检索增强生成 RAG(Retrieval-Augmented Generation,检索增强生成)常见做法是:把文档切成文本块,向量化后放进索引;用户提问时,检索最相似的几个文本块,再交给 LLM(Large Language Model,大型语言模型)生成答案。
这种方式适合回答“答案藏在少数几个片段里”的问题,例如:
| 问题 | 简单 RAG 是否适合 | 原因 |
|---|---|---|
| 某份报告里提到的预算是多少? | 适合 | 答案通常位于一个或几个文本块中 |
| 某个人在哪次访谈里谈到某个观点? | 适合 | 可以通过关键词或语义相似度找到相关片段 |
| 这个数据集里的主要主题是什么? | 不太适合 | 答案分散在整个语料库中 |
| 多年来新闻报道中的技术趋势如何变化? | 不太适合 | 需要综合大量文档,而不是检索几个片段 |
| 不同受访者对 AI 风险的共识和分歧有哪些? | 不太适合 | 需要跨文档归纳、对比和抽象 |
后面这类问题更接近 QFS(Query-Focused Summarization,查询聚焦摘要):用户给出一个问题,系统要围绕这个问题总结整个语料库。问题的答案不一定出现在某一段文字里,而是要把很多局部信息拼起来,形成全局判断。
GraphRAG 的核心思路是:不要只把语料库看成一堆独立文本块,而是先从文本中抽取实体、关系和声明,构造成一个知识图,再利用图天然的社区结构,把全局语料拆成多个主题社区。查询时,每个社区先给出局部答案,最后再汇总成全局答案。
为什么简单 RAG 很难回答全局问题
简单 RAG 的工作方式可以简化成下面这条链路:
flowchart LR
A[用户问题] --> B[向量检索]
B --> C[Top-K 文本块]
C --> D[LLM 生成答案]
D --> E[返回结果]
它的问题不在于检索做得不好,而在于任务本身不适合“只取 Top-K”。
假设语料库有 3000 个文本块,用户问:“这些新闻报道中主要有哪些科技主题?”向量检索可能会找出和“科技主题”语义最接近的几十个块,但这些块不一定覆盖所有重要主题。更麻烦的是,主题可能分散在大量文档里,单个文本块只能提供局部证据。
把更多文本塞进上下文窗口也不是万能方案。长上下文模型虽然能接收更多 token,但信息越长,模型越容易忽略中间位置的内容,也更难稳定地做全局归纳。全局摘要需要的是一种“先组织知识,再回答问题”的索引方式。
GraphRAG 就是为这种场景设计的。
GraphRAG 的整体流程
GraphRAG 分成两个阶段:
- 离线索引阶段:把源文档加工成知识图,并为图社区生成摘要。
- 在线查询阶段:针对用户问题,让社区摘要分别生成部分答案,再汇总成最终答案。
GraphRAG 的主流程可以这样理解:
flowchart LR
A[源文档] --> B[文本切块]
B --> C[抽取实体、关系、声明]
C --> D[合并并摘要图元素]
D --> E[构建加权知识图]
E --> F[社区检测]
F --> G[社区摘要]
Q[用户问题] --> H[社区摘要分批]
G --> H
H --> I[Map: 生成社区答案并打分]
I --> J[过滤与排序]
J --> K[Reduce: 汇总全局答案]
这张流程图展示了 GraphRAG 如何把文本语料转换成可查询的图索引:
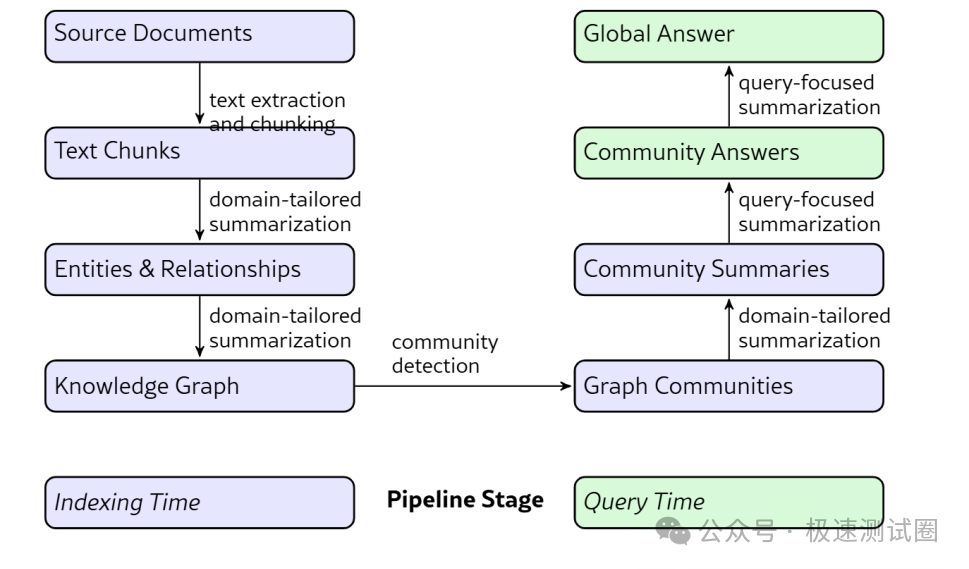
