企业落地 AI(人工智能)时,经常会遇到一个反直觉的问题:模型越来越强,项目成功率却没有同步提高。
很多失败并不是因为大语言模型不会推理,而是因为模型拿到的上下文是混乱的。客户信息在 CRM,订单状态在 ERP,事件记录在 ITSM,流程痕迹在流程挖掘系统,文档又散落在知识库和网盘里。智能体看似能调用工具、检索资料、生成建议,但它没有一个可靠的上下文基座来回答几个关键问题:
- 当前业务对象到底是谁?
- 相关证据来自哪里,是否可信?
- 这个动作是否允许执行?
- 如果写回系统,怎么审计、回滚和追责?
- 这次处理产生的新知识,能不能沉淀给下一次使用?
上下文工程(Context Engineering)要解决的正是这些问题。它不只是把提示词写得更好,也不只是把文档塞进向量数据库,而是把模型推理时需要的一切信息,变成可设计、可评估、可治理、可复用的工程系统。
统一上下文层 UCL(Unified Context Layer)可以理解为企业级上下文工程的一种核心架构。它把上下文图谱、权限治理、上下文编译、情境分析、工具调用、证据账本和运行时学习放在同一个受控基座里,让智能体不只是“回答问题”,而是能在企业规则内推理、决策、行动和学习。
1. 上下文工程到底是什么
上下文工程是对大语言模型推理时所接收信息的系统化设计。这里的“上下文”不只包括用户输入,还包括:
| 上下文类型 | 例子 | 作用 |
|---|---|---|
| 系统指令 | 角色、边界、输出格式 | 约束模型行为 |
| 对话历史 | 用户之前问过什么、系统之前回答过什么 | 保持连续性 |
| 检索内容 | 文档片段、数据库记录、知识库条目 | 提供事实依据 |
| 业务对象 | 客户、订单、合同、供应商、资产、工单 | 让模型知道正在处理什么 |
| 工具定义 | API schema、函数参数、可调用动作 | 让模型能行动 |
| 权限策略 | 谁能看什么、谁能改什么、什么动作要审批 | 防止越权 |
| 输出约束 | JSON schema、引用要求、置信度字段 | 方便系统接收结果 |
| 审计证据 | 输入、检索结果、决策理由、工具调用记录 | 支持追踪和复盘 |
如果把大语言模型看成一种新的计算单元,模型本身像处理器,上下文窗口像工作内存。模型每次推理能做出什么结果,很大程度上取决于工作内存里放了什么、怎么组织、哪些信息被赋予更高优先级、哪些信息被屏蔽。
普通提示词工程关注的是“怎么问”。上下文工程关注的是“模型在回答或行动前,应该看到什么、相信什么、遵守什么、记录什么”。
flowchart LR
A[用户任务] --> B[上下文工程层]
C[(业务系统)] --> B
D[(知识库)] --> B
E[(权限与策略)] --> B
F[(历史记忆)] --> B
B --> G[上下文包]
G --> H[LLM / 智能体]
H --> I[回答 / 决策 / 工具调用]
I --> J[(证据账本与学习回写)]
J --> B
这个流程里,模型并不直接面对所有原始数据。上下文工程层会把分散的数据、权限、证据和工具能力编译成一个上下文包,再交给模型使用。
2. 为什么“多给上下文”不够
很多 RAG(Retrieval-Augmented Generation,检索增强生成)系统失败,并不是因为没有检索,而是因为检索结果无法支持可靠行动。
常见做法是:用户提问后,系统从向量库里取出若干段相似文本,拼进提示词,让模型生成答案。这种方式适合问答,但放到企业流程里会暴露明显短板:
| 问题 | 表现 | 后果 |
|---|---|---|
| 检索片段缺少结构 | 只知道某段文字相似,不知道它对应哪个客户、合同、订单 | 模型无法稳定推理 |
| 权限没有进入上下文 | 用户能问到不该看的内容,或模型调用了不该调用的工具 | 安全风险 |
| 证据不可追踪 | 模型回答看起来合理,但无法证明依据 | 难以审计 |
| 写回无约束 | 智能体可以建议动作,却不能安全执行动作 | 只能停留在 Copilot |
| 学习不能沉淀 | 每次处理完都丢失经验 | 系统长期不进步 |
更深层的问题是“理解”和“生成行动”之间存在差距。模型可能能理解复杂材料,却未必能把理解转化成一个正确、合规、可执行的业务动作。比如模型能读懂一份采购合同,也能看懂发票匹配失败的原因,但它还需要知道:
- 当前供应商是否允许自动豁免?
