当越来越多业务都开始接入大语言模型(Large Language Model,LLM)时,一个很现实的问题会出现:每个团队都想要一个自己的 AI 助手,但每个助手又都要重新做意图识别、Prompt 调优、工具接入、流程编排、权限校验和效果验证。
表面上看,不同业务差异很大:有的助手负责发券,有的助手回答金融问题,有的助手排查系统故障,有的助手只是帮人整理一段输入。可把这些需求拆开之后,会发现大量工作其实在重复发生。
真正需要复用的不是某一个具体助手,而是创建助手的方法。
一个可复用的 AI 助手平台,核心目标不是让工程师不停“开发助手”,而是让业务方能基于模板“配置助手”。平台负责沉淀通用能力,业务方只补充业务知识、专家经验、工具权限和少量定制规则。
1. AI 助手工厂要解决什么问题
单个 AI 助手通常由几类能力组成:
flowchart LR
U[用户输入] --> P[预处理]
P --> I[意图识别]
I --> R[推理与规划]
R --> T[工具调用]
R --> K[知识检索]
T --> S[结果总结]
K --> S
S --> U
如果每个助手都从零开始建设,会遇到几个典型问题:
| 问题 | 具体表现 | 后果 |
|---|---|---|
| Prompt 重复编写 | 每个助手都要重新设计角色、输出格式、约束规则 | 调试成本高,质量不稳定 |
| 工具重复接入 | 相同接口被多个助手分别包装 | 工具描述不一致,权限难统一 |
| 流程重复编排 | 意图识别、召回、执行、总结链路高度相似 | 开发周期长 |
| 知识重复构建 | 文档切块、向量化、召回策略各做一套 | 知识更新难维护 |
| 安全规则分散 | 写操作、环境隔离、权限校验分散在各助手里 | 容易产生越权和误操作 |
AI 助手工厂的设计思路是:把高频工作场景抽象成有限的几类模板,每类模板内置通用流程、Prompt 框架、工具治理和安全策略,业务方只配置差异化部分。
2. 四类高频 AI 助手场景
多数工作型 AI 助手可以归入四类:复杂指令执行、知识问答、问题排查、常规极简任务。
| 场景类型 | 本质 | 典型例子 | 核心难点 |
|---|---|---|---|
| 复杂指令执行 | 把用户目标拆成工具链并安全执行 | “给用户 1234 发一张满 50 减 20 的优惠券” | 意图拆解、工具召回、工具链规划、写操作安全 |
| 知识问答 | 从海量图文知识中检索信息并生成回答 | “如何创建迭代?”、“这个截图报错是什么意思?” | 文本与图片联合召回、多轮上下文管理、知识更新 |
| 问题排查 | 从问题表象逐步定位根因 | “优惠券用不了,帮我查一下” | 多轮追问、工具试探、专家经验注入、异常解释 |
| 常规极简任务 | 用 LLM 完成轻量任务 | 文案改写、系统分析、结构化提取 | 接入门槛、快速试错、统一运维 |
