我会把素材改成一篇独立的开源工具导览,保留能支撑技术理解的结果图和界面图,去掉 GIF、WebP 和推广尾巴。正文会用表格与 Mermaid 补足流程和适用场景,而不是按原素材逐段复述。---
title: 用 4 个 GitHub 项目理解 AI Agent 工作流的成本、并行与提示词
date: 2026-06-07
slug: github-ai-agent-workflow-projects
categories:
- 开发工具
- 人工智能
tags: - GitHub
- AI Agent
- Claude Code
- 模型路由
- LightGBM
- Playwright
- System Prompt
description: 4 个开源项目分别解决 AI Agent 使用中的模型成本、多项目并行、求职信息处理和系统提示词研究问题。通过流程图、对比表和上手方式,梳理它们的核心机制、适用场景与使用边界。
AI Agent(智能体)已经不只是聊天窗口里的问答工具。它开始接管代码修改、资料检索、简历生成、面试准备等连续任务,但新的问题也跟着出现:模型费用容易失控,多任务并行很难管理,AI 输出需要人工审核,系统提示词又决定了模型在关键场景下的行为边界。
这 4 个 GitHub 项目分别切入了这些问题:
| 项目 | 解决的问题 | 核心做法 |
|---|---|---|
| OpenSquilla | 大模型调用成本过高 | 本地路由判断任务难度,把请求分配给便宜但够用的模型 |
| Nezha | 多个 Claude Code / Codex 会话难管理 | 用桌面应用统一管理项目、终端、Git 和会话历史 |
| Career-Ops | 求职信息筛选和材料定制耗时 | 用 AI CLI 和 Playwright 自动分析职位、生成匹配材料 |
| CL4R1T4S / system_prompts_leaks | 想研究 AI 产品背后的系统提示词 | 收集不同 AI 产品的 system prompt 样本,便于理解提示词结构 |
OpenSquilla:用本地模型路由降低 Agent 调用成本
很多 AI Agent 工作流有一个明显浪费:不管任务难不难,都直接调用最贵、能力最强的模型。复杂架构设计、跨文件重构、疑难 Bug 分析确实需要高能力模型,但改一行配置、整理列表、生成简单命令,并不一定要用同一个模型。
OpenSquilla 的思路是给 Agent 前面加一层“模型路由器”。每一轮请求进来后,路由器先在本地判断任务复杂度,再把请求交给能完成任务的最低成本模型。
flowchart LR
A[用户请求] --> B[Agent]
B --> C[本地路由器]
C --> D{判断任务复杂度}
D -->|简单任务| E[低成本模型]
D -->|中等任务| F[中档模型]
D -->|复杂任务| G[高能力模型]
E --> H[返回结果]
F --> H
G --> H
H --> B
B --> A
这里最关键的点不是“多接几个模型”,而是“分类动作在本地完成”。OpenSquilla 使用 LightGBM 和 ONNX 来运行路由判断,用户的 prompt 不需要先发给外部服务做分类。LightGBM 是常见的梯度提升树模型,适合处理结构化特征;ONNX(Open Neural Network Exchange,开放神经网络交换格式)则让模型可以更方便地在不同运行环境中部署。
OpenSquilla 的基准测试结果可以用一张对比图辅助理解:重点不是让分数更高,而是在任务质量几乎不变的前提下压低模型费用。
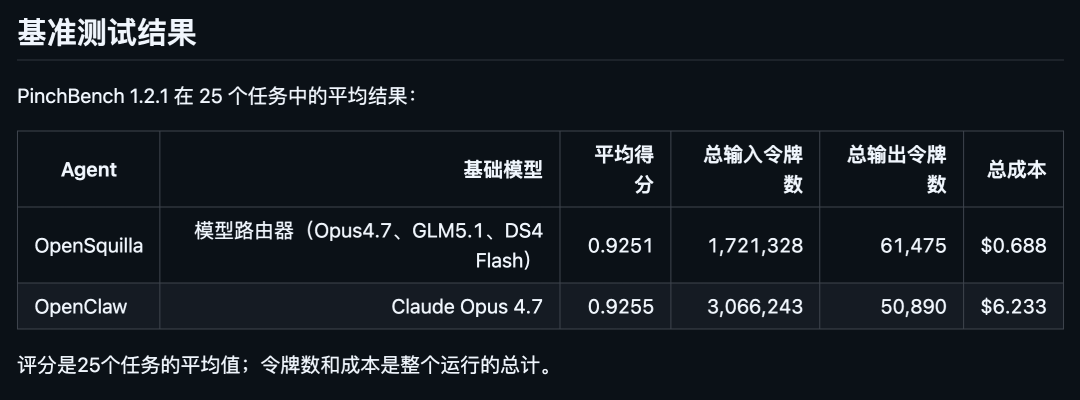
图里最值得看的数字是平均得分和总成本。OpenSquilla 在 PinchBench 1.2.1 的 25 个任务上平均得分为 0.9251,对照方案 OpenClaw 全程使用 Claude Opus 4.7,平均得分为 0.9255,两者差距很小;但成本从 6.233 美元降到 0.688 美元,约等于把费用压到九分之一左右。
| 指标 | OpenSquilla | OpenClaw 对照组 | 说明 |
|---|---|---|---|
| 任务数量 | 25 | 25 | 使用 PinchBench 1.2.1 |
| 平均得分 | 0.9251 | 0.9255 | 质量差距非常小 |
| 总成本 | 0.688 美元 | 6.233 美元 | 成本约降低 9 倍 |
| 路由方式 | 本地判断 | 固定使用高端模型 | OpenSquilla 按任务难度选模型 |
