服务 / 自定义插件]
| 层级 | 作用 | 示例 |
|---|---|---|
| 基础工具 | 让 Agent 能操作运行环境 | 读写文件、执行 Shell 命令、访问网页、抓取信息 |
| Skills | 把经验写成可复用的任务方法 | 修改代码前扫描项目结构、写完代码后运行测试、整理资料时按固定格式输出 |
| 外部工具 | 接入更多业务系统 | 调用 SaaS(软件即服务)平台、访问内部接口、连接知识库或工单系统 |
基础工具解决“能不能动手”的问题,Skills 解决“怎么做更像熟练员工”的问题,外部工具解决“能不能进入真实业务系统”的问题。
举个例子,如果用户让 Agent 修改一个项目里的登录逻辑,只有基础工具时,它可能直接搜索文件、修改代码、运行命令;加入 Skills 后,它可以按照更稳定的流程执行:
任务:修改登录逻辑
Skill:代码修改流程
- 扫描项目目录,判断技术栈
- 找到登录相关文件
- 修改前记录关键文件内容
- 小步修改,不一次性改太多
- 修改后运行测试或构建命令
- 如果失败,根据报错回滚或修正
- 输出变更摘要
Tools 体系并不是 OpenClaw 的唯一优势,因为 Claude Code、Codex 也有工具调用能力。差异仍然落在运行环境:这些工具通常是“用户打开后执行任务”,而 OpenClaw 更强调“服务一直在线,任务可以从任何接入渠道进来”。
Gateway:OpenClaw 和本地 Agent 工具的关键差异
Gateway 是 OpenClaw 最值得分析的模块。它不直接提供模型智能,也不直接完成工具执行,但它决定了 Agent 能不能像服务一样长期存在。
可以把 Gateway 理解成 Agent 的运行外壳,主要承担六类职责。
| 职责 | 解决的问题 | 典型场景 |
|---|---|---|
| 常驻与恢复 | 进程不能一崩就丢任务 | 服务异常退出后自动拉起,恢复未完成会话 |
| 多平台接入 | 不同聊天平台协议不一致 | 飞书、Telegram、钉钉等消息统一转成内部格式 |
| 会话隔离 | 多个用户或群聊不能串上下文 | 一个群里查资料,另一个窗口写文档,两边互不干扰 |
| 队列控制 | 大语言模型不适合无限并发 | 同一会话内按顺序处理任务,避免上下文混乱 |
| Heartbeat / Cron | Agent 需要主动执行任务 | 每天早上自动整理资讯,定时推送到指定渠道 |
| 记忆刷盘 | 长上下文压缩时不能丢关键结论 | 压缩对话前把决策、待办、项目约定写入记忆文件 |
常驻与恢复:让 Agent 不因为进程退出而失忆
普通命令行 Agent 通常依赖当前终端会话。终端关了、进程退出了,任务就结束了。
Gateway 的思路是把 Agent 当成一个长期服务来管理:进程异常时可以重启,会话状态可以恢复,任务记录可以继续读取。这样一来,Agent 不再是临时工具,而更像一个后台 Worker。
flowchart LR
A[Agent 进程运行] --> B{是否异常退出}
B -- 否 --> A
B -- 是 --> C[Gateway 检测异常]
C --> D[重新拉起进程]
D --> E[加载会话与任务状态]
E --> A
多平台接入:把不同消息协议变成统一输入
飞书、Telegram、钉钉等平台的消息格式、鉴权方式、回复接口都不同。如果每个平台都让 Agent 单独适配,系统会很快变得难维护。
Gateway 在中间做了一层统一转换:
flowchart LR
A[飞书消息] --> G[Gateway 消息适配层]
B[Telegram 消息] --> G
C[钉钉消息] --> G
G --> M[统一 Message 对象]
M --> L[Agent Loop]
内部只处理统一的 Message 对象,外部平台差异被 Gateway 消化掉。Agent Loop 不需要知道消息来自飞书还是 Telegram,它只关心用户说了什么、会话是谁、应该把结果返回到哪里。
会话隔离:避免多个任务互相污染上下文
AI Agent 的上下文非常重要。如果两个用户的任务混在一起,模型可能会把 A 的需求带到 B 的任务里,造成错误结果。
Gateway 需要为不同会话维护独立状态:
session_id = platform + channel_id + user_id/thread_id
不同系统实现可能不完全一样,但核心思想相同:每个会话有自己的上下文、任务队列和记忆文件。这样同一个 Agent 服务可以同时服务多个窗口,而不会把上下文揉在一起。
队列控制:宁可慢一点,也不要把任务搅乱
大语言模型可以并发调用,但 Agent 任务不一定适合并发执行。原因很简单:Agent Loop 依赖上下文,工具调用还可能修改文件、写入状态、触发外部系统。如果同一会话里同时跑两个循环,很容易互相覆盖。
