Claude Code 是 Anthropic 做的命令行编程 Agent。它不是简单地把大模型接到一个终端输入框上,而是把模型、工具系统、权限控制、上下文管理、插件扩展、多 Agent 协作和终端 UI 组合成了一个完整的工程系统。
npm(Node.js 包管理与分发生态)包曾经携带过 Source Map。Source Map 的作用是把打包、压缩、混淆后的 JavaScript 文件映射回更接近开发阶段的源文件,方便调试。对一个打包后的 CLI(Command Line Interface,命令行界面)工具来说,如果发布产物里留下了完整 Source Map,就可能暴露大量 TypeScript 源码结构。
从工程视角看,真正有学习价值的不是“源码在哪里”,而是一个生产级 AI Agent 到底怎么组织:
- 模型流式返回时,工具要不要立刻执行?
- 多个工具调用同时出现时,哪些能并发,哪些必须排队?
- 自动执行命令时,权限应该怎么判断?
- 上下文窗口越来越满时,哪些信息保留,哪些信息压缩?
- MCP(Model Context Protocol,模型上下文协议)工具很多时,怎么避免 prompt 被工具 schema 撑爆?
- 多 Agent 协作一定要多进程吗?
这些问题没有一个能靠“调一次 API(Application Programming Interface,应用程序编程接口)”解决。Claude Code 的架构可以拆成几个核心模块来看。
整体架构:一个带权限系统的流式工具执行循环
Claude Code 用 TypeScript 编写,运行在 Node.js 上。终端 UI(User Interface,用户界面)基于 React + Ink,Ink 可以把 React 组件渲染到命令行里,所以 Claude Code 的交互界面并不是传统的纯字符串拼接,而是一个真正的组件化 TUI(Text-based User Interface,文本用户界面)。
核心目录可以按职责分成几组:
| 目录 | 主要职责 |
|---|---|
entrypoints/ | 程序入口、启动初始化 |
query/ | Agent 主循环、模型请求、工具调用调度 |
tools/ | 文件读写、搜索、命令执行、MCP 工具等工具实现 |
commands/ | 斜杠命令,例如 /help、/loop |
services/ | API 调用、MCP 连接、分析、远程配置等业务逻辑 |
components/ / hooks/ | React/Ink 终端 UI 层 |
state/ | 应用状态管理 |
utils/swarm/ | 多 Agent 协作 |
skills/ | Skill 扩展系统 |
工具系统是整个 Agent 的骨架。模型负责推理和生成工具调用,工具负责接触真实世界,例如读文件、改代码、执行 shell 命令、访问 MCP 服务。
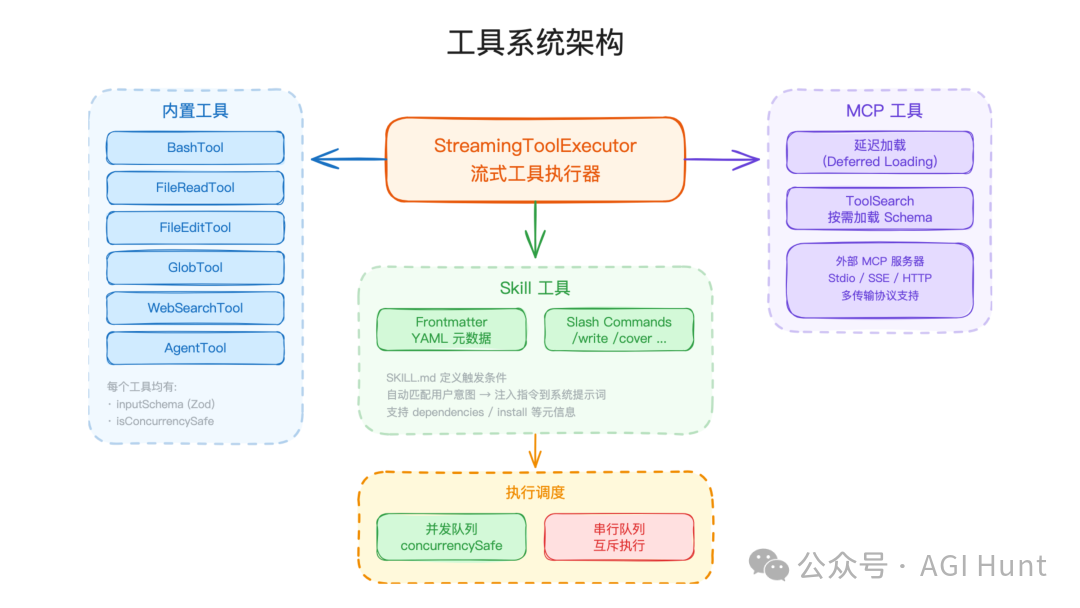
图里的关键关系是:入口初始化运行环境,query 模块驱动 Agent 循环,模型输出被转换成工具调用,工具调用再进入权限和调度系统。UI 层只负责展示交互状态,不直接决定工具是否执行;真正的执行权在工具系统和权限管道里。
可以把它抽象成一句话:
Claude Code 是一个运行在终端里的、带权限系统的、支持流式工具执行的 AI Agent 运行时。
这句话里有三个关键词:流式、工具、权限。后面的设计几乎都围绕这三点展开。
启动流程:信任边界之前只做安全初始化
一个 CLI Agent 启动时容易犯两个错误:要么启动阶段加载太多东西,导致首屏慢;要么在用户确认信任之前就读取项目、连接服务、启动语言服务器,扩大安全风险。
Claude Code 把启动拆成多个阶段,并在中间放了一条“信任边界”。
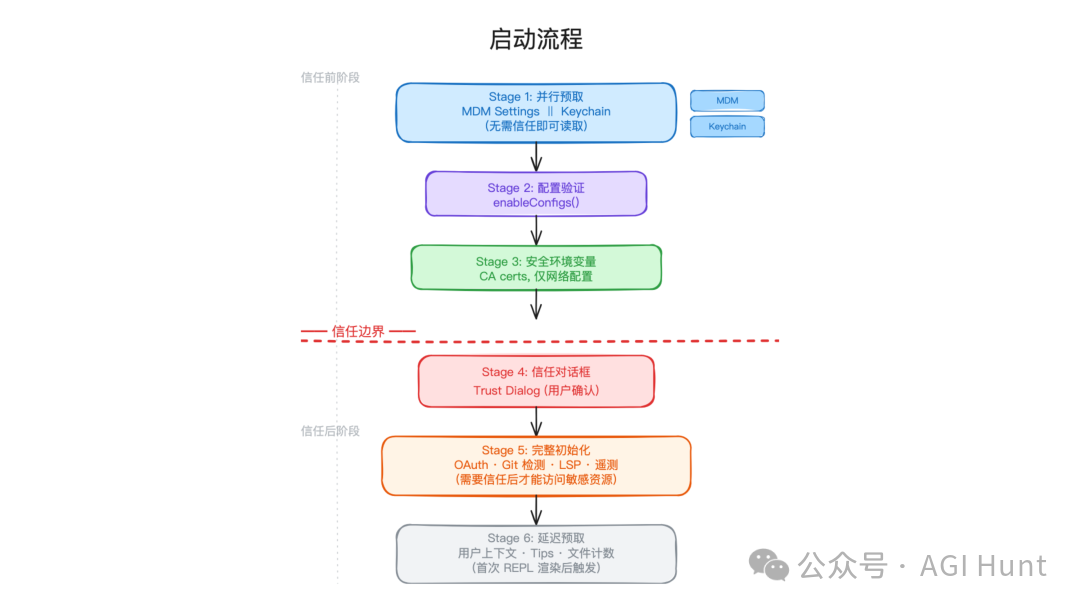
启动流程可以按阶段理解:
| 阶段 | 做什么 | 设计目的 |
|---|---|---|
| Stage 1 | 并行预取 MDM 配置和 Keychain 信息 | 能并行的尽早开始,减少等待 |
| Stage 2 | 校验 settings.json、CLAUDE.md 等配置 | 配置错误尽早失败,不进入复杂 UI |
| Stage 3 | 只应用 CA 证书和网络相关环境变量 | 在第一次 TLS 握手前准备证书环境 |
| 信任边界 | 用户确认当前项目是否可信 | 把安全敏感操作放到确认之后 |
