视频剪辑难,不只难在软件按钮多,更难在“怎么把一堆素材组织成一个有节奏、有重点、有情绪的故事”。
传统剪辑工具解决的是执行问题:裁剪、拼接、转场、字幕、配乐、渲染。真正消耗创作者时间的,往往是更靠前的环节:选哪些镜头,按什么顺序排列,哪里需要铺垫,哪里需要情绪爆发,文案怎么跟画面对上,音乐鼓点怎么和转场同步。
FireRed-OpenStoryline 的定位不是一个自动套模板的剪辑器,而是一个视频智能创作 Agent。它接收自然语言指令和多媒体素材,理解用户想做什么,再把任务拆成多个剪辑步骤,调用工具完成素材分析、脚本生成、时间线规划、字幕、配乐和渲染。
它的关键变化在于:人不再围着剪辑软件的功能菜单转,而是用语言描述目标,并在过程中持续干预结果。
flowchart LR
A[用户输入<br/>文本指令/图片/视频素材] --> B[Agent Client<br/>理解意图与任务规划]
B --> C[Storyline Middleware<br/>上下文管理/参数补全/结果过滤]
C --> D[MCP Server<br/>标准化工具调用层]
D --> E[剪辑工具节点<br/>拆条/理解/规划/字幕/配乐/渲染]
E --> F[成片或中间时间线]
F --> G[用户自然语言反馈]
G --> B
C <--> H[(Agent Memory<br/>历史状态与执行结果)]
D <--> I[(Resources<br/>BGM/字体/素材库/Skills)]
FireRed-OpenStoryline 解决的不是“剪一刀”,而是完整创作链路
如果只看单个功能,很多视频工具都能做到自动字幕、自动配乐、自动转场。FireRed-OpenStoryline 的重点在于把这些能力组织成一条 Agentic Workflow,也就是由智能体自主规划、执行、观察结果并接受反馈的工作流。
它覆盖的视频创作链路大致可以拆成五层:
| 环节 | 传统做法 | FireRed-OpenStoryline 的做法 |
|---|---|---|
| 找素材 | 人工翻相册、看缩略图、拖进软件 | 用语义描述检索或筛选素材 |
| 理解素材 | 人眼判断镜头内容、情绪和可用片段 | 使用视觉语言模型理解人物、动作、情绪和画面变化 |
| 规划故事线 | 手动排列镜头、反复试节奏 | 根据主题目标生成剪辑结构和时间线 |
| 执行剪辑 | 手动裁剪、加字幕、配乐、卡点 | 调用 MCP 工具节点完成具体操作 |
| 迭代修改 | 回到时间线手动调整 | 用自然语言打断、修改、局部重做 |
这里的 Agent 不只是“帮你点按钮”。它需要把用户一句模糊的话变成可执行计划,例如:
用这组旅行素材剪一个 60 秒 Vlog,整体轻松一点,开头要有到达目的地的感觉,中间突出海边和晚餐,结尾收在夜景。
这个指令里没有给出镜头编号、起止时间、字幕内容、音乐类型和转场位置,但一个可用的剪辑 Agent 必须推导出这些信息。FireRed-OpenStoryline 的系统设计,正是围绕这个问题展开。
总体架构:Agent Client、MCP Server 和资源层
FireRed-OpenStoryline 的系统主要由三部分组成:Agent Client、MCP Server、Resources & Input。可以把它理解成“大脑、身体和素材库”的关系。
架构图展示了三个层次之间的连接方式:Agent Client 负责推理、规划和上下文管理;MCP Server 负责提供标准化工具;Resources & Input 提供用户素材、提示词、模型配置、字体、音乐和可复用技能。
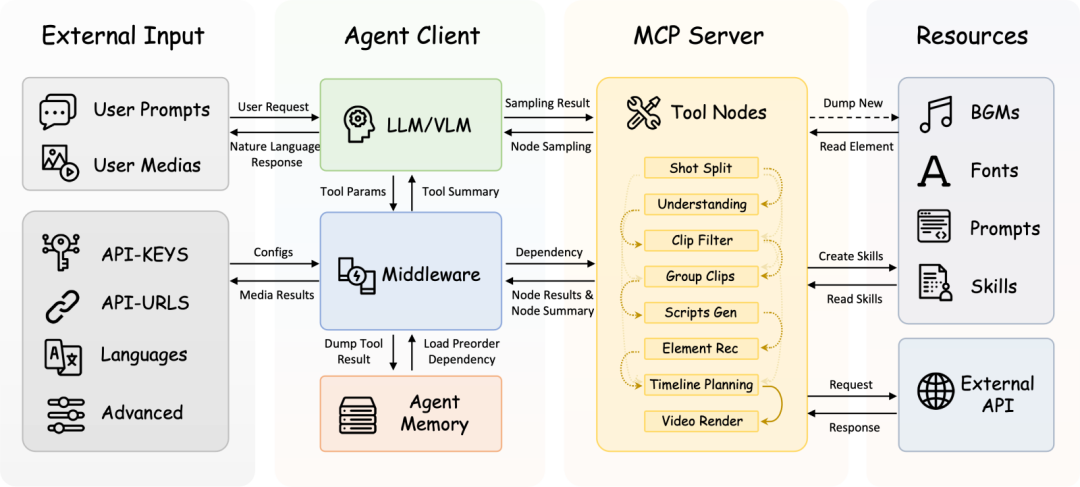