- 这类差异金额是否超过审批阈值?
- 历史上类似情况怎么处理?
- 应该改采购订单、重新开票,还是发起争议?
- 哪个动作会影响财务关账?
- 执行动作后如何记录证据?
所以,企业级上下文不能只是“更多文本”,而要变成结构化、可验证、可执行的上下文系统。
3. 上下文图谱为什么重要
上下文图谱(Context Graph)是把企业上下文组织成图结构的一种方式。图中通常包含实体、关系、事件、证据和决策痕迹。
flowchart LR
S[供应商 Supplier] -->|交付| O[采购订单 PO]
O -->|对应| I[发票 Invoice]
O -->|受约束于| C[合同 Contract]
I -->|触发| E[三方匹配异常]
E -->|参考| P[采购政策 Policy]
E -->|历史相似| H[历史处理案例]
E -->|产生| D[处理决策]
D -->|写入| L[证据账本]
和普通文本检索相比,图谱至少带来三类价值。
3.1 结构比字符串更适合推理
字符串检索只能告诉模型“这段话可能相关”。图谱可以告诉模型:
- 这个发票属于哪个订单;
- 订单对应哪份合同;
- 合同里有哪些付款条款;
- 供应商过去是否多次延期;
- 这次异常和哪些历史决策相似;
- 哪些政策限制了自动处理。
模型面对的不再是一堆段落,而是一组带关系的业务事实。
3.2 决策痕迹可以沉淀为资产
企业最有价值的上下文不只是“现在有什么数据”,还包括“过去为什么这么处理”。例如:
- 哪些异常曾经被批准?
- 哪些告警后来证明是误报?
- 哪些供应商在什么条件下可以自动豁免?
- 哪些客户投诉需要人工升级?
- 哪些变更导致过重大事故?
这些信息如果只留在邮件、会议纪要或工单评论里,智能体很难复用。放进上下文图谱后,过去的决策就能成为下一次推理的证据。
3.3 跨域关系能够暴露隐性风险
单个系统往往只能看到局部事实。跨图谱分析才能发现更复杂的问题。
举个例子:
- 身份安全图谱记录:过去 127 次来自新加坡的登录告警被关闭为误报,置信度 0.94。
- 威胁情报图谱记录:近期新加坡 IP 段的凭证填充攻击增长 340%。
单独看这两条信息,都不一定触发高优先级事件。合在一起看,就可能说明误报规则已经过时,需要重新校准风险模型。
这类发现依赖共享实体、统一语义和可遍历的元图。只有把多个业务域接到同一个上下文基座,智能体才有机会发现跨域信号。
4. 只有上下文图谱还不够
把企业元数据导入图数据库,并不会自动产生可生产化的智能体。图谱解决的是“上下文如何表示”,但企业级智能体还要解决“谁来消费、谁来修改、谁来控制行动”。
可以把问题拆成四层。
| 层次 | 需要解决的问题 | 只有图数据库时的缺口 |
|---|---|---|
| 读取 | 智能体如何遍历图谱、选择证据、构造推理上下文 | 图里有数据,但不知道该取哪些 |
| 决策 | 当前情况该推荐、审批、执行还是升级 | 图数据库不负责情境判断 |
| 写回 | 新关系、新案例、新决策如何沉淀 | 缺少运行时演进机制 |
| 行动 | 工具调用如何受控、审计、回滚 | 缺少激活和治理闭环 |
真正的自主智能体至少需要三种能力:
- 消费结构:能读取上下文图谱,把图结构转成任务相关的上下文包。
- 变异操作:能在运行后更新图谱,例如合并实体、添加关系、记录新案例。
- 受控激活:能在权限、审批、回滚、证据账本约束下调用业务系统。
没有这些能力,上下文图谱会停留在“高级知识库”阶段,无法支撑企业流程自动化。
5. 现有架构路线的能力边界
