Warp 的开源让命令行工具重新成为开发者工具里的热门话题。它用 Rust 实现客户端核心,并以 AGPL(GNU Affero General Public License,一种对网络服务分发约束更强的开源许可证)开放代码,同时把 AI(人工智能)能力放在产品设计的中心位置。
但讨论 Warp 时,最容易把两个概念混在一起:
| 名称 | 本质 | 负责什么 |
|---|---|---|
| Bash / Zsh / Fish | Shell,命令解释器 | 解析命令、执行脚本、管理环境变量、提供补全 |
| Terminal / iTerm2 / Windows Terminal / Warp | 终端模拟器或开发环境 | 显示命令行界面、接收键盘输入、渲染输出 |
| Warp AI / Oz | AI Agent 能力 | 读取上下文、解释错误、生成命令、辅助改代码 |
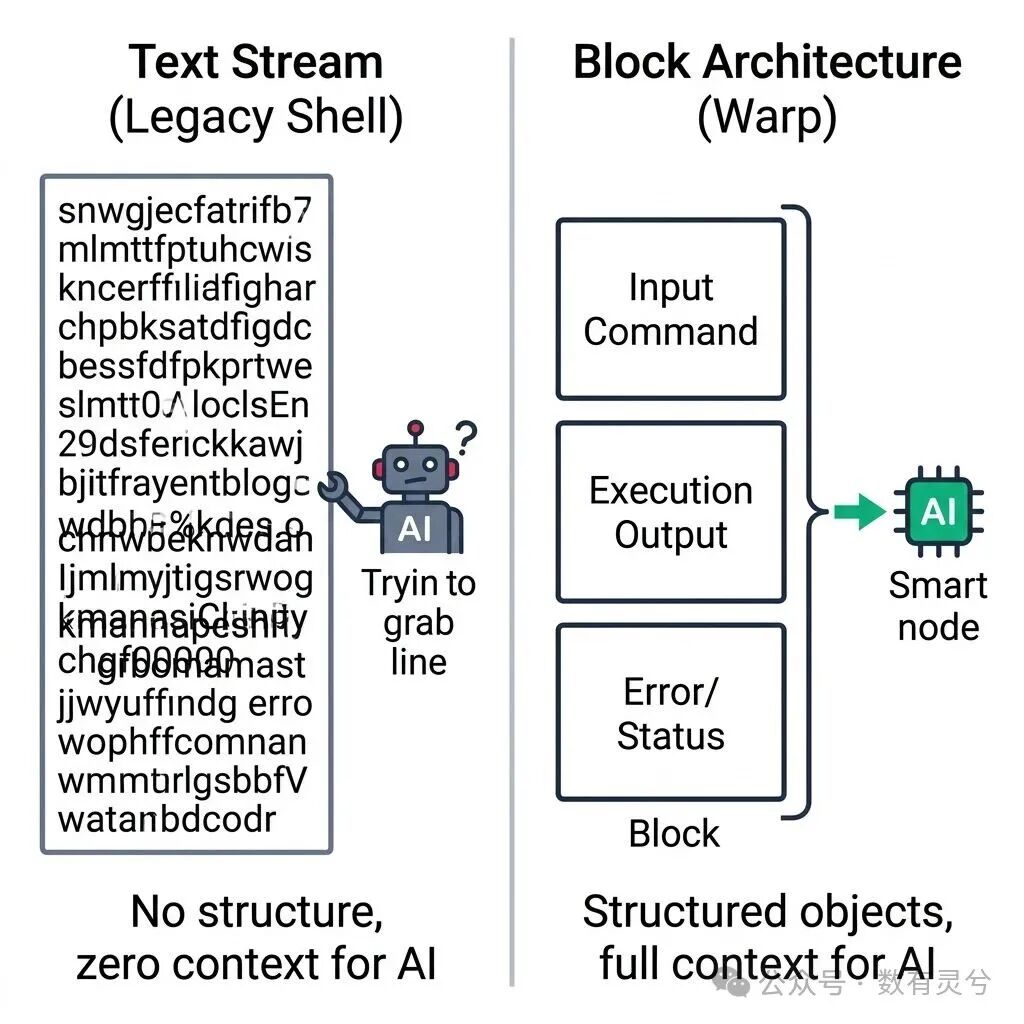
所以,问题不是“Zsh 会不会立刻消失”。更准确的说法是:传统终端基于纯文本流的交互模型,很难承载 AI Agent 所需要的结构化上下文;Warp 的 Block 架构试图补上这一层。
Zsh 仍然可以作为 Warp 里的默认 Shell。被挑战的不是 Shell 语言本身,而是过去几十年里“终端只负责显示字符流”的底层交互方式。
传统终端的问题:所有东西都会变成一长串字符
在 Bash 或 Zsh 里执行一条命令时,程序会把内容写到 stdout(标准输出)和 stderr(标准错误)。终端模拟器再通过 PTY(Pseudo Terminal,伪终端)接收这些字符,并把它们画到屏幕上。
npm run build
输出可能长这样:
> app@1.0.0 build
> vite build
src/main.ts:12:8 - error TS2307: Cannot find module './config'
12 import config from './config'
~~~~~~
Found 1 error.