这套结构的重点不是把所有能力塞进一个大模型提示词里,而是让大模型负责决策,让工具负责确定性执行。剪辑任务很容易出现长链路、多步骤和反复修改,如果缺少中间层做状态管理,系统会很快遇到上下文混乱、参数缺失、调用不可控等问题。
Agent Client:负责理解意图、拆解任务和调度工具
Agent Client 是 FireRed-OpenStoryline 的决策中心,主要包括三块:LLM/VLM、Storyline Middleware 和 Agent Memory。
LLM 是 Large Language Model,大语言模型,负责理解自然语言、规划任务、生成文案和组织调用参数。VLM 是 Vision-Language Model,视觉语言模型,负责把视频帧、图片和文字语义联系起来,让系统能理解“画面里发生了什么”。
1. LLM/VLM:把用户目标转成剪辑计划
当用户输入一条指令后,系统并不会所有情况都直接进入剪辑流程。一个 Agent 需要先判断这句话属于哪类任务:
| 用户输入 | Agent 行为 |
|---|---|
| “这个项目能做什么?” | 直接自然语言回答 |
| “帮我找一些夏日海滩素材” | 调用素材检索工具 |
| “把第三个镜头缩短一点” | 定位当前时间线中的第三个镜头并修改 |
| “生成一个纪录片风格的旁白” | 结合画面内容生成文案 |
| “按这个风格保存成我的模板” | 总结剪辑规律并沉淀为 Skill |
这一步叫动态路由。它决定了请求是进入普通对话,还是进入工具调用链路。
视频剪辑任务往往不是一次工具调用就能完成的。比如生成一条 Vlog,可能要经历素材清洗、镜头拆切、高光片段识别、故事线规划、字幕生成、配乐选择、渲染预览等步骤。LLM/VLM 负责把这些动作排成合理顺序,并为每个工具准备输入参数。
2. Storyline Middleware:让大模型和工具之间更稳定
大模型擅长理解和生成,但它的输出并不总是稳定。对于剪辑工具来说,参数少一个字段、时间格式错一点、素材 ID 对不上,都可能导致流程中断。
Storyline Middleware 的作用就是在大模型和 MCP Server 之间加一层工程化缓冲。它主要解决三类问题。
上下文管理。
视频创作是长链路任务,Agent 需要知道用户上传了哪些素材,当前时间线是什么状态,上一次修改了哪里,哪些镜头已经被删除,哪些设置已经保存。Middleware 负责把这些上下文组织起来,避免每轮对话都从零开始。
参数容错。
如果大模型生成的工具调用参数不完整,中间件可以根据当前状态补齐默认值,或者触发 fallback 策略。例如用户说“字幕换成黄色”,没有说明哪一段字幕,系统可以结合当前选中片段或最近修改对象推断目标范围。
信息过滤。
工具节点可能返回大量中间结果,例如每一帧的分析信息、候选片段列表、渲染日志。如果全部塞回大模型上下文,Token 会迅速膨胀,还会降低推理质量。Middleware 需要把工具输出压缩成关键摘要,只保留后续决策真正需要的信息。
flowchart TB
A[LLM/VLM 生成工具调用意图] --> B{Middleware 校验}
B -->|参数完整| C[发送给 MCP Server]
B -->|参数缺失| D[根据上下文补齐]
D --> C
B -->|无法补齐| E[向用户追问或使用 fallback]
C --> F[工具返回结果]
F --> G[过滤冗余日志和大体积结果]
G --> H[写入 Agent Memory]
G --> I[摘要注入下一轮上下文]
3. Agent Memory:记录项目状态和历史操作