这四类场景背后还有一组共性挑战:
- 用户表达不标准,同一个需求可能有多种说法;
- 用户输入可能同时包含文字、图片、截图;
- 工具描述质量参差不齐,功能可能重叠;
- LLM 不能随意执行写操作,必须有环境、权限和影响面控制;
- 调试过程需要可视化,否则很难定位问题出在意图、召回、推理还是执行阶段。
把这些问题抽象出来之后,就可以形成一个分层架构。
3. AI 助手工厂的分层架构
AI 助手工厂可以分成两层:上层是场景解决方案,下层是通用核心能力。上层决定“这个助手按什么流程工作”,下层提供“每个流程节点能复用哪些能力”。
整体结构可以用下面的架构图表示。
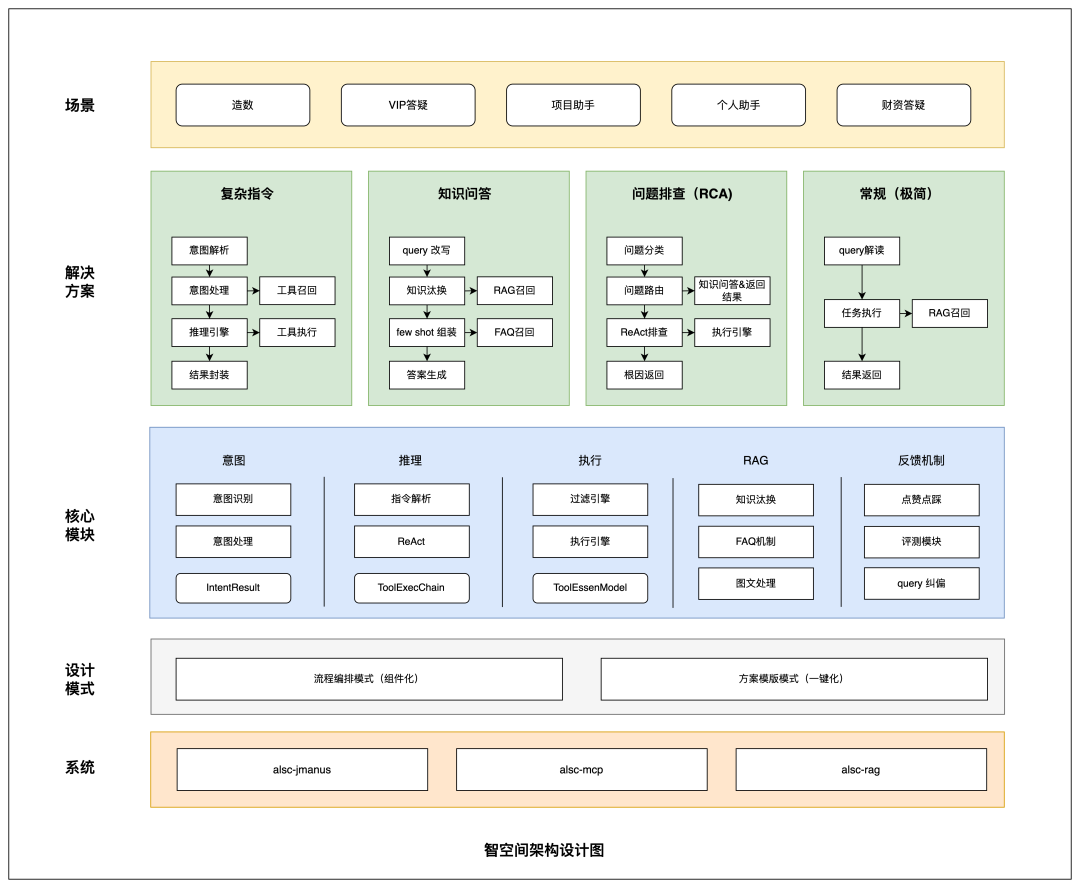
上层的解决方案层固化四类场景的差异化流程,例如复杂指令侧重工具链推理,知识问答侧重检索增强生成(Retrieval-Augmented Generation,RAG),问题排查侧重 ReAct 多轮推理。下层的核心能力层则提供推理、执行、知识、工具和安全能力,供不同模板按需组合。
可以把它理解成“模板 + 组件”的关系:
flowchart TB
subgraph Solution[解决方案模板]
A[复杂指令模板]
B[知识问答模板]
C[问题排查模板]
D[极简任务模板]
end
subgraph Core[核心能力组件]
I[意图识别]
TR[工具召回]
RE[ReAct 推理]
RAG[RAG 检索]
EX[执行引擎]
SEC[安全权限]
SUM[总结反馈]
end
A --> I
A --> TR
A --> EX
A --> SEC
B --> RAG
B --> SUM
C --> I
C --> RE
C --> EX
C --> SEC
D --> RAG
D --> SUM
这种分层的关键价值在于:模板稳定,组件可替换,业务规则可插拔。
4. 复杂指令执行:从一句话生成安全工具链
复杂指令执行不是简单聊天,而是“理解目标、选择工具、规划链路、安全执行”的过程。
用户可能只说一句:
给用户 1234 发放一张满 50 减 20 的优惠券,预发环境。
AI 助手需要做的事情并不少:
- 理解用户要做的是“发券”;
- 识别目标对象是“用户 1234”;
- 确认执行环境是“预发”;
- 找到合适的发券工具;
- 判断发券工具需要哪些入参;
- 如果入参缺失,继续寻找上游查询工具;
- 执行前做权限、环境、读写类型校验;
- 调用工具并向用户返回可理解的结果。
复杂指令场景的架构如下。
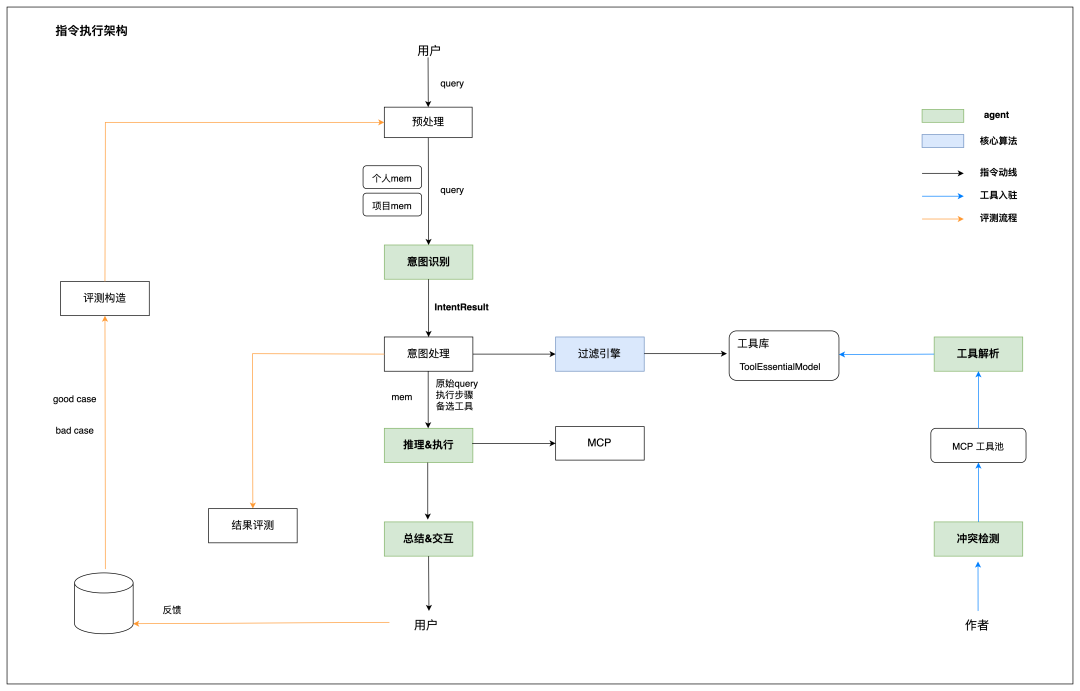
这条链路里,预处理负责处理多模态输入和简单内嵌命令;意图识别负责把自然语言转换成结构化模型;工具召回负责从工具池里筛出候选工具;推理执行负责生成工具链并调用工具;总结模块负责把执行结果组织成用户能理解的回答。
