把 AI Agent 用在真实研发里,难点通常不在“会不会写一段很长的 Prompt”。
本地演示里,一个模型能读需求、写代码、改 Bug,看起来已经像一个自动程序员。但只要进入企业工程环境,问题会马上变复杂:接口需要鉴权,调用链很长,日志分散在不同系统里,任务可能跨天,代码改错了还会影响别人,单轮对话窗口也装不下完整上下文。
这时真正决定 Agent 能不能持续交付的,不是某一句提示词,而是一套把大模型约束在工程轨道里的控制面。
这套控制面就是 Harness Engineering。
Harness Engineering 解决的是什么问题
Harness 原意有“束具、约束、控制装置”的意思。放到 AI Agent 里,可以把它理解成:把大语言模型接入工程系统时,用来约束行为、管理状态、连接能力、验证结果的一整套外部机制。
大语言模型(Large Language Model,LLM)本质上是一个概率系统。同样的输入,它可能给出不同回答;同样的任务,它可能选择不同路径;如果上下文变长,它还可能遗忘前面的约束,甚至把局部完成误判成整体完成。
传统软件工程主要处理确定性问题。一个函数只要实现正确,输入 1 + 2,输出就应该稳定是 3。测试、日志、代码审查、类型检查,都是围绕“确定性程序”建立的防错机制。
AI Agent 不一样。它会规划,会调用工具,会读写文件,会根据日志继续修复。能力越强,行动空间越大,失控风险也越高。
所以 Harness Engineering 的核心问题是:
如何把一个聪明但非确定性的模型,接入一条必须可预测、可回滚、可验收的工程流水线?
可以用一张简单的结构图理解它的位置:
flowchart LR
Engineer[工程师] --> Goal[目标与边界]
Goal --> Spec[(Spec / Handoff<br/>外部真相源)]
Spec --> Agent[AI Agent<br/>规划与执行]
Agent --> Router[能力路由]
Router --> Tool[Tool / API / Script]
Tool --> Sandbox[沙盒执行]
Sandbox --> Eval[测试 / 日志 / Evaluator]
Eval --> Decision{是否通过}
Decision -- 通过 --> Sync[回写状态]
Decision -- 不通过 --> Fix[带证据修复]
Fix --> Agent
Sync --> Spec
在这个结构里,模型不是被完全放任的“自由执行者”,而是被放在一组工程控制点之间:它可以提出意图、选择路径、生成代码,但执行前要过边界检查,执行后要接受外部验证,任务结束还要把状态回写到可恢复的真相源里。
Harness 和普通工程规范有什么区别
很多做法看起来都像 Harness:写规范、加测试、看日志、做代码审查、限制权限。它们确实都是工程基础,但 Harness Engineering 不是这些实践的简单堆叠。
区别在于它管理的对象不同。
| 维度 | 传统软件工程 | Harness Engineering |
|---|---|---|
| 管理对象 | 人写出的确定性程序 | 会自主规划和行动的非确定性模型 |
| 主要风险 | 代码缺陷、误操作、遗漏测试 | 目标漂移、幻觉调用、上下文腐烂、错误自信 |
| 控制方式 | 编译、测试、审查、发布流程 | 真相源、Checkpoint、沙盒、Evaluator、Handoff |
| 关注重点 | 程序运行是否正确 | 模型是否在正确边界内持续推进 |
| 失败形态 | 某个函数或服务出错 | Agent 沿着错误目标越做越远 |
传统软件工程像是在给人类工程师防手滑;Harness Engineering 更像是在给一个高能力但缺少工程常识的执行者装方向盘、刹车、仪表盘和护栏。
用两个坐标轴划分 Agent 架构
判断一个 Agent 系统有没有进入 Harness Engineering,可以看两个问题。
执行流路由是谁决定的?
- 静态预设:代码写死流程,模型只是其中一个处理节点。
- 动态自主:模型可以决定下一步做什么、调哪个工具、如何修复。
状态和上下文放在哪里?
