OCR 在大模型时代依然是基础能力
OCR(Optical Character Recognition,光学字符识别)解决的是“把图片、扫描件、票据、截图里的文字变成机器可处理文本”的问题。大模型可以理解语言,但如果输入是一张发票、一页论文截图、一份扫描合同,系统仍然需要先把视觉内容转成稳定的文本和结构化信息。
一个典型的文档智能系统通常不是直接把原图丢给大模型,而是先经过 OCR 和文档解析,把非结构化图像变成更可靠的中间结果:
flowchart LR
A[图片 / 扫描件 / PDF] --> B[文字检测]
B --> C[文字识别]
C --> D[版面分析]
D --> E[表格 / 公式 / 图表解析]
E --> F[Markdown / JSON / 结构化字段]
F --> G[检索 / 知识库 / 大模型问答]
如果 OCR 阶段漏字、错字、顺序混乱,后面的检索增强生成(RAG,Retrieval-Augmented Generation)和大模型问答都会被污染。PaddleOCR 的价值就在这里:它提供了一套面向工程落地的 OCR 与文档理解工具链,既能单独完成文字识别,也能作为知识库、票据系统、档案数字化系统的前置解析模块。
PaddleOCR 是什么
PaddleOCR 是 PaddlePaddle 生态里的开源 OCR 项目,覆盖文字检测、文字识别、版面分析、表格识别、公式识别、文档结构化、关键信息抽取等能力。它不是单个模型,而是一套可以组合使用的 OCR pipeline。
从能力边界看,PaddleOCR 3.x 可以拆成三条主线:
| 模块 | 解决的问题 | 输出结果 |
|---|---|---|
| PP-OCRv5 | 图片中的文字检测与识别 | 文本、坐标框、置信度 |
| PP-StructureV3 | 复杂文档解析与版面还原 | Markdown、JSON、表格、公式、阅读顺序 |
| PP-ChatOCRv4 | 对文档进行问答式信息抽取 | 指定字段、答案、结构化信息 |
PaddleOCR 从早期轻量 OCR 模型逐步扩展到完整文档处理平台。2020 年开源后,它凭借模型体积小、速度快、部署方便获得了大量使用者;PP-OCRv2、PP-OCRv3、PP-OCRv4 持续改进识别速度和精度;3.x 版本进一步把重点扩展到多语种识别、复杂文档解析、大小模型协同抽取和服务化集成。
3.x 的整体能力结构
PaddleOCR 3.x 的核心不是“把识别率再提高一点”,而是把 OCR 从单点能力扩展成完整链路:先看见文字,再理解版面,最终把信息抽取出来供业务系统使用。
flowchart TB
A[PaddleOCR 3.x] --> B[PP-OCRv5]
A --> C[PP-StructureV3]
A --> D[PP-ChatOCRv4]
A --> E[部署与集成]
B --> B1[42 种语言识别]
B --> B2[印刷体 / 手写体]
B --> B3[拼音 / 古籍 / 生僻字]
C --> C1[版面检测]
C --> C2[表格重构]
C --> C3[公式提取]
C --> C4[图表解析]
C --> C5[页面排序]