Gateway 通常会在会话维度做排队:
flowchart TD
A[消息 1] --> Q[会话队列]
B[消息 2] --> Q
C[消息 3] --> Q
Q --> T1[处理任务 1]
T1 --> T2[处理任务 2]
T2 --> T3[处理任务 3]
这种设计牺牲了一部分响应速度,但换来更稳定的上下文一致性。对 Agent 系统来说,稳定性往往比看起来“同时处理很多事”更重要。
Heartbeat 与 Cron:让 Agent 从被动回复变成主动执行
如果没有主动触发机制,Agent 只能等用户发消息。OpenClaw 的主动能力主要来自两类调度:
- Heartbeat:周期性巡检,例如每隔一段时间检查是否有待办任务。
- Cron:按固定时间触发,例如每天 8 点执行资讯整理任务。
一个典型的定时任务流程如下:
sequenceDiagram
participant Scheduler as Heartbeat / Cron
participant Gateway
participant Agent as Agent Loop
participant Tools
participant Channel as 消息平台
Scheduler->>Gateway: 触发待办任务
Gateway->>Agent: 注入任务上下文
Agent->>Tools: 搜索、抓取、整理数据
Tools-->>Agent: 返回执行结果
Agent-->>Gateway: 生成最终内容
Gateway-->>Channel: 推送到飞书/Telegram/钉钉
这里有一个常见坑:用户让 Agent “每天帮我做某件事”,模型可能在回复里说“已经配置好了”,但实际系统没有把任务写入持久化待办。要判断定时任务是否真的生效,不能只看模型回答,还要检查任务是否进入调度系统。
记忆刷盘:上下文压缩前保存关键状态
长时间对话一定会遇到上下文窗口限制。直接压缩旧消息会带来一个问题:项目约定、关键决策、未完成事项可能被压掉。
Gateway 的做法是,在压缩上下文之前,把重要信息写入记忆文件或持久化存储。下一轮任务需要时,再把这些内容重新加载进上下文。
适合刷盘的信息包括:
| 信息类型 | 示例 |
|---|---|
| 项目约定 | 使用 TypeScript、接口返回格式固定为 { code, data, message } |
| 关键决策 | 登录态改用 HttpOnly Cookie,不再放 localStorage |
| 长期任务 | 每天 8 点推送资讯摘要 |
| 用户偏好 | 输出结果使用 Markdown 表格,代码需要附带注释 |
| 外部资源 | 文档地址、知识库路径、常用 API 入口 |
记忆刷盘不是简单保存聊天记录,而是把“未来还会用到的状态”提炼出来。做得不好会导致 Agent 反复问同样的问题,或者在几轮对话后忘掉已经确认过的约束。
OpenClaw 与 Claude Code:两条 Agent 路线
OpenClaw 经常会被拿来和 Claude Code、Codex 这类工具对比,但它们解决的问题不完全一样。
| 维度 | OpenClaw | Claude Code / Codex |
|---|---|---|
| 核心定位 | 长期在线的开源 Agent 运行系统 | 面向编程任务的本地或云端 Agent 工具 |
| 强项 | 多平台接入、会话管理、定时任务、主动执行、自部署改造 | 代码理解、代码修改、工程任务执行能力强 |
| 运行方式 | 更像后台服务,可以持续运行 | 更像开发者主动打开的工作工具 |
| 是否强调 Gateway | 强调 | 通常不以多平台 Gateway 作为核心卖点 |
| 适合任务 | 定时汇总、消息机器人、知识库助手、自动化流程 | 写代码、改代码、解释项目、运行测试 |
| 开源可改造性 | 适合二次开发和自定义接入 | 取决于具体产品形态 |
如果目标是“让 AI 帮我高质量修改复杂代码”,Claude Code 这类工具更合适;如果目标是“让 AI 长期在线,接入飞书群、每天主动推送、处理多个会话”,OpenClaw 的架构更贴近需求。
一句话概括:Claude Code 更像一把面向编程任务的锋利工具,OpenClaw 更像一个可以部署和改造的 Agent 运行底座。
适合 OpenClaw 的场景
OpenClaw 的优势来自长期在线、多平台接入、主动触发和开源改造。场景选择要围绕这些优势展开。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 每天定时整理资讯并推送到群里 | 适合 | 需要 Cron、搜索抓取、消息推送 |
| 飞书群里的知识库助手 | 适合 | 需要消息平台接入、会话隔离、知识库工具 |