4.1 用 IntentResult 表达用户意图
自然语言不适合直接进入执行链路。更稳妥的做法是先把用户输入转换成结构化意图模型,例如:
{
"actor": "当前用户",
"environment": "预发环境",
"action": "发放",
"targetEntity": "优惠券",
"targetObject": "用户1234",
"conditions": [],
"constraints": [],
"negativeConstraints": [],
"time": "现在",
"missingFields": [],
"rawQuery": "给用户1234发放一张满50减20的优惠券,预发环境"
}
这个结构化模型有几个作用:
- 让后续工具召回可以基于标准字段匹配,而不是直接匹配散乱文本;
- 支持多意图拆解,例如“先查用户状态,再发券”;
- 支持缺失信息追问,例如没有用户 ID、没有环境、没有券模板;
- 支持负向约束,例如“不要影响线上数据”。
4.2 工具召回:从海量工具里筛候选集
工具池一旦变大,不能把所有工具都丢给 LLM 选择。这样不仅上下文过长,还容易让模型选错工具。
更合理的做法是先建立统一工具模型,例如:
{
"toolName": "issueCoupon",
"action": "发放",
"object": "优惠券",
"inputSchema": {
"userId": "string",
"couponTemplateId": "string",
"env": "string"
},
"outputSchema": {
"success": "boolean",
"couponId": "string"
},
"readWriteType": "write",
"supportedEnv": ["pre", "prod"],
"permissionCode": "coupon.issue"
}
工具召回的目标是让用户意图与工具能力进行匹配。FSWW(Fused Subspace with Word Weights)这类加权语义匹配思路可以用于解决这个问题:保留整句语义,同时给关键动作和关键对象更高权重。
以“发放优惠券”为例,匹配时不能只看整句相似度,而要让“发放”和“优惠券”成为主要判断依据。否则,“查询优惠券库存”“删除优惠券模板”“查询用户发券记录”这类工具都可能因为包含相似词而进入候选集。
一个简化后的召回流程如下:
flowchart LR
Q[用户 Query] --> I[IntentResult]
I --> W[动作/对象加权]
W --> M[匹配 ToolEssentialModel]
M --> F[环境/权限/读写过滤]
F --> C[候选工具集]