Agent Memory 用来保存工具执行结果、用户偏好、时间线状态和历史上下文。没有记忆的 Agent 很难处理连续修改,因为它不知道“刚才那段”“第三个镜头”“上次那个风格”分别指什么。
在剪辑场景里,记忆至少需要覆盖这些内容:
| 记忆内容 | 用途 |
|---|---|
| 素材列表和素材分析结果 | 方便后续检索、去重和重排 |
| 当前时间线结构 | 支持局部修改和回滚 |
| 用户修改历史 | 理解连续对话里的指代 |
| 字幕、字体、配乐选择 | 保持风格一致 |
| 已保存的 Editing Skill | 支持下次复用同类剪辑风格 |
这也是 Human-in-the-loop 能成立的基础。用户随时插入一句修改意见,Agent 必须知道当前工程进展到哪里,并且能在不破坏整体结构的前提下调整局部。
MCP Server:把剪辑能力封装成标准工具
MCP 是 Model Context Protocol,模型上下文协议。它的价值在于为模型和外部工具之间提供标准接口,让 Agent 可以用统一方式调用不同能力。
在 FireRed-OpenStoryline 中,MCP Server 扮演工具执行层。各种剪辑能力会被拆成原子化 Tool Nodes,例如:
| 工具节点 | 负责的能力 |
|---|---|
| 素材检索 | 根据语义、主题或氛围查找素材 |
| 视频拆切 | 将长视频切成更小的候选片段 |
| 内容理解 | 识别人物、动作、场景、情绪和画面变化 |
| 高光提取 | 找出更适合入片的片段 |
| 时间线规划 | 决定镜头顺序、时长和节奏 |
| 文案生成 | 生成旁白、标题、字幕或分镜说明 |
| 配乐选择 | 根据情绪目标匹配 BGM(背景音乐) |
| 卡点剪辑 | 让镜头切换与音乐节拍对齐 |
| 字幕样式 | 设置字体、颜色、位置和动效 |
| 渲染导出 | 输出最终视频或预览版本 |
这种拆法有两个好处。
一个是可维护。每个工具节点只负责一类确定性任务,出问题时可以定位到具体节点,而不是在一个巨大的黑盒里排查。
另一个是可扩展。开发者如果想给 Agent 增加新能力,不需要重写整个系统,只要把新能力封装成符合 MCP 接口的工具节点。例如增加一个 AI 生图节点、一个自动封面生成节点,或者接入新的语音合成工具,都可以通过工具层扩展。
flowchart LR
A[Agent 决策] --> B[MCP Server]
B --> C[素材检索工具]
B --> D[视频理解工具]
B --> E[时间线规划工具]
B --> F[字幕工具]
B --> G[配乐工具]
B --> H[渲染工具]
C --> I[工具结果]
D --> I
E --> I
F --> I
G --> I
H --> I
I --> A
Resources & Input:素材、资源和技能沉淀
FireRed-OpenStoryline 的输入不只是文本提示词,还包括图片、视频、资源库和模型配置。
外部输入
用户可以提供两类输入:
- Prompts:自然语言任务描述,例如“剪成轻松旅行风格”“字幕不要太花”“节奏快一点”。
- Image/Video:图片和视频素材,用于构建具体剪辑内容。
系统还支持动态配置 LLM API(应用程序编程接口),这意味着底层模型可以根据部署环境切换。复杂理解和规划交给云端模型,本地机器主要负责 Agent 流程和渲染相关工作。
资源库
资源库保存剪辑时会用到的素材资产,包括:
- BGM;
- 字体;
- 贴纸或视觉元素;
- 可复用的 Editing Skill;
- 用户偏好的风格配置。
其中 Editing Skill 是 FireRed-OpenStoryline 比较有辨识度的设计。它不是普通模板,而是从一次满意的剪辑结果中总结出可复用规律,例如节奏、色调、镜头取舍、转场习惯、字幕风格和叙事结构。