对人来说,这是一段“构建失败日志”。我们能看出命令是什么、错误在哪里、应该去改哪个文件。
但对传统终端来说,它看到的更接近这样:
用户敲了一些字符
程序吐出一些字符
屏幕滚动了一些字符
它并不知道哪一段输出属于哪一条命令,也不知道错误日志和普通日志之间有什么边界。颜色、高亮、清屏、光标移动主要依赖 ANSI 转义序列(控制颜色、光标位置等显示效果的特殊字符),这些信息更偏向“怎么显示”,不是“这段数据代表什么”。
传统终端的数据路径大致是这样:
flowchart LR
A[键盘输入] --> B[Shell: Bash / Zsh]
B --> C[子进程: npm / python / git]
C --> D[stdout / stderr 字符流]
D --> E[PTY 伪终端]
E --> F[终端滚动缓冲区]
F --> G[屏幕显示]
这种模型在纯人工操作时足够好。开发者用眼睛找错误,用鼠标复制日志,再把内容贴到搜索引擎或大语言模型里。
AI Agent 接手后,问题会变得明显:它需要知道上下文边界。
一条失败命令至少应该包含这些信息:
{
"command": "npm run build",
"cwd": "/Users/me/project/web",
"exit_code": 1,
"stdout": "...",
"stderr": "src/main.ts:12:8 - error TS2307...",
"shell": "zsh",
"timestamp": "2026-06-07T10:30:00+08:00"
}
传统终端通常只能提供一段混在滚动缓冲区里的文本。Shell 历史里可能有命令,但命令历史和输出结果并不是天然绑定的。AI 如果想分析失败原因,就必须依赖用户手动复制命令、日志、目录、环境信息。
这就是很多“给 Zsh 加 AI 插件”的局限:它们能生成下一条命令,却很难可靠理解上一条命令为什么失败。
Warp 的核心变化:把一次命令执行封装成 Block
Warp 最关键的设计不是主题、动画或补全,而是 Block。
一个 Block 可以理解成一次完整的命令交互单元。它把命令本身、命令输出、错误信息、退出码、工作目录等上下文封装在一起,并作为一个独立的 UI(用户界面)对象显示。
传统终端像一条不断追加的纸带:
命令 A
输出 A
命令 B
输出 B
错误 B
命令 C
输出 C
Warp 更像一组结构化卡片:
Block A = 命令 A + 输出 A + 退出码
Block B = 命令 B + 输出 B + 错误 B + 退出码
Block C = 命令 C + 输出 C + 退出码
对应的结构可以画成这样:
flowchart TB
A[输入命令] --> B[创建 Block]
B --> C[通过 Shell 执行命令]
C --> D[收集 stdout]
C --> E[收集 stderr]
C --> F[记录退出码]
C --> G[记录工作目录和环境上下文]
D --> H[Block 渲染]
E --> H
F --> H
G --> H
H --> I[用户查看]
H --> J[AI Agent 分析]
这个变化对 AI Agent 很重要。大语言模型 LLM(Large Language Model,大语言模型)不擅长从混乱文本里猜边界,但很擅长处理结构化上下文。Block 把“刚才发生了什么”整理成一个完整对象,AI 才能稳定回答这些问题:
- 哪条命令失败了?
- 失败命令在哪个目录执行?
- 标准输出和标准错误分别是什么?
- 命令退出码是多少?
- 需要修复依赖、改配置,还是修改源代码?
- 生成的修复命令是否能直接在当前目录运行?
