AI Agent(人工智能智能体)框架通常会强调两件事:把任务拆给多个 Agent,并让这些 Agent 互相协作。这个思路没有问题,但真正落到复杂任务时,只靠“有人规划、有人执行”还不够。
常见的问题有几个:
-
规划结果没有强制审核
一个 Agent 拆完任务后,执行 Agent 直接开始干活。如果拆解漏了关键需求,后面的执行会沿着错误方向推进。 -
Human-in-the-loop(人工介入闭环)容易变成人肉 QA
框架允许人类插手,并不等于系统有审核机制。人需要不断盯着中间结果,才能发现规划错误、角色分配错误或任务遗漏。 -
流转过程不可审计
最终拿到一个结果,却很难知道任务经历了哪些阶段、谁做了什么、哪一步被修改过、为什么被修改。 -
Agent 之间通信边界不清晰
如果任何 Agent 都能直接找任何 Agent,短期看起来灵活,长期会让任务链路变得混乱。出了问题,很难定位责任边界。
Edict 的设计思路是:把多 Agent 协作做成一个带制度约束的流程。它借用了三省六部的分工模型,把任务处理拆成“规划、审核、调度、执行、归档”几个固定环节,并且把审核做成必经关卡,而不是可选插件。
项目地址:
https://github.com/cft0808/edict
三省六部如何映射到 Agent 工作流
Edict 运行在 OpenClaw 之上,核心由 9 个 Agent 组成。三省负责流程治理,执行层负责具体任务,早朝官负责每日简报。
| 角色 | 在系统中的职责 | 典型产出 |
|---|---|---|
| 中书省 | 接收用户指令,理解目标,拆解任务 | 执行方案、子任务列表 |
| 门下省 | 审核中书省方案,发现遗漏、冲突和不可执行点 | 准奏或封驳意见 |
| 尚书省 | 接收通过审核的方案,派发任务,协调执行 | 部门任务、汇总结果 |
| 户部 | 数据分析、指标采集、量化对比 | 数据表、统计结论 |
| 礼部 | 文档撰写、报告整理、表达润色 | 报告、说明文档 |
| 兵部 | 代码开发、技术调研、架构分析 | 代码、技术方案 |
| 刑部 | 安全、合规、风险检查 | 风险清单、合规建议 |
| 工部 | CI/CD(持续集成与持续交付)、部署、基础设施 | 部署脚本、环境配置 |
| 早朝官 | 每日信息聚合 | 新闻简报 |
整个流程可以画成这样:
flowchart TD
U[用户下达旨意] --> ZS[中书省:理解目标并拆解任务]
ZS --> MX[门下省:审议方案]
MX -->|准奏| SS[尚书省:派发任务]
MX -->|封驳| ZS
SS --> HB[户部:数据分析]
SS --> LB[礼部:文档撰写]