| 自动巡检某个网页或接口状态 | 适合 | 需要 Heartbeat、工具调用和异常通知 |
| 团队内部轻量自动化机器人 | 适合 | 可以自定义工具并部署在内部环境 |
| 一次性生成一段代码 | 不一定适合 | 直接用编程 Agent 可能更快 |
| 高并发客服系统 | 谨慎 | Agent Loop 成本高、延迟高,队列和并发要重新设计 |
| 强事务业务操作 | 谨慎 | 工具权限、幂等、审计、回滚都必须补齐 |
| 纯文档问答 | 不一定适合 | 如果平台自带 AI 搜索已经够用,没有必要引入完整 Agent 系统 |
使用 OpenClaw 前,需要先判断任务是否真的需要“长期在线”和“主动执行”。如果只是偶尔问答或临时写代码,完整 Agent 运行系统反而会带来额外复杂度。
上手 OpenClaw 时应该关注什么
实际部署命令以仓库 README 为准,但上手路径可以按运行系统的思路拆解,而不是只盯着模型配置。
| 步骤 | 要做的事 | 检查点 |
|---|---|---|
| 准备运行环境 | 选择服务器或本地机器,保证进程可以长期运行 | 是否有进程守护、日志、重启机制 |
| 配置大语言模型 | 填写模型供应商、密钥、模型名 | 密钥是否只保存在安全位置 |
| 开启消息渠道 | 接入飞书、Telegram 或其他平台 | 消息能否进入 Gateway,回复能否返回原渠道 |
| 配置工具权限 | 开启文件、命令、网页、API 等工具 | 工具权限是否过大,是否可能误删文件或泄露数据 |
| 编写 Skills | 把常见任务流程固化下来 | Agent 是否按预期步骤执行 |
| 创建定时任务 | 使用 Heartbeat 或 Cron 触发任务 | 任务是否真的写入调度系统 |
| 增加监控 | 记录任务状态、工具调用、错误日志 | 出错后能否定位是哪一步失败 |
配置过程中最容易忽略的是权限边界。Agent 一旦拥有命令执行、文件读写和外部 API 调用能力,就不只是聊天机器人,而是能操作真实系统的自动化程序。工具权限应该按任务最小化开放。
常见坑与工程建议
1. 不要只相信模型说“已经完成”
Agent 的回复和系统状态不是一回事。尤其是定时任务、外部 API 操作、文件修改这类动作,必须检查真实结果。
更可靠的方式是给关键动作加确认机制:
用户:每天 8 点推送 AI 资讯摘要
Agent 应该完成的真实动作:
- 创建任务记录
- 写入调度时间
- 绑定推送渠道
- 保存任务参数
- 返回任务 ID
如果只返回“好的,已经安排”,但没有任务 ID 或调度记录,这个任务大概率并没有真正落地。
2. 工具调用要做幂等设计
定时任务和自动化任务可能重复触发。比如网络抖动、进程重启、消息平台重试,都可能导致同一个任务执行两次。
涉及写文件、发消息、调用业务接口时,要尽量设计成幂等:
- 同一任务有唯一
task_id。 - 执行前检查是否已经完成。
- 发送通知前记录发送状态。
- 外部 API 调用失败后区分“失败”和“已成功但响应丢失”。
3. 会话隔离不能只靠提示词
提示词可以提醒模型“不要混淆上下文”,但真正的隔离应该由 Gateway 和存储层保证。不同用户、群聊、线程应该有独立的上下文、队列和记忆。
4. 长期记忆要控制质量
记忆文件不是越多越好。把所有对话都塞进去,会让 Agent 在后续任务里读到大量噪声。更好的做法是只保存稳定、可复用、未来会影响决策的信息。
5. 日志比界面更重要
Agent 系统出错时,表面现象可能只是“没有回复”或“任务没执行”。没有日志就很难判断问题出在消息接入、队列、模型调用、工具执行还是调度系统。
至少需要记录:
| 日志类型 | 用途 |
|---|---|
| 消息日志 | 判断外部平台消息是否进入 Gateway |
| 队列日志 | 判断任务是否排队或卡住 |
| 模型调用日志 | 判断模型是否返回工具调用 |
| 工具执行日志 | 判断文件、命令、API 是否成功 |
| 调度日志 | 判断 Heartbeat / Cron 是否触发 |
| 错误日志 | 定位异常栈和失败原因 |
OpenClaw 的工程价值
OpenClaw 的重要性不在于某个单点算法突破,而在于把一组成熟组件组合成了可运行的 Agent 系统。
Agent Loop、工具调用、多平台消息适配、定时任务、会话隔离、记忆刷盘,这些能力单独看都不神秘。难点在于把它们放进同一个系统里,让任务能从外部平台进入,让模型能稳定调用工具,让状态能持续保存,让系统崩溃后还能恢复。
对 AI Agent 来说,模型能力只是上限的一部分。真正决定它能否进入日常工作流的,还有运行环境、工具权限、调度机制、上下文管理和可观测性。
OpenClaw 提供的启发是:一个可用的 AI Agent,不只是“更聪明的大模型”,还需要一个能长期在线、能连接现实系统、能管理状态的工程底座。