过去几年,大模型的竞争重点一直在变。
一开始大家更关心单点能力,比如知识题能答对多少、数学题能不能推出来、代码生成排在什么位置。到了 Agent 开始普及后,单轮问答已经不够用了,模型需要规划任务、调用工具、读取文件、搜索资料、修正错误,还要把多个步骤串成一个可交付结果。
到了生产级 Agent 场景,效率会变成很硬的问题。一次复杂任务可能包含几十轮模型调用,每轮还会夹杂搜索、代码执行、文件读写、多模态识别和结果校验。如果模型每一步都慢,最终等待时间就会从几分钟拉长到几十分钟。
Step 3.7 Flash 的定位正是解决这个问题:在保持较强任务能力的同时,把 Agent 循环里的生成速度、工具协作和多模态处理做得更适合真实工作流。它最高生成速度可达 400 TPS(Tokens Per Second,每秒生成 Token 数),并且是开源模型,可以在自有基础设施中部署。
官方仓库地址:
https://github.com/stepfun-ai/Step-3.7-Flash
为什么 Agent 更在意“完整链路效率”
很多模型评测看的是单次回答质量,但 Agent 的真实耗时不是一次模型调用决定的,而是多轮循环叠加出来的。
一个典型 Agent 任务大概会经历这样的流程:
flowchart TD
A[用户目标] --> B[任务规划]
B --> C[拆分子任务]
C --> D{是否需要外部信息}
D -- 需要 --> E[搜索 / 检索资料]
D -- 不需要 --> F{是否需要执行动作}
E --> G[整理上下文]
G --> F
F -- 需要 --> H[调用工具:代码、文件、浏览器、办公软件]
F -- 不需要 --> I[生成阶段结果]
H --> J[读取工具结果]
J --> K{结果是否满足目标}
I --> K
K -- 否 --> C
K -- 是 --> L[交付最终结果]
Agent 的总耗时可以粗略理解为:
总耗时 ≈ Σ(模型思考与生成时间 + 工具执行时间 + 上下文整理时间 + 重试修正时间)
如果一次任务需要 20 轮循环,单轮模型响应从 20 秒降到 5 秒,光模型调用部分就能从 400 秒降到 100 秒。工具执行时间不变,但整体等待时间会明显缩短。
| 单轮模型耗时 | 循环次数 | 模型调用累计耗时 |
|---|---|---|
| 20 秒 | 20 轮 | 约 6 分 40 秒 |
| 10 秒 | 20 轮 | 约 3 分 20 秒 |
| 5 秒 | 20 轮 | 约 1 分 40 秒 |
这也是 Flash 类模型在 Agent 场景里重新变得重要的原因。便宜和快只是基础,真正关键的是:快的同时能不能完成规划、理解上下文、正确调用工具,并在失败时修正动作。
Step 3.7 Flash 的几个核心能力
1. 面向 Agent Loop 的高吞吐
Step 3.7 Flash 不是单纯追求单轮对话速度,而是更强调 Agent Loop 里的完整效率。Agent Loop 指模型不断“观察状态、思考下一步、调用工具、读取结果、继续决策”的循环。
这类任务对模型有几项要求:
| 能力 | 对 Agent 的意义 |
|---|---|
| 快速生成 | 降低多轮循环的累计等待时间 |
| 稳定遵循指令 | 减少工具调用错误和返工 |
| 长程任务规划 | 能把复杂目标拆成多个可执行步骤 |
| 工具调用能力 | 能正确选择搜索、文件、代码、办公软件等工具 |
| 结果校验 | 能根据工具返回结果判断是否需要修正 |
Agent 任务评测更接近真实工作负载,它看的不是模型能不能答一道题,而是能不能完成一串动作。下面这类榜单的价值就在这里:它把模型放进更长的任务链路中比较,能更直接反映模型在 Agent 场景里的可用性。
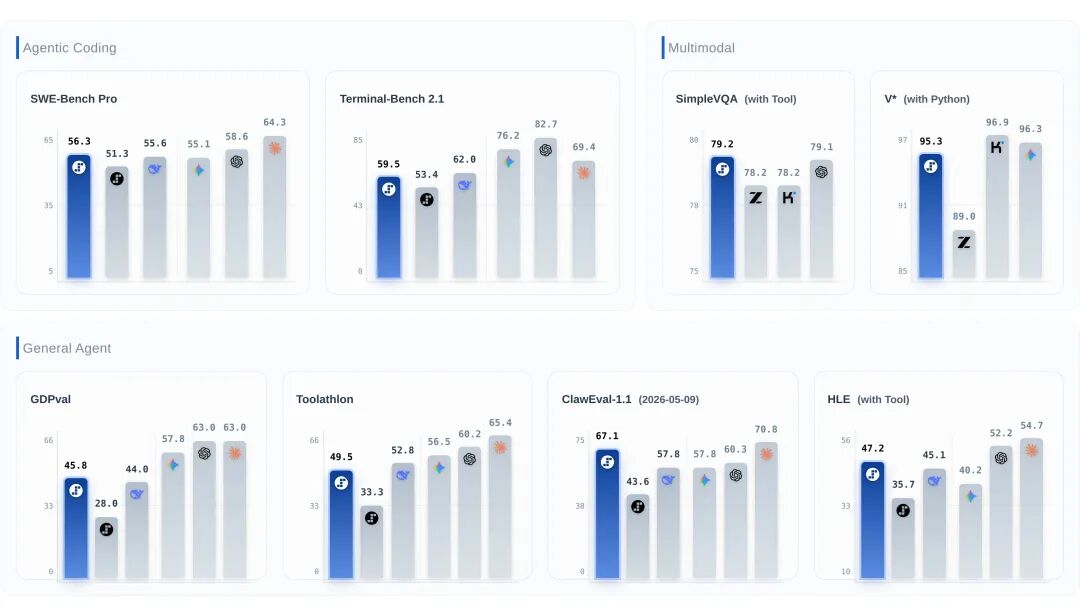
这类评测需要结合速度一起看。一个模型如果单轮能力很强但每一步都很慢,在长任务里可能会让用户等待过久;另一个模型如果生成速度高、工具协作稳定,即使不是所有单点任务都最强,也可能更适合高频 Agent 工作流。
2. 原生多模态能力
Step 3.7 Flash 支持多模态输入,也就是模型不只处理文本,还能理解图片、截图、文档扫描件等视觉内容。
这对 Agent 很重要。很多真实任务并不是纯文本输入,例如:
- 从发票图片里提取金额、日期、税号和购买方信息;
- 读取桌面截图,判断当前应用状态;
- 根据网页截图理解页面结构;
- 从合同扫描件中抽取关键条款;
- 识别表格截图并转成结构化数据。
以发票整理为例,传统做法通常需要单独接一个 OCR(Optical Character Recognition,光学字符识别)模块,再把识别结果交给大模型整理。多模态模型可以把“看图”和“理解内容”合到同一条链路里。
sequenceDiagram
participant U as 用户
participant A as Agent
participant M as Step 3.7 Flash
