Agent Skill 可以理解成给智能体使用的“能力说明书”:里面写清任务目标、执行步骤、工具调用方式、输出格式、异常处理和禁止行为。一个写得好的 Skill,能让大语言模型在重复任务里表现得更稳定;一个写得含糊的 Skill,会让模型在边界情况里漂移,甚至把错误流程固化下来。
达尔文 Skill 2.0 解决的就是这个问题:不要靠人一遍遍通读 Skill 文档、凭感觉修改,而是把 Skill 的评估、修改、验证和回滚做成一套可重复流程。它会让独立评委给 Skill 打分,找出最低维度,只改一个关键问题;改完之后重新验证,分数没有严格上涨就回滚。整个过程类似进化算法:产生变异、接受更好的版本、淘汰退化版本。
达尔文 1.0 已经具备这个雏形:多维评分、最低维度优先、自动回滚、评分模型和修改模型分离、低风险场景支持干跑。1.0 的实测记录是 40 次优化、平均提升 13.5 分、0 次回滚。不过,0 次回滚并不等于评估体系足够可靠,因为 LLM-as-a-Judge(用大语言模型充当评审)的准确性高度依赖评分标准本身。
微软研究院联合复旦、上海交通大学在 2026 年 5 月发布的两项工作,刚好把 Skill 优化拆成了两个关键问题:
- SkillLens:研究 Skill 应该怎么评估。
- SkillOpt:研究 Skill 应该怎么自动优化。
达尔文 Skill 2.0 的核心升级,就是把 SkillLens 的评分维度、SkillOpt 的验证闸门,再加上面向个人开发者的人工卡口,组合成一个轻量但可控的 Skill 优化器。
SkillLens:AI 评委不可靠,除非评分标准足够硬
SkillLens 的一个关键结论很直接:如果只让单个 AI 评委在松散标准下判断两份 Skill 哪个更好,准确率只有 46.4%。这比随机抛硬币还低。
这说明一个问题:让大语言模型当评委并不天然可靠。它能给出解释,能打出分数,但如果标准不够具体,它可能只是用流畅的语言包装随机判断。Skill 优化流程一旦建立在这种评分上,就会出现“分数在涨,能力没涨”的假象。
SkillLens 给出的改进方向是强化评分 rubric,也就是评审规则。加入三个关键维度后,评估准确率可以提升到 73.8%。
| 维度 | 要求 | 不合格写法 |
|---|---|---|
| 失败模式编码 | 不只写正常流程,还要写清失败条件、分支处理和兜底方案 | “如果失败就重试” |
| 可执行具体性 | 指令必须能直接执行,减少模糊措辞 | “可以考虑优化提示词” |
| 高风险行动黑名单 | 明确列出绝对不能做的事 | 只写应该做什么,不写禁止行为 |
这三个维度的共同点是“把模糊空间压缩掉”。Skill 文档越像操作规程,模型越不容易自由发挥;越像建议清单,模型越容易在关键步骤上跑偏。
SkillOpt:把 Skill 当成可训练的外部状态