| Stage 4 | 展示信任对话框 | 明确用户授权点 |
| Stage 5 | 初始化 OAuth、Git、LSP、遥测等模块 | 信任确认后再接触项目和外部服务 |
| Stage 6 | 延迟加载用户上下文、文件统计、提示信息 | 首屏出来后再做非关键工作 |
几个缩写需要先讲清楚:
- MDM(Mobile Device Management,移动设备管理)常用于企业策略下发。
- Keychain 是 macOS 的密钥存储服务。
- CA(Certificate Authority,证书颁发机构)用于证书链校验。
- TLS(Transport Layer Security,传输层安全协议)是 HTTPS 等安全连接的基础。
- OAuth(开放授权)用于用户授权登录。
- LSP(Language Server Protocol,语言服务器协议)用于编辑器和语言服务交互。
这里的思路很清晰:
- 配置校验要早,失败要快。
- 网络证书类环境要早,因为运行时可能在第一次 TLS 请求时缓存证书状态。
- Git 仓库扫描、LSP 启动、遥测等操作要放在信任确认之后。
- 远程配置、上下文统计这类不影响首屏的任务要延迟。
用流程图表示就是:
flowchart TD
A[启动 CLI] --> B[并行读取企业配置与密钥]
B --> C[校验本地配置]
C --> D[应用安全网络环境变量]
D --> E{项目是否已信任}
E -- 否 --> F[展示信任确认]
F --> G[完整初始化]
E -- 是 --> G
G --> H[渲染 REPL 首屏]
H --> I[延迟加载上下文与提示信息]
REPL(Read-Eval-Print Loop,读取-求值-输出循环)在这里指命令行交互主界面。启动优化不是简单地“少做事”,而是把任务按安全性和首屏必要性重新排序。
Agent 主循环:模型边返回,工具边执行
Claude Code 的 Agent 循环主要由 query.ts 和 QueryEngine 驱动。Agent 的职责不是只调用一次模型,而是在“用户输入—模型响应—工具执行—结果回填—继续推理”之间反复循环。
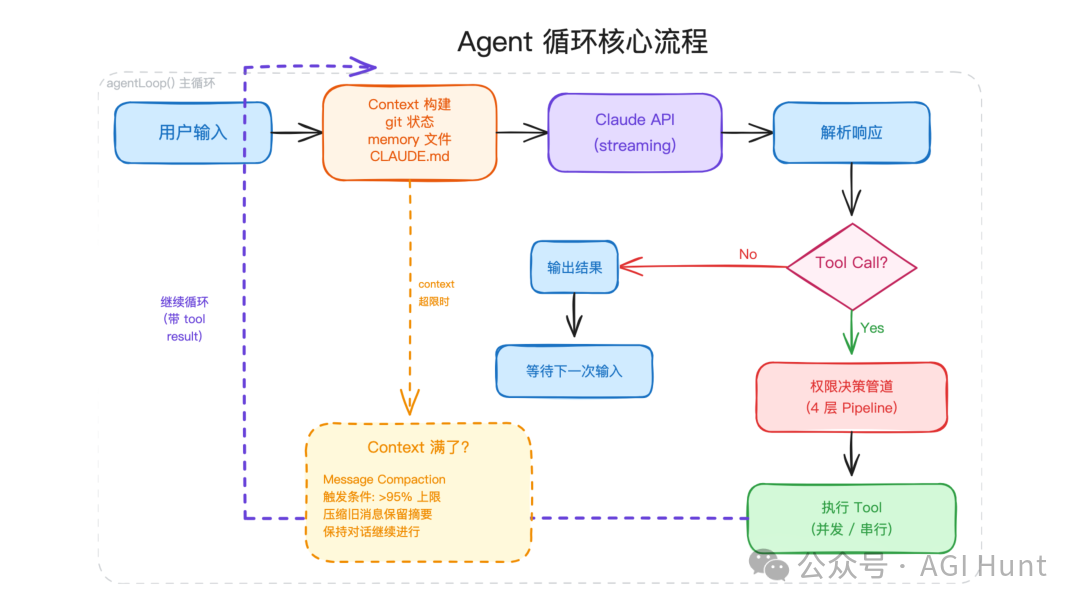
图中的流程可以拆成四步:
-
准备请求上下文
把用户消息、系统提示、项目上下文、历史消息、Git 状态、Memory 信息、可用工具等内容组合成请求。 -
调用 Claude API 并开启流式响应
模型不是一次性返回完整结果,而是通过流式事件不断吐出文本块、工具调用块等内容。 -
工具调用到达后立即执行
如果流里出现一个完整的工具调用,执行器会尽快启动对应工具,而不是等模型整段消息结束。 -
根据停止原因决定是否继续
如果模型还需要工具结果,就把结果写回消息列表,再跑下一轮;如果模型已经完成回答,循环结束。
核心结构可以写成伪代码:
type QueryEngineOptions = {
maxTurns?: number; // 最大循环轮次,防止 Agent 无限自我循环
maxBudgetUsd?: number; // 费用上限,防止长任务失控
};
async function runAgentLoop(input: UserMessage, options: QueryEngineOptions) {
const messages = buildInitialMessages(input);
for (let turn = 0; turn < options.maxTurns; turn++) {
const stream = callClaudeApi({
messages,
tools: getVisibleTools(),
});
const toolResults = await consumeStreamAndRunTools(stream);
messages.push(...toolResults);
if (stream.stopReason === "end_turn") {
return buildFinalAnswer(messages);
}
if (isBudgetExceeded(options.maxBudgetUsd)) {
throw new Error("Budget exceeded");
}
}
throw new Error("Max turns exceeded");
}