4.3 推理执行:逆向推理,正向执行
复杂任务通常需要多个工具串联。工具链生成可以采用“逆向推理、正向执行”的方式。
以发券为例:
flowchart RL
Goal[目标:完成发券] --> A[工具A:发放优惠券]
A --> Need1[需要 userId]
A --> Need2[需要 couponTemplateId]
Need1 --> B[工具B:查询用户ID]
Need2 --> C[工具C:查询券模板]
逆向推理从目标工具开始,逐步分析它缺哪些入参,再寻找能补齐入参的上游工具。工具链确定后,再按依赖顺序正向执行:
flowchart LR
B[查询用户ID] --> C[查询券模板]
C --> A[发放优惠券]
A --> R[返回执行结果]
涉及工具调用时,模型上下文协议(Model Context Protocol,MCP)可以作为工具接入和调用的统一协议。LLM 只负责规划调用链,真正执行由受控执行引擎完成。
执行前至少要做四类安全校验:
| 校验类型 | 作用 |
|---|---|
| 环境校验 | 确认工具能否在预发、测试、线上等环境执行 |
| 读写类型校验 | 查询类需求不能误用写工具,写操作必须显式确认 |
| 功能匹配校验 | 确认工具能力与用户目标一致 |
| 权限与影响面校验 | 校验操作者权限,限制高风险操作范围 |
复杂指令执行的关键不是“让 LLM 自由发挥”,而是让 LLM 在结构化输入、候选工具、执行约束和安全策略内完成规划。
5. 知识问答:RAG 不只检索文本,还要召回图片
知识问答场景的核心目标是:根据用户问题,在知识库里找到相关信息,并生成准确回答。
传统 RAG 往往只处理文本,但工程文档、业务手册和故障排查资料里有大量图片:架构图、流程图、时序图、配置截图、报错截图。只检索文本会丢失很多关键信息。
知识问答的推理链路如下。
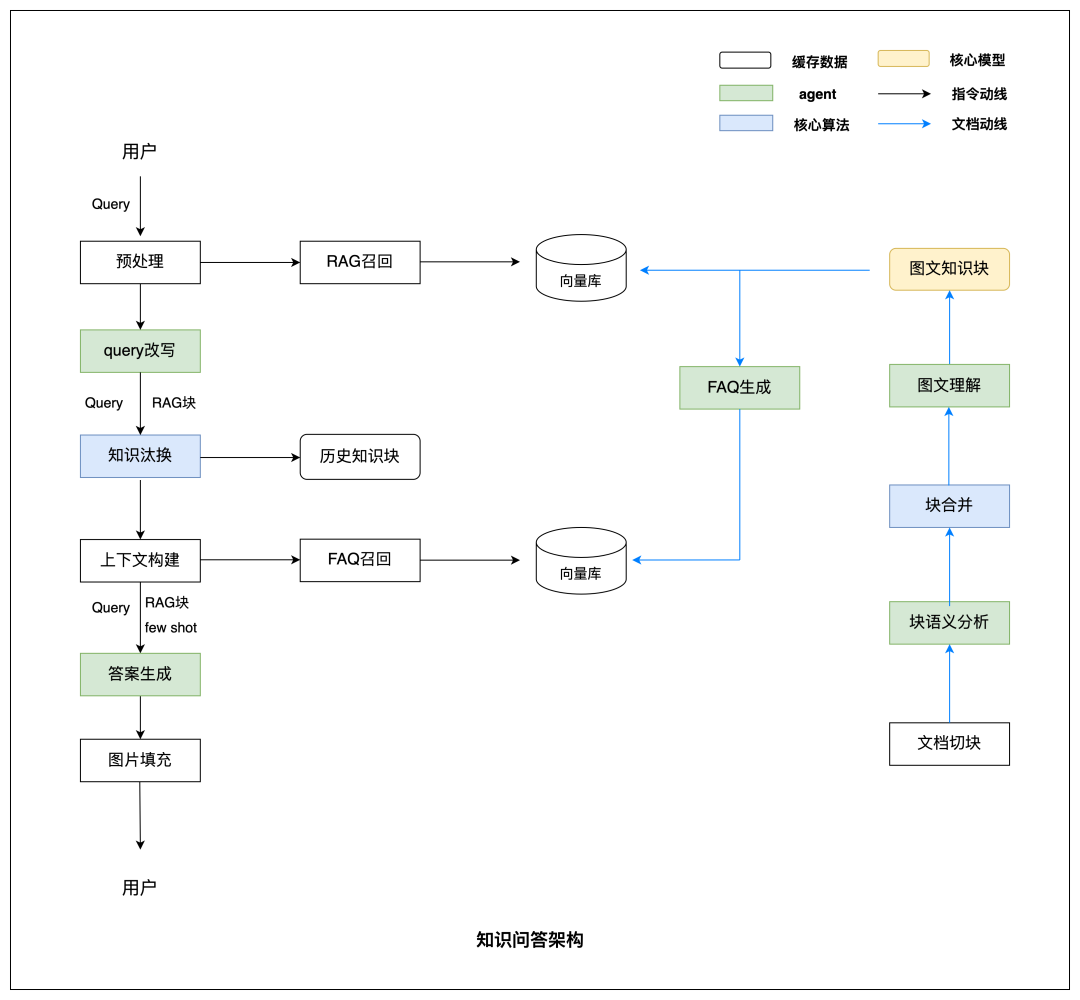
这个流程包含预处理、Query 改写、知识筛选、上下文生成、答案生成和图片填充。答案文本由模型生成,图片则从知识库中召回,避免模型凭空生成不存在的图片内容。
5.1 图文 RAG 的知识构建流程
图文 RAG 的关键在知识入库阶段。图片不能只当附件保存,而要转成可检索、可关联的语义信息。
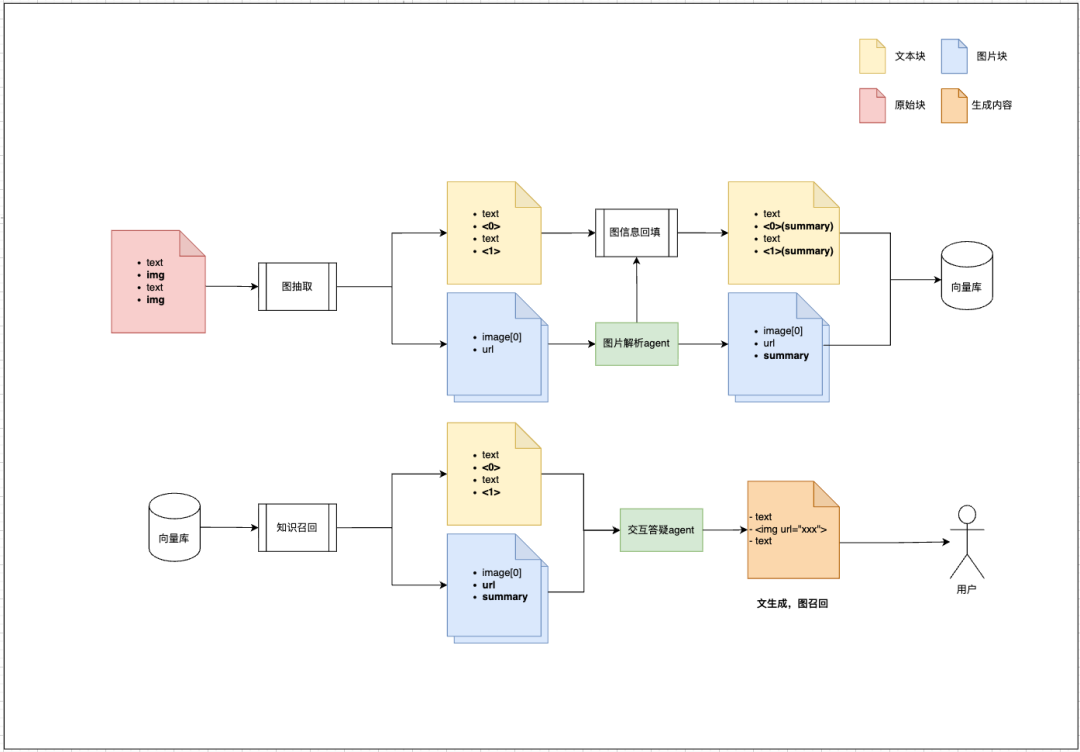
比较实用的做法是:
- 文档解析时,把文本拆成语义完整的文本块;
- 遇到图片时,使用图像解析 Agent 生成图片摘要;
- 把图片摘要回填到图片附近的文本上下文中;
- 文本块和图片分别向量化;
- 文本块与图片 ID 建立关联关系;
- 检索时返回文本证据,同时返回关联图片。
可以把知识块设计成类似结构:
{
"chunkId": "gateway-route-001",