假设用户做出了一条满意的“周末城市散步 Vlog”,可以让 Agent 抽取它的剪辑逻辑并保存为一个 Skill。下次再上传类似素材时,Agent 可以调用这个 Skill,让新视频继承相近的叙事和视听风格。
从素材到成片:一次典型工作流
一个完整剪辑任务可以抽象成以下流程:
sequenceDiagram
participant U as 用户
participant A as Agent Client
participant M as Storyline Middleware
participant S as MCP Server
participant R as Resources/Memory
U->>A: 上传素材并描述目标
A->>M: 拆解任务,准备工具调用
M->>R: 读取历史偏好和可用资源
M->>S: 调用素材分析与拆切工具
S-->>M: 返回片段、标签和高光候选
M->>A: 注入精简后的分析结果
A->>M: 生成故事线和时间线计划
M->>S: 调用字幕、配乐、卡点和渲染工具
S-->>M: 返回预览结果
M->>R: 保存时间线状态
M-->>U: 返回预览视频
U->>A: 用自然语言提出修改
A->>M: 定位修改目标
M->>S: 执行局部调整
S-->>U: 返回更新后的结果
这个流程里有一个关键点:用户不需要等最终渲染完才发现方向不对。只要系统保存了中间状态,用户就能在任意阶段插入修改指令,例如:
第三个镜头太长,缩到 2 秒以内。
开头不要直接进海边,先放一段路上的镜头。
字幕颜色换成黄色,但不要改字体。
这段旁白太正式,改成更像朋友聊天的语气。
音乐鼓点出来的时候再切到夜景。
这些指令都不是传统剪辑软件里的结构化参数,但 Agent 可以把它们翻译成时间线修改、字幕样式修改、文案重写或配乐调整。
关键能力拆解
语义级素材检索
素材多的时候,人工翻找会非常慢。语义检索的目标是让用户用自然语言描述素材,而不是记住文件名或拍摄时间。
例如:
找一些夏日海滩、阳光、朋友玩水的素材。
Agent 可以在素材库中搜索画面语义接近的片段,再把这些片段送入后续剪辑流程。这里的重点不是简单匹配文件名,而是理解画面内容。
智能拆切与高光提取
视频素材通常包含大量无效片段,例如抖动、重复、过曝、无主题画面。FireRed-OpenStoryline 会先对素材做拆切,再理解片段内容,从中筛出更适合入片的部分。
这个过程通常会参考:
- 画面是否稳定;
- 人物或主体是否清晰;
- 动作是否完整;
- 情绪是否明显;
- 与用户主题是否相关;
- 和其他片段是否重复。
拆切不是为了把视频切碎,而是为了让 Agent 获得可组合的叙事单元。只有先得到片段级素材,后续故事线规划才有基础。
文案生成与音画同步
短视频文案不能只看用户提示词生成,还要看画面。否则就会出现画面在海边奔跑,旁白却在讲不相关内容的情况。
更合理的流程是:
- 先分析每个镜头的画面内容和情绪;
- 再根据镜头顺序生成旁白或字幕;
- 根据剪辑节奏控制句子长短;
- 在画面转折处安排文案转折;
- 在情绪递进处增加更强的表达。
例如,一个从“出发路上”到“到达海边”再到“傍晚聚餐”的 Vlog,可以让文案跟着画面推进,而不是把所有感受堆在开头。
配乐和卡点
配乐不是简单地随机选一首歌。Agent 需要根据视频目标判断音乐情绪,再结合时间线做节奏匹配。
如果用户说“轻松一点,有夏天的感觉”,系统可能会优先选择明亮、节奏不太压迫的 BGM。如果用户说“燃一点,像运动集锦”,系统则需要选择鼓点更强、切点更密的音乐。
卡点剪辑的本质是让镜头切换、动作高潮和音乐节拍对齐。工具层可以负责分析音乐节拍,Agent 则负责决定哪些镜头适合放在节奏点上。