这里最重要的不是循环本身,而是流式工具执行。传统做法通常是等模型完整返回,再解析里面有哪些工具调用,然后执行。Claude Code 更激进:工具调用块一旦完整,就进入执行队列。
这样做能减少端到端延迟。比如模型先决定读取 package.json,后面还在生成别的内容时,文件读取已经开始了。等模型需要下一个推理步骤时,工具结果可能已经准备好。
流式工具执行:并发安全由工具自己声明
Agent 经常会一次触发多个工具调用。假设模型同时要做三件事:
- 读
package.json - 搜索
src/**/*.ts - 修改
src/index.ts
读文件和搜索通常可以并发执行,但写文件不能随便和其他修改操作并发,否则可能产生文件冲突。Claude Code 用 StreamingToolExecutor 做调度,并要求每个工具声明自己是否并发安全。
工具接口可以抽象成这样:
type Tool<Input, Output> = {
name: string;
inputSchema: ZodSchema<Input>;
// 根据输入判断本次调用是否能并发执行
isConcurrencySafe(input: Input): boolean;
validateInput(
input: unknown,
context: ToolContext
): ValidationResult<Input>;
call(
input: Input,
context: ToolContext
): Promise<{ data: Output }>;
isEnabled(context: ToolContext): boolean;
};
这里有一个细节:并发安全不是工具的固定属性,而是可以根据输入动态判断。例如同一个文件编辑工具,修改不同文件时也许可以并行,修改同一个文件就必须串行。把判断权交给工具,比框架写死规则更灵活。
调度逻辑可以画成这样:
flowchart LR
A[流式工具调用到达] --> B{是否通过输入校验}
B -- 否 --> E[返回校验错误]
B -- 是 --> C{是否并发安全}
C -- 是 --> D[进入并发执行池]
C -- 否 --> F[进入串行队列]
D --> G[收集工具结果]
F --> G
G --> H[写回 Agent 消息]
这种设计同时解决两个问题:
| 问题 | 解决方式 |
|---|---|
| 全部串行太慢 | 只读工具进入并发池 |
| 全部并发容易冲突 | 写文件、执行 Bash 等状态变更操作进入串行队列 |
每个工具调用还会绑定独立的 AbortController。用户按 Esc 取消时,正在运行的子进程或异步任务可以被精确终止,而不是粗暴杀掉整个 CLI 进程。
权限系统:权限是管道,不是一个开关
AI 编程 Agent 最大的风险来自工具执行,尤其是 Bash 命令、文件写入、Git 操作、部署命令。一个成熟的权限系统不能只有“允许”和“拒绝”两个按钮,它需要多层决策。
Claude Code 支持多种权限模式:
| 模式 | 行为 | 适合场景 |
|---|---|---|
default | 每次敏感操作都询问 | 交互式开发 |
bypassPermissions | 默认放行 | CI(Continuous Integration,持续集成)或受控自动化环境 |
dontAsk | 默认拒绝 | 高限制环境 |
acceptEdits | 自动接受编辑类操作 | 只希望自动改文件,不希望自动执行命令 |
auto | 分类器自动判断 | 需要减少打扰,同时保留安全边界 |
auto 模式最有参考价值。它不是一次判断完成,而是四层递进。
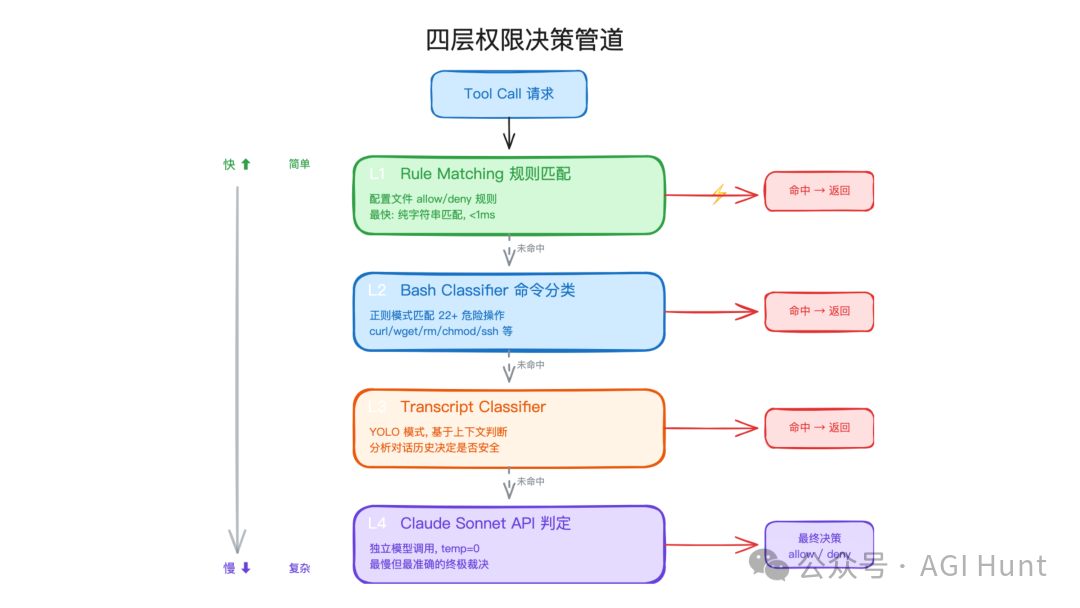
图里的四层可以理解成从快到慢、从确定规则到模型判断的管道:
| 层级 | 判断方式 | 特点 |
|---|---|---|
| 规则匹配 | 用户配置的 allow/deny 字符串规则 | 极快,适合明确命中 |
| Bash 分类器 | 对 shell 命令做模式识别 | 能拦截 rm -rf、force push、生产部署等高风险命令 |
| Transcript 分类器 | 基于整段对话上下文判断 | 能识别单条命令看不出的风险 |
| 独立模型分类 | 调用独立 Claude Sonnet 做安全分类 | 最慢,但能处理复杂边界情况 |
权限管道的价值在于“快路径”和“慢路径”分离。常见明确场景在前两层解决,少数复杂场景才进入上下文分类或模型分类。这样既不会每次都调用模型增加延迟,也不会把所有命令都交给正则表达式硬判。