SkillOpt 的思路更像训练系统。它不修改模型权重,而是把 Skill 文档看成 frozen model(冻结模型)外部的一组可训练状态。训练对象不是神经网络参数,而是 Skill 里的文字。
它的优化循环可以抽象成四步:
flowchart LR
A[Rollout 跑任务] --> B[Reflect 复盘成功和失败轨迹]
B --> C[Edit 提议文本修改]
C --> D[Validate 留出集验证]
D -->|通过| E[接受新 Skill]
D -->|不通过| F[拒绝改动]
E --> A
F --> A
四个阶段分别做这些事:
| 阶段 | 作用 |
|---|---|
| Rollout | 让目标模型使用当前 Skill 跑一批真实任务,记录结果和分数 |
| Reflect | 用独立优化器分析成功样本和失败样本,找出可复用规律 |
| Edit | 在文本编辑预算内提出增、删、改,不允许一次性大幅重写 |
| Validate | 只有留出测试集分数严格提升,改动才会写入 |
这里最关键的是 Validate。它相当于把机器学习里的“只有 loss 下降才接受更新”搬到文本空间里。Skill 可以变,但每次变化都要经过测试集验证,不能只靠模型自己说“我改好了”。
SkillOpt 的实验覆盖了 6 个 benchmark、7 个模型、3 个执行环境,共 52 个组合。实验结果显示,SkillOpt 在所有组合中达到最强或并列最强。它对比的基线包括人工写 Skill、一次性 LLM 生成 Skill,以及 TextGrad、GEPA、EvoSkill 等提示词优化方法。
这套方案很强,但它默认你有 benchmark(基准测试集)和可计算的评分函数。企业内部的代码修复、数据处理、工具调用任务比较适合这种范式;写作风格、内容生产、角色视角这类主观任务,则很难提前定义一个足够客观的验证集。
达尔文 Skill 2.0 的整体工作流
达尔文 Skill 2.0 可以看成一个面向个人开发者的 SkillOpt 轻量变体。它不强制要求 benchmark,而是用 rubric-driven(评分标准驱动)的方式评估 Skill 文档,再用人工卡口控制关键决策。
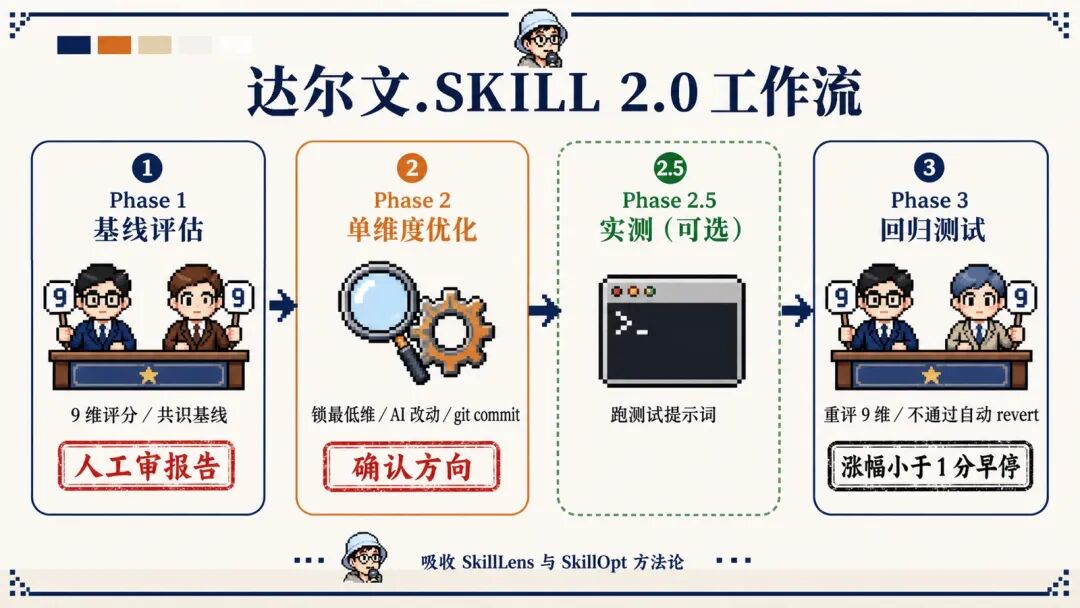
这张工作流图概括了达尔文 2.0 的四个核心模块:9 维评分、单维度编辑、验证闸门、人工卡口。流程不是让 AI 一路自动改到底,而是在关键节点暂停,让人确认修改方向和测试结果。
可以把它抽象成下面这条链路:
flowchart TD
A[目标 Skill 文档] --> B[基线评估:两个独立评委打分]
B --> C[找出最低维度]
C --> D[只针对最低维度生成最小修改]
D --> E{人工确认修改方向}
E -->|拒绝| C