这种方案适合高频调用 Agent 的场景,尤其是团队内大量请求都属于“简单任务 + 少量复杂任务”的混合负载。如果所有任务都高度复杂,路由器最终仍会频繁选择高能力模型,成本优势会变小。
开源地址:
https://github.com/opensquilla/opensquilla
Nezha:把多个 Claude Code 和 Codex 会话放进一个工作台
使用 Claude Code 或 Codex 做代码任务时,一个项目开一个终端很常见。问题在于,当多个项目同时跑起来,终端窗口会越来越多:某个 Agent 在等待确认,另一个 Agent 正在改文件,还有一个 Agent 的上下文需要恢复,开发者要靠记忆在窗口之间切换。
Nezha 把这个问题做成了桌面应用。它的定位是 Agent-First 工作台,也就是默认围绕 AI 写代码、人类审查和协调进度来设计界面,而不是把 Agent 当作普通终端里的附属功能。
Nezha 的界面把项目、终端、Git、代码浏览和会话回放放在同一个窗口中,适合同时盯多个 AI 编码任务。

从界面结构上看,Nezha 更像一个“多 Agent 控制台”:每个项目可以作为一个标签页存在,Claude Code 和 Codex 会话在后台继续运行;如果某个项目卡在人工确认步骤,侧边栏会通过黄色状态提醒把它标出来,减少用户反复切终端检查状态的时间。
flowchart TB
A[Nezha 桌面应用] --> B[项目标签页]
A --> C[集成终端]
A --> D[Git 状态]
A --> E[代码浏览]
A --> F[会话回放]
B --> G[项目 A: Claude Code]
B --> H[项目 B: Codex]
B --> I[项目 C: Claude Code]
F --> J[自动识别会话文件]
J --> K[恢复历史任务]
它还有两个实用点:
| 功能 | 作用 |
|---|---|
| 后台运行多个 Agent | 不需要为每个项目单独开终端窗口 |
| 会话文件识别 | 可以把 Claude Code 和 Codex 的历史对话可视化,方便恢复任务 |
| 状态提醒 | 某个任务等待确认时,侧边栏给出明显提示 |
| 轻量安装包 | 安装包约 7 MB,适合只需要 Agent 管理能力的用户 |
Nezha 更适合经常在多个仓库之间切换的人。如果只是偶尔让 Claude Code 改一个小文件,原生命令行已经足够;如果每天需要同时推进多个 AI 编码任务,统一工作台能明显减少上下文切换。
开源地址:
https://github.com/hanshuaikang/nezha
Career-Ops:把 AI CLI 变成求职分析流水线
求职场景里最费时间的部分不只是投递,而是判断“这个职位到底值不值得投入时间”。职位描述要读,要求要和简历匹配,薪酬区间要查,简历还要针对 ATS(Applicant Tracking System,招聘管理系统)做关键词优化。
Career-Ops 把 Claude Code、Gemini CLI、OpenCode 这类 AI 编程工具改造成求职指挥中心。它不是自动批量投递工具,而是一个筛选器:先判断机会质量,再决定要不要投入时间准备材料。
核心流程可以拆成 5 步:
sequenceDiagram
participant U as 用户
participant C as Career-Ops
participant P as Playwright
participant R as 简历资料
participant A as AI CLI
U->>C: 输入职位 URL
C->>P: 抓取招聘页面
P-->>C: 返回职位描述
C->>R: 读取个人简历
C->>A: 分析岗位与简历匹配度
A-->>C: 返回评分、差距、薪酬和面试材料
C-->>U: 输出定制简历和申请建议
Career-Ops 的输出不是一段简单评价,而是一组求职决策材料,包括匹配度分析、薪酬调研、STAR 面试故事和面向 ATS 的简历 PDF。STAR 指 Situation、Task、Action、Result,也就是“情境、任务、行动、结果”,常用于行为面试回答结构。
Career-Ops 的界面展示了从职位分析到材料生成的完整输出,重点在于把“是否值得申请”和“如何准备申请”合并到同一个流程里。

图中这类输出适合人工复核,而不是直接提交。评分较低的职位通常意味着岗位要求、经验背景或薪酬预期不匹配,Career-Ops 建议不要投入太多时间在评分低于 4.0 的机会;评分较高的职位才值得进一步定制简历、准备面试故事并手动提交申请。