"text": "配置网关路由时,需要进入路由管理页面,填写路径、服务名和转发规则。",
"imageSummary": "图片展示了网关路由配置页面,包括路径输入框、服务名下拉框、转发规则配置区域。",
"imageIds": ["img-gateway-route-config"],
"source": "gateway-routing-guide.md"
}
这样用户问“网关路由怎么配置”时,系统既能生成操作步骤,也能把配置页面截图一起返回。
5.2 多轮对话里的知识汰换
知识问答还有一个容易被忽略的问题:用户会连续追问,而且可能中途跳转话题。
多轮对话常见三种情况:
| 对话状态 | 示例 | 处理策略 |
|---|---|---|
| 话题延续 | “那第二步在哪里配置?” | 保留上一轮知识块 |
| 话题切换 | “另一个问题,权限怎么申请?” | 引入新知识,降低旧知识权重 |
| 话题回跳 | “刚才那个网关路由继续说” | 恢复历史相关知识 |
多轮知识选择流程如下。
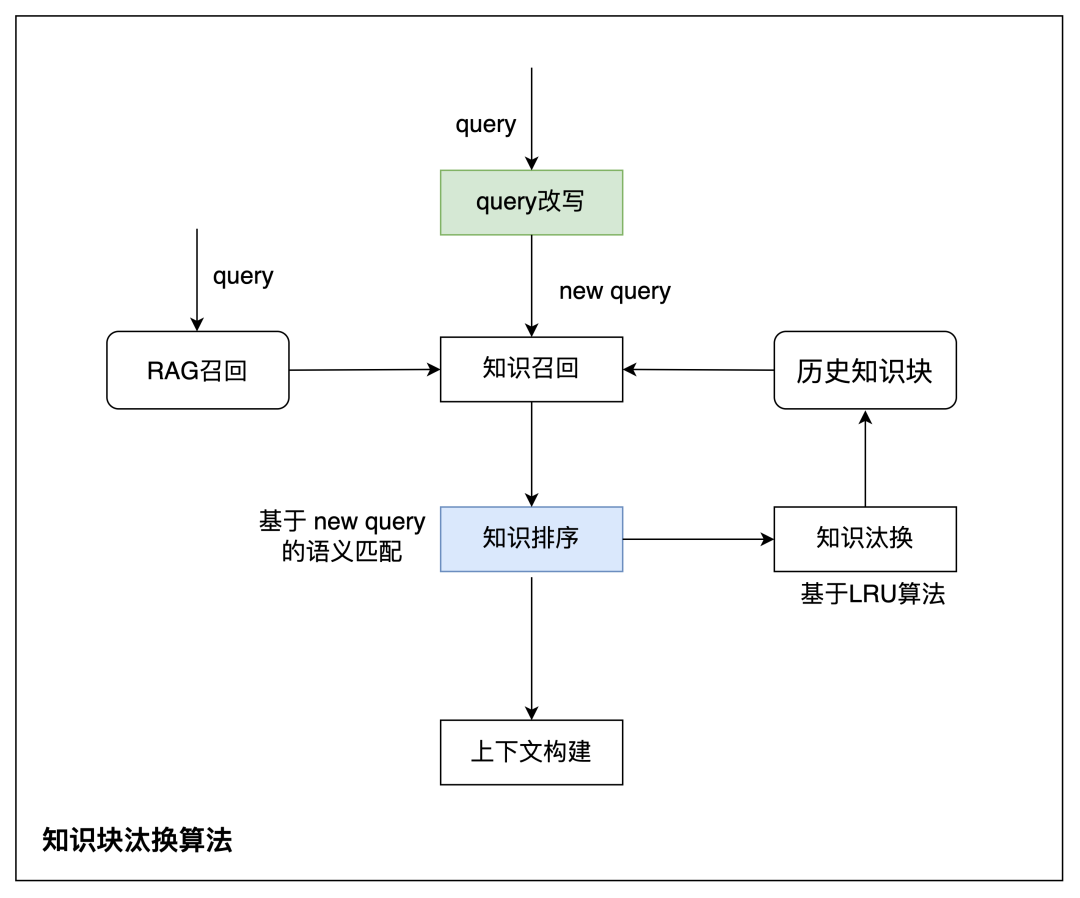
系统可以基于三个信号决定知识保留与汰换:
topicSwitch:是否发生话题切换;dialogAct:当前输入是追问、确认、纠错还是新问题;infoNovelty:当前输入带来了多少新信息。
一个简化的决策逻辑可以写成:
def select_knowledge(old_chunks, new_chunks, topic_switch, dialog_act, info_novelty):
if topic_switch and info_novelty > 0.7:
return rank(new_chunks)
if dialog_act in ["follow_up", "clarification"]:
return rank(old_chunks + new_chunks, boost_old=True)
if dialog_act == "back_to_previous_topic":
return recover_previous_topic_chunks(old_chunks)
return rank(old_chunks + new_chunks)
多轮 RAG 的重点不是无限保留上下文,而是在“连贯性”和“抗干扰”之间动态平衡。
6. 问题排查:用 ReAct 把表象推进到根因
问题排查场景本质上是根因分析(Root Cause Analysis,RCA)。用户给出的通常只是表象,例如:
优惠券用不了,帮我查一下。
AI 助手需要逐步判断:
- 是用户不会操作,还是系统异常?
- 是券模板失效,还是用户不满足领取条件?
- 是账号状态异常,还是风控命中?
- 是前端提示问题,还是后端接口失败?
