FireRed-Image-Edit 是小红书 Super Intelligence Team 发布的图像编辑基础模型,目标不是简单地“把图重画一遍”,而是在保留原图主体、风格、布局和身份信息的前提下,根据自然语言指令完成局部或全局修改。
它面向的任务比普通文生图更难。文生图只需要从零生成一张符合描述的图片,而图像编辑需要同时满足三件事:
- 理解原图:知道图里有哪些对象、文字、人物、背景和空间关系。
- 理解指令:判断用户到底想改哪里、不想改哪里。
- 保持一致性:修改目标区域,同时尽量不破坏主体身份、画面风格、文字排版和非编辑区域。
典型输入输出可以抽象成下面的流程:
flowchart LR
A[输入图像] --> D[图像编辑模型]
B[编辑指令] --> D
C[可选参考图] --> D
D --> E[编辑后图像]
D --> F[保留主体身份]
D --> G[执行局部修改]
D --> H[保持风格与布局]
FireRed-Image-Edit 在 ImgEdit、GEdit 等主流图像编辑榜单中取得了 SOTA(State of the Art,当前最优水平)结果,同时还构建了 RedEdit Bench,用更贴近真实用户需求的复杂编辑任务来评估模型能力。
项目资源如下:
图像编辑模型难在哪里
图像编辑表面上是“输入图片 + 输入一句话 + 输出图片”,但真正困难的是约束非常多。用户可能只说一句“把右下角文字改成 program ongoing,保持风格一致”,模型就要同时做到:
- 找到右下角文字区域;
- 识别原文字体、字号、颜色和排版;
- 替换成新内容;
- 保持海报其他部分不变;
- 不把背景、边框、图案、人物一起改乱。
这类任务不能只依赖生成能力,还需要强指令理解和强约束控制。FireRed-Image-Edit 的设计重点正是围绕这些问题展开。
可以把它的能力拆成四类:
| 能力 | 解决的问题 | 典型场景 |
|---|---|---|
| 指令遵循 | 准确判断要改什么、不改什么 | 修正图中错误、替换指定对象 |
| 文字编辑 | 修改图片里的文字并保持版式 | 海报改字、商品图改文案 |
| 创意与多图生成 | 根据参考图完成融合、换装、风格迁移 | 服装搭配、商品广告图、多参考图创作 |
| 画质修复 | 把底层视觉修复任务纳入统一编辑框架 | 老照片修复、去模糊、超分、去噪、补光 |