企业 AI 生态里已经出现了几种常见路线:MCP、ADK、ACE、上下文图谱。它们都解决了一部分问题,但侧重点不同。
5.1 MCP:解决连接问题
MCP(Model Context Protocol,模型上下文协议)提供统一协议,让 AI 应用连接外部工具和数据源。它的价值在于降低集成成本,避免每个模型应用都为每个系统单独写适配器。
适合解决的问题:
- AI 应用如何调用数据库、搜索、代码仓库、业务 API;
- 不同工具如何用统一方式暴露给模型;
- 连接器生态如何复用。
不足也很明显:MCP 让智能体“连得上”,但不保证它“理解得对、做得安全、写得可审计”。连接不是治理,工具可见也不等于动作可执行。
5.2 ADK:把上下文看成编译结果
ADK(Agent Development Kit,智能体开发工具包)类框架通常强调把上下文从原始源编译成模型可用视图。它关注成本、延迟、信号衰减和推理漂移。
适合解决的问题:
- 如何把多源信息整理成模型输入;
- 如何控制上下文窗口大小;
- 如何让智能体运行路径更稳定。
它的短板在于:编译视图能让模型看到更好的上下文,但如果缺少企业流程、权限、写回、审计和激活机制,智能体仍然更像一个推荐系统,而不是能闭环处理业务的执行系统。
5.3 ACE:让智能体自我改进
ACE(Agent Context Engineering,智能体上下文工程)强调让智能体通过生成、反思、策展等循环改进自己的 Playbook,也就是任务处理手册。
适合解决的问题:
- 智能体如何根据执行结果调整策略;
- 如何降低适应新任务的延迟;
- 如何让经验沉淀到下一次运行。
问题在于:自我改进需要高质量企业上下文作为燃料。如果智能体只在孤立环境里优化 Playbook,而没有接入 ERP、ITSM、EDW、流程挖掘、权限策略和证据账本,它改进的可能只是局部行为,未必符合企业真实流程。
5.4 能力对比

能力矩阵的核心信息是:单点架构通常只覆盖连接、编译、学习或图谱存储中的某一部分,而企业级智能体需要把这些能力连成一个闭环。
| 架构路线 | 强项 | 主要缺口 |
|---|---|---|
| MCP | 标准化连接工具和数据源 | 缺少语义治理、情境分析、受控激活 |
| ADK | 上下文编译、运行路径规范 | 缺少跨流程融合和企业级写回闭环 |
| ACE | Playbook 自改进 | 缺少企业上下文基座和治理对象 |
| 上下文图谱 | 结构化表达企业知识和决策痕迹 | 缺少消费、变异、激活系统 |
| UCL | 统一上下文、治理、推理、行动、学习 | 架构复杂度更高,需要分阶段建设 |
UCL 的定位不是替代所有技术,而是把这些能力放到同一个企业上下文基座中。MCP 可以成为连接层的一部分,图数据库可以承载上下文图谱,RAG 可以作为检索手段,ACE 式循环可以用于运行时学习;UCL 负责把它们组织成可治理的生产架构。
6. 什么样的上下文工程才算企业级
企业级上下文工程至少要具备七个维度。少了其中任意一个,系统都很容易退化成“能演示、难生产”的 AI 应用。
| 维度 | 要解决的问题 | 缺失后的风险 |
|---|---|---|
| 多源融合 | ERP、EDW、ITSM、流程挖掘、文档系统如何统一接入 | 智能体只能看到局部事实 |
| 统一语义 | 客户、订单、供应商、资产等实体如何统一定义 | 同名不同义、同物不同名导致推理错误 |
| 上下文图谱 | 实体、关系、事件、证据、决策如何结构化 | 检索结果碎片化,无法推理 |
| 上下文产品化 | 上下文包如何版本化、测试、评估 | 不知道模型输入质量是否达标 |