C --> C6[Markdown 输出]
D --> D1[PaddleOCR 文档识别]
D --> D2[PP-DocBee2 结构感知]
D --> D3[文心大模型语义理解]
D --> D4[字段抽取 / 文档问答]
E --> E1[Python SDK]
E --> E2[API 服务]
E --> E3[MCP Server]
E --> E4[国产硬件适配]
PaddleOCR 3.x 的一个明显特点是“专用小模型 + 文档 pipeline + 大模型协同”。普通 OCR 任务不必全部交给大模型处理,因为专用 OCR 模型在速度、成本、可控性上更适合批量场景;涉及语义理解、字段归纳、跨页问答时,再引入大模型会更合适。
PP-OCRv5:多语种文字识别
PP-OCRv5 是 PaddleOCR 3.x 的核心文字识别模型,主要解决图片中的文字检测和识别问题。它支持 42 种语言,覆盖中文、繁体中文、英文、法语、西班牙语、葡萄牙语、德语、日语、韩语、俄语、泰语、希腊语、意大利语等多种文字体系。
识别场景不局限于常规印刷体,还包括:
| 场景 | 难点 |
|---|---|
| 手写体 | 字形变化大,笔画粘连或缺失 |
| 拼音 | 字母短文本多,容易被当成英文片段 |
| 古籍 | 竖排、异体字、低质扫描常见 |
| 生僻字 | 字库覆盖和训练样本不足 |
| 多语种混排 | 同一页面内出现不同字符集 |
| 低质图像 | 模糊、倾斜、噪声、压缩失真 |
PP-OCRv5 的识别指标可以与部分多模态大模型方案形成对照。关键点不是“大模型不需要 OCR”,而是专用 OCR pipeline 在识别任务上更容易做到低成本、低延迟、稳定输出。
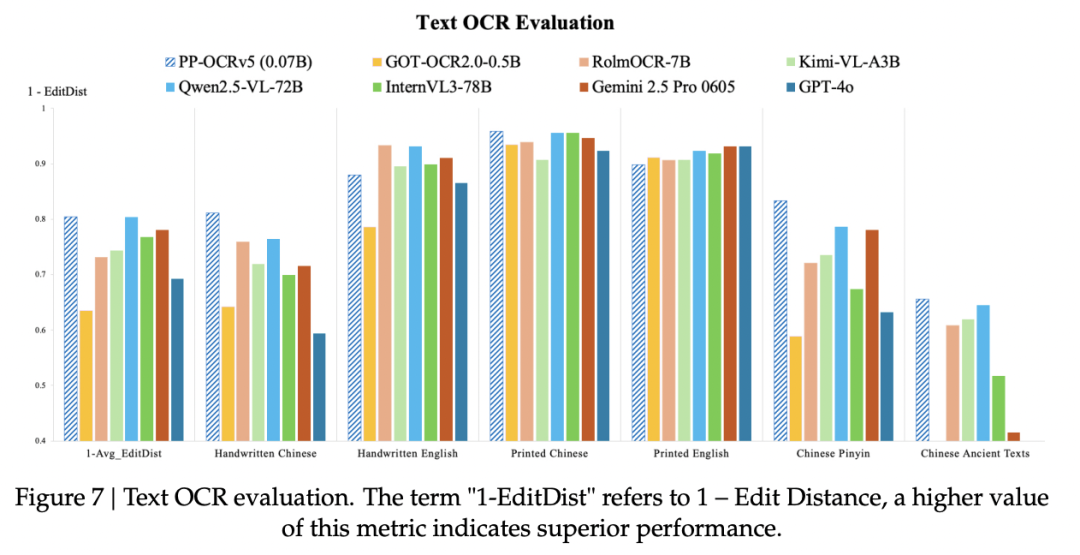
这组对比强调的是工程取舍:通用多模态大模型能处理更开放的问题,但在大量图片文字识别任务里,PP-OCRv5 这类专用模型可以用更小的推理成本完成高频任务。对票据批处理、截图文字提取、档案扫描等场景来说,稳定的坐标框、置信度和文本顺序往往比“模型能聊天”更重要。
PP-OCRv5 的基础流程可以理解成四步:
flowchart LR
A[输入图片] --> B[文本检测]
B --> C[方向 / 角度处理]
C --> D[文本识别]
D --> E[后处理]
E --> F[文字 + 坐标 + 置信度]
检测模型负责找出文字区域,识别模型负责把裁剪后的文字行转成字符串。方向分类、图像矫正、后处理则用于处理旋转文本、倾斜图片、低质量图像和字符纠错。
PP-StructureV3:把复杂文档转成结构化内容
普通 OCR 只能告诉你“页面上有哪些字”,但企业文档解析常常需要知道更复杂的信息:
- 哪些内容是标题;
- 哪些内容属于正文段落;
- 表格的行列关系是什么;
- 数学公式如何转成可编辑格式;
- 多栏论文应该按什么顺序阅读;
- PDF 或图片如何变成 Markdown。
PP-StructureV3 解决的是“文档结构还原”问题。它会把页面拆成多个版面元素,再分别处理文本、表格、公式、图表和阅读顺序。
flowchart TB
A[PDF / 图片] --> B[页面预处理]