评测:为什么需要 RedEdit Bench
主流图像编辑评测集通常覆盖基础编辑任务,比如添加对象、删除对象、替换对象、局部修改等。这些任务可以衡量模型的基础能力,但和真实用户需求仍有距离。
真实编辑请求往往更复杂,例如:
- 修复老照片并上色;
- 提升模糊图像清晰度;
- 美化人像但保持身份一致;
- 替换海报文字并保持原字体风格;
- 根据多张参考图融合服装、人物和场景。
RedEdit Bench 针对这种差距设计,包含 15 个子任务,不只覆盖常规增删改,还加入了人像美化、低画质增强等高频编辑场景。它的价值在于把“真实复杂需求”变成可比较、可复现的评测任务。
主流榜单与自建评测集的指标对比如下,重点看不同模型在 ImgEdit、GEdit 和 RedEdit Bench 上的整体差异。
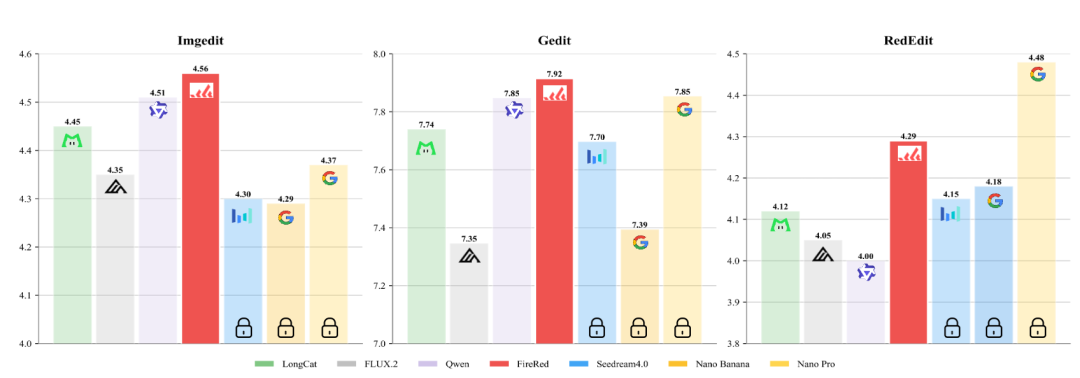
这组结果展示的是自动指标层面的横向比较。自动评测能快速覆盖大量样本,但图像编辑还存在审美、主体保持、局部修改是否自然等主观维度,所以人工评估也很重要。
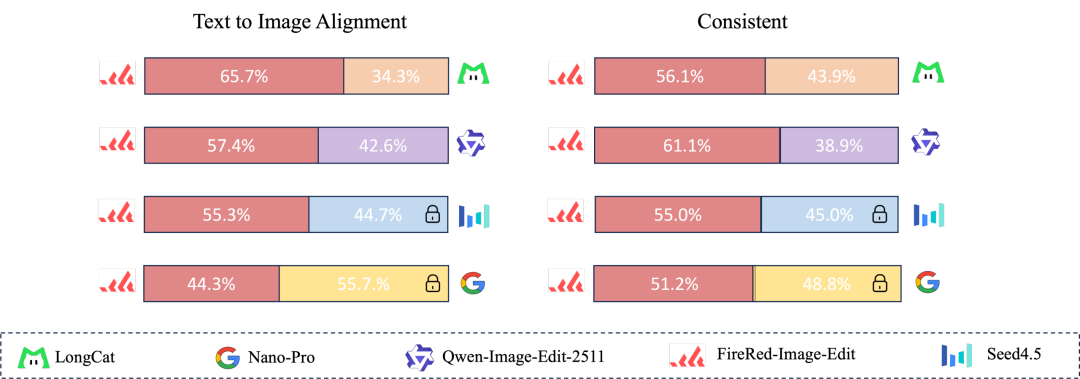
人工评估胜出率更接近实际使用体验。对于图像编辑模型来说,单纯某个像素级指标更高并不一定代表结果更好,人工比较通常会同时关注指令完成度、视觉自然度、非编辑区域稳定性和主体一致性。
RedEdit Bench 的任务构成可以用下图理解:
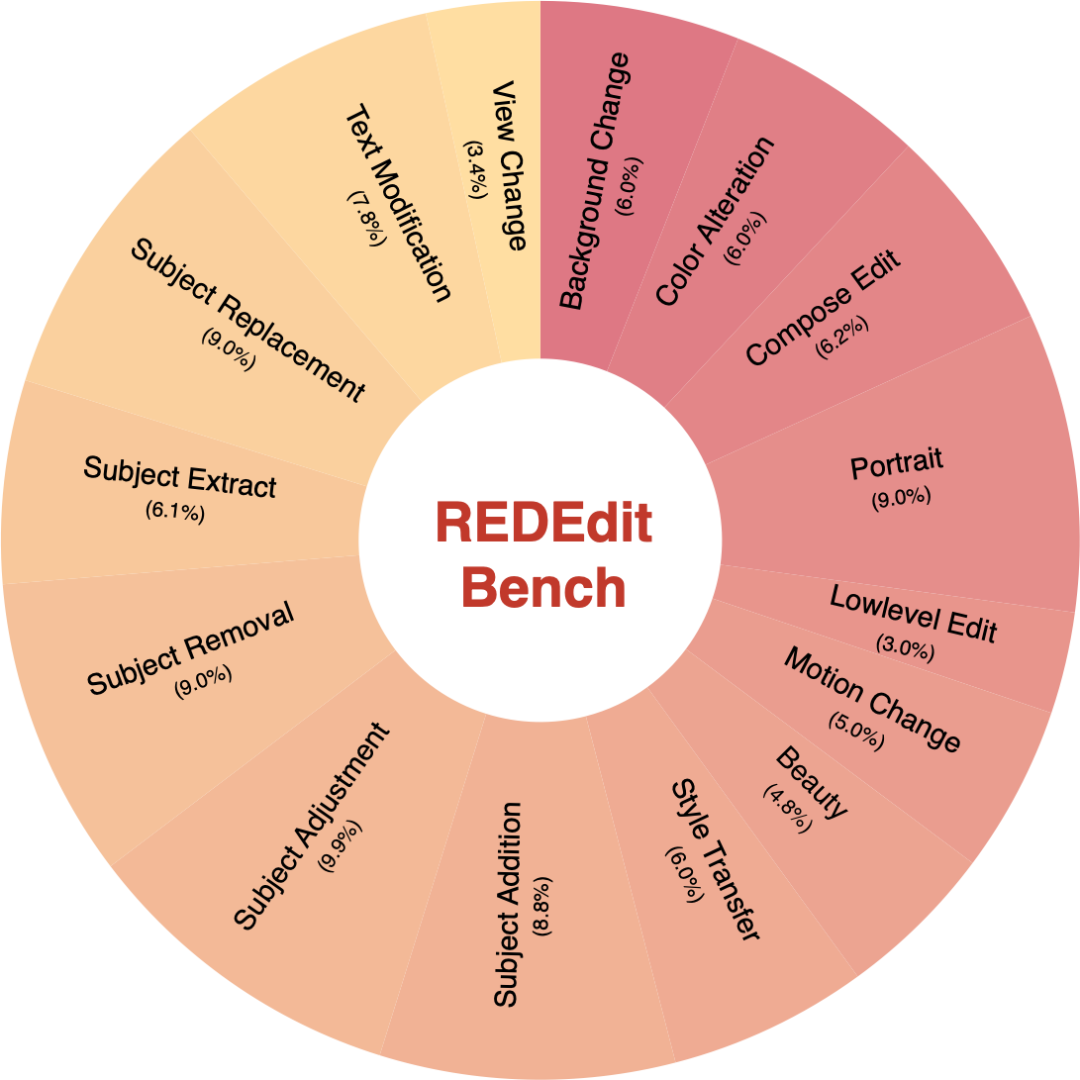
这类评测集的核心作用不是给模型“刷榜”,而是逼迫模型面对更细的编辑目标。比如低画质增强不能只把图锐化,人像美化不能改变身份,文字编辑不能只生成类似字符,而要保证内容正确、位置合理、风格一致。
数据引擎:训练数据怎么规模化构造
图像编辑模型要学会复杂编辑,关键前提是有足够多、足够准的“编辑前图像—编辑指令—编辑后图像”训练样本。FireRed-Image-Edit 构建了一套编辑数据生产引擎,用来把复杂需求拆成可组合子任务,并规模化产出训练数据。
数据生产大致分为三条路径:
| 数据路径 | 做法 | 适合任务 |
|---|---|---|
| 指令控制的专家模型合成 | 用已有专家模型按自然语言指令生成编辑样本 | 对象增删改、局部替换、风格化 |