一个权限请求可以抽象成:
async function decidePermission(request: ToolRequest): Promise<PermissionResult> {
const ruleResult = matchUserRules(request);
if (ruleResult.isFinal) return ruleResult;
if (request.tool === "Bash") {
const bashResult = classifyBashCommand(request.input.command);
if (bashResult.isFinal) return bashResult;
}
const transcriptResult = classifyWithConversationContext(request);
if (transcriptResult.isFinal) return transcriptResult;
return classifyWithDedicatedModel({
request,
temperature: 0,
});
}
温度设为 0 的独立模型调用用于降低输出随机性。安全分类需要稳定结果,而不是创造性回答。
上下文管理:固定大小窗口里的信息取舍
Agent 的上下文窗口可以理解成一个容量固定的背包。背包里要放系统提示、用户消息、历史对话、工具结果、项目说明、Memory、Git 状态、MCP 指令、工具 schema。装得太少,模型不知道项目背景;装得太多,费用上升,还可能超过上下文限制。
Claude Code 的上下文由多个来源拼装。
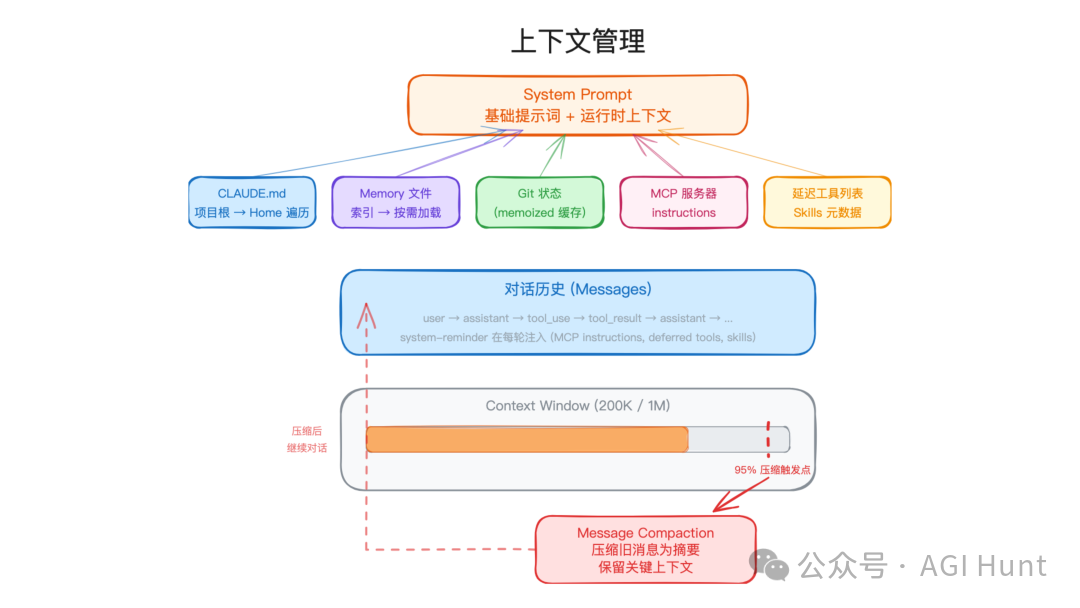
图里的设计重点是:不同信息使用不同加载策略。
| 上下文来源 | 加载策略 | 原因 |
|---|---|---|
CLAUDE.md / .claude.md | 从项目目录向上收集 | 支持项目、目录、用户级说明 |
MEMORY.md | 索引常驻,topic 按需加载 | 避免把全部记忆塞进 prompt |
| Git 状态 | memoized 缓存 | 避免重复执行 Git 命令 |
| MCP 服务器 instructions | 增量注入 | 连接变化时只通知变化部分 |
| 工具列表 | 名字先可见,schema 按需加载 | 减少 token 消耗 |
| 历史消息 | 接近上限时压缩 | 支持长会话 |
Memory 系统可以分成索引和正文两层。索引文件限制行数和大小,只记录有哪些 topic;真正的 topic 文件在需要时才加载。Memory 类型大致包括:
user:用户偏好和画像。feedback:历史交互反馈。project:项目背景。reference:外部资源指针。
当 token 使用量接近上下文窗口上限时,会触发 Message Compaction,也就是消息压缩。早期工具调用和结果会被压缩成摘要消息,保留关键事实,删除冗余细节。压缩过的内容后续还可以再次压缩。
flowchart TD
A[历史消息持续增长] --> B{是否接近上下文上限}
B -- 否 --> C[继续正常对话]
B -- 是 --> D[选择早期消息与工具结果]
D --> E[生成摘要消息]
E --> F[替换原始长消息]
F --> G[继续 Agent 循环]
还有一个容易忽略的优化:默认输出 token 上限不需要一开始就开到很大。很多请求的 p99(第 99 百分位)输出长度并没有那么夸张,所以默认可以给较小的 max output tokens。如果不够,再 retry 并提高上限。这样可以减少模型服务端的计算资源预留。
渐进式工具披露:工具很多时,先给名字,不给完整 schema
Agent 工具越多,prompt 越容易膨胀。尤其接入多个 MCP 服务器后,上百个工具的 JSON Schema(JavaScript Object Notation Schema,JSON 结构定义)可能占掉大量上下文窗口。
Claude Code 用“渐进式披露”解决这个问题。
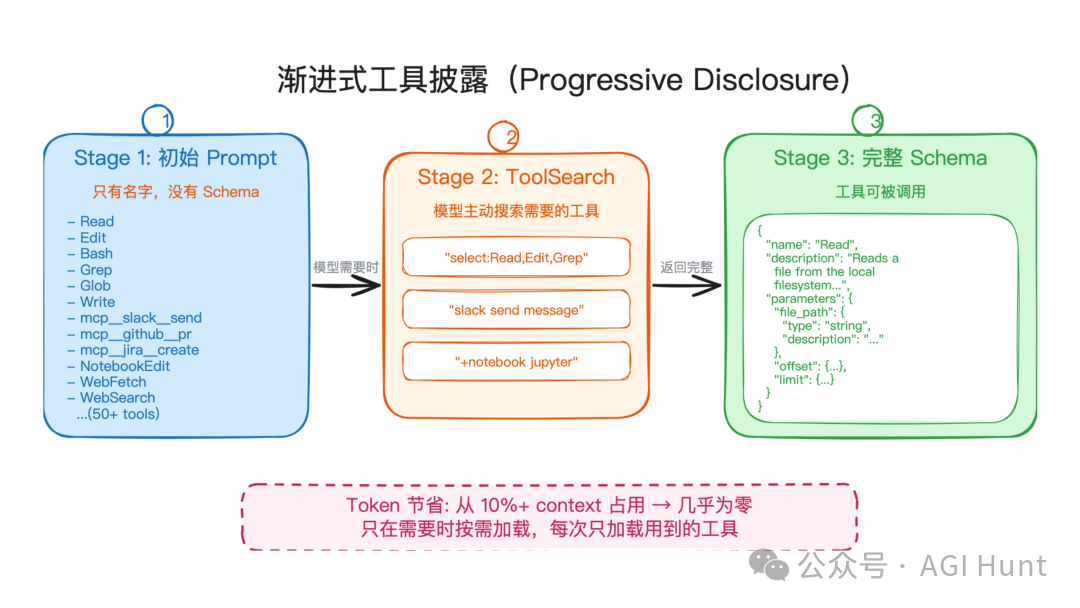
工具来源分成三类:
| 工具来源 | 加载方式 |
|---|---|
| 内置工具 | 核心工具直接加载,部分工具只披露名称 |
| MCP 工具 | 默认延迟加载 |