participant T as 表格工具
U->>A: 上传多张发票图片,要求整理成表格
A->>M: 发送图片与抽取字段说明
M-->>A: 返回发票关键信息
A->>T: 写入表格文件
T-->>A: 返回保存结果
A-->>U: 交付结构化表格
这种能力减少了模块拼接成本。Agent 不需要先调用 OCR,再处理 OCR 的噪声文本,再把结果重新格式化;模型可以直接围绕目标字段理解图片内容,并输出更接近业务需要的结构。
3. 搜索不只是工具,而是推理过程的一部分
在 Agent 工作流里,搜索经常不是一次性的动作。模型可能需要先搜索背景资料,再搜索细节数据,还要对不同来源的信息做交叉验证。
传统流程是:
模型判断缺少信息 -> 调用搜索工具 -> 把搜索结果塞回上下文 -> 模型继续回答
问题在于,搜索结果往往很长,直接塞给模型会占用上下文窗口,也会带来噪声。Agent 更需要模型具备这样的能力:
| 搜索阶段 | 模型需要做什么 |
|---|---|
| 判断是否要搜索 | 区分常识问题、时效问题和需要核验的问题 |
| 生成查询词 | 把用户目标转成适合搜索的关键词 |
| 过滤结果 | 去掉重复、低质量、无关内容 |
| 压缩上下文 | 只保留对当前任务有用的信息 |
| 验证结论 | 避免把单一来源当成事实 |
Step 3.7 Flash 强调搜索能力,核心意义不只是“能联网查资料”,而是让搜索更自然地嵌入 Agent 的决策过程。对于办公、研究、代码排错、资料整理这类任务,搜索效率会直接影响最终交付速度。
4. 开源带来的部署选择
Step 3.7 Flash 是开源模型,这意味着使用方式不只限于托管 API(Application Programming Interface,应用程序编程接口)。如果业务对数据安全、私有环境、审计合规有要求,可以考虑自部署。
两种使用方式的差别大致如下:
| 使用方式 | 适合场景 | 代价 |
|---|---|---|
| 托管 API | 快速验证、个人工具、轻量 Agent、无需维护推理服务 | 数据会经过服务端,需要关注配额、价格和网络稳定性 |
| 自部署 | 企业内网、敏感数据、本地化 Agent、定制推理服务 | 需要 GPU、部署运维、并发管理和监控体系 |
开源不等于零成本。模型可以自己部署,但推理资源、显存占用、并发调度、日志监控和升级维护都要自己处理。对个人开发者来说,先用官方平台接入验证体验,通常比直接搭推理集群更省事。
如何接入 Step 3.7 Flash
官方提供了模型文档和 Step Plan 接入方式:
模型接入文档:https://platform.stepfun.com/docs/zh/guides/models/step-3.7-flash
Step Plan:https://platform.stepfun.com/step-plan
Step Plan 快速开始:https://platform.stepfun.com/docs/zh/step-plan/quick-start
如果一个 Agent 工具支持自定义模型供应商,或者支持 OpenAI Compatible(兼容 OpenAI 接口格式)的模型服务,通常只需要配置三类信息:
| 配置项 | 含义 |
|---|---|
| Base URL | 模型服务接口地址 |
| API Key | 平台生成的访问密钥 |
| Model Name | 模型名称,例如 step-3.7-flash |
示例配置可以写成这样,实际字段名要按具体工具调整:
{
"provider": "step",
"type": "openai-compatible",
"baseURL": "https://api.stepfun.com/v1",
"model": "step-3.7-flash",
"apiKeyEnv": "STEP_API_KEY"
}
在 Python 里调用 OpenAI 兼容接口时,结构通常如下:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["STEP_API_KEY"],
base_url="https://api.stepfun.com/v1"
)
response = client.chat.completions.create(
model="step-3.7-flash",
messages=[
{
"role": "system",
"content": "你是一个擅长拆解任务并调用工具的 Agent。"
},
{
"role": "user",
"content": "把当前项目的 README 改写成更适合新手阅读的版本,并列出修改要点。"
}
]
)
print(response.choices[0].message.content)
如果要处理图片,可以使用多模态输入。不同平台的图片字段可能略有差异,思路是把文本指令和图片一起发给模型:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["STEP_API_KEY"],