| 控制平面 | 权限、策略、血缘、隐私、职责分离如何执行 | 越权访问和合规风险 |
| 情境分析 | 系统如何判断当前情况、评分风险、选择动作 | 智能体只能按脚本走,遇到新情况就升级 |
| 受控激活 | 写回、审批、回滚、审计、证据账本如何闭环 | 无法安全执行真实业务动作 |
企业级要求的重点不在“有没有 AI”,而在“AI 是否可以进入关键业务流程”。一旦智能体能改订单、关工单、触发财务动作、调整供应链计划,治理、证据和回滚就不再是附加功能,而是基础设施。
7. UCL 的核心架构
UCL(Unified Context Layer,统一上下文层)位于企业系统和 AI 消费端之间。它既不是单纯的数据湖,也不是单纯的向量库,而是一个把数据、语义、策略、工具和证据统一起来的上下文运行层。
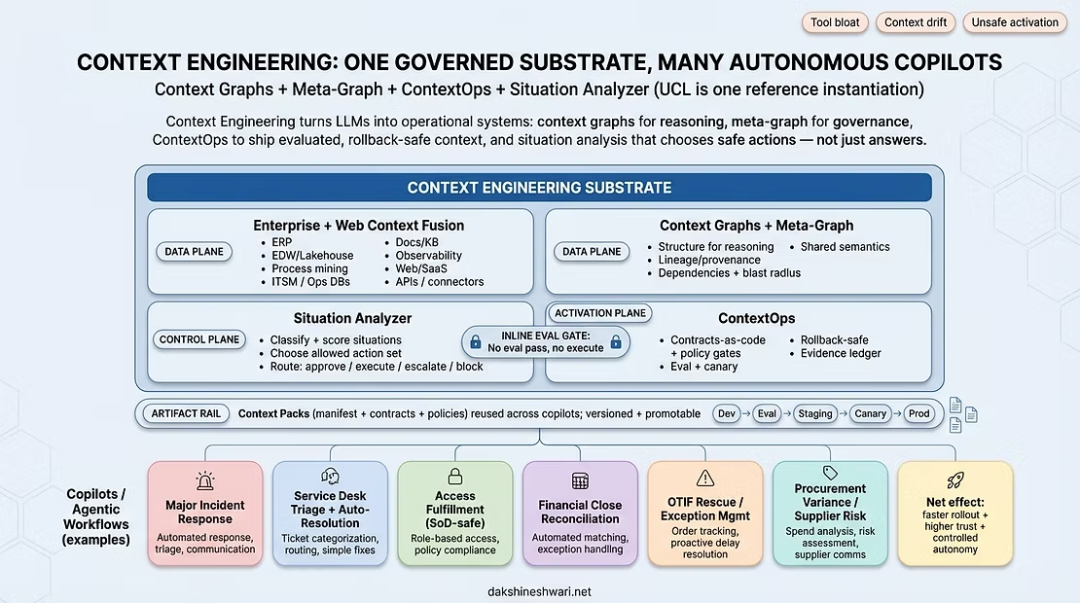
图中表达的是“一套受控上下文基座,服务多个自主 Copilot”的架构思想。重大事件响应、服务台分类、访问履行、财务关账、供应链救援、采购差异处理等场景,不应该各自重复建设上下文系统,而应该共享同一个语义和治理底座。
可以把 UCL 拆成五个平面理解。
flowchart TB
subgraph Consumers[消费端]
BI[BI 分析]
ML[机器学习模型]
RAG[RAG 问答]
Agents[AI 智能体]
Automation[业务自动化]
end
subgraph UCL[统一上下文层 UCL]
SA[情境分析平面\n风险评分 / 路由 / 决策]
CP[控制平面\n权限 / 策略 / 评估 / 血缘]
MP[元数据与语义平面\n实体 / 关系 / 上下文图谱]
DP[数据与服务平面\n连接器 / 事件 / API / 文档]
AP[受控激活平面\n工具调用 / 写回 / 回滚 / 证据账本]
end
subgraph Systems[企业系统]
ERP[(ERP)]
EDW[(EDW)]
ITSM[(ITSM)]
PM[(流程挖掘)]
Docs[(知识库)]
Sec[(安全系统)]
end
Systems --> DP
DP --> MP
MP --> CP
CP --> SA
SA --> Consumers
Consumers --> AP
AP --> Systems
AP --> MP
7.1 数据与服务平面
这一层负责连接企业已有系统,包括:
- ERP(Enterprise Resource Planning,企业资源计划);
- EDW(Enterprise Data Warehouse,企业数据仓库);
- ITSM(IT Service Management,IT 服务管理);
- CRM(Customer Relationship Management,客户关系管理);
- 流程挖掘平台;
- 文档知识库;
- 安全日志和监控系统;
- 内部 API 和自动化工具。
关键不是把所有数据复制一遍,而是把数据源抽象成可治理的上下文源。每个源都需要带上血缘、更新时间、权限标签、可信等级和可调用能力。
7.2 元数据与语义平面
这一层负责定义企业世界里的“名词”和“关系”。
例如“供应商”这个实体,在采购系统、财务系统、合同系统里可能有不同 ID。UCL 需要通过实体解析把它们合并到统一语义对象上。
flowchart LR
A[采购系统 Supplier ID] --> E[统一供应商实体]
B[财务系统 Vendor ID] --> E