| Skill 工具 | 只加载 frontmatter,完整内容调用时再读 |
模型一开始只知道有一些工具名字和简短描述。如果需要完整定义,就调用 ToolSearch 获取工具 schema。查询方式可以支持精确选择、关键词搜索和排序:
select:Read,Edit,Grep
notebook jupyter
+slack send
含义分别是:
| 查询 | 含义 |
|---|---|
select:Read,Edit,Grep | 按工具名精确取回 |
notebook jupyter | 用关键词搜索并排序 |
+slack send | 必须包含 slack,再按 send 排序 |
这套机制的收益很直接:工具数量从几十个增长到几百个时,prompt 不会线性膨胀。模型只在需要调用某个工具时才拿完整 schema。
Skill 系统:Markdown 变成可调用能力
Skill 是 Claude Code 的扩展机制,本质上是带 frontmatter 的 Markdown 文件。frontmatter 是 Markdown 文件开头用 YAML 写的元数据区域,用来描述 Skill 的名字、用途、触发条件、允许使用的工具等信息。
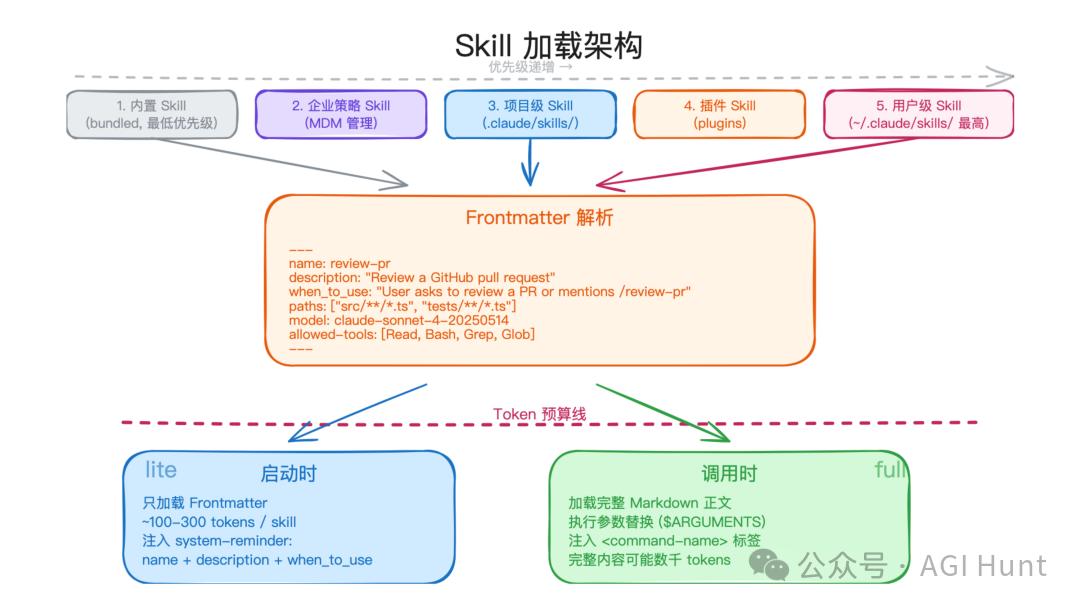
Skill 可以来自多个层级,加载时存在优先级:
- 内置 Skill。
- 企业策略下发的 Skill。
- 项目级 Skill,例如
.claude/skills/。 - 插件提供的 Skill。
- 用户级 Skill,例如
~/.claude/skills/。
一个 Skill 的配置可以长这样:
---
name: database-migration-helper
description: Help inspect and edit database migration files
when_to_use: Use when changing schema migration scripts
arguments:
- migration_name
allowed-tools:
- Bash
- Read
- Edit
model: sonnet
user-invocable: true
context: inline
effort: medium
paths: "migrations/**"
hooks:
PreToolUse:
- check-migration-safety
---
其中 paths 很关键。假设某个 Skill 只适合数据库迁移文件,那么配置 paths: "migrations/**" 后,只有当用户编辑迁移目录里的文件时,它才出现在候选能力里。
参数替换也很实用:
| 写法 | 含义 |
|---|---|
$ARGUMENTS | 全部参数 |
$0 | 第一个参数 |
$filename | 命名参数 |
Skill 系统的核心不是“多一种命令格式”,而是让 Agent 能按场景加载能力。frontmatter 只需要几百 tokens,完整说明在真正调用时再进入上下文,因此可以注册很多 Skill 而不立即撑爆 prompt。
MCP 集成:外部工具的一等入口
MCP 是 Claude Code 连接外部工具和数据源的重要机制。它可以把本地服务、远程服务、企业内部系统暴露成 Agent 可调用工具。
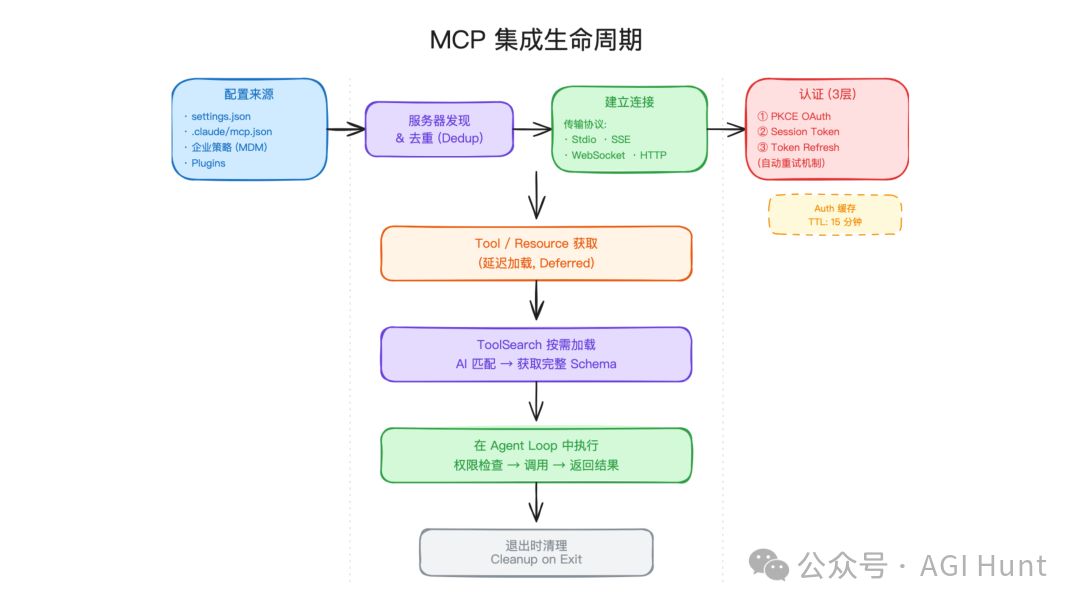
MCP 集成要解决五类问题:
| 问题 | 设计 |
|---|---|
| 配置从哪里来 | 全局配置、项目配置、企业策略、插件市场 |
| 怎么连接 | Stdio、SSE、WebSocket、HTTP |
| 怎么认证 | PKCE OAuth、Session Token、Token Refresh |
| 工具怎么进入 prompt | 先拿列表,schema 按需加载 |
| 服务器变化怎么通知模型 | 用 system reminder 增量通知 |
几个协议和认证名词需要拆开看:
- Stdio 是标准输入输出,适合本地子进程 MCP 服务。
- SSE(Server-Sent Events,服务器发送事件)适合服务端向客户端持续推送事件。
- WebSocket 是双向长连接协议。
- HTTP(HyperText Transfer Protocol,超文本传输协议)可以用于可流式传输。
- PKCE(Proof Key for Code Exchange,授权码交换证明密钥)是 OAuth 的安全增强机制。