E -->|接受| F[运行测试提示词或真实任务]
F --> G[启动全新评委复评]
G --> H{分数是否严格提升}
H -->|否| I[git revert 回滚]
H -->|是| J[保留提交]
J --> K{单轮涨幅是否低于阈值}
K -->|是| L[早停]
K -->|否| C
它和 1.0 相比,主要升级在四个位置。
1. 评分标准从 8 维升级到 9 维
达尔文 2.0 直接吸收了 SkillLens 的三个关键评估维度。
| 变化 | 2.0 的要求 |
|---|---|
| 错误处理升级为失败模式编码 | 写清 “如果 X 发生,就做 Y;否则做 Z” |
| 明确性升级为可执行具体性 | 明确禁止“建议、可以考虑、根据情况、灵活把握、视情况而定”等软化措辞 |
| 新增高风险行动黑名单 | Skill 必须有独立章节说明绝对不要做什么 |
这些规则会逼迫 Skill 从“经验描述”变成“执行规范”。例如,下面这种写法不够好:
如果生成效果不好,可以适当优化提示词,并根据情况调整参数。
更好的写法应该把触发条件和动作写死:
如果图像中文字出现错字:
1. 将画质参数从 medium 改为 high;
2. 在提示词开头加入:“每个汉字必须逐字精确渲染”;
3. 如果仍失败,将中文文本放到提示词最前面,并用双引号包裹。
前者像建议,后者才像 Skill。
2. 验证闸门变成多层机制
1.0 的回滚逻辑是“总分没涨就回滚”。2.0 把验证拆得更细:
| 机制 | 作用 |
|---|---|
| 多评委独立审查 | 每轮使用两个彼此独立的评委,减少单评委随机性 |
| 评委不复用 | 下一轮启动新的评委,避免上一轮结论形成锚定 |
| 严格提升才接受 | 分数没有上涨就拒绝写入,并用 git revert 回滚 |
| 早停 | 单轮涨幅低于阈值时停止,避免为了凑分堆冗余 |
| 干跑比例告警 | 干跑超过 30% 时提示必须做实测验证 |
多评委不是 SkillLens 论文中的原始结论。SkillLens 验证的是“单评委 + 强化 rubric”能把准确率提升到 73.8%。达尔文 2.0 的多评委设计属于工程加固:既然单评委仍可能误判,就让两个独立判断形成共识。
3. Human in the Loop 负责关键决策
Human in the Loop(人在回路)是达尔文 2.0 和 SkillOpt 的重要差异。
SkillOpt 更适合全自动 benchmark-driven 场景。只要任务集和评分函数定义好,它可以批量跑,最终输出一个最佳 Skill。
个人开发者经常没有这种条件。比如一个公众号写作 Skill、角色扮演 Skill、配图提示词 Skill,它们的好坏往往包含主观判断:语气是否一致、风格是否稳定、内容是否顺畅、边界情况是否可接受。这些指标很难完全塞进自动评分函数。