| 结构化控制专家模型合成 | 借助分割、关键点、深度等结构信号控制生成 | 人像、姿态、空间结构相关编辑 |
| 模板化合成 | 不依赖单一编辑模型,用 3D、布局、文字等模板批量构造 | 文字编辑、布局编辑、规则化场景 |
数据引擎流程如下:
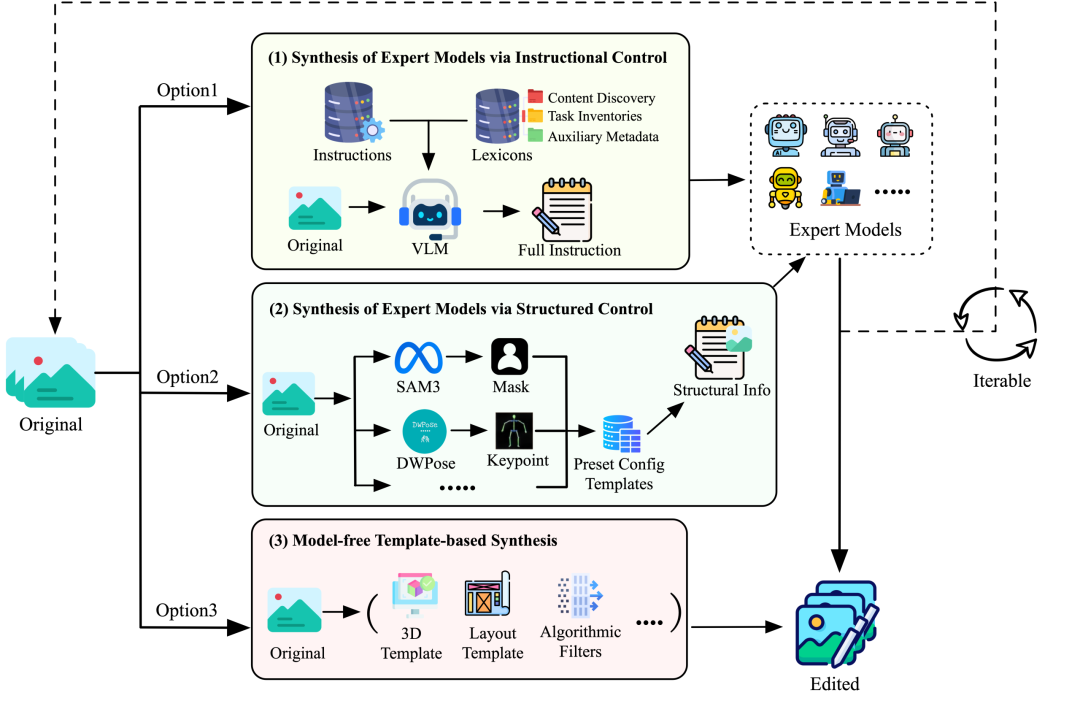
这套流程有几个关键点。
复杂任务要拆开。
例如“给模特换上参考图服装,同时保持人物身份和姿势不变”可以拆成服装区域定位、服装外观迁移、人体结构保持、背景稳定等子问题。拆分后,每个子任务都可以由不同专家模型或规则模板生成数据。
长尾任务要定向补数。
很多编辑场景不是均匀分布的。常见任务数据很多,罕见任务样本很少。如果模型训练时长期看不到某类请求,就很容易在实际使用中失效。FireRed-Image-Edit 使用“检查—补齐”的流程识别薄弱任务,再由数据引擎生成对应样本。
数据必须经过质量守门。
图像编辑数据如果质量不稳定,会直接把错误行为教给模型。清洗流程包括三层级去重、十余种质量清洗算子,以及一致性检查,重点保证三件事:
- 指令和结果一致;
- 编辑后图像视觉自然;
- 不该变化的内容保持稳定。
可以把数据引擎理解成下面的流水线:
flowchart TD
A[复杂编辑需求] --> B[拆解为子任务]
B --> C1[指令控制专家模型合成]
B --> C2[结构化控制专家模型合成]
B --> C3[模板化合成]
C1 --> D[候选训练样本]
C2 --> D
C3 --> D
D --> E[长尾任务检查]
E --> F[定向补数]
F --> D
D --> G[去重]
G --> H[质量清洗]
H --> I[一致性检查]
I --> J[高质量编辑训练集]
模型训练:三阶段把能力逐步推上去
FireRed-Image-Edit 的训练分成三个阶段:预训练、微调、强化学习。每个阶段解决的问题不同。
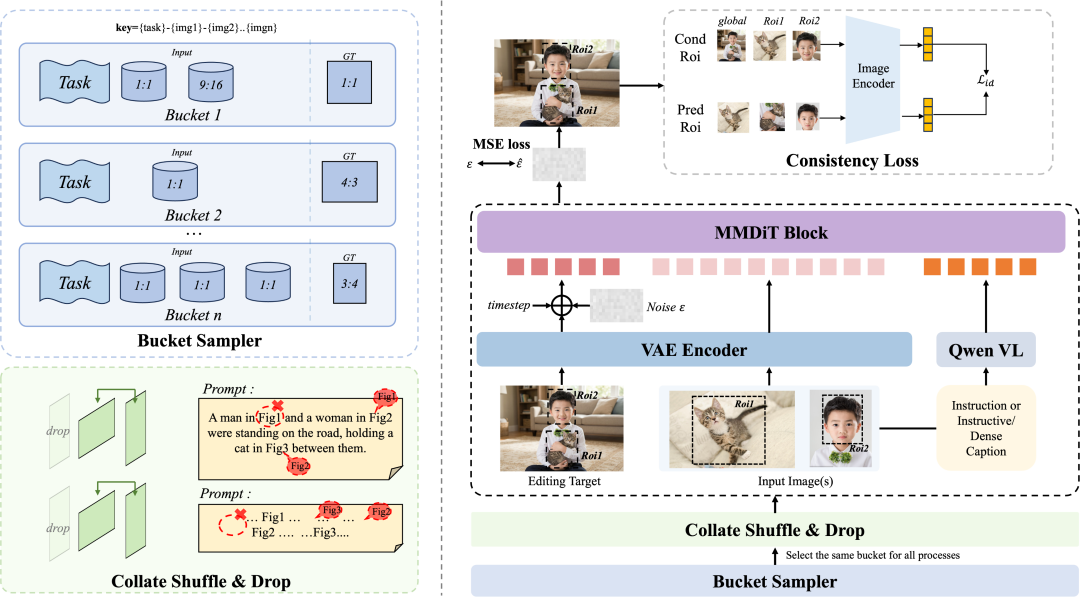
预训练:先获得通用编辑能力
预训练阶段要让模型见到足够多类型的编辑任务。这里用了几个设计:
多条件感知桶采样。
不同编辑任务难度和数据规模不同,如果训练采样不平衡,模型可能偏向数据量大的简单任务。多条件感知桶采样会根据任务条件做平衡,让模型更均匀地学习不同编辑类型。