图中左侧是索引流程:源文档先被切成文本块,再由 LLM 抽取节点、边和附加信息,随后通过社区检测得到一组覆盖整个图的社区。右侧是查询流程:用户提问后,每个社区摘要都可以作为一个局部视角参与回答,最终通过 Map-Reduce 汇总为全局答案。
源文档如何切成文本块
文本块大小是 GraphRAG 的第一个关键参数。
文本块太短,LLM 调用次数会变多,成本上升;文本块太长,单次调用虽然覆盖更多内容,但抽取质量会下降,尤其容易漏掉实体和关系。
在实体抽取任务中,较短文本块通常能带来更高召回率。下面的实验结果展示了文本块大小和补提取轮次对实体引用数量的影响:
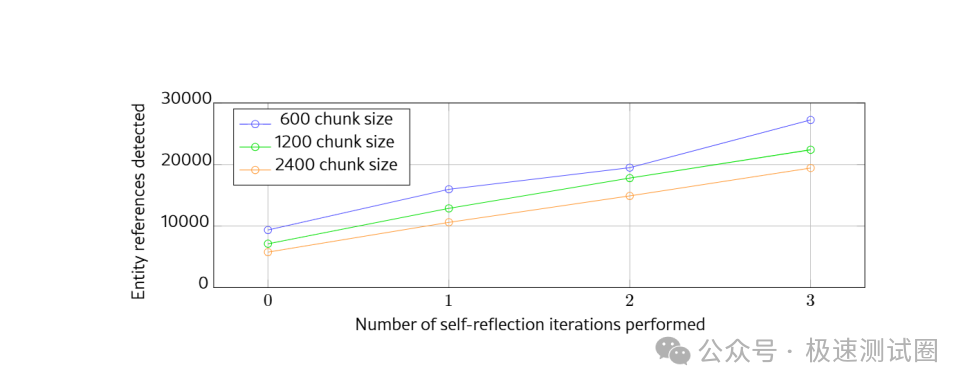
上面的结果说明了一个实际问题:如果只做一次抽取,600 token 文本块能抽到的实体引用明显多于 2400 token 文本块。原因很直接,短上下文里信息密度更可控,LLM 不容易漏掉细节。
但短文本块也会增加调用次数。GraphRAG 使用一种“补提取”机制缓解这个矛盾:先让 LLM 做一轮实体和关系抽取,再询问它是否遗漏了实体;如果判断有遗漏,就追加一轮提示,让它补充上一轮没有抽到的内容。
伪代码可以写成这样:
def extract_with_gleaning(chunk: str, max_rounds: int = 2):
result = extract_entities_and_relations(chunk)
for _ in range(max_rounds):
missed = ask_llm_yes_no(
chunk=chunk,
previous_result=result,
question="是否还有重要实体或关系没有被抽取?只回答 yes 或 no。"
)
if missed == "no":
break
extra = extract_missing_entities_and_relations(
chunk=chunk,
previous_result=result
)
result = merge_extraction_result(result, extra)
return result
这种做法的目标不是无限追求更多实体,而是在召回率、噪声和成本之间取得平衡。
从文本块中抽取图元素
GraphRAG 的索引不是直接存文本块,而是从文本块中抽取三类信息:
| 元素 | 在图中的角色 | 示例 |
|---|---|---|
| 实体 Entity | 节点 | 人、组织、地点、技术、产品、事件 |
| 关系 Relationship | 边 | “A 任职于 B”“A 支持 B”“A 与 B 合作” |
| 声明 Claim / Covariate | 附加信息 | 某实体相关的观点、事实、时间范围、来源片段 |
一个常见的抽取结果可以设计成结构化 JSON:
{
"entities": [
{
"name": "OpenAI",
"type": "organization",
"description": "一家从事人工智能模型研发的组织"
},
{
"name": "GPT-4",
"type": "technology",
"description": "OpenAI 发布的大型语言模型"
}
],
"relationships": [
{
"source": "OpenAI",
"target": "GPT-4",
"description": "OpenAI 发布并维护 GPT-4",