达尔文 2.0 因此把流程切成多个明确卡口:
| 阶段 | 自动部分 | 人工卡口 |
|---|---|---|
| 基线评估 | 评委打 9 维分数,输出问题报告 | 决定是否认可最低维度 |
| 单维度优化 | 修改最低维度对应内容 | 确认修改方向 |
| 测试提示词 | 跑真实任务或半自动测试 | 判断结果是否符合预期 |
| 回归测试 | 新评委重新打分 | 决定是否继续下一轮 |
AI 负责发现问题、提出修改和执行重复检查,人负责判断方向是否偏离真实需求。这样既有自动化杠杆,又不会让文档在无人确认的情况下被改得面目全非。
4. 反例黑名单让流程更抗踩坑
SkillLens 要求 Skill 必须写“不要做什么”。达尔文 2.0 把这一点落到了自身流程里,形成了一组反例黑名单。
| 反例 | 为什么危险 | 更安全的做法 |
|---|---|---|
| 同一个 AI 又改又评 | 容易自我确认,评分失真 | 修改模型和评审模型分离 |
用 git reset --hard 回滚 | 破坏历史,难以审计 | 使用 git revert 保留可追溯记录 |
| 为了涨分堆冗余 | 文档变长,但执行效果未必更好 | 单轮只修最低维度 |
| 跳过测试提示词 | 静态评分无法证明真实任务可用 | 至少跑一组代表性任务 |
| 一轮内改多个维度 | 难以判断是哪处带来变化 | 控制文本编辑预算 |
| 干跑比例过高 | 只有文档分析,没有执行证据 | 干跑超过阈值必须实测 |
| 静默跳过异常 | 错误被隐藏,评分虚高 | 异常必须进入报告 |
| 忽视维度相关簇 | 改一维可能影响相邻维度 | 观察相关维度是否联动变化 |
这类黑名单比“最佳实践”更实用,因为它直接规定了流程中不能越过的红线。
用真实 Skill 验证:从 80.8 到 91.5
达尔文 2.0 的验证对象之一是 huashu-gpt-image,一个用于 GPT-image-2 生图的 Skill,原始文档 368 行。
基线评估使用两个独立评委。它们互相不知道对方存在,也不知道后续会如何修改。
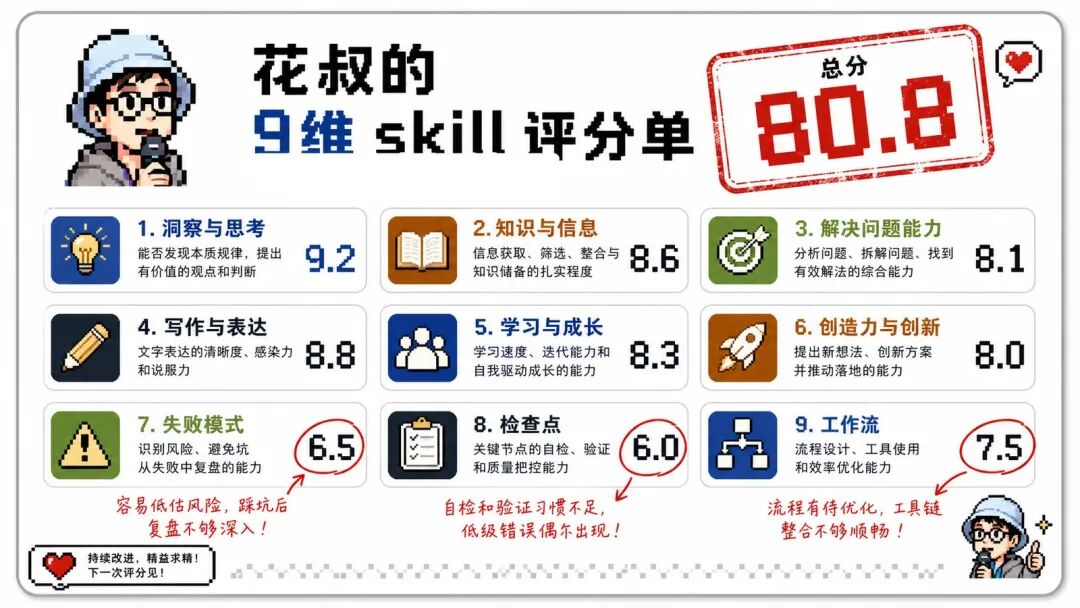
这张评分单显示,基线共识分为 80.8。两个评委独立指出同一个最低维度:失败模式。也就是说,Skill 已经能描述正常工作流,但对常见失败条件、修复路径和兜底策略写得不够硬。
按照“一轮只改最低维度”的规则,优化只增加失败模式相关内容,不同时修改其它部分。新增的核心结构类似下面这张表:
| 失败现象 | 触发条件 | 一线修复 | 仍失败兜底 |
|---|---|---|---|
| 中文字渲染错误 | 画质为 medium,或提示词没明确渲染要求 | 升级为 high,并写明“每个汉字精确渲染” | 将中文文本放到提示词最前,并用双引号包裹 |