随机动态指令。
同一个编辑目标可以用多种语言表达。如果训练数据里的指令太固定,模型可能学到的是模板匹配,而不是语义理解。随机打乱、动态重组 prompt,可以迫使模型建立“语言描述”和“图像区域”之间的真实对应关系。
前置 embedding 抽取。
训练扩散模型时,图像和文本编码会带来额外计算开销。提前抽取部分 embedding,可以减少重复计算,提高训练效率。
微调:用高质量数据提升结果上限
预训练阶段让模型学会广泛任务,微调阶段则用质量更高的数据修正输出细节。对图像编辑来说,高质量数据通常意味着:
- 编辑区域更准确;
- 非编辑区域更稳定;
- 风格一致性更好;
- 人像和主体身份不容易漂移;
- 文字和布局更可控。
微调不只是让图片“更好看”,更重要的是让模型在复杂约束下更可靠。
强化学习:把反馈信号注入难点任务
强化学习阶段用于进一步强化正样本反馈。FireRed-Image-Edit 采用非对称梯度优化,并在文字编辑任务中引入 OCR(Optical Character Recognition,光学字符识别)奖励。
这里的关键是:文字编辑不能只看图像是否自然,还要看字对不对、位置对不对、布局有没有坏。
文字编辑:Layout-Aware OCR-based Reward 的作用
图像里的文字是扩散模型很容易出错的部分。常见问题包括:
- 少字、多字、错字;
- 字符顺序错误;
- 字体大小异常;
- 文本位置偏移;
- 多行文本排版崩坏;
- 改了文字但破坏海报整体风格。
FireRed-Image-Edit 使用 Layout-Aware OCR-based Reward,也就是“布局感知的 OCR 奖励”。它在强化学习阶段不只检查识别出的字符内容,还检查字符布局、大小和位置。
flowchart LR
A[生成编辑结果] --> B[OCR 识别文字]
B --> C[检查字符内容]
B --> D[检查位置与布局]
B --> E[检查字号和排版]
C --> F[奖励分数]
D --> F
E --> F
F --> G[强化学习更新模型]
文字编辑示例如下,任务要求把海报右下角的 “programme” 修改为 “program ongoing”,同时保持字体和风格一致。

这个例子体现了文字编辑任务的两个约束:一是文本内容必须准确,二是替换后的文字要融入原海报,而不是像后期贴上去的一块新图层。布局感知奖励正是为了解决这类细节问题。