"strength": 1.0
}
],
"claims": [
{
"subject": "GPT-4",
"object": "多模态能力",
"type": "capability",
"description": "GPT-4 被描述为具备处理复杂语言任务的能力",
"source_span": "..."
}
]
}
抽取提示通常需要包含少量示例。通用语料可以抽取人名、组织、地点、事件等命名实体;医学、法律、金融、科研等专业语料则需要定制实体类型和示例,否则 LLM 容易抽到过宽或不稳定的概念。
从元素实例到图元素摘要
同一个实体可能在不同文本块中出现多次,而且写法不完全一致。例如:
- “Microsoft”
- “微软”
- “Microsoft Corporation”
- “这家软件公司”
如果每种写法都变成一个独立节点,图会变得很噪。但 GraphRAG 并不要求像传统知识图谱那样把所有三元组都标准化到极致,它更依赖 LLM 的描述性摘要能力。
处理方式大致是:
- 将同名或高度相似的实体实例聚合。
- 把多个实例的描述合并成一个实体摘要。
- 把多次出现的关系合并成一条边,并用出现次数或归一化计数作为权重。
- 把声明、证据片段、时间信息作为节点或边的附加信息保存。
最终得到的是一个同质、无向、加权图:
import networkx as nx
G = nx.Graph()
for entity in entities:
G.add_node(
entity["id"],
name=entity["name"],
type=entity["type"],
description=entity["summary"]
)
for rel in relationships:
if G.has_edge(rel["source"], rel["target"]):
G[rel["source"]][rel["target"]]["weight"] += rel["weight"]
G[rel["source"]][rel["target"]]["descriptions"].append(rel["description"])
else:
G.add_edge(
rel["source"],
rel["target"],
weight=rel["weight"],
descriptions=[rel["description"]]
)
这个图不是为了做严格逻辑推理,而是为了给全局摘要提供结构。节点的描述、边的描述和附加声明越丰富,后续社区摘要越容易保留语义信息。
用社区检测把图拆成主题模块
知识图构建好以后,需要把它划分成多个社区。图社区的含义是:社区内部节点之间连接更紧密,和外部节点连接相对更弱。
这很适合语料库摘要。因为同一个主题下的人物、组织、事件和概念往往会形成密集连接,社区检测算法可以把它们自动聚在一起。
GraphRAG 使用 Leiden 算法做分层社区检测。Leiden 算法适合大规模图,并且可以产生多层社区结构:
flowchart TB
C0[根级社区 C0<br/>数量少,粒度粗] --> C1[高级社区 C1]
C1 --> C2[中级社区 C2]
C2 --> C3[低级社区 C3<br/>数量多,粒度细]
社区层级越高,摘要越粗,token 成本越低;社区层级越低,摘要越细,覆盖的信息更具体,但查询时需要处理的上下文更多。
下面的图展示了实体图被社区检测算法划分后的效果:
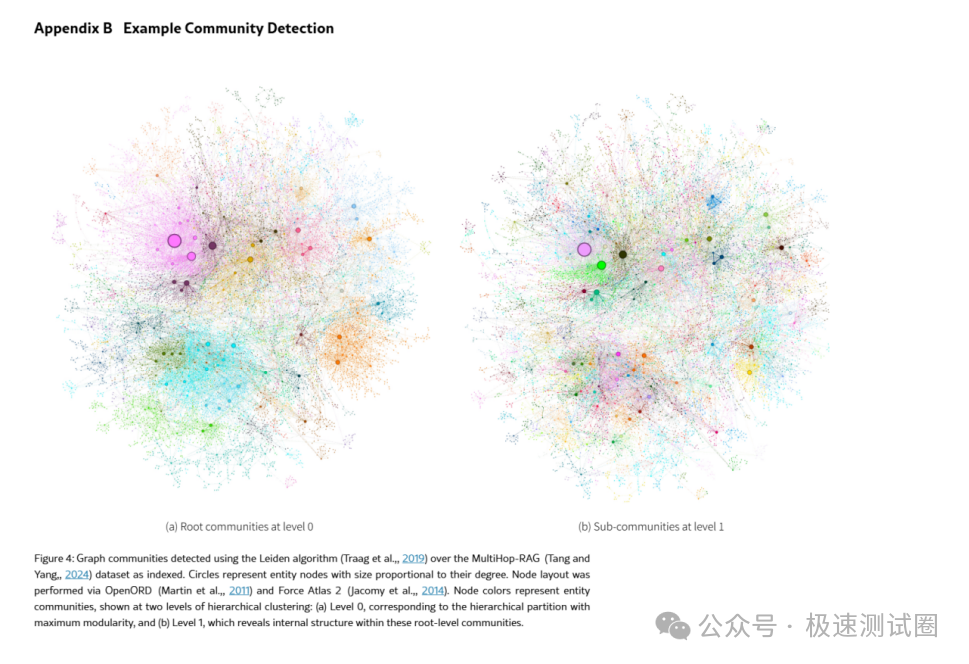
图里的圆点代表实体节点,节点大小和连接度有关,颜色代表不同社区。可以看到,图并不是均匀散开的,而是天然形成多个相对紧密的模块。GraphRAG 利用的正是这种模块化结构。
社区摘要如何生成
社区检测完成后,每个社区都要生成一份“社区报告”。这份报告不是回答某个用户问题,而是对该社区内部实体、关系和声明的通用总结。
叶子社区和上层社区的处理方式略有不同。
叶子社区
叶子社区的元素数量通常较少,可以直接把节点、边和声明放进 LLM 上下文窗口中生成摘要。
为了优先保留重要信息,可以按照边的重要性排序。常见做法是根据源节点和目标节点的度数计算优先级:连接越多的实体越可能重要,相关边也应该更早进入上下文。
def rank_edges_for_leaf_community(G, community_nodes):
edges = []
for u, v, data in G.subgraph(community_nodes).edges(data=True):
importance = G.degree[u] + G.degree[v]
edges.append((importance, u, v, data))
return sorted(edges, reverse=True, key=lambda x: x[0])
然后把这些信息组织成输入:
社区元素:
- 实体 A:描述……
- 实体 B:描述……
- 关系 A -> B:描述……
- 相关声明:……
请生成一份社区摘要,要求:
1. 概括社区的核心主题;
2. 说明关键实体及其关系;
3. 保留重要事实、观点和时间线索;
4. 用清晰的小标题组织内容。
上层社区
上层社区包含多个子社区。如果所有原始元素都能放进上下文窗口,就直接摘要;如果放不下,就用子社区摘要替代大量细节。
这相当于做了一次递归压缩:
flowchart BT
A[实体、关系、声明] --> B[叶子社区摘要]
B --> C[中级社区摘要]
C --> D[高级社区摘要]
D --> E[根级社区摘要]
这种分层摘要有两个好处:
- 全覆盖:每个节点都属于某个社区,社区摘要可以覆盖整张图。
- 可调粒度:查询时可以选择 C0、C1、C2 或 C3,不同层级对应不同成本和细节程度。
查询阶段:社区答案到全局答案
用户提问时,GraphRAG 不直接从文本块检索 Top-K,而是让社区摘要参与回答。
查询过程分成 Map 和 Reduce 两步。
Map:每批社区摘要生成部分答案
社区摘要会被随机打乱,再按 token 上限切成多个批次。随机打乱的目的,是避免相关信息全部集中在某一个长上下文中,导致模型处理不稳定。
每个批次独立调用 LLM:
用户问题:
{question}
社区摘要:
{community_reports}
请基于这些社区摘要回答问题。
如果这些摘要无法支持回答,请说明无关。
同时给出一个 0 到 100 的分数,表示该答案对回答问题的帮助程度。
输出可以设计成:
{
"answer": "这批社区摘要显示,语料库中反复出现的主题包括……",
"score": 82
}
得分为 0 的答案会被过滤掉,剩余答案按分数排序。
Reduce:汇总部分答案
Reduce 阶段把高分部分答案放入新的上下文窗口,再生成最终答案:
用户问题:
{question}
候选部分答案:
1. {answer_1}
2. {answer_2}