当用户对失败 Block 发起 AI 分析时,调用链更接近这样:
sequenceDiagram
participant U as 用户
participant W as Warp
participant B as Block
participant M as LLM 大语言模型
participant S as Shell
U->>W: 选择失败的 Block 并请求解释
W->>B: 读取命令、输出、错误、目录、退出码
B-->>W: 返回结构化上下文
W->>M: 发送上下文并请求诊断
M-->>W: 返回原因、修复步骤、候选命令
W-->>U: 展示可确认的修复建议
U->>W: 确认执行
W->>S: 执行修复命令
这里的关键不是“AI 更聪明了”,而是“AI 拿到的数据更完整了”。同一个模型,如果只看到几十行错误日志,可能只能猜;如果同时看到触发错误的命令、目录、退出码和完整输出,诊断质量会稳定很多。
Ask Warp AI 的价值在于上下文绑定
Warp 的 AI 分析入口通常围绕 Block 展开。用户不需要从滚动日志里精确框选某一段,再手动补充“我刚才执行的是 npm run build”。Block 已经把命令和输出绑定好了。
这个界面的重点不只是多了一个提问按钮,而是交互对象发生了变化。AI 面对的不是一块随手复制的文本,而是一次完整命令执行记录。它可以围绕这个 Block 给出解释、修复命令或后续排查步骤,用户再决定是否执行。
这种方式尤其适合这些场景:
| 场景 | 传统终端的麻烦 | Block 带来的变化 |
|---|---|---|
| 构建失败 | 需要复制命令和日志 | 失败命令与输出天然绑定 |
| 依赖缺失 | 错误可能埋在长日志中 | AI 可直接读取完整 stderr |
| Git 操作冲突 | 状态、命令、报错分散 | 一个 Block 记录一次操作结果 |
| 部署脚本失败 | 多行输出难以定位 | 按执行单元查看和诊断 |
| 长任务运行 | 滚动缓冲区容易丢上下文 | 每次命令保留独立边界 |
这也是 Warp 与普通“AI 命令生成器”的区别。命令生成器主要解决“我该敲什么”;Block + AI 解决的是“刚才发生了什么,以及下一步怎么安全处理”。
输入体验为什么也要重做
传统 Shell 输入适合短命令,不适合长文本。
例如这条命令稍微长一点,编辑体验就会变差:
docker run --rm -e NODE_ENV=production -v "$PWD:/app" -w /app node:22 bash -lc "npm ci && npm run build && npm run test"
如果要改中间某个参数,用户往往要依赖方向键、Ctrl+A、Ctrl+E、按词跳转等快捷键。熟悉 readline 的人能适应,但这套输入模型并不适合复杂命令、长提示词和多行任务说明。
AI Agent 加入后,终端输入不再只是 shell command,也可能是自然语言任务:
检查当前仓库的构建失败原因。
要求:
1. 不要修改业务逻辑;
2. 优先检查依赖版本和 TypeScript 配置;
3. 如果需要改文件,先列出计划;
4. 所有命令执行前都要让我确认。
这种输入更像在 IDE(Integrated Development Environment,集成开发环境)里编辑一段说明,而不是在传统终端里敲一行命令。
Warp 把输入栏做成更接近现代编辑器的交互方式,常见能力包括:
- 多行编辑;
- 鼠标定位光标;
- 常见编辑器快捷键;
- 括号、引号等基础编辑辅助;
- 更适合长命令和自然语言提示词的输入区域。
这不是单纯的“舒服一点”。当终端开始承载 AI Agent 任务时,输入区就从命令行变成了任务描述区。任务描述越复杂,传统单行输入的限制越明显。
Agent-First 开源协作:人写目标,Agent 写实现
Warp 开源后,另一个值得关注的方向是 Agent-First,也就是把 AI Agent 放进开源协作流程里。
传统开源贡献一般是:
flowchart LR
A[开发者发现问题] --> B[阅读代码]
B --> C[本地修改]
C --> D[运行测试]
D --> E[提交 PR]
E --> F[维护者 Review]
Agent-First 的分工会变成:
flowchart LR
A[人类提出需求或 Issue] --> B[人类补充约束和验收标准]
B --> C[AI Agent 阅读代码库]
C --> D[AI Agent 生成实现方案]
D --> E[AI Agent 修改代码并运行测试]
E --> F[人类审查架构和风险]
F --> G[提交 PR 合并请求]
这里的变化不是让 AI 直接替代维护者,而是把耗时的机械工作交给 Agent:检索代码、定位模块、生成初版实现、补测试、跑构建。人类更适合负责需求边界、设计取舍、安全审查和最终合并。
这种协作模式对大型 Rust 代码库尤其有意义。Rust 的类型系统和编译器反馈非常强,Agent 可以不断根据编译错误修正实现;人类则检查实现是否符合产品目标和长期架构。