| 接口限流 429 | 子进程返回 quota 错误 | 等待几分钟后重试 | 切换另一条 API 路径 |
| 5×5 网格末行被压缩 | 用 1:1 画布生成 2:3 卡片 | 降级为 4×4 网格 | 把画布尺寸决策权交还给 AI |
这次修改把文件从 368 行增加到 449 行。随后启动两个全新评委复评,不复用基线阶段的评委。
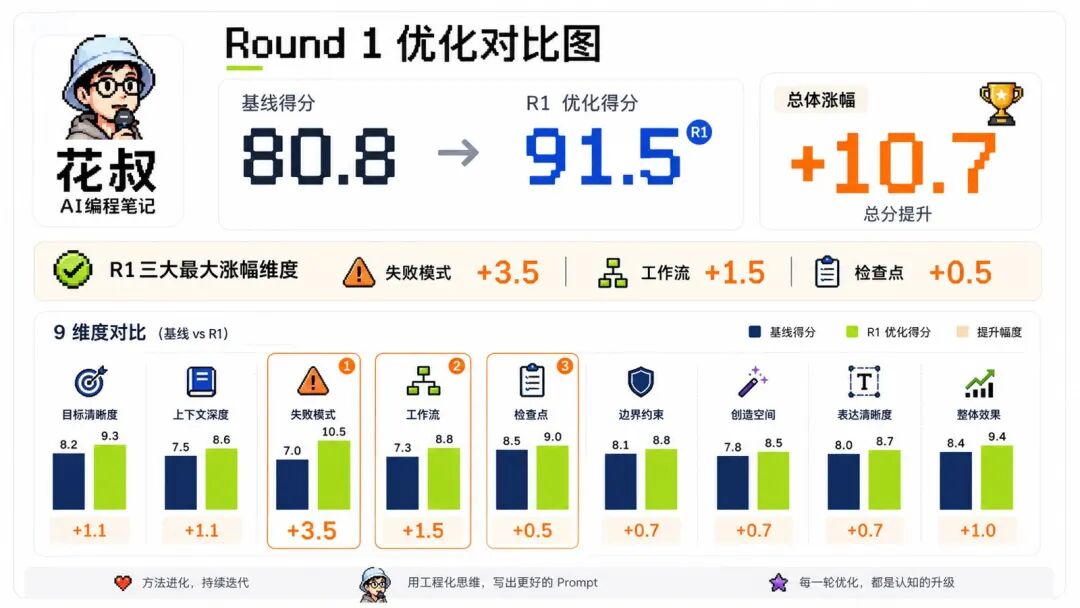
复评共识分从 80.8 提升到 91.5,单轮增加 10.7 分。失败模式维度从 6.5 提升到 10 分。
还有一个有意思的现象:只修改失败模式后,工作流维度也从 7.5 提升到 9.0。原因不难理解,失败模式要求写清“如果 X 就做 Y,否则做 Z”,这会天然补全流程分支,让工作流也变得更清晰。
这说明评分维度不是完全独立的。失败模式、工作流、检查点经常构成一个相关簇。改动其中一个维度,可能带动相邻维度一起变化。达尔文 2.0 把这种现象纳入反例黑名单,避免在相邻维度之间重复堆内容。
第二轮继续优化次低维度,增加了“单图工作流”,让它和已有的“批量工作流”对称。新评委复评后,共识分只从 91.5 增加到 91.65,涨幅 0.15。早停机制触发,流程停止。
早停很重要。Skill 优化不是把分数刷到满分,而是在文档长度、清晰度和实际收益之间保持平衡。涨幅进入平台期后继续改,往往只会制造冗余。
自指评估:让达尔文审查达尔文
达尔文 2.0 还做了一个特殊实验:用它自己的规则审查自己的 SKILL.md。
这个实验有点像“写规则的工具被自己的规则审判”。它能暴露一种常见盲区:设计新规则时,注意力集中在新规则是否合理,却容易忘记旧内容是否也符合新规则。
两个独立评委给达尔文自己的基线分为 86.05,并指出三个问题:
| 问题 | 具体表现 | 对应规则 |
|---|---|---|
| 版本描述不同步 | 有些地方仍写“8 维评分标准”,正文已经升级为 9 维 | 文档一致性 |
| 检查点不够显性 | 关键卡口只用粗体,没有使用 🔴、STOP、CHECKPOINT 等强标记 | 检查点必须显性 |
| 软化措辞超标 | 出现多处“建议”“可以考虑”等表达 | 可执行具体性 |
这三个问题都不是复杂逻辑错误,而是规则升级后的结构性遗漏。靠写文档的人自己检查,很容易漏掉;让独立评委按字面规则审查,就能把这些不一致扫出来。
修复后,达尔文自己的分数从 86.05 提升到 92.05。随后又按照 Skill 写作实践,把详细论文证据下沉到子目录,主文档从 550 行精简到 484 行,最终分数达到 92.7。
这个实验说明,达尔文不只是优化业务 Skill,也能优化“如何写 Skill”的规则本身。一个 Skill 优化器如果能经受住自指评估,说明它至少能发现自己文档里的规则冲突、检查点缺失和措辞问题。