3. {answer_3}
请综合这些部分答案,生成一个完整、结构化、避免重复的全局回答。
需要保留不同观点和关键证据。
整个查询链路可以表示为:
sequenceDiagram
participant U as 用户
participant S as GraphRAG系统
participant C as 社区摘要集合
participant M as LLM Map阶段
participant R as LLM Reduce阶段
U->>S: 提出全局问题
S->>C: 读取指定层级的社区摘要
S->>S: 随机打乱并按token分批
S->>M: 每批生成部分答案和帮助分数
M-->>S: 返回多个候选答案
S->>S: 过滤0分答案并按分数排序
S->>R: 汇总高分候选答案
R-->>U: 返回全局答案
C0、C1、C2、C3 应该怎么选
不同社区层级适合不同查询需求。
| 层级 | 粒度 | 成本 | 适合的问题 | 可能的不足 |
|---|---|---|---|---|
| C0 | 最粗 | 最低 | “整个语料库的大主题是什么?” | 细节较少,容易过度概括 |
| C1 | 较粗 | 低 | “主要主题下有哪些子方向?” | 对局部事实覆盖有限 |
| C2 | 中等 | 中等 | “不同主题之间的观点和关系是什么?” | 成本高于 C0/C1 |
| C3 | 最细 | 较高 | “需要更丰富细节和多样视角的问题” | 社区数量多,Map 阶段调用更多 |
| 源文本 Map-Reduce | 原始粒度 | 最高 | 不想构建图索引、一次性全局摘要 | token 消耗大,重复信息多 |
| 简单 RAG | 局部检索 | 低 | 明确事实问答 | 不适合全局归纳 |
经验上,C2 和 C3 更容易在全面性和多样性上取得较好结果;C0 成本极低,适合快速获得全局概览,但答案可能不够细。
GraphRAG 和源文本 Map-Reduce 的区别
不用图也能做全局摘要:把所有源文本打乱、分批,让每批文本回答问题,再汇总部分答案。这就是源文本 Map-Reduce。
GraphRAG 和它的区别在于,GraphRAG 在 Map 阶段使用的是社区摘要,而不是原始文本块。
| 对比项 | 源文本 Map-Reduce | GraphRAG |
|---|---|---|
| 上下文输入 | 原始文本块 | 社区摘要 |
| 是否预先组织知识 | 否 | 是 |
| 是否利用实体关系 | 弱 | 强 |
| token 成本 | 高 | 较低 |
| 重复信息 | 多 | 社区摘要已压缩 |
| 多次查询复用 | 复用程度低 | 图索引和社区摘要可反复使用 |
| 初始索引成本 | 低 | 高 |
如果只对一个数据集问一次问题,源文本 Map-Reduce 可能已经足够。如果要围绕同一个语料库反复提问,GraphRAG 的索引成本更容易被摊薄。
实验中的 token 统计也体现了这种差异:

表中对比了不同条件下的上下文单元数量和 token 使用量。根级社区摘要 C0 的 token 成本最低,低级社区摘要 C3 的成本高一些,但仍少于直接使用源文本做 Map-Reduce。换句话说,GraphRAG 先在索引阶段做了一次结构化压缩,查询阶段就不必反复扫描大量原始文本。
评估方式和结果
GraphRAG 的评估重点不是“能不能找到某个事实”,而是全局理解能力。
测试使用了两类接近真实场景的语料:
| 数据集 | 内容 | 规模 |