- Session Token 用于维持会话。
- Token Refresh 用于访问令牌过期后的刷新。
MCP 工具默认延迟加载很重要。连接建立后,系统可以知道服务器有哪些工具,但不会把所有 schema 全部塞进 prompt。模型需要用某个工具时,再通过 ToolSearch 获取完整定义。
多个 MCP 服务器同时认证失败时,还要处理竞态。例如多个连接同时返回 401,认证缓存如果并发读写,很容易出现重复弹窗或 token 覆盖。序列化写入链可以保证认证状态按顺序更新。
多 Agent 协作:上下文隔离比物理隔离更关键
Claude Code 的多 Agent 系统叫 Swarm。它支持三种后端:
| 后端 | 运行方式 | 适合场景 |
|---|---|---|
| InProcess | 同一个 Node.js 进程内运行 | 默认模式,开销低 |
| Tmux | 使用 tmux pane | 需要可见终端隔离 |
| iTerm2 | 使用 iTerm2 tab | macOS 图形终端协作 |
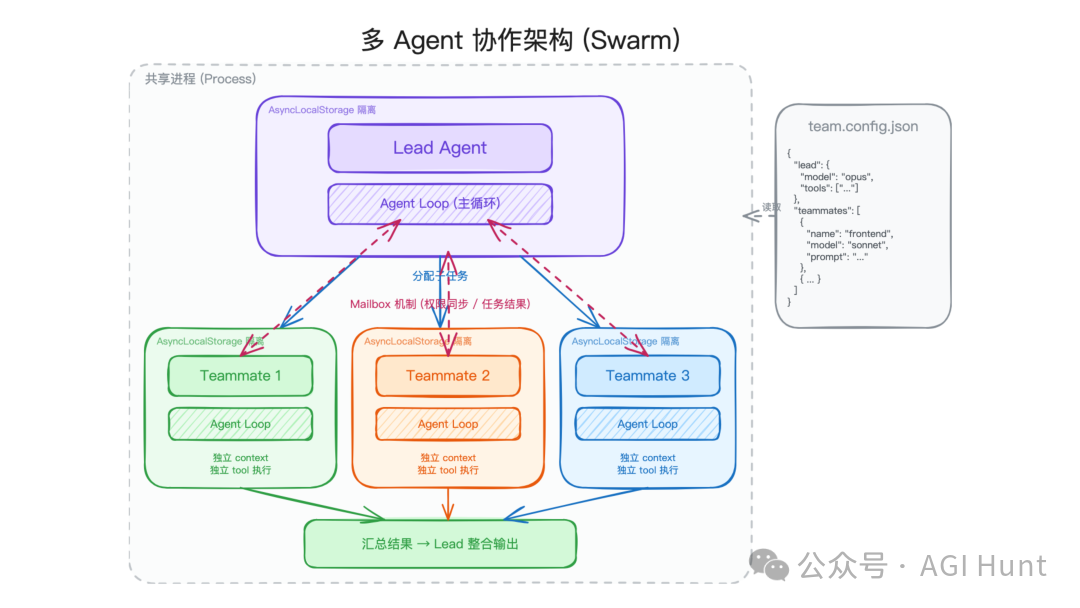
InProcess 模式最有意思。它没有为每个 Agent 启动独立进程,而是用 Node.js 的 AsyncLocalStorage 做上下文隔离。
runWithTeammateContext(
{
agentId,
teamName,
role: "member",
},
async () => {
// 这里读取到的是当前 teammate 的上下文
const sessionId = getSessionId();
const permissions = getPermissionContext();
await runAgentTask({ sessionId, permissions });
}
);
AsyncLocalStorage 可以在同一个进程的异步调用链里保存独立上下文。这样多个 Agent 共享进程和内存,但每个 Agent 看到自己的 session、权限、任务状态。
权限同步通过 mailbox 机制完成:
sequenceDiagram
participant Member as Member Agent
participant Mailbox as Mailbox
participant Lead as Lead Agent
participant UI as Terminal UI
Member->>Mailbox: 发起权限请求
Mailbox->>Lead: 通知 lead 审批
Lead->>UI: 展示 worker 权限请求
UI-->>Lead: 用户批准或拒绝
Lead->>Mailbox: 写入审批结果
Mailbox-->>Member: 返回权限结果
每个 Team 有一个 lead agent 和多个 member agent。lead 负责分配任务和审批权限,member 负责执行子任务。配置可以存放在类似 ~/.claude/teams/{team-name}/config.json 的位置。
这个设计的重点是:多 Agent 不一定等于多进程。很多场景只需要上下文隔离,不需要操作系统级隔离。同进程方案可以减少进程间通信成本,也更容易共享缓存和工具注册表。
/loop 与定时任务:把 Agent 变成周期性执行器
Claude Code 还有定时任务能力,/loop 可以周期性执行某个命令或自然语言任务,底层对应 CronCreateTool。
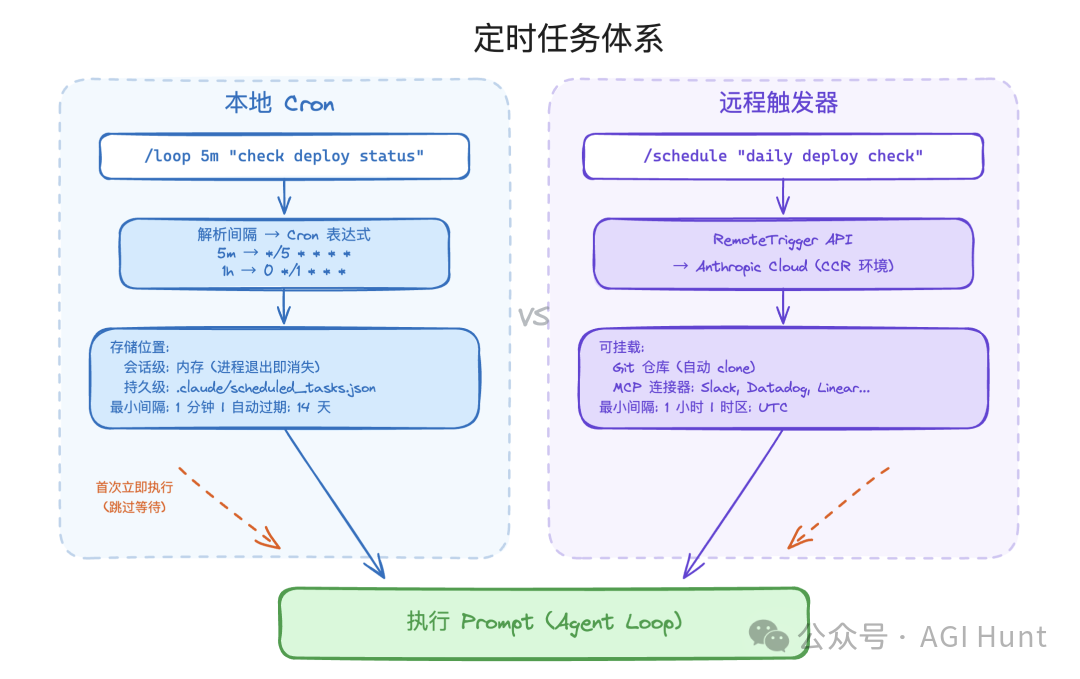
常见用法如下:
/loop 5m /babysit-prs
/loop 30m check the deploy
/loop check status every 20m
/loop
时间间隔会转换成 cron 表达式:
| 输入 | cron 表达式 | 含义 |
|---|---|---|
5m | */5 * * * * | 每 5 分钟 |
2h | 0 */2 * * * | 每 2 小时 |
1d | 0 0 * * * | 每天 0 点 |
cron 的最小粒度通常是分钟,所以秒级间隔会向上取整。不均匀间隔也需要处理,例如 7 分钟无法均匀划分一小时,系统可以提示并取整到更合适的值。
任务有两种存储方式:
| 类型 | 存储位置 | 生命周期 |
|---|---|---|
