我会把原素材改成一篇面向工程实践的评测型技术博客,重点保留模型能力、评测方法、适用场景和风险边界,去掉娱乐化表达和推广内容。图片只保留对能力判断有帮助的截图或图表,并在正文中解释其含义。---
title: Claude Fable 5 首日能力评测:多模态生成、代码重构与成本边界
date: 2026-06-19
slug: claude-fable-5-first-day-evaluation
categories:
- 人工智能
- 软件工程
tags: - Claude Fable 5
- 大语言模型
- AI Agent
- 代码生成
- 工具调用
- SWE-Bench
- 多模态生成
description: Claude Fable 5 首日公开实测显示,它在界面生成、游戏开发、3D 场景构建和代码重构上都有明显进展,但高强度工具调用会带来成本压力,复杂重构也可能出现“代码好看但跑不起来”的问题。
Claude Fable 5 首日能力评测:多模态生成、代码重构与成本边界
Claude Fable 5 的首日实测可以归纳成一个核心结论:它已经不只是“回答问题”的大语言模型,而是在向“能连续使用工具、生成完整项目、处理复杂软件任务”的 AI Agent 形态靠近。
它能根据一句自然语言提示生成界面、游戏、网站和 3D 场景,也能对老旧代码库做大规模重构。与此同时,它并没有消除大模型在工程场景里的老问题:结果可能看起来完整,但运行时仍会失败;任务越复杂,工具调用越密集,成本也越高。
用工程视角看,Fable 5 的价值不在于某个演示有多炫,而在于它把三个能力同时向前推了一步:
| 能力方向 | 典型表现 | 工程意义 | 主要风险 |
|---|---|---|---|
| 视觉与界面生成 | 生成类 Photoshop、社交网站界面、像素风应用 | 快速做原型、交互稿和可运行 Demo | 细节可控性仍需要人工校验 |
| 游戏与 3D 场景 | 一次推理生成小游戏、Three.js 3D 世界 | 降低创意项目的启动成本 | 复杂逻辑和性能优化仍需开发者接管 |
| 代码重构 | 自动拆分模块、清理冗余代码、触发大量工具调用 | 适合处理重复性工程任务 | 可能生成无法运行的“漂亮代码” |
| 推理与常识判断 | 能识别问题里的隐含条件 | 对任务理解更接近真实需求 | 幽默化回答可能掩盖严肃任务边界 |
从提示词到可运行项目
Fable 5 的一个明显变化,是它在“单次提示词生成复杂结果”上的能力更强。以“在我的世界里创建一个克隆版推特”为例,Fable 5 不只是生成了一个抽象界面,而是把笔记本电脑外观、键盘、底座、屏幕 UI、颜色层次和像素风细节都组织在了一起。
这类任务本质上不是普通问答,而是多步规划问题。模型需要同时完成需求理解、空间布局、视觉元素选择和最终输出组织。
flowchart LR
A[自然语言提示] --> B[理解目标应用]
B --> C[拆分视觉元素]
C --> D[规划界面层级]