Human-in-the-loop:自然语言参与全链路修改
Human-in-the-loop 指人在系统运行过程中持续参与,而不是只在开头输入需求、结尾验收结果。
FireRed-OpenStoryline 的交互方式更接近“用户坐在剪辑师旁边提修改意见”:
| 用户反馈 | Agent 需要完成的动作 |
|---|---|
| “这段太拖了” | 定位相关片段并缩短时长 |
| “字幕太抢眼” | 调整字号、颜色或透明度 |
| “前面铺垫不够” | 重排镜头,增加过渡片段 |
| “不要这么像广告” | 重写文案,降低营销感 |
| “整体再克制一点” | 调整配乐、转场和字幕风格 |
这类指令的难点在于它们往往不精确。系统要结合当前时间线、最近操作和用户偏好来推断具体修改对象。
Editing Skill:把一次满意结果沉淀成可复用能力
模板通常是固定的,适合套相同结构的视频。Editing Skill 更像是风格记忆,它保存的是剪辑决策规律。
一个 Skill 可以包含:
name: weekend-vlog-style
story_structure:
- opening: 用环境镜头建立地点
- middle: 用人物动作和细节镜头推进
- ending: 用夜景或远景收束
visual_style:
pace: 中等偏慢
transition: 少量自然转场
subtitle: 简洁白色字幕
audio:
bgm_mood: 轻松
voiceover_style: 朋友聊天感
editing_preference:
highlight_duration: 2-4 秒
avoid: 过度花哨特效
实际实现不一定使用这个格式,但它表达了 Skill 的意义:把剪辑风格从单个成片中抽象出来,供后续项目调用。
适合和不适合的场景
FireRed-OpenStoryline 更适合“需要快速形成故事线,并允许通过自然语言反复调整”的视频创作场景。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| Vlog、旅行记录、生活方式短视频 | 适合 | 素材量大,叙事结构相对灵活,适合自动筛选和重排 |
| 批量生产同类账号内容 | 适合 | Editing Skill 可以复用风格,减少重复配置 |
| 素材库语义检索和粗剪 | 适合 | Agent 可以先完成筛选、拆条和初版时间线 |
| Agentic Workflow 学习和二次开发 | 适合 | MCP 工具层和中间件设计有参考价值 |
| 影视级精修和逐帧特效 | 不太适合 | 仍然需要专业剪辑师做精细控制 |
| 对画面、声音、调色有严格广播级要求的项目 | 不太适合 | 自动流程更适合初剪和辅助,不适合作为唯一质检 |
| 完全离线且不能调用云端大模型的环境 | 不太适合 | 系统设计支持本地跑核心流程,但理解和规划依赖可用模型 |
| 涉及版权、肖像、敏感内容的商业发布 | 需要人工审核 | 自动生成结果不能替代合规检查 |
开发者怎么上手
FireRed-OpenStoryline 已经开源,代码库地址:
https://github.com/FireRedTeam/FireRed-OpenStoryline
体验地址:
https://fireredteam-firered-openstoryline.hf.space/
本地上手可以按这个思路准备:
git clone https://github.com/FireRedTeam/FireRed-OpenStoryline.git
cd FireRed-OpenStoryline
运行前需要关注几个配置点:
| 配置项 | 说明 |
|---|---|