- 隐式内部:主要靠 Prompt 窗口维持记忆。
- 显式外部:由数据库、状态机、Spec、Handoff 等外部系统管理。
这两个坐标轴可以组成一个架构矩阵:
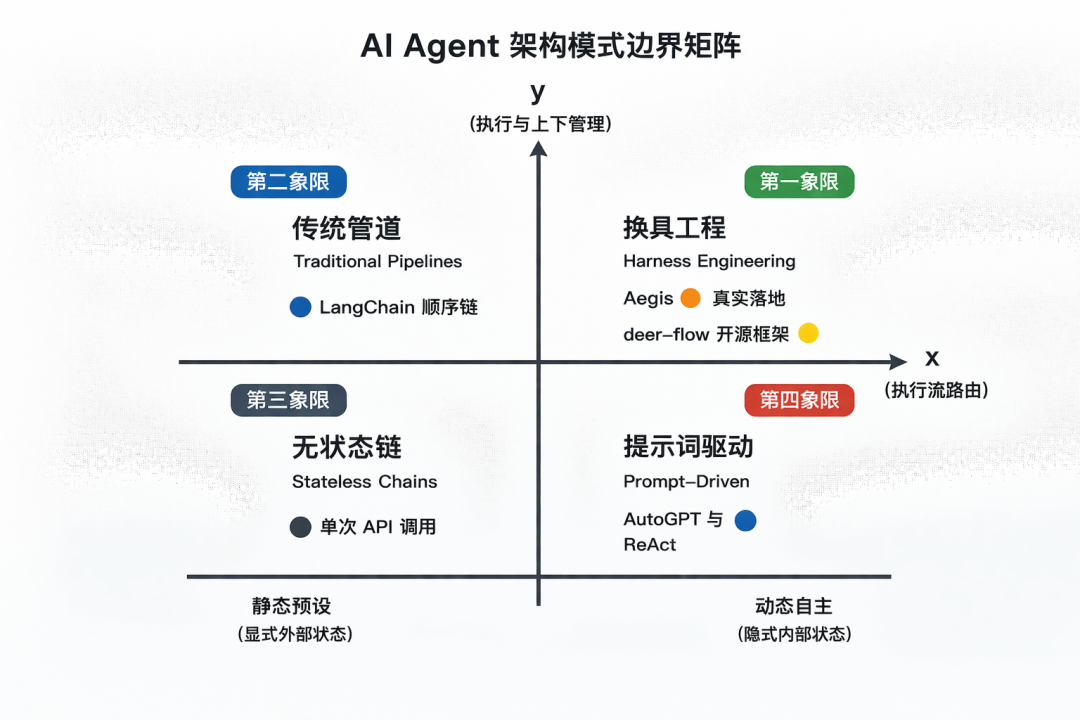
这张图的重点不是给四种模式排序,而是帮助判断场景适配度。不同象限适合不同任务。
| 象限 | 架构模式 | 特点 | 适合场景 | 主要风险 |
|---|---|---|---|---|
| 无状态链 | 单次 API 调用 | 把 LLM 当纯函数使用 | 翻译、分类、摘要、标签生成 | 没有长期任务能力 |
| 提示词驱动 | AutoGPT / ReAct 类模式 | 模型自主性高,状态堆在上下文里 | 探索性任务、短链路试错 | 长任务容易遗忘和偏航 |
| 传统管道 | LangChain 顺序链等 | 外部流程固定,模型被动处理 | 固定流程中的非结构化处理 | 灵活性有限 |
| Harness Engineering | 动态意图 + 外部控制面 | 模型负责意图,外部系统负责边界、状态和验证 | 企业研发、长任务、多工具协作 | 建设成本更高 |
Harness Engineering 通常位于“动态自主 + 显式外部状态”这个区域。模型可以行动,但不能靠单轮 Prompt 独自记住所有东西;模型可以调用能力,但能力目录、权限边界、验证逻辑都由外部系统托管。
常见的伪 Harness 和劣质 Harness
做 Agent 系统时,很容易把“提示词写得很细”误认为“已经有控制面”。但 Prompt 是模型内部指令,Harness 是模型外部约束,两者不是一回事。
伪 Harness:只有口头约束,没有物理边界
最典型的做法是写一段超长 Prompt:
你不能删除文件。
你不能调用危险接口。
你不能跳过测试。
你不能修改核心架构。
你必须遵守下面 50 条规则……
短任务里,这种方式可能有效;长链路里,它只是“口头提醒”。上下文变长后,模型可能遗忘;任务压力增大后,模型可能绕开;工具太多时,模型还可能误选危险能力。
另一种常见误区是把二十多个工具一次性暴露给 Agent,让它“自己判断该用哪个”。这不是能力增强,而是把选择空间变成了风险空间。没有能力目录、权限分层、调用前审批和调用后验证,工具越多,事故面越大。