B --> C[版面检测]
C --> D[文本 OCR]
C --> E[表格重构]
C --> F[公式识别]
C --> G[图表解析]
C --> H[阅读顺序排序]
D --> I[结构化融合]
E --> I
F --> I
G --> I
H --> I
I --> J[Markdown / JSON]
PP-StructureV3 在 OmniDocBench 等文档解析评测中展示了和 pipeline 方案、多模态大模型方案的对比结果。
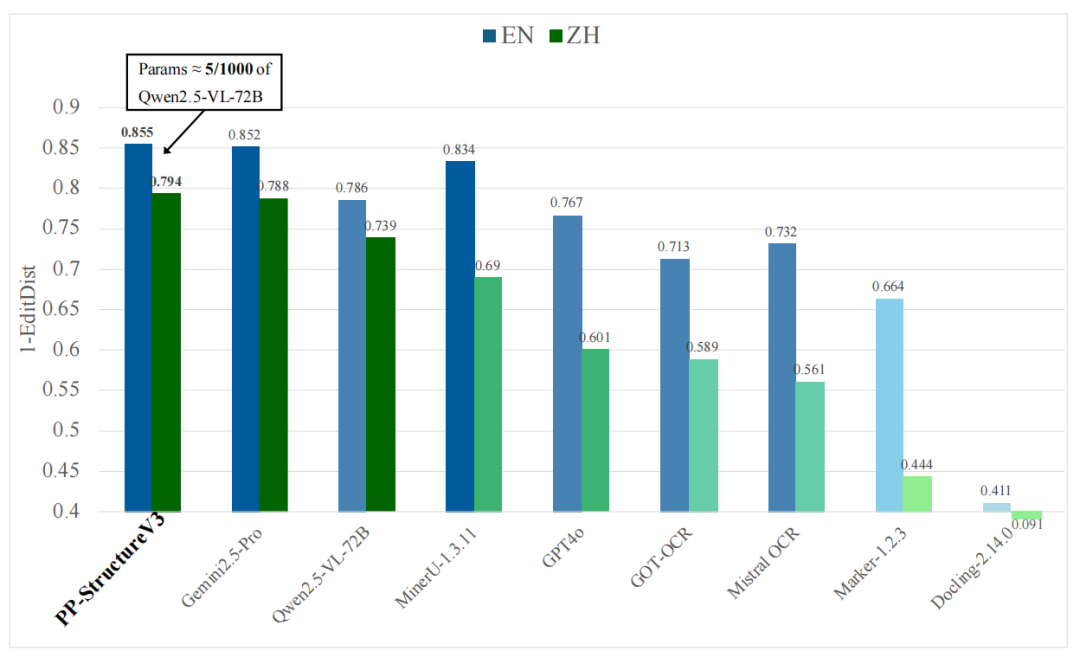
文档解析的评价重点和纯 OCR 不同。纯 OCR 更关注字符是否识别正确;文档解析还要看段落顺序、表格结构、公式格式、跨栏阅读顺序是否合理。知识库构建、论文解析、合同归档等场景尤其依赖这些结构信息。
PP-StructureV3 的目标输出通常是 Markdown 或 JSON,而不是一堆无序文本框。
这类输出适合进入后续系统:Markdown 可以直接作为知识库语料,JSON 适合入库检索,表格和公式可以单独保存,用于报表系统、搜索系统或训练数据清洗。
PP-ChatOCRv4:用问答方式抽取关键信息
很多业务并不只想识别全文,而是想从文档里拿到指定字段。例如:
| 文档类型 | 常见抽取字段 |
|---|---|
| 发票 | 发票号码、金额、日期、购买方、销售方 |
| 合同 | 合同主体、签署日期、金额、履约期限 |
| 简历 | 姓名、学校、工作年限、技能 |
| 研报 | 公司名称、核心指标、风险提示 |
| 物流单据 | 运单号、地址、联系人、电话 |
PP-ChatOCRv4 使用“大小模型协同”的思路:PaddleOCR 负责稳定识别文档内容,PP-DocBee2 提供多模态文档结构感知能力,文心大模型 4.5 负责语义理解和问答式抽取。
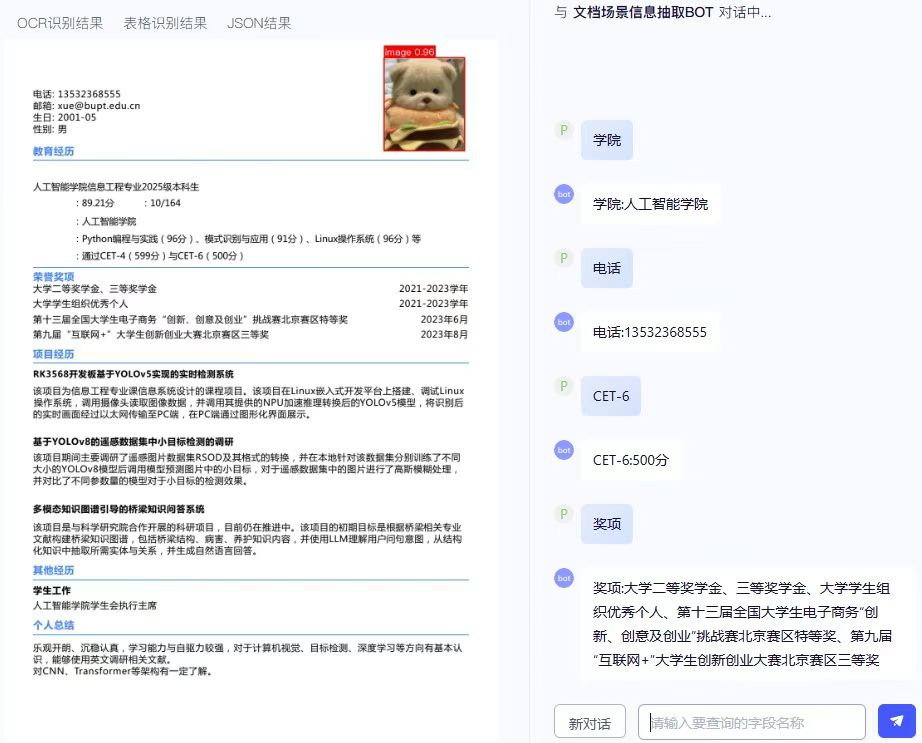
这个架构的意义在于分工明确。OCR 模型处理文字和坐标,大模型处理语义和推理;如果全部交给大模型,成本和可控性都会变差,如果只用传统 OCR,又很难处理“帮我找出合同甲方并解释付款条件”这种语义任务。
PP-ChatOCRv4 更适合下面这些需求:
- 字段名不完全固定,需要通过自然语言提问;
- 文档版式复杂,字段可能跨页出现;
- 需要结合上下文判断字段含义;
- 需要把识别结果整理成业务系统可消费的 JSON。
一个典型链路如下:
sequenceDiagram
participant U as 用户
participant OCR as PaddleOCR
participant DOC as 文档结构模型
participant LLM as 大模型
participant SYS as 业务系统
U->>OCR: 上传合同 / 发票 / PDF
OCR->>DOC: 提供文字、坐标、版面元素
DOC->>LLM: 提供结构化文档上下文
U->>LLM: 提问:提取金额和付款日期
LLM-->>SYS: 返回字段 JSON
什么时候适合用 PaddleOCR