| LLM/VLM API | 用于自然语言理解、视觉理解和任务规划 |
| 素材目录 | 放置待剪辑图片、视频或素材库 |
| Resources | 准备 BGM、字体等可选资源 |
| Docker | 项目支持容器化启动,具体命令以仓库说明为准 |
| CPU/GPU | 核心 Agent 流程可以在普通笔记本 CPU(中央处理器)上跑通,不强依赖本地 GPU(图形处理器) |
一次典型使用可以这样组织:
1. 启动服务
2. 上传一组视频或图片素材
3. 输入剪辑目标
4. 等待 Agent 生成初版时间线或预览
5. 用自然语言修改局部结果
6. 满意后导出视频
7. 将风格保存为 Editing Skill,后续复用
可以尝试的提示词:
用这些素材剪一个 60 秒旅行 Vlog,节奏轻松,开头突出出发感,中间多放海边和朋友互动,结尾用夜景收束。
把前 10 秒节奏加快一点,字幕改成更口语化的表达,音乐不要太吵。
保留这条片子的剪辑风格,保存成“周末 Vlog Skill”,下次类似素材继续用。
工程实现里最容易踩的坑
工具粒度不能太粗,也不能太碎
如果一个工具节点承担太多职责,例如“自动剪完整条视频”,Agent 很难做局部修改,也很难解释中间结果。
如果工具拆得过碎,例如每一个字幕字色都变成独立工具,调用链会变长,状态管理也会复杂。
更合理的做法是按剪辑语义拆工具:素材分析、片段拆切、时间线规划、字幕生成、配乐、渲染,各自边界清晰。
大模型输出必须经过校验
剪辑工具通常需要严格参数,例如素材 ID、时间戳、轨道编号、字幕样式。大模型生成的参数不能直接送入执行层,必须经过 Middleware 校验、补齐和转换。
一个稳定系统至少要检查:
- 素材是否存在;
- 时间范围是否合法;
- 片段是否重叠或越界;
- 字幕样式是否可用;
- 工具必填参数是否缺失;
- 输出格式是否符合 MCP Server 约定。
上下文不能无限塞
视频分析结果很容易变得很大。每个片段的帧信息、标签、转写、置信度、候选排序都塞进上下文,会迅速消耗 Token,并让模型注意力变差。
更稳的方式是把完整结果存在 Memory 或文件系统里,只把摘要交给模型。例如:
{
"clip_id": "clip_023",
"summary": "海边傍晚,人物走向镜头,情绪轻松",
"suggested_use": "适合作为结尾前的过渡镜头",
"duration": 3.8
}
非破坏性修改很重要
用户说“把第三个镜头换掉”时,系统不应该把整条时间线推倒重来。更好的方式是保留时间线结构,只替换目标片段,并重新计算受影响的字幕、配乐和转场。
这要求系统保存可编辑的项目状态,而不是只保存最终视频文件。
Skill 不能替代素材质量
Editing Skill 可以复用风格,但不能让低质量素材自动变成高质量作品。如果素材本身模糊、重复、缺少主体或情绪不足,Agent 能做的是筛选和组织,而不是凭空补出完整叙事。
FireRed-OpenStoryline 的价值在于“可对话的剪辑系统”
视频创作 Agent 的难点不是单点模型能力,而是把理解、规划、执行、反馈和记忆串成一个稳定系统。
FireRed-OpenStoryline 给出的方案是:用 LLM/VLM 负责理解和决策,用 Storyline Middleware 保证上下文与参数稳定,用 MCP Server 标准化工具调用,再通过 Resources 和 Editing Skill 保存资源与用户风格。
这种架构让视频剪辑从“人手动拖时间线”逐渐变成“人定义目标,Agent 生成并执行方案,人再持续干预”。对于创作者,它降低了从素材到成片的操作成本;对于开发者,它提供了一个用 MCP 构建多工具 Agent 的完整参考。