| 会话级任务 | 内存 | CLI 退出后消失 |
| 持久任务 | .claude/scheduled_tasks.json | 重启后仍存在 |
定时任务创建后会立即执行一次,而不是等待第一个 cron 触发点。这对“每隔一段时间检查一次”的任务更符合直觉,因为用户创建任务时往往希望马上得到第一次结果。
更重的远程触发器可以在云端调度远程 Agent。远程任务通常使用 UTC(Coordinated Universal Time,协调世界时),最小间隔可能比本地任务更长,并且可以挂接 Slack、Datadog 等外部连接器。
Hook 系统:扩展能力不应该写死在核心流程里
Claude Code 的可扩展性很大程度来自 Hook。Hook 是生命周期事件上的插入点,用户或插件可以在这些点执行自定义逻辑。
常见事件包括:
| Hook | 触发时机 |
|---|---|
PreToolUse | 工具执行前 |
PostToolUse | 工具执行后 |
UserPromptSubmit | 用户提交消息时 |
SessionStart | 会话开始 |
FileChanged | 文件变化 |
PermissionRequest | 请求权限 |
PermissionDenied | 权限被拒 |
SubagentStart | 子 Agent 启动 |
Elicitation | URL 唤起协议相关事件 |
Hook 可以来自两种地方:
- SDK(Software Development Kit,软件开发工具包)回调函数。
- settings 配置里的 shell 命令。
例如,一个团队可以在 PreToolUse 里禁止修改某些敏感文件,在 FileChanged 后自动运行格式化或测试,在 UserPromptSubmit 时注入内部规范检查。
可扩展系统的关键是预留稳定事件,而不是把所有需求都写进核心代码。核心只定义生命周期,扩展逻辑交给用户、插件和企业策略。
状态管理:基础设施状态和 UI 状态分开
Claude Code 的状态大致分两层。
| 状态层 | 示例 | 生命周期 |
|---|---|---|
| 全局基础设施状态 | session ID、项目根目录、模型配置、token 统计、team 上下文、hook 注册表 | 整个进程 |
| React 应用状态 | 对话消息、任务列表、UI 展开状态、当前权限弹窗 | UI 渲染周期 |
全局状态适合放跨 Agent、跨组件共享的基础信息。React 状态适合放跟渲染强相关的数据,例如消息列表和输入框状态。
边界清晰很重要。如果所有东西都塞进全局变量,UI 更新会混乱;如果所有基础设施状态都放进 React,非 UI 模块又会被迫依赖渲染层。Agent 运行时需要明确区分“系统状态”和“界面状态”。
费用追踪:Agent 失控时要能止损
长任务 Agent 可能连续调用模型、搜索网页、执行工具。如果没有费用追踪,用户很难知道一次会话已经消耗多少。
Claude Code 按模型统计 token:
| 模型维度 | 统计项 |
|---|---|
| Opus | input、output、cache tokens |
| Sonnet | input、output、cache tokens |
| Haiku | input、output、cache tokens |
缓存命中的 token 通常按较低价格计算。Web 搜索这类工具可能按次数固定收费。会话费用可以通过 session ID 关联到项目配置,恢复旧会话时继续累计,新建会话则从零开始。
费用系统还需要处理未知模型价格。如果遇到无法识别的模型,应该明确标记费用可能不准确,而不是假装统计无误。
对 Agent 产品来说,费用上限和最大轮次一样,都是安全阀:
type AgentSafetyLimits = {
maxTurns: number;
maxBudgetUsd: number;
maxToolCalls: number;
timeoutMs: number;
};
没有这些限制,Agent 在错误循环里可能持续消耗 API 费用和本机资源。
快捷键系统:终端 Agent 也需要可定制交互
Claude Code 的快捷键配置可以放在 ~/.claude/keybindings.json:
{
"bindings": [
{
"context": "main",
"bindings": {
"ctrl+shift+k": "/help",
"cmd+enter": "submit",