PaddleOCR 适合的是“需要稳定、可批量、可部署的 OCR 与文档解析”场景。它不只是研究模型,也能作为业务系统的一部分运行。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 批量图片文字识别 | 适合 | 专用 OCR 模型成本低,速度快 |
| 多语种截图识别 | 适合 | PP-OCRv5 支持多语言 |
| 扫描 PDF 转 Markdown | 适合 | PP-StructureV3 能处理版面结构 |
| 票据、合同字段抽取 | 适合 | PP-ChatOCRv4 支持问答式抽取 |
| 对话式开放问答 | 需要配合大模型 | OCR 负责输入质量,大模型负责语义 |
| 极少量图片临时识别 | 不一定需要 | 在线工具或通用多模态模型可能更省事 |
| 对图像内容进行视觉推理 | 不适合作为唯一方案 | OCR 只处理文字和文档结构,不等同于视觉理解模型 |
上手使用
PaddleOCR 可以通过 Python SDK 使用,也可以部署成服务供其他系统调用。基础环境需要 Python 和 PaddlePaddle。
安装
CPU 环境可以直接安装:
pip install paddlepaddle paddleocr
如果使用 GPU,需要安装与 CUDA 版本匹配的 PaddlePaddle GPU 包,再安装 PaddleOCR:
pip install paddleocr
安装完成后,可以检查版本:
python -c "import paddleocr; print(paddleocr.__version__)"
使用 PP-OCRv5 做图片文字识别
PaddleOCR 3.x 推荐使用 predict 风格接口。输入可以是本地图片,也可以是目录或部分远程图片地址。
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
)
result = ocr.predict(input="demo.jpg")
for item in result:
item.print()
item.save_to_img("./output")
item.save_to_json("./output")
输出 JSON 中通常会包含文字内容、检测框坐标、置信度等信息。业务系统可以根据坐标保留原始版面,也可以只提取纯文本。
使用 PP-StructureV3 解析文档
复杂文档更适合走结构化解析 pipeline:
from paddleocr import PPStructureV3
pipeline = PPStructureV3()
result = pipeline.predict(input="demo.pdf")
for item in result:
item.print()
item.save_to_json("./output")
item.save_to_markdown("./output")
这种方式适合把扫描 PDF、论文、研报、说明书转成 Markdown,再进入知识库或搜索系统。
把 OCR 接入后端服务
在后端系统里,推荐把 OCR 服务和业务服务拆开:
flowchart LR
A[业务系统] --> B[OCR API 服务]