base_url="https://api.stepfun.com/v1"
)
response = client.chat.completions.create(
model="step-3.7-flash",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "请从这张发票图片中提取日期、发票号码、购买方、销售方、金额,并输出 JSON。"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,这里放图片base64内容"
}
}
]
}
]
)
print(response.choices[0].message.content)
接入 Claude Code、OpenClaw、桌面语音助手或自研 Agent 时,关键不是把模型名填进去就结束,而是要把模型能力和工具编排对齐:
flowchart LR
A[Agent 框架] --> B[模型 Provider 配置]
B --> C[Step 3.7 Flash]
A --> D[工具层]
D --> E[文件系统]
D --> F[搜索工具]
D --> G[代码执行器]
D --> H[办公软件]
C --> A
模型负责规划和生成,工具层负责执行动作。Agent 框架需要记录每一步的输入输出,失败时把错误信息回传给模型,让模型能继续修正。
适合用在哪些场景
Step 3.7 Flash 更适合需要多轮执行、对延迟敏感、同时希望控制成本的 Agent 任务。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 代码修改与项目内问答 | 适合 | 多轮读取文件、生成补丁、解释错误,需要较快响应 |
| 办公自动化 | 适合 | 文档整理、表格抽取、报告生成通常由多个小步骤组成 |
| 发票、截图、表格识别 | 适合 | 多模态能力能减少单独 OCR 模块 |
| 搜索型研究任务 | 适合 | 搜索、筛选、总结和交叉验证对链路效率要求高 |
| 极难数学推理 | 需要评估 | Flash 模型不一定是所有高难推理任务的最优选择 |
| 强监管生产环境 | 需要评估 | 自部署可控性更高,但要承担运维和安全成本 |
接入时容易踩的坑
只看 TPS 不够
400 TPS 说明生成吞吐很高,但 Agent 体验还受首 Token 延迟、上下文长度、工具执行速度、网络耗时和重试次数影响。评估时不要只跑一句问答,可以用真实任务脚本压测。
建议压测指标:
- 首 Token 延迟
- 平均输出速度
- 单任务总耗时
- 工具调用成功率
- 多轮任务完成率
- 失败重试次数
多模态任务要控制输入质量
图片太糊、倾斜严重、遮挡字段、分辨率过低,都会影响识别结果。发票、合同、表格这类任务最好加一层校验,例如金额字段必须能转成数字,日期必须符合格式。
def validate_invoice(data: dict) -> list[str]:
errors = []
if not data.get("invoice_no"):
errors.append("缺少发票号码")
if not data.get("amount"):
errors.append("缺少金额")
try:
float(str(data.get("amount", "")).replace(",", ""))
except ValueError:
errors.append("金额格式不合法")
return errors
搜索结果要做压缩
Agent 搜索到的网页内容不要整段塞回模型。更稳的做法是先提取标题、来源、发布时间和关键片段,再让模型基于压缩后的上下文判断。
{
"query": "Step 3.7 Flash agent benchmark",
"results": [
{
"title": "页面标题",
"source": "来源站点",
"published_at": "发布时间",
"snippet": "与当前问题直接相关的摘要"
}
]
}
自部署要提前算资源账
开源模型可以放到自己的环境里跑,但高并发 Agent 会持续消耗 GPU 资源。上线前至少要确认:
- 单实例能承受多少并发;
- 平均上下文长度是多少;
- 是否需要量化;
- 日志里是否会记录敏感输入;
- 是否要做请求限流;
- 模型升级时如何回滚。
小结
Step 3.7 Flash 的重点不是“又一个更快的聊天模型”,而是把高吞吐、多模态、搜索和开源部署组合到 Agent 场景里。对需要频繁调用模型的桌面助手、代码 Agent、办公自动化和资料整理工具来说,链路效率会直接决定可用性。
如果目标是快速接入,可以从官方 API 或 Step Plan 开始;如果目标是私有化和数据可控,再评估自部署成本。真正落地时,模型只是 Agent 系统的一部分,工具编排、错误回传、结果校验和搜索压缩同样决定最终体验。