|---|---|---|
| 播客转录 | 技术访谈对话 | 约 100 万 token |
| 新闻文章 | 娱乐、商业、体育、技术、健康、科学等新闻 | 约 170 万 token |
问题不是人工写死的细节题,而是根据“潜在用户、用户任务、需要理解整个语料库的问题”自动生成。每个数据集生成 125 个测试问题,更接近“我要理解这批资料”的场景。
评估指标有四个:
| 指标 | 含义 |
|---|---|
| 全面性 | 是否覆盖问题涉及的多个方面和细节 |
| 多样性 | 是否提供不同视角、主题和见解 |
| 赋权 | 是否帮助用户形成理解并做出判断 |
| 直接性 | 是否清楚、具体地回答问题 |
评估采用 LLM-as-Judge:给定同一个问题和两种方法生成的答案,让 LLM 判断哪个答案在某个指标上更好。为了降低随机性,每组比较重复多次后取平均。
实验结果可以概括为:
- 所有全局方法在全面性和多样性上都明显优于简单 RAG。
- 简单 RAG 的答案通常更直接,但覆盖范围较窄。
- GraphRAG 的中低层社区摘要在全面性、多样性上通常能达到或超过源文本 Map-Reduce,同时 token 成本更低。
- 根级社区摘要 C0 成本最低,虽然细节少于 C2/C3,但仍能明显超过简单 RAG 的全局回答能力。
下面的结果矩阵展示了不同方法在多个指标上的头对头胜率:
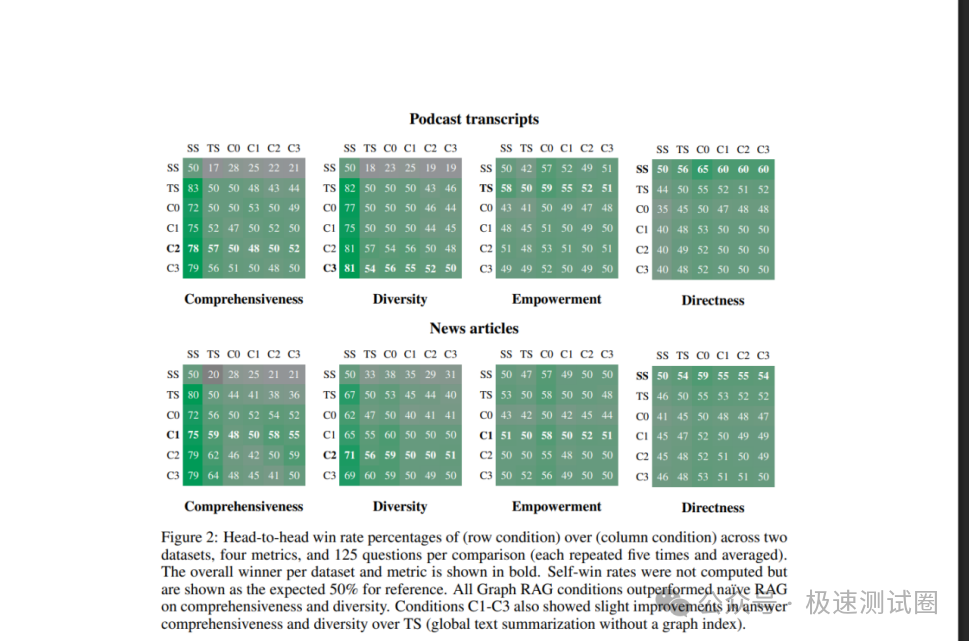
矩阵中的核心信号是:简单 RAG 在“直接性”上有优势,因为它倾向于围绕少数检索片段回答;GraphRAG 和源文本 Map-Reduce 在“全面性”和“多样性”上更强,因为它们覆盖了更多语料范围。对于全局问题,直接但狭窄的答案往往不够用,能否覆盖多主题、多视角更关键。
为什么 8k 上下文可能比更长上下文更好
直觉上,上下文窗口越大,答案应该越好。但实验中,8k token 上下文在全面性上反而表现更稳定,16k、32k、64k 并没有带来明显收益。
原因可能有两个:
- 更长上下文会带来更多无关或重复信息,模型需要在噪声中筛选重点。
- 长上下文存在“中间信息丢失”问题,放进去的信息不一定都能被同等利用。
这对工程实现很有启发:不要简单地把上下文窗口拉满。更好的策略通常是先压缩和组织信息,再把高质量上下文交给模型。
适合使用 GraphRAG 的场景
GraphRAG 适合“同一个语料库会被反复分析”的场景,例如:
| 场景 | 为什么适合 |
|---|---|
| 企业内部知识库分析 | 多部门、多文档、问题经常是全局性的 |
| 新闻和舆情分析 | 需要总结主题、趋势、人物组织关系 |
| 访谈和会议转录分析 | 观点分散在多段对话中 |
| 科研文献集合分析 | 需要跨论文提炼主题、方法和争议 |
| 情报和调查分析 | 实体关系、事件线索和全局模式都很重要 |
不太适合的场景也很明确:
| 场景 | 原因 |
|---|---|
| 只问少量事实型问题 | 简单 RAG 成本更低 |
| 数据集很小,能完整放进上下文 | 直接摘要即可 |
| 实体和关系不重要的纯格式化文本 | 图结构收益有限 |
| 对答案引用精确性要求极高 | 需要额外设计证据回溯和引用机制 |
落地实现时的几个关键点
1. 抽取提示要按领域定制
通用实体类型不一定适合专业语料。医学语料可能需要疾病、药物、症状、治疗方案;法律语料可能需要案件、法规、主体、责任、判决;金融语料可能需要公司、指标、风险、交易、监管事件。