SS --> BB[兵部:开发与技术调研]
SS --> XB[刑部:安全合规]
SS --> GB[工部:部署与基建]
HB --> SS
LB --> SS
BB --> SS
XB --> SS
GB --> SS
SS --> Archive[奏折归档]
Archive --> U
这个结构里最重要的环节是门下省。中书省不能把方案直接交给执行层,必须先经过门下省审议。门下省发现问题后,可以把方案打回,让中书省重新规划。
这一步让多 Agent 系统多了一层“制度性质量门禁”。
门下省审核为什么关键
规划 Agent 最容易犯的错误不是“不会做事”,而是“拆错事”。例如用户要求分析一个框架的可观测性、开发体验和适用场景,中书省可能只拆出“技术架构调研”和“数据采集”,漏掉“可观测性”这个明确需求。
如果没有审核,后面几个执行 Agent 会很认真地完成一组不完整的任务。最终报告看起来结构完整,但其实没有回答用户真正关心的问题。
门下省的审核目标不是重复执行任务,而是检查方案本身:
| 审核项 | 检查内容 |
|---|---|
| 需求覆盖 | 用户明确提出的要求是否都被拆进任务 |
| 任务边界 | 子任务之间是否重复、冲突或缺少依赖 |
| 部门匹配 | 任务是否分配给了合适的执行 Agent |
| 可执行性 | 任务描述是否足够明确,是否能落到产出物 |
| 结论导向 | 是否只收集材料,却没有安排结论输出 |
门下省的输出只有两类:准奏或封驳。
flowchart LR
Plan[中书省提交方案] --> Review{门下省审议}
Review -->|通过| Dispatch[尚书省派发]
Review -->|不通过| Reject[封驳意见]
Reject --> Replan[中书省重新规划]
Replan --> Review
这和简单的提示词检查不同。门下省是一个专职审核 Agent,它不负责执行,也不负责最终汇总。规划、审核、执行三种权力被拆开,任何一个环节都不能包办完整流程。
权限矩阵:防止 Agent 越级通信
Edict 不是只在提示词里告诉 Agent“不要越级”,而是在架构层面定义通信权限。谁能给谁发消息,是固定的。
| 谁 ↓ 给谁发 → | 中书省 | 门下省 | 尚书省 | 执行层 |
|---|---|---|---|---|
| 中书省 | — | ✅ | ✅ | ❌ |
| 门下省 | ✅ | — | ✅ | ❌ |
| 尚书省 | ✅ | ✅ | — | ✅ |
| 执行层 | ❌ | ❌ | ✅ | ❌ |
这张表的含义很直接:
- 中书省不能绕过门下省,直接指挥执行层。
- 执行层不能越级向中书省汇报。
- 跨层任务流转由尚书省协调。