问题排查架构如下。
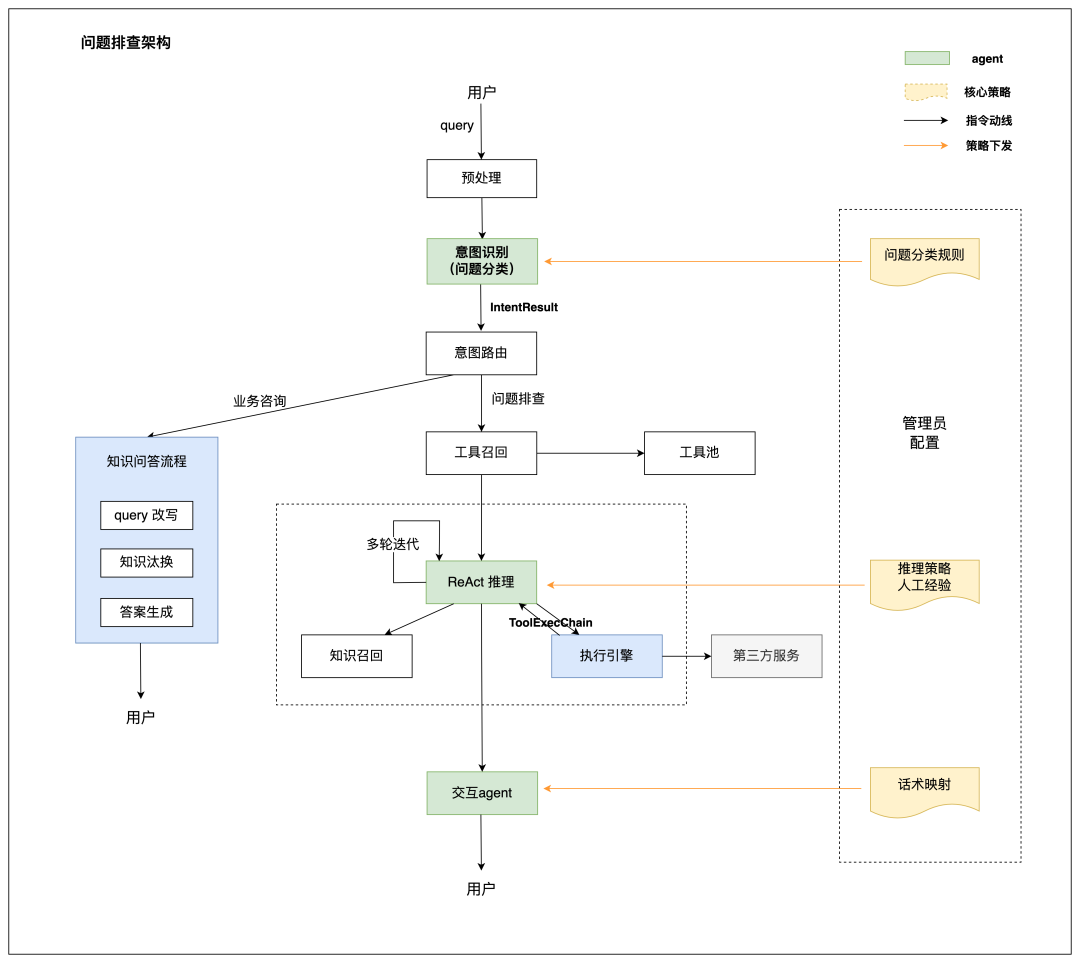
这类助手通常先做意图路由,把请求分成两类:
| 类型 | 处理方式 |
|---|---|
| 业务咨询类 | 走知识问答流程,例如“如何查看优惠券” |
| 查询排查类 | 走 ReAct 推理流程,例如“用户 1234 的券为什么用不了” |
ReAct(Reason + Act,推理与行动)模式适合排查类任务。它让 Agent 在每一轮中思考下一步该查什么,再交给执行引擎调用工具,然后基于观察结果继续推理。
6.1 ReAct Agent 只规划,不直接执行
为了控制风险,ReAct Agent 不应该直接调用工具,而是输出结构化执行计划。
输入通常包括:
{
"intentResult": {},
"rawQuery": "优惠券用不了,帮我查一下",
"toolResults": [],
"conversationHistory": [],
"availableTools": []
}
输出可以是:
{
"thought": "需要先确认用户身份和优惠券状态,再判断是否命中限制条件。",
"actions": [
{
"toolName": "queryUserCouponStatus",
"arguments": {
"userId": "1234"
},
"reason": "查询用户当前优惠券状态"
}
],
"needUserConfirm": false,
"riskLevel": "low"
}
执行引擎负责真正调用工具,并把结果回传给 ReAct Agent。这样可以把“推理”和“执行”隔离开,便于权限控制、审计和重试。
6.2 两种执行引擎
排查任务复杂度不同,执行引擎可以分成轻量版和完整版。
| 执行引擎 | 流程 | 适合场景 | 代价 |
|---|---|---|---|
| ReActExecutor | Thought → Action | 简单查询、单步排查 | 响应快,但复杂任务不够稳 |
| ReActObservationExecutor | Thought → Action → Observation | 多步骤排查、需要重试或回退 | 多一次观察与评估,耗时更长 |
选择方式可以很直接:
| 场景 | 推荐引擎 | 原因 |
|---|---|---|
| 简单答疑或查询 | ReActExecutor | 少一次模型调用,响应更快 |
| 多步骤业务排查 | ReActObservationExecutor | 每一步都需要根据结果调整路径 |
| 需要错误恢复 | ReActObservationExecutor | 观察阶段可以触发重试、回退或追问 |
问题排查助手的质量很大程度取决于“专家经验”。平台可以提供 ReAct 框架、工具执行和权限控制,但每类问题该怎么排查、先查什么、哪些结果代表异常,仍然需要业务专家沉淀成策略。
7. 常规极简任务:不要把简单场景做复杂
不是所有助手都需要多 Agent、多工具、多轮推理。很多场景只需要一个清晰 Prompt,再复用平台已有能力即可。
极简场景的架构如下。
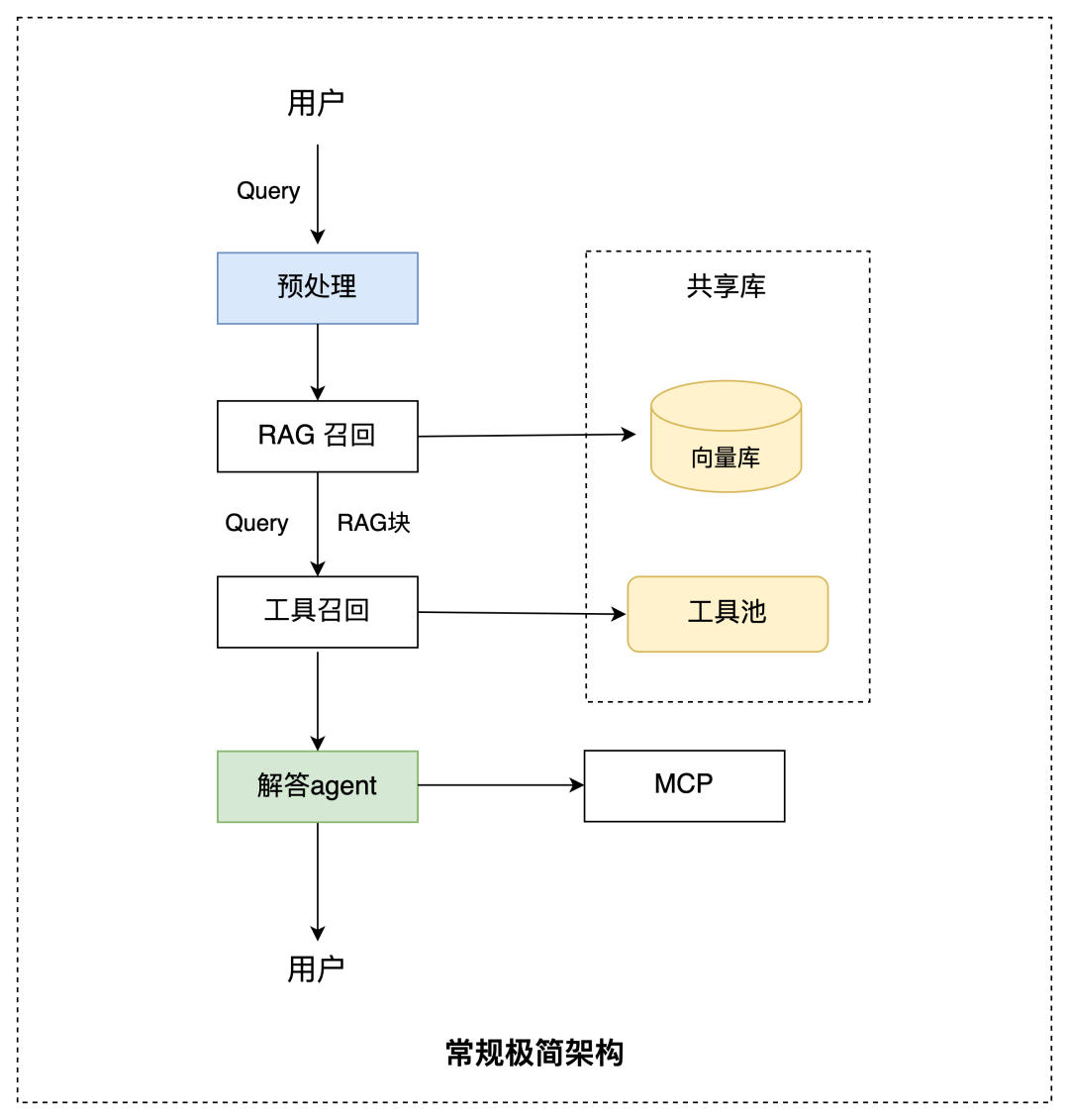
这种模板的目标是降低接入成本,让简单助手快速创建,同时复用平台统一能力:
- 复用多模态预处理;
- 复用公共工具池;
- 复用统一 RAG 知识库;
- 复用权限与安全体系;
- 复用调试、发布和运维流程。
适合极简模板的场景包括:
| 场景 | 示例 |
|---|---|
| 文本处理 | 改写、总结、格式转换 |
| 结构化提取 | 从自然语言中提取字段 |
| 轻量分析 | 根据输入生成检查清单 |