扫描整个 Skill 生态:近 30 个 Skill 的批量优化
单个 Skill 的分数提升可能有偶然性。更好的验证方式是把同一套流程应用到一组不同类型的 Skill 上。
达尔文 2.0 被用于优化近 30 个 Skill,包括 perspective skill 和日常业务 Skill。每个 Skill 都执行两轮独立评委、9 维评分、验证闸门回滚和人工卡口。
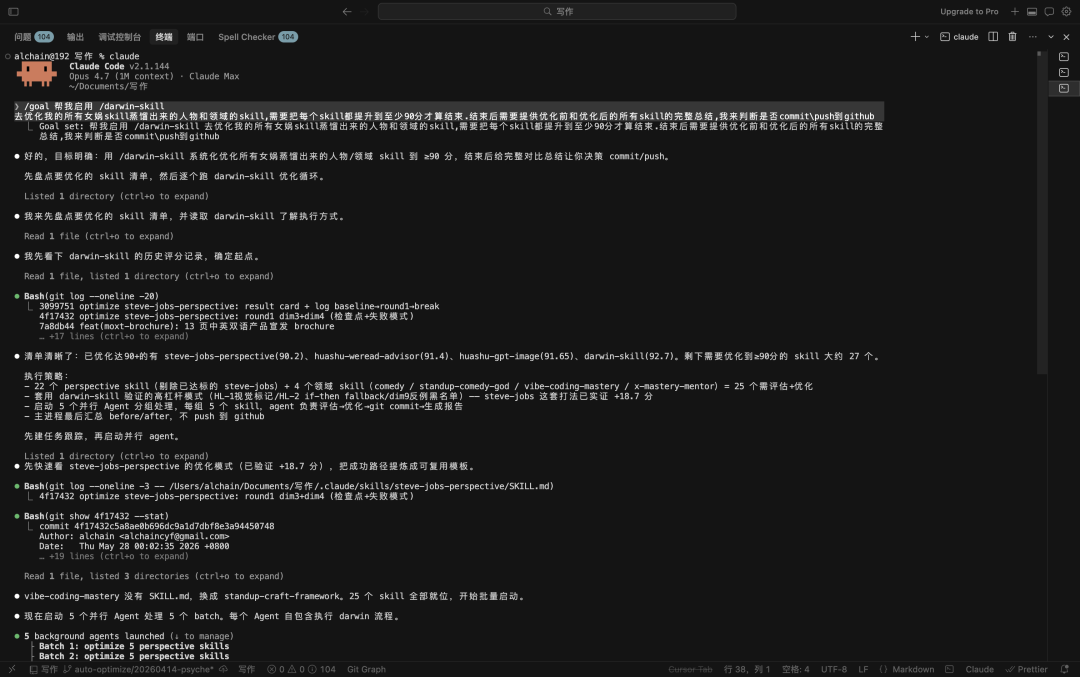
这张结果图展示了批量优化后的整体变化。代表性结果包括:
| Skill | 优化前 | 优化后 | 涨幅 |
|---|---|---|---|
| steve-jobs-perspective | 64 | 94 | +30 |
| huashu-weread-advisor | 80+ | 91.4 | 约 +10 |
| huashu-gpt-image | 80.8 | 91.65 | +10.85 |
| darwin-skill | 86.05 | 92.7 | +6.65 |
| vibe-coding-mastery / x-mastery-mentor / standup-comedy-god | 未列出 | 全部进入 90+ | - |
整组 Skill 的平均涨幅约为 +15 分。每次改动都有 git commit 链可追溯,验证没通过的改动会自动 revert,人工卡口负责确认修改方向。
这里的关键不只是分数,而是维护规模。一个人维护几十个 Skill 时,纯人工审查很难持续;达尔文 2.0 把重复劳动交给评委和优化器,人只在 CHECKPOINT 做判断。它没有消灭人工决策,而是把人工决策集中在更高价值的位置。
达尔文 2.0 和 SkillOpt 的分工
达尔文 2.0 不是 SkillOpt 的替代品。两者解决的问题相近,但适用场景不同。
| 对比项 | SkillOpt | 达尔文 Skill 2.0 |
|---|---|---|
| 驱动方式 | benchmark-driven | rubric-driven |
| 是否需要测试集 | 需要明确 validation set | 不强制需要 |
| 自动化程度 | 更偏全自动 | 自动化 + 人工卡口 |
| 评估方式 | 任务执行结果和评分函数 | 9 维 Skill 文档评分 + 可选实测 |
| 适合场景 | 企业级、可量化任务、大规模训练 | 个人 Skill 生态、写作/风格/内容类任务 |
| 风险控制 | 留出集验证 | 多评委、早停、回滚、人工确认 |
| 成本 | 更高,需要准备 benchmark | 更低,直接从 Skill 文档开始 |