- 门下省只审议,不接管执行。
权限矩阵解决的是协作边界问题。Agent 数量一多,如果没有通信边界,系统会变成一团自由对话;有了权限矩阵,任务链路可以被追踪、复盘和审计。
和常见多 Agent 框架的差异
Edict 和 CrewAI、AutoGen 这类框架的差异,不在于“能不能让多个 Agent 一起干活”,而在于有没有把审核、审计和干预做成流程的一部分。
| 能力 | CrewAI | AutoGen | Edict |
|---|---|---|---|
| 多 Agent 分工 | ✅ | ✅ | ✅ |
| Agent 对话 | ✅ | ✅ | ✅ |
| 强制审核 | ❌ | ⚠️ 依赖人工或自定义流程 | ✅ 门下省必审 |
| 审核失败返工 | ❌ | ⚠️ 可自行实现 | ✅ 封驳后重新规划 |
| 实时任务看板 | ❌ | ❌ | ✅ |
| 流转归档 | ⚠️ 有限 | ⚠️ 有限 | ✅ 奏折归档 |
| 任务干预 | ❌ | ⚠️ 取决于实现 | ✅ 叫停、取消、恢复 |
| Agent 健康监控 | ❌ | ❌ | ✅ |
| 每个 Agent 独立切换 LLM | ⚠️ 取决于集成方式 | ⚠️ 取决于集成方式 | ✅ 看板内配置 |
LLM(大语言模型)越强,单个 Agent 的输出质量通常会越好,但多 Agent 系统的问题不只来自模型能力。规划漏项、角色混乱、任务不可追踪,都是系统设计问题。Edict 的重点是给 Agent 协作加上流程约束。
军机处看板:让任务流转可见
多 Agent 系统不能只在后台跑。任务走到哪一步、哪个 Agent 正在工作、哪个环节被打回、最终结果如何归档,都需要可观测界面。
Edict 提供了一个“军机处看板”,前端是单文件 HTML,没有 React 和 Vue;后端使用 Python 标准库 http.server,不依赖 Flask 或 FastAPI。它的目标是降低体验成本,启动后打开浏览器就能看任务流转。
旨意看板是任务入口。任务以卡片形式展示,按状态分列,并带有心跳标记,用来区分活跃、停滞和告警状态。
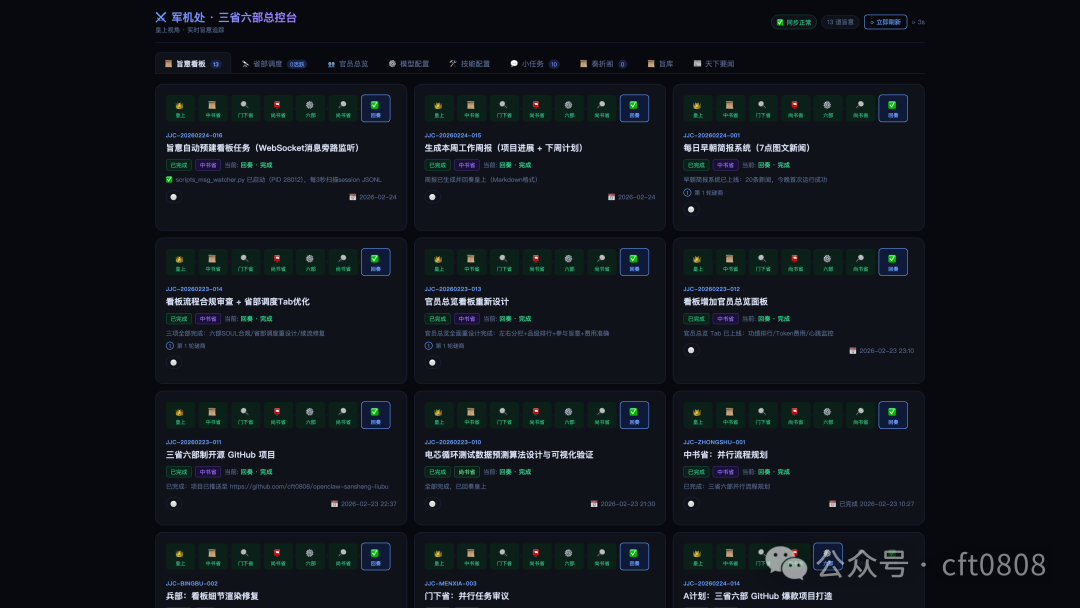
这类看板的价值不只是“好看”,而是把任务状态从日志里抽出来。用户可以直接看到任务处于规划、审议、执行还是归档阶段,也可以点开卡片查看完整时间线,并在必要时叫停或取消任务。
省部调度面板关注系统整体负载,包括各状态任务数量、部门分布和 Agent 健康状态。
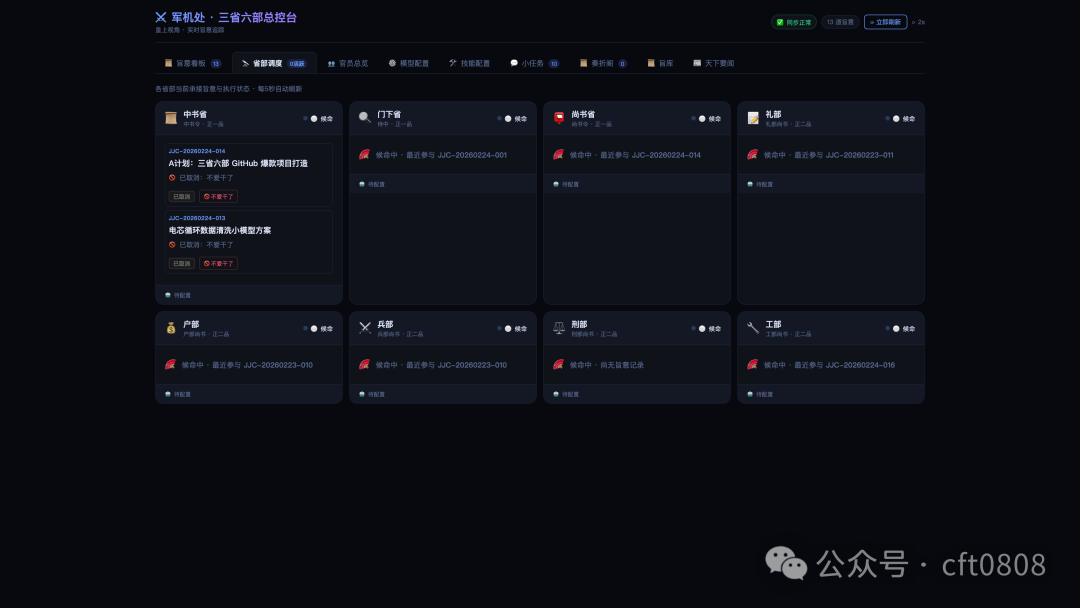
当多个任务同时运行时,调度面板可以用来判断瓶颈在哪里:是某个执行部门排队太多,还是某个 Agent 长时间没有心跳。对多 Agent 系统来说,这比只看最终输出更重要。