多图参考与创意编辑
FireRed-Image-Edit 支持多参考图编辑,也就是从一张或多张参考图中抽取对象、服饰、风格或布局信息,再融合到目标图中。相比单图编辑,多图参考更容易出现冲突:
- 参考图服装和目标人物姿态不一致;
- 参考物体视角和目标场景不匹配;
- 多张图风格不统一;
- 融合后主体身份发生变化。
多图参考编辑示例如下,指令要求模特穿上图 1 的服饰,并额外搭配指定材质、颜色和款式的骑行短裤以及耳环。

这种任务要求模型同时处理参考图视觉信息和文本补充约束。参考图提供服饰外观,文本指令提供额外搭配规则,模型需要把二者合并成一个自然结果。
画质修复也可以统一成指令编辑
画质修复通常会被拆成多个底层视觉任务,比如超分辨率、去模糊、去噪、补光、上色。FireRed-Image-Edit 把这些任务统一纳入指令微调框架,让用户可以直接用自然语言描述修复目标。
例如“修复并上色这张老照片,使其看起来像是用现代相机拍摄的”就是一个复合任务,里面包含去噪、增强清晰度、补全细节、色彩恢复和风格自然化。
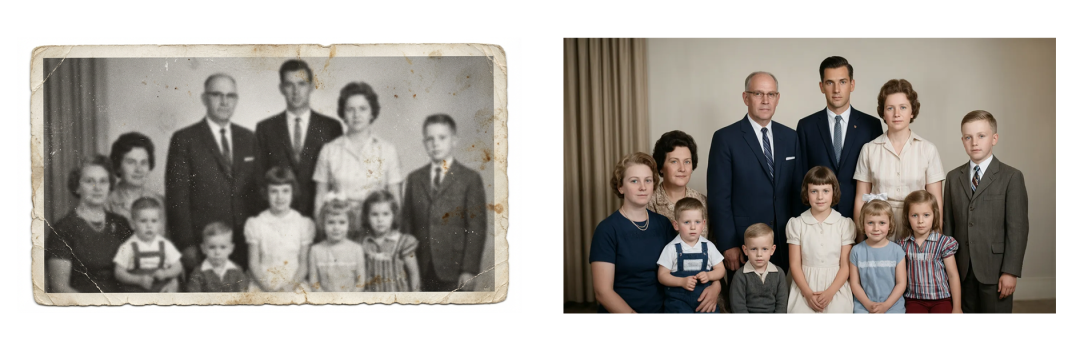
这类任务的难点在于不能过度生成。修复模型如果凭空添加太多不存在的细节,照片会看起来清晰,但真实性会下降。更合理的结果应该在增强画质的同时保持人物、场景和年代感的可信度。
FireRed-Image-Edit 的整体技术路线
把前面的设计合起来,可以看到 FireRed-Image-Edit 的核心路线并不只是“堆更大的模型”,而是围绕编辑任务的关键瓶颈做系统优化:
| 模块 | 核心设计 | 解决的问题 |
|---|---|---|
| 评测 | RedEdit Bench | 用复杂真实任务衡量模型,而不只看基础增删改 |
| 数据 | 三路径数据引擎 | 大规模构造可控、精准、多样的编辑数据 |
| 采样 | 多条件感知桶采样 | 平衡不同编辑任务,减少能力偏科 |
| 指令 | 随机动态指令 | 提升语义泛化,避免模板记忆 |
| 微调 | 高质量编辑数据 | 提升视觉自然度、主体一致性和局部编辑准确性 |
| 强化学习 | 非对称梯度优化 | 强化正样本反馈 |
| 文字编辑 | Layout-Aware OCR-based Reward | 同时约束字符正确性、位置、大小和布局 |