劣质 Harness:有控制面,但控制方式粗暴
有些系统确实把模型放进了外部执行器,但控制逻辑非常粗糙。
| 陷阱 | 表现 | 问题 |
|---|---|---|
| 死循环重试 | 出错后把错误直接丢回模型,让它无限修 | 模型可能为了修小错破坏大结构 |
| 重型文档流 | 每次改代码前强制生成万字设计文档 | Token 浪费严重,文档很快过期 |
| 单点审批 | 所有动作都等人批准 | 安全但低效,Agent 变成手动工具 |
| 无差别工具开放 | 所有 API 都给模型自由调用 | 容易误调用、越权调用、重复调用 |
好的 Harness 不是把模型绑死,而是把风险高的环节卡住,把低风险的动作自动化,把验证证据接进闭环。
好的 Harness 应该包含哪些控制点
一个能进入生产研发的 Agent Harness,至少要有五类机制。
1. 最小真相源:Spec is Truth
长任务不能只存在于聊天窗口里。任务目标、阶段边界、已完成项、未完成项、关键决策和验证结论,都要写进外部文件或状态存储。
常见形式包括:
/specs
project-goal.md
current-stage.md
constraints.md
decisions.md
open-issues.md
/handoff
2026-03-07-task-handoff.md
Spec 不需要写成厚重文档。它的价值在于“足够恢复上下文”。当任务跨天、会话中断、模型上下文被清空时,新的会话能从这份真相源恢复,而不是靠模型猜测之前发生了什么。
2. 执行前 Checkpoint
高风险动作不能让模型直接执行。改核心代码、删文件、调用生产接口、调整架构之前,模型要先复述:
- 当前理解是什么;
- 本轮核心目标是什么;
- 准备做哪几个动作;
- 风险点在哪里;
- 怎么验证结果。
一个可直接使用的模板:
先别改代码。做一次 checkpoint:
1. 当前你对任务的理解是什么?
2. 本轮核心目标是什么?
3. 你准备执行哪 1 到 3 个动作?
4. 可能影响哪些文件、接口或数据?
5. 执行后用什么测试、日志或回包验证?