B --> C[PaddleOCR 推理服务]
C --> D[模型文件]
B --> E[(结果缓存)]
B --> F[(数据库 / 对象存储)]
拆分之后有几个好处:
- OCR 推理可以单独扩容;
- 图片和 PDF 可以异步处理;
- 识别结果可以缓存,避免重复推理;
- 业务系统不需要直接依赖深度学习运行环境。
一个简单的接口可以这样设计:
POST /api/ocr
Content-Type: multipart/form-data
file: demo.pdf
mode: structure
lang: ch
返回结果:
{
"task_id": "ocr_20260607_001",
"status": "success",
"pages": [
{
"page_no": 1,
"markdown": "# 标题\n\n正文内容...",
"blocks": [
{
"type": "text",
"text": "示例文字",
"bbox": [120, 88, 430, 128],
"confidence": 0.98
}
]
}
]
}
MCP Server 的使用位置
MCP(Model Context Protocol,模型上下文协议)可以让大模型客户端以工具方式调用外部能力。PaddleOCR 支持 MCP Server 后,大模型应用可以把 OCR 当成一个工具:
flowchart LR
A[大模型应用] --> B[MCP Client]
B --> C[PaddleOCR MCP Server]
C --> D[OCR / 文档解析]
D --> C
C --> B
B --> A
这种集成方式适合智能助手类产品:用户上传 PDF 后,大模型先调用 OCR 工具获取结构化内容,再基于结果回答问题,而不是直接猜测图片里的文字。
部署模式怎么选
| 部署模式 | 适合场景 | 代价 |
|---|---|---|
| Python SDK | 单机脚本、离线批处理、快速验证 | 和业务代码耦合较深 |
| HTTP API | 后端系统、微服务、多人共用 | 需要服务治理和队列 |
| 批处理任务 | 大量 PDF、档案数字化 | 延迟高,不适合实时 |
| MCP Server | 大模型应用、智能助手 | 需要维护工具调用协议 |
| GPU 推理服务 | 高并发、大文件解析 | 机器成本更高 |
| CPU 轻量部署 | 小规模识别、边缘场景 | 吞吐有限 |
如果业务只是每天处理少量图片,Python SDK 足够;如果每天有大量票据、合同、扫描件进入系统,最好做成独立 OCR 服务,并配合任务队列、对象存储和结果缓存。
工程落地时容易踩的坑
1. 图片质量比模型选择更早影响结果
低分辨率、严重压缩、过曝、倾斜、阴影都会影响 OCR。上线前应该做预处理:
flowchart LR
A[原始图片] --> B[方向检测]
B --> C[去噪 / 增强]
C --> D[裁边 / 矫正]
D --> E[OCR 识别]
如果输入图片来自手机拍照,图像矫正和方向处理通常不能省。
2. PDF 要区分扫描版和文本版
PDF 分两类:
| 类型 | 特征 | 处理方式 |