D --> E[生成可视化结果]
E --> F[人工检查细节]
这张截图展示的是同一提示下两个模型的可视化生成差异。左侧结果保留了笔记本形态和社交应用界面层级,右侧结果出现文字方向、排版和边界控制问题。
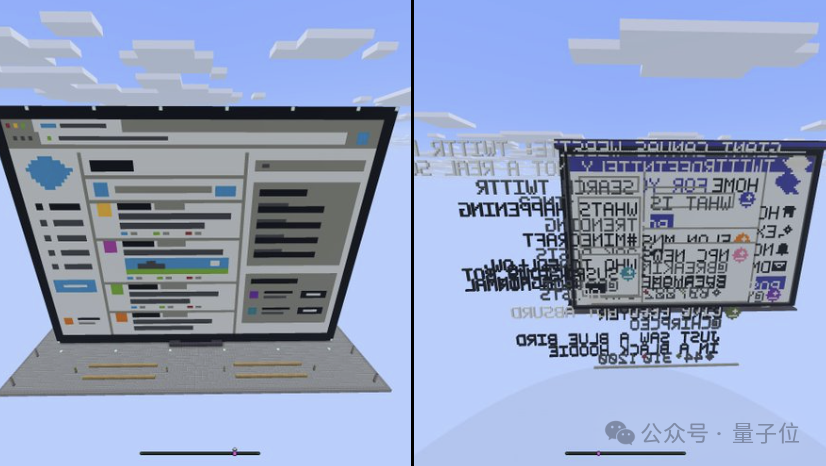
关键差异不只在“好不好看”,而在于模型是否能稳定维护空间关系。对于生成式 UI、游戏资产和 3D 场景来说,空间一致性比单个元素质量更重要:按钮可以不完美,但布局错乱、文字反向、元素溢出会直接破坏可用性。
为什么一句提示词能生成类 Photoshop 工具
Fable 5 被用来复刻类 Photoshop 工具时,展示出的能力并不是“复制某个软件界面”这么简单。真正重要的是,它能把一个复杂工具拆成多个功能区:画布、工具栏、图层、调色、滤镜、特效和预览。
一个图像编辑器的基本结构可以抽象成这样:
flowchart TB
A[用户输入提示] --> B[解析编辑目标]
B --> C[选择工具能力]
C --> D[处理图像或画布]
D --> E[应用风格与特效]
E --> F[输出预览结果]
C --> C1[修图]
C --> C2[调色]
C --> C3[特效]
C --> C4[创意绘画]
当模型能够生成类似工具时,说明它已经掌握了“产品结构”和“视觉效果”之间的映射关系。例如赛博朋克风格并不只是换成亮色,而通常包含高对比色调、色彩分离、颗粒质感、霓虹边缘和数字雨这类视觉特征。模型需要知道这些元素如何组合,结果才会像一个完整的图像工具,而不是一张孤立的图片。
这类能力适合用于:
| 场景 | 可以交给模型的部分 | 仍需人工完成的部分 |
|---|---|---|
| 设计原型 | 快速生成工具界面和交互草图 | 确认品牌规范与交互细节 |
| 创意实验 | 尝试多种视觉风格 | 筛选可落地方案 |
| 内部工具 Demo | 生成初版页面和基础功能 | 接入真实数据与权限系统 |
| 图像特效探索 | 组合滤镜和视觉元素 | 精修输出质量 |
小游戏生成体现的是“闭环能力”
小游戏比静态界面更难,因为它要求模型同时处理规则、关卡、碰撞、状态变化和动画反馈。Fable 5 生成《只有一道门》风格小游戏时,能在一次推理中落地游戏框架、核心玩法、关卡逻辑和交互动画。
这类任务可以拆成四层:
flowchart TB
A[游戏目标] --> B[玩法规则]
B --> C[关卡状态]
C --> D[玩家输入]
D --> E[动画与反馈]
E --> C
游戏生成能力的重点不在于模型能不能画出角色,而在于它能不能维持一个可玩的循环。玩家输入会改变状态,状态会触发反馈,反馈又会影响下一步操作。只要其中一环断掉,游戏就会变成“能打开但不能玩”的页面。
截图中的小游戏界面说明,Fable 5 已经能把关卡、角色、障碍和失败反馈组合成可交互体验。
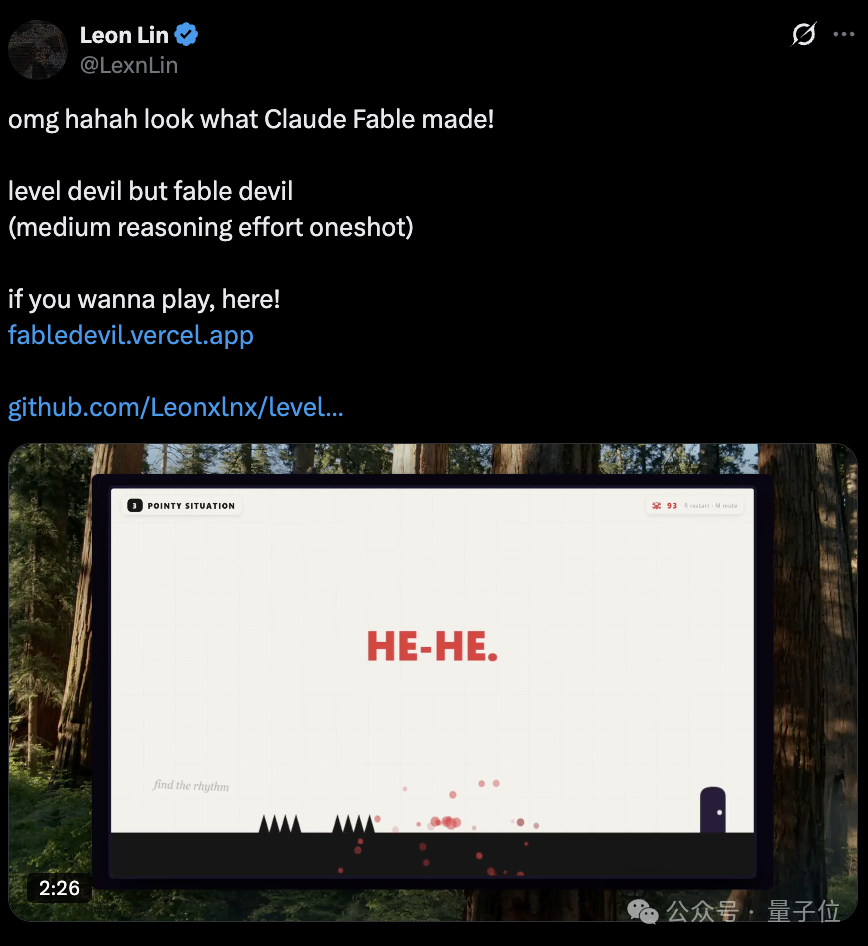