我确认后再执行。
Checkpoint 的意义不是增加仪式感,而是在模型动手前发现目标漂移。如果它连本轮目标都说不清,后面执行越快,偏差越大。
3. 能力路由:把 Prompt 拆进确定性管道
复杂业务不能靠一个巨型 Prompt 穷举所有分支。更稳的方式是把能力拆成小单元:
Capability = 专属 Prompt + 确定性脚本 + Validator
例如一个两阶段召回能力,可以写成明确的管道:
class Capability:
def __init__(self, name, prompt, runner, validator):
self.name = name
self.prompt = prompt
self.runner = runner
self.validator = validator
def execute(self, input_data):
prepared = self.prompt.render(input_data)
result = self.runner(prepared)
self.validator.check(result)
return result
模型只做轻量路由决策:
def route(task):
if task.requires_recall and task.context_size > task.model_window_limit:
return "two_stage_recall_pipeline"
if task.is_simple_classification:
return "direct_llm_pipeline"
return "human_checkpoint"
这样做的好处是,模型不需要在几千字 Prompt 里“猜”该走哪条路。它只需要判断任务类型,然后把数据送进已经验证过的确定性管道。
4. 沙盒和 Evaluator
模型生成的代码、脚本和命令,应该先在隔离环境里运行。沙盒可以是本地临时目录、Docker 容器,也可以是 Kubernetes(K8s,容器编排系统)中的隔离任务。
执行后不能只听模型说“修好了”,要引入外部证据:
- 单元测试结果;
- 集成测试结果;
- 日志片段;
- API(应用程序编程接口)回包;
- 页面或接口的实际现象;
- 独立 Evaluator Agent 的判断。
一个典型验证闭环如下:
sequenceDiagram
participant A as Agent
participant S as Sandbox
participant T as TestRunner
participant L as LogSystem
participant E as Evaluator
participant H as Human
A->>S: 提交代码变更
S->>T: 运行最小测试集
T-->>S: 返回测试结果
S->>L: 拉取关键日志
L-->>S: 返回日志片段
S->>E: 提交测试与日志证据
E-->>H: 给出是否通过及原因
H-->>A: 批准继续或要求修复
这里的关键是“证据在模型外部”。模型可以解释证据,但不能凭主观感觉宣布成功。
5. Handoff:任务中断也能接着做
Agent 做长任务时,最怕上下文腐烂。一天前为什么这么设计、哪个方案被否掉、当前只允许修哪条链路,如果没有外部记录,新会话很容易重新发明一遍,甚至推翻已经确认过的结论。
Handoff 需要记录四类信息:
# Handoff
## 当前总目标
构建一个可接入内部工程流程的 Agent 服务。
## 本阶段目标
只定位 chat 链路为什么在无文本输出时直接结束。
## 已完成
- 找到 SSE 链路入口。
- 复现 RUN_STARTED -> TEXT_MESSAGE_START/END -> RUN_FINISHED。
- 确认不是前端渲染问题。
## 未完成
- 判断后端流式响应为何提前收尾。
- 补充最小回归测试。
## 下一轮建议
先检查 chat handler 中空 chunk 的处理逻辑,不要扩大到权限和超时问题。
Handoff 写得越清楚,下一轮恢复成本越低。
企业环境里,Harness 为什么比 Prompt 更关键
本地 Demo 能掩盖很多问题。人工可以随时兜底,任务可以一次性塞进上下文,失败了也没有太大代价。
企业工程环境不一样。Agent 面对的是:
- 内部鉴权和权限边界;
- 多服务调用链;
- 不稳定接口;
- 超时、拦截、空响应等运行时问题;
- 需要多人接手的长期任务;