实体类型设计得太宽,图会变得松散;设计得太细,抽取会不稳定。比较稳妥的方式是先用小样本调试提示,再观察抽取结果的重复节点、孤立节点和错误关系。
2. 不要追求完美知识图谱
GraphRAG 的图索引主要服务于摘要,不是严格的逻辑推理系统。实体别名、关系表述不完全一致,并不一定会毁掉效果。只要相关实体之间连接足够密,社区检测仍然可以把它们聚到相近主题里。
真正需要关注的是:
- 关键实体有没有被漏掉;
- 重要关系有没有被抽出来;
- 节点和边的描述是否足够丰富;
- 社区摘要是否保留了主要事实和观点。
3. 社区摘要要保留证据线索
GraphRAG 在全面性和多样性上表现好,但“赋权”指标不总是稳定领先。一个重要原因是:如果社区摘要过度抽象,用户虽然能看到结论,却缺少例子、引用和证据。
社区摘要提示里可以要求保留:
- 支撑结论的代表性例子;
- 关键实体之间的具体关系;
- 重要声明的来源文本范围;
- 时间、地点、人物、组织等可核查线索;
- 不同观点之间的分歧。
如果业务要求答案可追溯,社区摘要和最终答案都应该带上来源 ID,方便回到原始文本检查。
4. 社区层级要按问题类型选择
不要固定只用一个层级。可以按问题自动选择:
def choose_community_level(question: str):
if is_broad_overview_question(question):
return "C0"
if asks_for_major_themes_and_subthemes(question):
return "C1"
if asks_for_comparison_or_relationships(question):
return "C2"
if asks_for_detailed_evidence(question):
return "C3"
return "C2"
更进一步,可以先用 C0/C1 生成概览,再根据用户追问下钻到 C2/C3。这种交互方式比一次性生成超长答案更自然,也更省成本。
5. 成本要分成索引成本和查询成本看
GraphRAG 的离线索引成本高于简单 RAG,因为它要做实体抽取、关系抽取、元素摘要、社区摘要。但查询阶段可以反复复用这些索引。
判断是否值得构建 GraphRAG,可以看三个因素:
| 因素 | 判断方式 |
|---|---|
| 数据集是否长期存在 | 临时数据不一定值得建图 |
| 查询次数是否足够多 | 查询越多,索引成本越容易摊薄 |
| 问题是否偏全局理解 | 事实问答多,简单 RAG 更合适 |
| 是否需要主题浏览和下钻 | GraphRAG 的社区摘要有额外价值 |
| 是否需要实体关系分析 | 图索引可以支持更多查询方式 |
一个最小可实现版本
不依赖特定框架,也可以按下面的模块实现一个简化版 GraphRAG:
class MiniGraphRAG:
def __init__(self, llm):
self.llm = llm
self.graph = None
self.community_reports = {}
def build_index(self, documents):
chunks = split_documents(documents, chunk_size=600, overlap=100)
all_entities = []
all_relationships = []
all_claims = []