奏折阁负责归档已完成任务。一个任务完成后,会按照“圣旨 → 中书规划 → 门下审议 → 六部执行 → 回奏”的顺序留下完整记录。
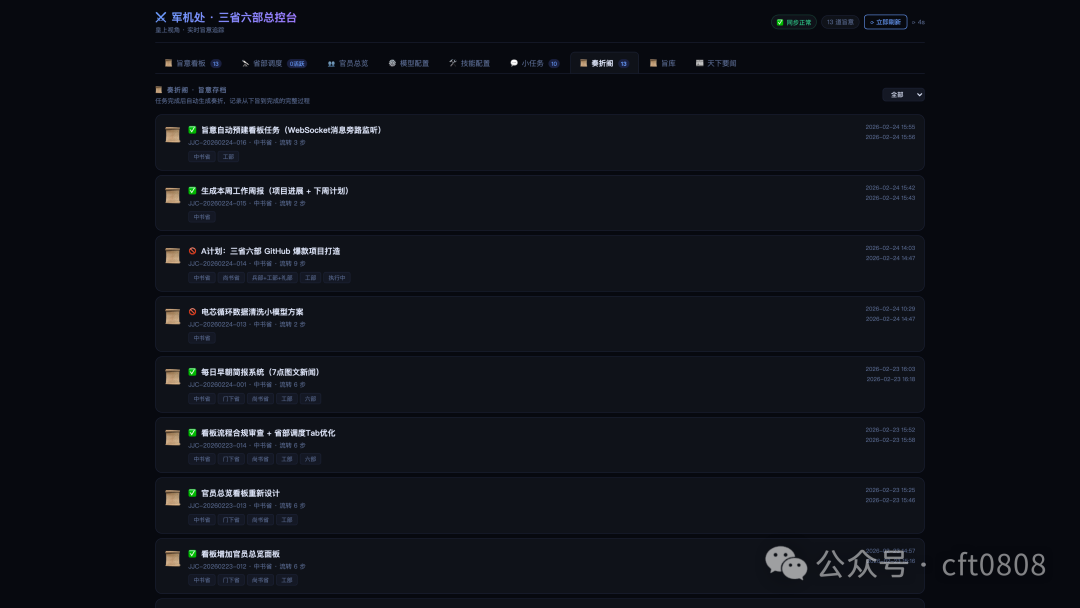
归档的意义在于复盘。任务结果出了问题,不需要重新猜测中间发生了什么,可以沿时间线检查是哪一步漏了需求、哪一次审议放过了问题、哪个执行部门产出了错误内容。
模型配置面板允许每个 Agent 单独选择 LLM。
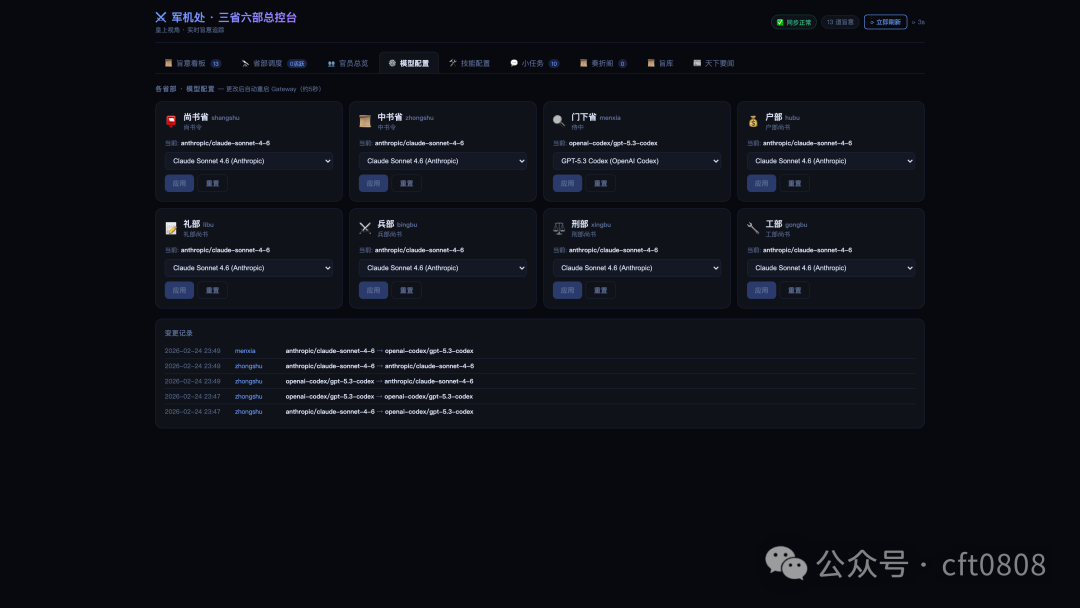
不同角色对模型能力的要求不一样。中书省更依赖规划能力,兵部更依赖代码能力,户部更依赖数据处理能力,礼部更依赖长文档组织能力。把所有 Agent 绑定到同一个模型上,简单但不够灵活;按角色配置模型,可以让不同 Agent 使用更适合自己的能力。
一个任务如何在 Edict 里流转
用“分析 CrewAI、AutoGen 和 LangGraph 的差异,并输出对比报告”这个任务,可以看到门下省审核的作用。
任务卡片点开后,可以查看完整流转链路和实时状态。
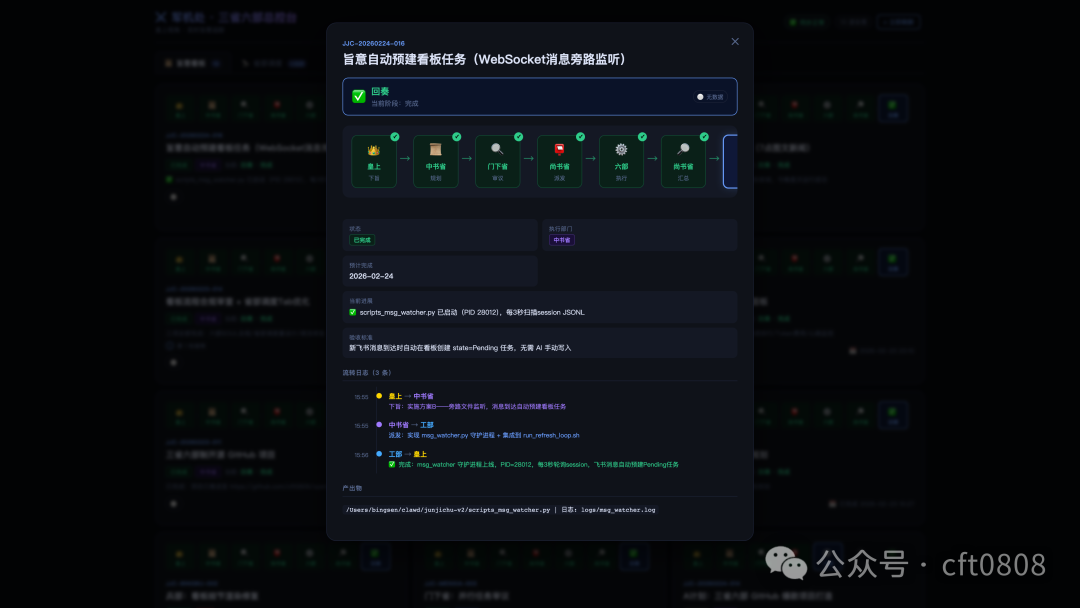
这次任务的理想流程是:
sequenceDiagram
participant User as 用户
participant ZS as 中书省
participant MX as 门下省
participant SS as 尚书省
participant BB as 兵部
participant HB as 户部
participant LB as 礼部
User->>ZS: 分析 CrewAI、AutoGen、LangGraph
ZS->>MX: 提交初版任务拆解
MX-->>ZS: 封驳:漏掉可观测性,任务有重叠,缺少推荐结论
ZS->>MX: 提交修订方案
MX->>SS: 准奏
SS->>BB: 调研架构、通信、开发体验
SS->>HB: 采集 Stars、Contributors、Issue 响应等数据
SS->>LB: 整合材料并撰写报告
BB-->>SS: 返回技术分析
HB-->>SS: 返回量化数据
LB-->>SS: 返回最终报告
SS-->>User: 回奏并归档
初版规划把任务拆成了几块:
- 兵部:架构与通信机制调研
- 户部:GitHub Stars、Contributors 等量化指标采集
- 兵部:开发者体验评测
- 礼部:汇总并输出对比报告
门下省审核后发现三个问题:
| 问题 | 影响 |
|---|---|
| 用户要求评测可观测性,但方案里没有对应子任务 | 最终报告会漏掉关键维度 |