| 能力 | 具体输出 | 使用方式 |
|---|---|---|
| 职位抓取 | 通过 Playwright 读取招聘页 | 输入职位 URL |
| 匹配评分 | 用 A-F 等级和分数判断适配度 | 过滤低质量机会 |
| 简历优化 | 生成针对岗位关键词的 ATS 简历 PDF | 人工确认后使用 |
| 薪酬调研 | 分析岗位可能薪酬范围 | 辅助谈薪预期 |
| 面试准备 | 生成 STAR 故事 | 用于行为面试准备 |
项目维护者公开的使用结果包括评估 740 多个职位、生成 100 多份定制简历,并最终获得 Head of Applied AI 职位机会。这个结果不能直接等同于工具对所有人都有效,但说明它的设计目标很清楚:减少无效投递,把时间集中到更匹配的机会。
开源地址:
https://github.com/santifer/career-ops
CL4R1T4S 与 system_prompts_leaks:把系统提示词当作工程样本研究
System Prompt(系统提示词)是 AI 产品里非常核心的一层配置。它通常定义模型身份、回答风格、工具调用规则、安全边界和拒答策略。用户看到的是聊天界面,真正影响模型行为的很多规则却藏在系统提示词里。
CL4R1T4S 和 system_prompts_leaks 是两个专门收集系统提示词样本的仓库,覆盖 OpenAI、Google、Anthropic、xAI、Cursor、Devin 等 AI 产品或工具。system_prompts_leaks 的 GitHub 星标数已经达到数万级,说明很多人把它当作提示词工程和 AI 产品设计的研究资料。
开源地址:
https://github.com/elder-plinius/CL4R1T4S
https://github.com/asgeirtj/system_prompts_leaks
这类仓库的价值不在于“复制某个厂商的提示词”,而在于观察成熟 AI 产品如何组织约束。一个完整的系统提示词通常会包含这些模块:
| 模块 | 作用 |
|---|---|
| 身份设定 | 规定模型是谁、服务于什么产品 |
| 能力边界 | 说明能做什么、不能声称自己能做什么 |
| 工具规则 | 约束搜索、代码执行、文件读取等工具的调用方式 |
| 安全策略 | 处理违法、暴力、自伤、儿童安全等高风险内容 |
| 语气规范 | 控制回答的简洁程度、礼貌程度和格式 |
| 特殊场景流程 | 对心理危机、政治话题、医疗法律等敏感问题给出单独路径 |
system_prompts_leaks 中出现过名为 claude-fable-5.md 的文件,声称包含 Claude Fable 5 的系统提示词信息。对于这类材料,更稳妥的处理方式是把它当作待验证样本:可以研究其中的结构、分类和安全规则设计,但不要把每一条产品信息都当成事实,更不要直接复制到商业产品里使用。
系统提示词研究最适合做三件事:
| 目标 | 可以怎么用 |
|---|---|
| 学习提示词结构 | 观察身份、工具、安全和风格如何分层 |
| 设计内部 Agent | 借鉴规则组织方式,而不是照搬具体内容 |
| 做安全评审 | 检查自己的 Agent 是否缺少危机场景处理流程 |
如果要给自己的 Agent 写系统提示词,可以借鉴这种结构化写法:
1. 角色与任务边界
2. 可用工具和调用规则
3. 输出格式要求
4. 安全与拒答策略
5. 特殊场景处理流程
6. 不确定信息的处理方式
这样写比单纯告诉模型“你是一个专业助手”更可靠,因为它把模型在不同场景下应该遵守的规则拆开了。
4 个项目怎么选
| 场景 | 更适合的项目 | 不适合的情况 |
|---|---|---|
| Agent 调用量大,账单增长快 | OpenSquilla | 任务都必须使用最高能力模型 |
| 同时跑多个 AI 编码项目 | Nezha | 只在单个终端里偶尔使用 Agent |
| 想筛选高匹配职位并定制材料 | Career-Ops | 期待全自动批量投递 |
| 想研究 AI 产品提示词结构 | CL4R1T4S / system_prompts_leaks | 需要完全可信的官方产品文档 |
这 4 个项目覆盖了 AI Agent 工作流的不同层面:OpenSquilla 优化模型选择,Nezha 优化多任务协作,Career-Ops 把 AI CLI 用到求职决策,系统提示词仓库则提供了观察 AI 产品约束设计的样本。真正落地时,最重要的是先判断自己的瓶颈:费用高就看路由,多窗口混乱就看工作台,求职流程耗时就看自动分析,想提升 Agent 稳定性就研究系统提示词结构。