for chunk in chunks:
extracted = extract_with_gleaning(chunk, max_rounds=1)
all_entities.extend(extracted["entities"])
all_relationships.extend(extracted["relationships"])
all_claims.extend(extracted.get("claims", []))
entities = summarize_and_merge_entities(all_entities)
relationships = summarize_and_merge_relationships(all_relationships)
self.graph = build_weighted_graph(entities, relationships, all_claims)
communities_by_level = detect_hierarchical_communities(self.graph)
for level, communities in communities_by_level.items():
self.community_reports[level] = [
summarize_community(self.graph, community)
for community in communities
]
def ask(self, question, level="C2", batch_token_limit=8000):
reports = self.community_reports[level]
batches = shuffle_and_batch(reports, token_limit=batch_token_limit)
partial_answers = []
for batch in batches:
answer = answer_from_reports(question, batch)
if answer["score"] > 0:
partial_answers.append(answer)
partial_answers.sort(key=lambda x: x["score"], reverse=True)
return reduce_answers(question, partial_answers, token_limit=batch_token_limit)
这个简化版本只表达关键结构。生产环境还需要补上缓存、重试、并发、token 统计、来源追踪、实体去重、社区层级存储和评估流水线。
小结
GraphRAG 解决的是简单 RAG 不擅长的全局理解问题。它先把文档中的实体、关系和声明抽取成知识图,再用社区检测把图划分为多个主题模块,并为每个模块生成摘要。查询时,系统不再只检索少数文本块,而是让相关社区摘要分别生成局部答案,再汇总成覆盖全局的回答。
它的优势主要体现在三个方面:
- 面向整个语料库的问题,答案更全面;
- 社区摘要提供多个主题视角,答案更多样;
- 图索引和社区摘要可以复用,适合长期、多轮分析。
代价也很清楚:索引阶段更复杂,LLM 调用更多,提示设计和质量控制更重要。对于一次性事实问答,简单 RAG 仍然是更轻的方案;对于需要反复理解大型私有语料库的场景,GraphRAG 提供了一条从局部文本走向全局语义的可行路径。