对开发者来说,这种能力更适合用来做早期原型,而不是直接替代完整游戏开发。原因很简单:原型阶段需要快速验证玩法是否成立,而正式项目还要处理资源管理、性能、关卡编辑器、存档、音效、适配和测试。
网站与 3D 场景生成的工程价值
让 Fable 5 给自己生成网站,属于典型的前端原型任务。模型要完成的不只是写 HTML 和 CSS,还要理解产品定位、页面分区、视觉风格、信息层级和动效组织。
这类网页生成任务适合用于:
1. 产品落地页初稿
2. 内部工具控制台
3. 活动页面 Demo
4. 组件库视觉草案
5. 可交互演示页面
Fable 5 生成的网站截图显示,它能把品牌表达、信息展示和页面装饰统一到一个完整视觉系统里。

更进一步的测试是 3D 世界构建。公开样例中,有人用几行提示词让 Fable 5 基于 Three.js 生成 3D 场景,并且无需额外配置环境,直接在浏览器中运行。
Three.js 是一个 JavaScript 3D 图形库,常用来在浏览器里创建三维场景。一个最小 3D 项目通常包含场景、相机、渲染器、几何体、材质、光源和动画循环。
flowchart LR
A[Three.js 项目] --> B[Scene 场景]
A --> C[Camera 相机]
A --> D[Renderer 渲染器]
B --> E[Mesh 物体]
E --> F[Geometry 几何体]
E --> G[Material 材质]
B --> H[Light 光源]
D --> I[Animation Loop 动画循环]
这张截图对应的是 Fable 5 生成的浏览器 3D 世界。它的意义在于,模型已经能够把自然语言需求转换成可运行的前端图形项目,而不是只给出代码片段。
不过,3D 场景越复杂,越容易遇到工程化问题,例如帧率下降、资源加载慢、对象管理混乱、交互逻辑难维护。模型能把项目启动起来,但性能调优和长期维护仍然要依赖开发者。
基准测试显示能力曲线出现跃迁
公开基准测试中,Fable 5 在 FC Diamond、SWE-Bench Pro 等任务上的表现引起关注。SWE-Bench 是用于评估模型解决真实软件工程问题能力的测试集,重点看模型能否理解代码仓库、定位 bug、修改代码并通过测试。
从趋势图看,上一代旗舰模型 Opus 4.8 在 Diamond 榜单上约为 14% 成功率,基本符合历史增长趋势;Fable 5 则提升到 30% 以上,明显高于旧趋势线。
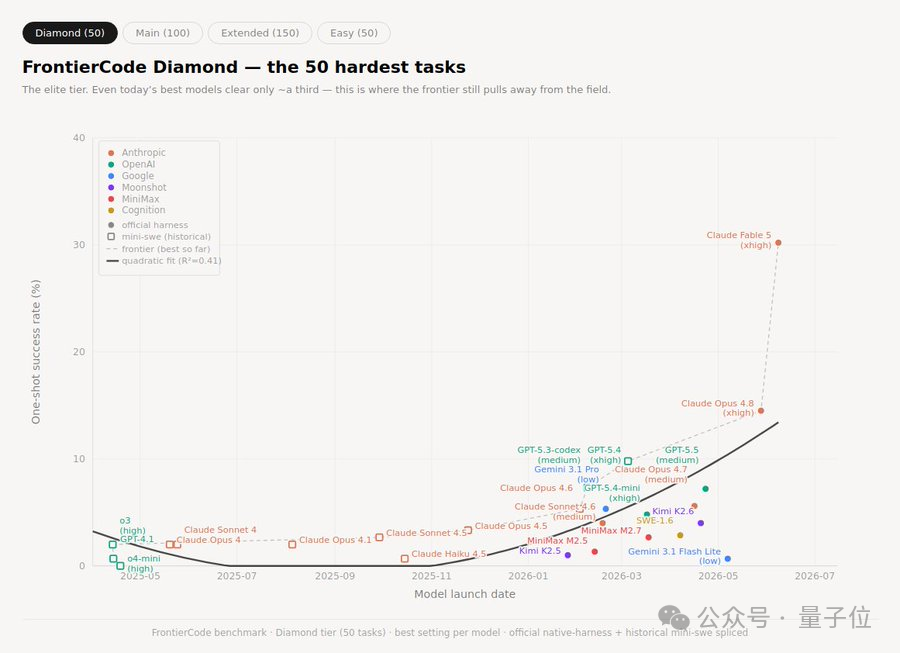
这类跃迁说明,Fable 5 的提升可能不只是参数规模或训练数据带来的线性增长,而是与工具调用、长上下文规划、代码理解和多步执行能力有关。
可以把它理解成两类模型的区别:
| 模型形态 | 工作方式 | 适合任务 | 局限 |
|---|---|---|---|
| 问答型模型 | 根据输入直接生成答案 | 解释概念、写片段代码、回答问题 | 很难独立完成长链路任务 |