最终形成的编辑链路可以概括为:
flowchart TD
A[RedEdit Bench 定义复杂任务] --> B[数据引擎构造训练样本]
B --> C[去重与质量清洗]
C --> D[预训练获得通用编辑能力]
D --> E[高质量数据微调]
E --> F[强化学习优化难点任务]
F --> G[指令遵循、文字编辑、多图参考、画质修复]
适合和不适合的使用场景
FireRed-Image-Edit 更适合需要精细控制的图像编辑任务,尤其是自然语言指令比较复杂、需要保持原图主体一致的场景。
| 场景 | 适合程度 | 原因 |
|---|---|---|
| 海报文字替换 | 高 | OCR 奖励专门优化文字内容和布局 |
| 商品图局部修改 | 高 | 需要保留商品主体和风格 |
| 多参考图服饰搭配 | 高 | 支持参考图融合和文本约束 |
| 老照片修复 | 高 | 画质增强任务被纳入指令微调 |
| 纯文生图创作 | 中 | 模型重点是图像编辑,不是单纯从零生成 |
| 像素级工业检测 | 低 | 图像编辑模型不适合替代严格可解释的检测系统 |
| 法务级证件修复 | 低 | 生成式修复可能引入不可验证细节 |
使用时需要注意的坑
不要把图像编辑模型当成确定性工具。
扩散模型存在随机性,同一条指令多次运行可能得到不同结果。对文字、商品细节、身份一致性要求极高的场景,应保留人工审核。
复杂指令最好拆清楚。
如果同时要求换背景、换衣服、改文字、修脸、调色,模型需要满足的约束会变多。更稳定的做法是把任务拆成多个步骤,每一步只改一个主要目标。
文字越长,布局越难。
短文本替换通常更容易保持原样式;长段落、多行排版、特殊字体和复杂背景会显著提高难度。
修复类任务要警惕过度生成。
老照片修复、去模糊、超分辨率都可能生成不存在的纹理。用于纪实、档案或证据类材料时,需要谨慎使用。
FireRed-Image-Edit 的主要贡献在于把复杂图像编辑拆成评测、数据、训练和奖励四个层面系统处理。RedEdit Bench 负责定义更真实的难题,数据引擎负责产出可训练样本,三阶段训练负责逐步提升能力,布局感知 OCR 奖励则专门解决文字编辑这个高频痛点。对于需要自然语言控制、主体保持和多参考图融合的图像编辑任务,这套设计提供了一个清晰的实现范式。