"ctrl+k ctrl+s": "toggleSearch"
}
}
]
}
它支持 chord binding,也就是组合键序列。例如 ctrl+k ctrl+s 表示先按 ctrl+k,再按 ctrl+s。
快捷键解析器需要支持别名:
| 别名 | 统一含义 |
|---|---|
ctrl / control | Control |
alt / opt / option | Option / Alt |
cmd / command / super / win | Command / Super |
快捷键还要区分上下文。main、search、textarea、input 等场景下,同一个按键可以有不同含义。Esc 这类保留按键通常不能随意重绑,否则会破坏基础交互。
配置热重载也很实用,用户修改配置后不必重启 CLI。
Source Map 发布风险:打包产物需要检查调试文件
从工程发布角度看,Source Map 事故给所有 TypeScript / JavaScript CLI 项目提了一个醒:构建产物不只要能运行,还要确认不携带不该发布的调试材料。
常见检查项包括:
| 检查项 | 风险 |
|---|---|
.map 文件 | 可能包含源码、路径、注释 |
内嵌 sourceMappingURL | 可能指向可下载 Source Map |
| base64 内联 Source Map | 可能把源码塞进打包文件 |
| 绝对路径 | 暴露内部目录结构和用户名 |
| 未清理测试文件 | 暴露内部接口或测试数据 |
| feature flag 名称 | 暴露未发布功能线索 |
发布前可以加一道脚本:
#!/usr/bin/env bash
set -euo pipefail
DIST_DIR="${1:-dist}"
echo "Checking source maps..."
if find "$DIST_DIR" -name "*.map" | grep -q .; then
echo "Error: source map files found in $DIST_DIR"
exit 1
fi
echo "Checking sourceMappingURL..."
if grep -R "sourceMappingURL" "$DIST_DIR"; then
echo "Error: sourceMappingURL found in bundle"
exit 1
fi
echo "Checking inline base64 maps..."
if grep -R "data:application/json;base64" "$DIST_DIR"; then
echo "Error: inline source map found"
exit 1
fi
echo "Release artifact check passed."
如果确实需要 Source Map,也应该上传到受控的错误追踪平台,而不是随 npm 包公开分发。
可复用的 Agent 架构原则
从 Claude Code 的设计里,可以抽象出一组通用原则,适合用在自己的 AI Agent 框架里。
| 原则 | 具体做法 |
|---|---|
| 流式优先 | 模型工具调用一旦完整就开始执行,不必等待整段回复结束 |
| 工具声明并发安全性 | 读操作并发,写操作串行,判断逻辑由工具自己提供 |
| 权限做成管道 | 规则、命令分类、上下文分类、独立模型判断逐层递进 |
| 上下文按需装载 | Memory、MCP 指令、工具 schema、Skill 内容都不要一次性全塞进 prompt |
| 长会话自动压缩 | 接近窗口上限时,把早期工具调用和结果压缩成摘要 |
| 多 Agent 重视上下文隔离 | 不必默认多进程,同进程隔离也能覆盖很多协作场景 |
| 扩展点靠 Hook | 在生命周期事件上开放插入点,避免把插件逻辑写死 |
| 成本和轮次必须设上限 | 防止 Agent 自循环导致费用和资源失控 |
| 启动流程分阶段 | 信任边界前只做安全初始化,重模块延迟加载 |
做 Agent 产品时,模型能力只是起点。真正决定可用性的,是模型之外的工程系统:工具如何调度,权限如何判断,上下文如何裁剪,扩展如何接入,错误如何恢复,费用如何止损。
Claude Code 的架构说明了一件事:生产级 AI Agent 不是一个“大模型调用器”,而是一个围绕模型构建的运行时。模型负责推理,运行时负责把推理安全、稳定、可控地落到真实环境里。