| Agent 型模型 | 规划步骤、调用工具、检查结果、继续修改 | 重构代码库、生成项目、处理多文件任务 | 成本更高,失败模式更复杂 |
Fable 5 的优势更像后者。它不是只输出一段答案,而是能围绕目标不断调用工具,把任务推进到一个接近完整项目的状态。
代码重构能力:强,但不能盲信
代码能力是 Fable 5 首日实测里最值得谨慎分析的部分。
有开发者把一个杂乱的老旧代码库交给 Fable 5 做全面重构。模型自动触发 67 次工具调用,生成超过百万行新代码,新增 24 个文件,完成了架构拆分和模块化改造。从代码组织上看,结果更规整;但最终无法正常运行。
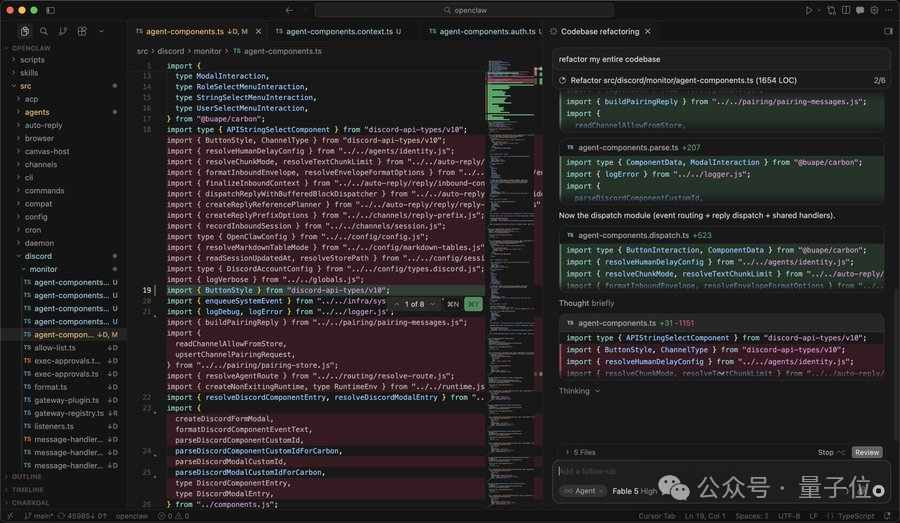
这个案例很典型:大模型可以生成结构上更像现代工程的代码,但“结构好看”不等于“行为正确”。重构真正困难的地方,不是把文件拆开,而是保持外部行为不变。
一个可靠的 AI 重构流程应当包含这些环节:
flowchart TB
A[读取代码库] --> B[理解模块边界]
B --> C[建立测试基线]
C --> D[小步重构]
D --> E[运行测试]
E -->|通过| F[继续下一步]
E -->|失败| G[回滚或修复]
G --> D
F --> H[人工代码审查]
如果缺少测试基线,模型很容易做出看似合理但破坏行为的修改。尤其是老旧代码库里常有隐式依赖、历史兼容逻辑和未文档化约定,这些东西不一定能从代码结构里直接推断出来。
另一个实测案例更接近适合 AI 的工程任务:让 Fable 5 清理项目冗余代码,删除约 7000 行无效代码后,系统仍能正常运行,原有功能保持完好。
这说明 Fable 5 更适合从“低风险、高重复”的工程任务开始使用,例如删除未引用代码、整理依赖、补充类型、拆分大文件、统一命名和生成测试。直接让它一次性重构核心架构,风险会明显升高。
成本是 Agent 能力的另一面
Fable 5 的高强度工具调用会带来明显成本压力。一次清理冗余代码的任务就消耗了约 30% 额度,这说明 Agent 型模型的定价不能只按“问一次多少钱”来理解。
它的消耗来自多个部分:
| 成本来源 | 为什么会增加消耗 |
|---|---|
| 长上下文读取 | 代码库、依赖、日志和测试输出都会占用上下文 |
| 多次工具调用 | 每次搜索、读取、编辑、运行检查都要消耗额度 |
| 反复修正 | 失败后重新分析和修改会继续扩大成本 |
| 大规模生成 | 一次性生成大量文件和代码会显著增加输出量 |
| 隐性验证 | 让模型解释、检查、对比变更也会消耗上下文 |
因此,使用 Fable 5 这类模型时,任务粒度要控制得更细。与其说“重构整个项目”,不如给出明确边界:
目标:删除未使用的工具函数
范围:src/utils 和 src/helpers
约束:不修改公开 API
验证:运行现有单元测试
输出:列出删除的文件和受影响模块
任务越具体,模型越容易判断成功条件,也越不容易在无关文件里扩大修改范围。
适合和不适合 Fable 5 的任务