| 固定问答 | 基于少量知识回答常见问题 |
极简模板的原则是:能用单 Agent 解决,就不要引入复杂编排;能用平台公共能力解决,就不要为单个场景单独建设。
8. Prompt 插拔架构:框架 Prompt + 业务定制
Prompt 形式上是文本,本质上是给 LLM 执行的指令程序。既然是程序,就应该有模块、接口、参数和复用边界。
一个可维护的 Prompt 不应该是一整段难以修改的长文本,而应该拆成两部分:
| 部分 | 负责内容 | 维护方式 |
|---|---|---|
| 框架 Prompt | 通用角色、任务步骤、输出模型、约束规则、追问逻辑 | 平台统一维护 |
| 业务定制 Prompt | 业务说明、意图分类、字段规则、归一化词表、示例 | 业务方配置 |
以意图识别 Agent 为例,框架 Prompt 可以定义稳定结构:
你是意图识别 Agent,需要把用户输入解析为 IntentResult。
必须完成:
1. 识别用户动作、对象、环境、约束、时间、缺失信息;
2. 判断是否需要追问;
3. 按指定 JSON Schema 输出;
4. 不允许执行工具;
5. 不允许补充用户没有表达的关键事实。
业务定制信息:
{{business_description}}
意图分类:
{{intent_definitions}}
动作归一化词表:
{{action_normalization}}
实体归一化词表:
{{entity_normalization}}
输出模型:
{{intent_result_schema}}
业务方只需要填写插槽内容,例如:
business_description: |
当前助手用于优惠券业务,支持查询用户券状态、发放测试券、排查用券失败问题。
intent_definitions:
- name: issue_coupon
description: 给指定用户发放指定优惠券
- name: query_coupon_status
description: 查询用户当前优惠券状态
- name: diagnose_coupon_failure
description: 排查用户无法使用优惠券的原因
action_normalization:
发: 发放
给: 发放
查一下: 查询
看看: 查询
entity_normalization:
券: 优惠券
优惠: 优惠券
这种设计有三个好处:
- 框架部分稳定后,可以统一升级;
- 业务差异集中在插槽里,不会污染通用逻辑;
- 调试时可以明确判断问题来自框架逻辑还是业务配置。
9. 从模板到平台:让业务方配置助手
AI 助手工厂最终要落到产品能力上。理想流程应该足够简单:
flowchart LR
A[选择模板] --> B[填写业务配置]
B --> C[绑定知识库和工具]
C --> D[调试验证]
D --> E[发布生效]
不同模板需要的配置项不同。
| 模板 | 必填配置 | 可选配置 |
|---|---|---|
| 复杂指令 | 意图定义、工具池、权限策略、执行环境 | 工具召回权重、确认话术 |
| 知识问答 | 知识库、召回策略、回答格式 | 图片召回、FAQ 示例 |
| 问题排查 | 问题分类、排查流程、工具池、专家经验 | 重试策略、追问策略 |
| 极简任务 | 任务说明、输出格式 | 少量示例、知识库 |
创建排查助手时,最重要的不是一开始就写 Prompt,而是把问题拆清楚:
- 明确助手要解决哪些问题,不解决哪些问题;
- 按互斥穷尽(Mutually Exclusive Collectively Exhaustive,MECE)原则拆分问题类型;
- 为每类问题沉淀排查过程,而不是只写最终结论;