- 必须能回归验证的交付标准。
例如接入 Chat 服务后,Agent 可能遇到 SSE(Server-Sent Events,服务器发送事件)链路直接结束、接口返回 504 超时、403 拦截、本地测试进程异常退出。解决这些问题不能靠“把 Prompt 写得更礼貌”,而是要把问题转成可诊断的工程链路:
目标:只定位 chat 为什么直接结束,不扩大修复范围。
证据:
RUN_STARTED -> TEXT_MESSAGE_START/END -> RUN_FINISHED
要求:
1. 找出 SSE 链路入口。
2. 判断无文本输出时哪里触发收尾。
3. 不修改权限、超时和前端逻辑。
4. 给出最小复现和验证方式。
当问题被压缩成“本轮只定位一条链路”,Agent 才能在边界内推进。否则它很可能一边修接口,一边改架构,一边碰权限,最后留下更大的不确定性。
工程师角色会发生什么变化
当 Agent 能承担越来越多实现任务,工程师的价值不会消失,但工作重心会变化。
过去很多时间花在亲手实现每个函数、每个接口、每个脚本上。进入 Agent 协作模式后,更关键的动作变成:
- 定义目标;
- 切分阶段;
- 卡住边界;
- 设计验证;
- 观察日志;
- 判断风险;
- 在关键节点接管。
这不等于“把活甩给模型”。恰恰相反,能用好 Harness 的工程师必须保留很强的技术判断。只是这种判断不再体现在每一行代码都亲自写,而是体现在什么时候放权、什么时候收紧、什么时候暂停、什么时候要求证据。
尤其在这些时刻,工程师必须下潜:
| 信号 | 为什么要接管 |
|---|---|
| 架构主线被污染 | Agent 可能为了修局部问题改掉整体设计 |
| 阶段目标漂移 | 当前任务会被扩大成不可控的大任务 |
| 日志暴露系统性异常 | 需要重新定义排查路径 |
| 模型把阶段完成说成全局完成 | 交付状态会被误判 |
| 工具调用开始越界 | 可能触碰权限、数据或生产环境 |
安全放权的前提是先建好 Harness。没有控制面,放权就是裸奔;有了控制面,模型才可能成为研发链路里的执行协作者。
一个 Agent 项目如何被 Harness 化
以一个名为 Aegis 的 Agent 项目为例,它的演进过程可以拆成五个阶段。
阶段一:先收敛目标,不急着写代码
起手不应该是:
帮我把这个 Agent 后端写出来。
更稳的方式是:
先读架构设计文档,不要实现。
用你的话复述你理解的目标,并说明当前项目主线应该怎么收敛。
这一步是在检查模型有没有抓住总目标、阶段目标和边界。如果模型一上来就写代码,要立刻拉回到目标对齐。
阶段二:用 Spec 和 Handoff 对抗上下文腐烂
长任务经常跨越多轮会话。每一轮开始时,让模型先读外部真相源:
先阅读 spec / handoff 恢复任务。
告诉我现在做到哪里了,还剩什么,你建议从哪一段接着推进。
这样做能避免模型靠残缺记忆继续执行,也能让人类随时接手。
阶段三:把复杂 Prompt 拆成 Capability
当业务逻辑开始复杂,比如“先召回再喂模型”还是“一次性全量输入”,不要把所有分支都塞进 Prompt。更好的方式是沉淀成能力:
two_stage_recall_pipeline:
prompt: 判断召回目标与查询条件
script: pipeline_two_stage.py
validator: 检查召回数量、上下文长度、模型输入格式
Agent 执行前只负责选择管道,而不是在巨大提示词里临场推理所有细节。
阶段四:把运行时问题变成链路排查
接入真实环境后,问题会变成工程问题:
- Chat 接口静默退出;
- SSE 流没有文本输出;
- 接口
504; - 鉴权
403; - 本地测试进程直接结束。
这时目标要压得很小:
当前阶段目标改成:只定位 chat 为什么直接结束。
先做原因分析,不改代码,不扩展到权限和超时问题。
运行时证据会不断改变排查路线,Harness 的作用就是让每一轮目标都能根据证据重新收束。
阶段五:测试和回归前置化
测试不是收尾动作,而是执行轨道的一部分。Agent 改代码前要确认测试入口,改完后要跑最小测试集,并基于事实判断状态。
先确认测试入口和构建方式。
只跑与本轮目标相关的最小测试集,避免高开销动作。
完成后基于测试结果、日志和接口回包判断,不要主观宣布成功。
这样,一个大需求就被压缩成多个可验证、可回退、可交接的小闭环。
sdd-riper-one-light 在 Harness 中扮演什么角色