从首日实测看,Fable 5 适合承担“有明确目标、可以快速验证、允许迭代修正”的任务;不适合直接接管“业务风险高、隐式规则多、缺少测试”的核心系统。
| 任务类型 | 是否适合 | 使用建议 |
|---|---|---|
| 生成网页 Demo | 适合 | 明确页面结构、风格和交互目标 |
| 生成小游戏原型 | 适合 | 用来验证玩法,不直接当正式代码 |
| 生成 Three.js 场景 | 适合 | 先做单场景,复杂交互分阶段增加 |
| 清理死代码 | 比较适合 | 必须配合测试和代码审查 |
| 大规模架构重构 | 谨慎使用 | 拆成小任务,逐步验证 |
| 修改核心业务逻辑 | 不建议直接放手 | 需要人工定义规则和验收条件 |
| 无测试老旧项目重写 | 高风险 | 先补测试,再让模型参与改造 |
更稳妥的使用方式
Fable 5 的能力越强,越需要清晰的使用边界。把它当成“能干活的工程助理”比当成“自动完成一切的开发者”更合理。
一个实用的工作流是:
sequenceDiagram
participant Dev as 开发者
participant Fable as Fable 5
participant Repo as 代码库
participant Test as 测试系统
Dev->>Fable: 给出小范围任务和约束
Fable->>Repo: 读取相关文件
Fable-->>Dev: 提出修改计划
Dev->>Fable: 确认范围
Fable->>Repo: 修改代码
Fable->>Test: 运行测试或检查
Test-->>Fable: 返回结果
Fable-->>Dev: 汇报变更和风险
Dev->>Repo: 审查并合并
提示词可以尽量包含四类信息:
1. 目标:要完成什么,不要完成什么
2. 范围:允许修改哪些目录和文件
3. 约束:不能改变哪些 API、行为或数据结构
4. 验证:用什么测试、命令或现象判断成功
例如:
请清理 src/components 中未使用的 React 组件。
约束:
- 不修改路由配置
- 不改变任何导出的公共组件名
- 删除前先列出候选文件
- 修改后运行 npm test
- 如果测试失败,停止继续删除并说明原因
这样的任务描述会限制模型的自由度,让它更像在执行工程任务,而不是自由发挥。
结论:Fable 5 更像一名高成本的多技能工程助理
Claude Fable 5 的首日实测显示,它在多模态生成、前端原型、小游戏、3D 场景和代码处理上都已经具备很强的端到端能力。尤其是工具调用和长链路执行,让它开始接近真正的 AI Agent。
但工程落地时要抓住两个现实问题:一是复杂代码重构仍可能失败,不能只看生成结果是否整齐;二是高强度工具调用会快速消耗额度,任务拆分和验证流程会直接影响使用成本。
更稳妥的方式,是把 Fable 5 用在原型生成、低风险重构、冗余代码清理和局部工程自动化上;遇到核心业务逻辑、长期维护项目和无测试老旧系统时,仍然需要人工设计边界、补齐测试,再让模型参与具体执行。