- 绑定每一步排查需要的工具和知识;
- 用真实 Query 调试意图识别、工具调用和总结反馈。
排查策略应该写成过程,例如:
intent: diagnose_coupon_failure
steps:
- name: 查询用户券状态
tool: queryUserCouponStatus
abnormal_conditions:
- couponStatus == "expired"
- couponStatus == "used"
- name: 查询用户账号风险
tool: queryUserRiskStatus
abnormal_conditions:
- riskLevel in ["high", "blocked"]
- name: 查询券模板限制
tool: queryCouponTemplateRule
abnormal_conditions:
- userNotMatchRule == true
response_policy:
explain_system_error_in_plain_language: true
ask_user_for_missing_fields: true
平台要做的是把多 Agent 编排、工具召回、Prompt 框架、权限控制和发布流程隐藏起来,让专家把精力放在“如何判断问题”和“如何处理问题”上。
10. 落地时容易踩的坑
10.1 工具描述不适合 AI 使用
给人看的接口文档不一定适合 LLM。工具描述需要明确动作、对象、输入、输出、适用环境和风险等级。
不清晰的描述:
查询券信息。
更适合 AI 的描述:
查询指定用户在指定环境下的优惠券状态。
适用于判断用户是否已领取、已使用、已过期或不可用。
只读工具,不会修改数据。
必填入参:userId、env。
10.2 写操作必须有强约束
AI 助手一旦能调用写工具,就必须引入更严格的控制:
- 高风险操作需要二次确认;
- 线上写操作需要权限校验;
- 测试数据与真实数据要隔离;
- 工具执行结果要可审计;
- 查询意图不能调用写工具。
10.3 多轮对话不能简单拼历史
把所有历史对话都塞进上下文,会增加噪声,还可能让模型被旧话题干扰。多轮场景需要做知识筛选、话题识别和历史压缩。
10.4 专家经验不能只写结论
“如果优惠券用不了,一般是账号异常”这种经验太粗,无法指导 Agent 排查。更有价值的是过程:
先查用户券状态。
如果券已过期,直接解释过期原因。
如果券正常,再查账号风控状态。
如果账号被限制,解释风控命中原因。
如果账号正常,再查券模板规则。
Agent 需要的是可执行的判断路径。
11. AI 助手工厂的演进方向
模板化可以解决“重复开发”的问题,但还可以继续向自动化演进。
一个更成熟的助手工厂,可以让后台 Agent 自动完成部分配置工作:
| 当前依赖人工的工作 | 可自动化方向 |
|---|---|
| 分析历史案例 | 从工单、对话和文档中抽取问题类型 |
| 拆分意图 | 自动生成候选意图并检查重叠 |
| 编写 Prompt | 根据模板生成业务定制配置 |
| 绑定工具 | 根据动作和对象推荐工具 |
| 调试 Query | 自动生成测试集并回归验证 |
| 运维分析 | 统计失败 Query,反向优化意图和知识 |
但有一件事不能完全交给后台 Agent:高质量专家经验的沉淀。
平台可以提供骨架,LLM 可以提供推理能力,工具可以连接业务系统,RAG 可以承载文档知识。真正决定助手是否好用的,仍然是专家是否把真实场景里的判断过程、异常分支、边界条件和处理经验沉淀下来。
AI 助手工厂的目标不是减少专家价值,而是把专家从重复搭框架、调 Prompt、接工具的工作里释放出来,让他们专注于定义问题、整理经验和校准结果。