sdd-riper-one-light 是一个轻量的 SDD(Spec-Driven Development,规格驱动开发)协作骨架:
https://github.com/huisezhiyin/sdd-riper/tree/main/skills/sdd-riper-one-light
需要分清两层:
- Harness Engineering 是底层架构,提供沙盒、日志、能力路由、状态管理、审批和验证。
- SDD 是协作方法,把目标、规格、执行、验证、回写组织成稳定流程。
从工程角度看,sdd-riper-one-light 的核心是契约式设计(Design by Contract):把非确定性的模型夹在确定性的契约里。
| 契约类型 | 控制点 | 解决的问题 |
|---|---|---|
| 前置条件 | Checkpoint、Restate First、Approval | 防止模型没对齐目标就执行 |
| 后置条件 | 测试、日志、回包、Reverse Sync | 防止模型主观宣布成功 |
| 不变式 | Spec is Truth、Handoff | 防止跨会话状态腐烂 |
它不是让模型变“更聪明”,而是让模型的每一步都可检查、可恢复、可追责。
从 0 到 1 落地 Agent Harness
团队内部要落地 Agent,不建议一开始追求“全自治”。更稳的路径是逐步放权。
| 步骤 | 要做什么 | 产物 |
|---|---|---|
| 搭真相源 | 建立 Spec、Handoff、决策记录 | 可恢复的任务状态 |
| 约束执行边界 | 引入 Checkpoint 和 Approval | 高风险动作可控 |
| 建能力目录 | 明确可用 Tool、API、脚本和权限 | 减少幻觉调用 |
| 接验证闭环 | 接入测试、日志、回包检查 | 用证据判断结果 |
| 做沙盒隔离 | 在隔离环境里运行代码和命令 | 降低破坏风险 |
| 建恢复机制 | 中断后能从 Handoff 继续 | 长任务可持续 |
| 逐步放权 | 低风险动作自动,高风险动作审批 | 自动化和安全之间可调 |
一个最小可用 Harness 可以先从文件系统开始,不一定马上做复杂平台:
agent-workspace/
specs/
goal.md
current-stage.md
constraints.md
handoff/
latest.md
capabilities/
two_stage_recall.md
code_fix.md
scripts/
run_tests.sh
collect_logs.sh
sandbox/
docker-compose.yml
先把“目标、边界、能力、验证、交接”跑通,再考虑自动化程度。
8 阶段 SOP:每一轮都要拿到中间产物
Agent 协作最怕一路黑盒干到底。更稳的节奏是:每一阶段只给一个带边界的输入,模型必须先交付中间产物,人类或外部验证器确认后再进入下一步。
| 阶段 | 给模型的输入 | 要求模型先返回 | 控制动作 |
|---|---|---|---|
| 目标收敛 | 先读文档,不准写代码 | 需求复述、主线判断、疑问边界 | 纠偏后放行 |
| 状态恢复 | 先读 Spec / Handoff | 已完成项、未完成项、接续建议 | 用外部真相源恢复 |
| 上下文装配 | 不整包投喂,只给索引 | 最小上下文清单 | 按需补充 |
| 任务分块 | 本轮只做一个小段 | 1 到 3 个动作、风险、验证方式 | 只批准当前轮次 |
| 链路设计 | 先判断走什么模式 | 执行模式和装配方案 | 先定路线 |
| 执行前校准 | 先 Checkpoint | 当前理解、下一步、风险、验证方案 | 对齐后 Approval |
| 外部验证 | 不接受主观判断 | 测试、日志、回包事实 | 用证据决策 |
| 回写交接 | 暂停前必须回写 | 完成项、偏差、残留问题、下一步 | 留下干净恢复点 |
这张表的重点不是把流程变复杂,而是让每一步都有可检查的中间状态。
长任务里要盯住三层目标
Agent 长任务偏航,通常不是一开始就错,而是做着做着把目标混了。
需要同时维护三层目标:
| 目标层级 | 作用 | 示例 |
|---|---|---|
| 总核心目标 | 指明最终方向 | 构建可接入工程流程的 Agent 服务 |
| 阶段性核心目标 | 收束当前几轮任务 | 只定位 chat 链路直接结束的问题 |
| 本轮动作目标 | 限制当前一次执行 | 查 SSE handler,不改权限和超时逻辑 |