如果任务能定义清晰 benchmark,例如代码修复准确率、工具调用成功率、结构化输出通过率,SkillOpt 更适合。它能全自动跑大量任务,用验证集选择更好的 Skill。
如果任务主要依赖主观评估,例如写作风格、内容策划、角色视角、配图提示词、个人工作流,达尔文 2.0 更合适。它不要求一开始就准备完整 benchmark,而是先用可读评分标准把 Skill 文档变硬,再通过人工卡口控制方向。
上手方式
仓库地址:
https://github.com/alchaincyf/darwin-skill
可以先克隆仓库:
git clone https://github.com/alchaincyf/darwin-skill.git
如果使用的 Agent 支持读取本地 Skill 或远程仓库,可以让它加载该仓库中的 SKILL.md,然后指定要优化的目标 Skill:
请读取 darwin-skill 仓库中的 SKILL.md,
对 path/to/target-skill/SKILL.md 运行达尔文优化流程。
要求:
1. 先做 9 维基线评估;
2. 启动两个独立评委;
3. 只选择最低维度进行第一轮优化;
4. 修改前给出 CHECKPOINT,等待确认;
5. 修改后运行测试提示词或真实任务;
6. 使用全新评委复评;
7. 如果分数没有严格提升,用 git revert 回滚。
一轮基线评估加一轮优化通常需要 15 到 30 分钟,主要耗时在评委 Agent 返回结果。目标 Skill 越长、测试提示词越多,耗时越高。
使用时要注意的坑
达尔文 2.0 把 Skill 优化流程工程化,但它不是万能评分器。使用时需要控制几个边界。
| 风险 | 说明 | 处理方式 |
|---|---|---|
| 分数上涨不等于业务结果一定上涨 | rubric 评估的是 Skill 文档质量,真实任务仍可能失败 | 保留代表性测试提示词 |
| 评委仍可能误判 | 即使强化 rubric,LLM-as-a-Judge 也不是绝对可靠 | 使用多评委和人工卡口 |
| 过度优化会让文档变臃肿 | 为了补规则不断加段落,可能降低可读性 | 单轮只改最低维度,低涨幅早停 |
| 主观任务难以完全自动验证 | 写作、风格、审美类任务很难有客观分数 | 人工确认关键输出 |
| 回滚方式不能破坏历史 | reset --hard 会让审计链断掉 | 使用 git revert |
达尔文 Skill 2.0 的价值在于把“自己审自己”变成“独立评委审查 + 验证通过才接受”。Skill 仍然是文本,但它不再是一次写完就长期静止的文档,而是可以被评估、被修改、被验证、被回滚的外部状态。
当一个人维护的 Skill 数量从几个增长到几十个时,这套流程能把维护成本压下来:AI 负责重复检查和局部改写,人负责方向判断和最终验收。Skill 的进化不再依赖临时灵感,而是进入一条可重复执行的工程流水线。