| 架构调研和开发者体验都交给兵部,边界有重叠 | 可能重复调研,浪费 Token 和时间 |
| 缺少推荐场景的结论性任务 | 报告只会罗列信息,不回答“该怎么选” |
门下省封驳后,中书省重新规划。修订方案通过后,尚书省再派发给各部门执行。
执行结束后,报告形成类似这样的结论:
| 场景 | 推荐框架 | 原因 |
|---|---|---|
| 快速原型 | CrewAI | 上手路径短,适合快速组织角色任务 |
| 对话式协作 | AutoGen | 更适合多轮对话和交互式协作 |
| 复杂工作流 | LangGraph | 状态机表达能力强,适合复杂流程控制 |
| 可靠性优先 | Edict | 内置强制审核、流转归档和权限边界 |
这个案例说明了强制审核的实际价值:它不只是挑语言问题,而是在执行前修正任务结构。越复杂的任务,越需要这一层。
SOUL.md:用文件定义 Agent 职责
Edict 给每个 Agent 准备了独立的 Workspace、Skills 和 SOUL.md。SOUL.md 是一个 Markdown 文件,用来描述 Agent 的人格、职责边界和工作规则。
例如要调整门下省的审核标准,可以修改:
agents/menxia/SOUL.md
这种设计的好处是,职责定义不被写死在代码里。团队可以根据自己的业务改造执行层:
| 默认角色 | 可以改造成 |
|---|---|
| 兵部 | 工程研发、技术评审、架构设计 |
| 户部 | 数据分析、财务测算、增长指标分析 |
| 礼部 | 产品文档、运营内容、客户报告 |
| 刑部 | 安全审查、法务合规、风险控制 |
| 工部 | DevOps、部署、基础设施管理 |
只要保持“规划不执行、审核不执行、执行不规划”的边界,三省六部模型可以迁移到很多场景。
技术实现上的取舍
Edict 做了几个偏工程化的选择。
零依赖看板
看板前端使用纯 HTML、CSS 和 JavaScript,大约 2200 行;后端使用 Python 标准库 http.server。这样做牺牲了一些前端工程化能力,但换来了低启动成本。
对于一个工作流框架来说,体验门槛很关键。如果用户只是想验证“三省六部式多 Agent 流转”是否适合自己的任务,不应该先处理一堆前端依赖和服务配置。
独立 Agent Workspace
每个 Agent 有自己的工作目录、技能配置和职责文件。这样能减少角色污染:兵部不需要知道礼部的完整写作规则,门下省也不应该拥有执行部门的操作权限。
架构级权限约束
权限矩阵不是提示词约定,而是通信层约束。提示词只能告诉 Agent 应该怎么做,架构约束可以限制 Agent 不能做什么。