一个重要判断是:阶段完成不等于全局完成。
模型可能会说“问题已经解决”,但它实际只完成了本轮最小收敛。例如它定位了 Chat 空响应原因,并补了一个测试,这只能说明当前阶段有进展,不能说明所有流式链路问题都已经治理完。
4 个偏航信号
出现这些信号时,要暂停执行,重新设门禁。
| 偏航信号 | 处理方式 |
|---|---|
| 绕过阶段目标,直接谈总目标 | 要求它只复述本轮阶段目标 |
| 跳过中间产物,直接改代码 | 卡 Checkpoint |
| 用“应该好了”替代测试和日志 | 要求基于证据回答 |
| 混淆阶段完成和全局完成 | 要求明确已完成、未完成、下一轮目标 |
偏航时,不要试图用“你认真一点”解决。更有效的做法是重新压目标、重新要求证据、重新限制动作范围。
可直接使用的提示模板
这些句式适合放进日常 Agent 协作流程中。
起手收敛
先读架构设计文档,不要实现。
先用你的话复述你理解的目标,并告诉我你认为当前项目主线应该怎么收敛。
压最小 Spec
先把这轮任务压成最小 spec,写清目标、范围、约束、暂不处理项。
没有我的批准,不要进入实现。
恢复任务
先读这份 spec / handoff 恢复任务。
告诉我现在做到哪里了、还剩什么、你建议从哪一段接着推进。
执行前 Checkpoint
先别改代码。做一次 checkpoint:
总结当前理解、核心目标、下一步动作、风险和验证方式。
我确认后你再执行。
发现偏航时
先停,不要继续展开。
你先复述这轮阶段性核心目标,不要谈总目标。
基于证据验证
不要主观判断是否完成。
去看测试、日志、接口回包和现场现象,基于事实再回答。
阶段验收
不要把这次最小收敛和全局完成混为一谈。
明确告诉我:这轮完成了什么,还没完成什么,下一轮最小目标是什么。
收尾回写
任务暂停。
把这一轮实际做了什么、验证了什么、还剩哪些问题没做,全部回写到 spec / handoff,
保证下一轮能直接接着干。
公开工程实践中的共同方向
从公开资料看,多个团队在长任务 Agent 上都走向了类似思路:减少对巨型 Prompt 的依赖,把状态、验证和执行环境外置。
| 实践 | 关键做法 | 对 Harness 的启发 |
|---|---|---|
| OpenAI Codex 相关工程实践 | 把代码仓库和 docs/ 结构化文档作为记录系统 | 上下文是稀缺资源,真相源要外置 |
| Anthropic 长时应用开发框架 | Context Reset、结构化交接、独立 Evaluator | 长任务需要强制重置和外部验证 |
| deer-flow | Docker / K8s 沙盒、SKILL.md 能力边界、LangGraph 状态机 | 模型大脑和执行环境要物理隔离 |
它们的共同点很清楚:想让模型承担更长、更真实的任务,不能只继续加 Prompt,而要搭建约束、状态、沙盒和验证轨道。
关键结论
AI Agent 进入生产研发后,核心命题不是“模型能不能写代码”,而是“模型能不能在明确边界内持续交付”。
Harness Engineering 提供的就是这套边界:
- 用 Spec 和 Handoff 管住长期状态;
- 用 Checkpoint 和 Approval 管住执行前风险;
- 用 Capability 管住工具和业务能力;
- 用 Sandbox 和 Evaluator 管住运行后验证;
- 用回写机制保证任务可恢复、可交接。
当执行权交给非确定性模型,工程师不能只做旁观者。更合理的角色是控盘者:定义目标、拆分阶段、审查证据、处理偏航,并在关键节点接管方向盘。
AI Agent 的生产力不是从“更长的 Prompt”里释放出来的,而是从“更稳的 Harness”里释放出来的。
延伸阅读
-
OpenAI Engineering:Harness Engineering
https://openai.com/zh-Hans-CN/index/harness-engineering/ -
Anthropic:Harness design for long-running application development
https://www.anthropic.com/engineering/harness-design-long-running-apps -
bytedance/deer-flow:An open-source long-horizon SuperAgent harness
https://github.com/bytedance/deer-flow