|---|---|---|
| 文本型 PDF | 内部已有可复制文本 | 优先直接提取文本 |
| 扫描型 PDF | 每页都是图片 | 需要 OCR |
| 混合型 PDF | 部分文本、部分图片 | 需要按页判断 |
对文本型 PDF 直接跑 OCR 可能会浪费资源,还可能引入识别错误。更稳妥的做法是先检测 PDF 是否已有文本层,再决定是否走 OCR。
3. 多语种识别要设置正确语言
多语种模型覆盖广,但语言配置仍然重要。中文、英文、日文、韩文、泰文等文字体系差异很大,错误的语言配置会降低识别质量。多语种混排场景需要单独做测试,尤其是中英混排、日英混排、公式与正文混排。
4. 文档解析不能只看 OCR 准确率
知识库构建更关心阅读顺序和结构完整性。识别出所有字不代表解析正确,多栏论文如果顺序错了,后续大模型问答会把上下文拼错。
评估文档解析时至少看四件事:
- 段落顺序是否正确;
- 表格行列是否还原;
- 公式是否可读;
- 图片、图表、标题是否被正确区分。
5. 关键信息抽取要保留置信度和证据
票据、合同、金融材料不能只返回一个字段值,最好同时保存证据位置:
{
"field": "invoice_amount",
"value": "1280.00",
"confidence": 0.96,
"evidence": {
"page": 1,
"bbox": [420, 560, 610, 598],
"text": "价税合计:1280.00"
}
}
这样业务系统可以做人工复核,也能在抽取错误时快速定位来源。
PaddleOCR 与大模型的关系
PaddleOCR 和大模型不是替代关系,更像上下游关系:
| 能力 | PaddleOCR 更擅长 | 大模型更擅长 |
|---|---|---|
| 文字检测 | 是 | 不稳定 |
| 批量识别 | 是 | 成本较高 |
| 坐标框输出 | 是 | 通常不精确 |
| 版面结构 | PP-StructureV3 适合 | 多模态模型可辅助 |
| 语义问答 | 需要配合 | 是 |
| 字段归纳 | PP-ChatOCRv4 协同 | 是 |
| 长文档知识库 | 负责解析输入 | 负责检索后生成答案 |
一个合理的文档智能系统会把两者组合起来:PaddleOCR 负责把图像和 PDF 变成高质量结构化文本,大模型负责理解、检索、问答和生成。
常用链接
GitHub: https://github.com/PaddlePaddle/PaddleOCR
Hugging Face: https://huggingface.co/PaddlePaddle
文档: https://www.paddleocr.ai
PaddleOCR 3.0 技术报告: https://arxiv.org/pdf/2507.05595
PaddleOCR 3.x 的定位已经从单纯 OCR 工具扩展到多语言文档理解平台。PP-OCRv5 负责看清文字,PP-StructureV3 负责还原文档结构,PP-ChatOCRv4 负责把文档内容转成可问答、可抽取的业务信息。对需要处理扫描件、票据、合同、研报、论文和企业知识库的系统来说,它提供了一条从原始文档到结构化数据的完整路径。