在多 Agent 系统里,“不能做什么”往往比“应该做什么”更重要。因为一旦允许越级通信,任务链路就会绕开审计点,门下省审核也会失去意义。
适合和不适合的场景
Edict 的优势来自流程治理,所以它适合中等复杂度以上、需要审计和质量把关的任务。简单的一次性问答不一定需要这么完整的流转。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 多框架技术调研 | 适合 | 需要拆任务、采集数据、写报告、给结论 |
| 代码审查与修复 | 适合 | 需要规划修复点,并在执行前检查风险 |
| API(应用程序编程接口)设计 | 适合 | 需要兼顾需求、接口边界、文档和合规 |
| 周报、竞品分析、研究报告 | 适合 | 多角色协作能减少遗漏 |
| 单轮问答 | 不太适合 | 流程开销大于收益 |
| 极低延迟任务 | 不太适合 | 审核和调度会增加等待时间 |
| 完全自由探索式聊天 | 不太适合 | 权限矩阵会限制随意对话 |
选择多 Agent 框架时,可以按任务风险来判断:如果错误规划会导致明显返工,或者结果需要复盘,就应该引入审核和归档;如果只是临时生成一段文本,完整流程可能过重。
快速运行
Docker 方式最简单:
docker run -p 7891:7891 cft0808/edict
启动后访问:
http://localhost:7891
如果本机已经安装 OpenClaw,可以使用完整安装方式:
git clone https://github.com/cft0808/edict.git
cd edict
chmod +x install.sh
./install.sh
安装脚本会创建 Agent Workspace,写入职责文件,注册权限矩阵,并重启 Gateway。
后续可以扩展的方向
Edict 的核心流程已经具备:接旨、规划、审议、派发、执行、归档。围绕这个基础,还可以继续扩展几类能力:
| 能力 | 作用 |
|---|---|
| 御批模式 | 门下省审议结果推送到飞书或 Telegram,由人类决定准奏还是封驳 |
| 功过簿 | 统计每个 Agent 的完成率、返工率、耗时和 Token 消耗 |
| 急递铺 | 在看板中展示实时 Agent 通信流向 |
| 国史馆 | 把历史任务和奏折沉淀为知识库,让新任务参考旧经验 |
多 Agent 协作的关键不只是让 Agent 更多、更聪明,而是让它们在清晰的边界内协作。Edict 用三省六部模型把规划权、审核权和执行权拆开,再通过权限矩阵、看板和归档机制把流程固定下来。
对于需要可靠输出的 Agent 系统,这种“先审再做、做完可查”的结构,比单纯堆角色更重要。