不过,Agent-First 也有边界:
| 环节 | 适合交给 Agent | 仍然需要人类判断 |
|---|---|---|
| 代码检索 | 搜索调用链、定位文件 | 判断模块边界是否合理 |
| 初版实现 | 生成样板代码和局部逻辑 | 决定设计是否可维护 |
| 测试修复 | 根据失败信息补测试 | 判断测试是否覆盖真实风险 |
| 文档更新 | 根据改动生成说明 | 判断对外行为是否表达准确 |
| 安全审查 | 找常见漏洞模式 | 判断权限、隐私、供应链风险 |
AI Agent 能加快实现过程,但不能替代工程决策。尤其是终端工具会接触命令、路径、环境变量甚至密钥,任何自动化改动都需要严格审查。
Warp 适合什么场景,不适合什么场景
Warp 的优势集中在“本地开发 + 复杂上下文 + AI 辅助”这类工作流里。
| 场景 | 是否适合 Warp | 原因 |
|---|---|---|
| 前端构建、Node.js 项目开发 | 适合 | 构建日志长,Block 便于定位失败命令 |
| Python、Rust、Go 本地开发 | 适合 | 编译错误、测试失败适合交给 AI 分析 |
| Git 冲突处理 | 适合 | 命令、状态和错误可以形成上下文 |
| 容器与部署脚本调试 | 适合 | 多步骤命令更需要可追踪记录 |
| 远程服务器临时救火 | 谨慎 | 需要确认隐私、审计和网络策略 |
| 极简服务器环境 | 不适合替代 Shell | 服务器上通常仍然依赖 Bash / Zsh / sh |
| 强合规、完全离线环境 | 取决于配置 | 需要确认是否能接入本地模型和禁用云能力 |
| POSIX 脚本运行环境 | 不能替代 Shell | Warp 是交互层,不是脚本解释器 |
所以,Warp 更像是开发者桌面上的 AI 原生命令行环境,而不是用来替换所有服务器 Shell 的东西。
AGPL 开源意味着什么
Warp 选择 AGPL,而不是 MIT、Apache-2.0 这类更宽松的许可证,说明它希望开放代码,同时防止云服务厂商直接拿走核心代码做闭源托管服务。
对普通使用者来说,AGPL 通常不会影响日常使用;对准备修改、分发或提供网络服务的团队来说,需要认真阅读许可证条款,尤其是修改后通过网络提供服务时的源码开放义务。
可以简单理解为:
| 使用方式 | 需要关注什么 |
|---|---|
| 本地安装使用 | 主要关注隐私和配置 |
| 阅读源码学习 | 遵守许可证即可 |
| 修改后内部使用 | 仍应咨询团队合规要求 |
| 基于代码提供服务 | AGPL 义务需要重点评估 |
| 二次分发客户端 | 需要遵守源码开放和许可证声明要求 |
开源降低了安全审查门槛。开发者可以检查客户端如何处理命令、日志、AI 请求和本地配置,这比完全闭源更容易建立信任。
如何开始使用或研究 Warp
如果目标是体验 Warp 的 AI 工作流,可以按这条路径走:
flowchart TB
A[安装 Warp] --> B[选择默认 Shell: zsh / bash / fish]
B --> C[配置 AI Provider]
C --> D[执行真实开发命令]
D --> E[对失败 Block 发起 AI 分析]
E --> F[确认修复建议后再执行]
如果目标是研究源码或参与贡献,可以从仓库入手:
git clone https://github.com/warpdotdev/warp.git
cd warp
构建步骤、依赖版本和平台要求应以仓库 README 为准。Rust 项目通常会涉及 toolchain、系统依赖、测试命令和平台差异,直接照官方说明配置能少踩很多坑。
如果要把 Warp 接入私有化 AI 体系,重点检查这些配置:
| 配置项 | 需要确认的问题 |
|---|---|
| 本地模型 | 是否支持 Ollama 等本地模型运行方式 |
| 第三方模型 | 是否支持指定 API Endpoint 和 Key |
| 数据边界 | 命令、日志、路径是否会发送到云端 |
| 敏感信息 | 是否会包含 token、密钥、环境变量 |
| 团队策略 | 是否符合公司安全和合规要求 |
AI 终端的便利性来自上下文,但风险也来自上下文。发送给模型的信息越完整,越需要明确数据边界。
Zsh 不会消失,但终端交互层正在变厚
Bash 和 Zsh 的价值仍然很明确:它们是成熟的命令解释器,适合脚本、管道、环境管理和服务器自动化。大量基础设施仍然建立在这些 Shell 之上,短期内不可能被一个桌面终端取代。
真正变化的是终端交互层。
过去,终端只要把字符显示出来就够了;现在,终端需要理解“一次操作”的边界,并把它组织成 AI Agent 可以使用的上下文。Warp 的 Block 架构正是围绕这个目标设计的。
可以用一句话概括:
Shell 负责执行命令,Warp 负责把命令执行过程变成结构化、可追踪、可交给 AI 分析的交互单元。
如果日常工作主要是写代码、跑测试、处理构建失败、调试部署脚本,Block 终端会比传统纯文本流更适合 AI 辅助开发。如果只是在服务器上执行几条管理命令,Bash 和 Zsh 仍然是最稳定、最通用的选择。