C[合同系统 Counterparty ID] --> E
D[风控系统 Risk Profile] --> E
E --> F[合同]
E --> G[采购订单]
E --> H[发票]
E --> I[交付记录]
E --> J[风险事件]
这就是上下文图谱真正发挥作用的位置:它不只是保存知识,还负责把业务对象、事件、证据和历史决策连接起来。
7.3 控制平面
控制平面决定上下文能否被使用、如何被使用、能不能写回。常见能力包括:
- 身份认证和权限控制;
- 数据脱敏和最小化暴露;
- 行级、字段级访问策略;
- 上下文包评估;
- 模型输出校验;
- 审批规则;
- 职责分离;
- 数据血缘和审计。
上下文包进入模型前,可以设置质量门禁。例如:
| 指标 | 含义 | 示例阈值 |
|---|---|---|
| answerable@k | 前 k 条证据是否足以回答问题 | ≥ 90% |
| cite@k | 输出是否能引用前 k 条证据 | ≥ 95% |
| faithfulness | 回答是否被证据支持 | ≥ 95% |
| policy_pass | 是否通过权限和策略检查 | 必须通过 |
| schema_valid | 输出是否符合结构化 schema | 必须通过 |
这些指标让上下文从“拼出来的一段提示词”变成“经过测试的输入产品”。
7.4 情境分析平面
情境分析是 UCL 区别于普通数据层的关键。它负责判断当前状态属于哪种业务情境,并决定下一步应该推荐、执行、升级还是拒绝。
例如发票异常场景中,情境分析器要同时考虑:
- 差异金额;
- 合同条款;
- 供应商历史表现;
- 是否接近关账日期;
- 是否影响现金流;
- 是否存在欺诈风险;
- 当前用户权限;
- 自动处理策略。
情境分析器输出的不是一段自然语言,而是可执行决策结构:
{
"situation": "invoice_three_way_match_exception",
"risk_score": 0.31,
"root_cause": "purchase_order_quantity_mismatch",
"recommended_action": "adjust_po_quantity_within_tolerance",
"requires_human_approval": false,
"allowed_tools": [
"get_contract_terms",
"update_purchase_order",
"release_invoice_hold"
],
"evidence_required": true,
"rollback_plan": "restore_previous_po_quantity_and_reapply_invoice_hold"
}
智能体拿到这样的结构,才能从“会聊天”进入“会处理”。
7.5 受控激活平面
受控激活负责把智能体决策变成真实业务动作,同时保证安全。
一个动作执行前至少要经过几类校验:
flowchart LR
A[智能体提出动作] --> B{权限检查}
B -- 不通过 --> X[拒绝并记录]
B -- 通过 --> C{策略检查}
C -- 不通过 --> Y[升级人工审批]
C -- 通过 --> D{预写入验证}
D -- 不通过 --> Z[返回修正建议]
D -- 通过 --> E[执行业务 API]
E --> F[写入证据账本]
F --> G[更新上下文图谱]
这层的目标不是让智能体随意操作系统,而是让它在可证明、可撤销、可审计的边界内行动。
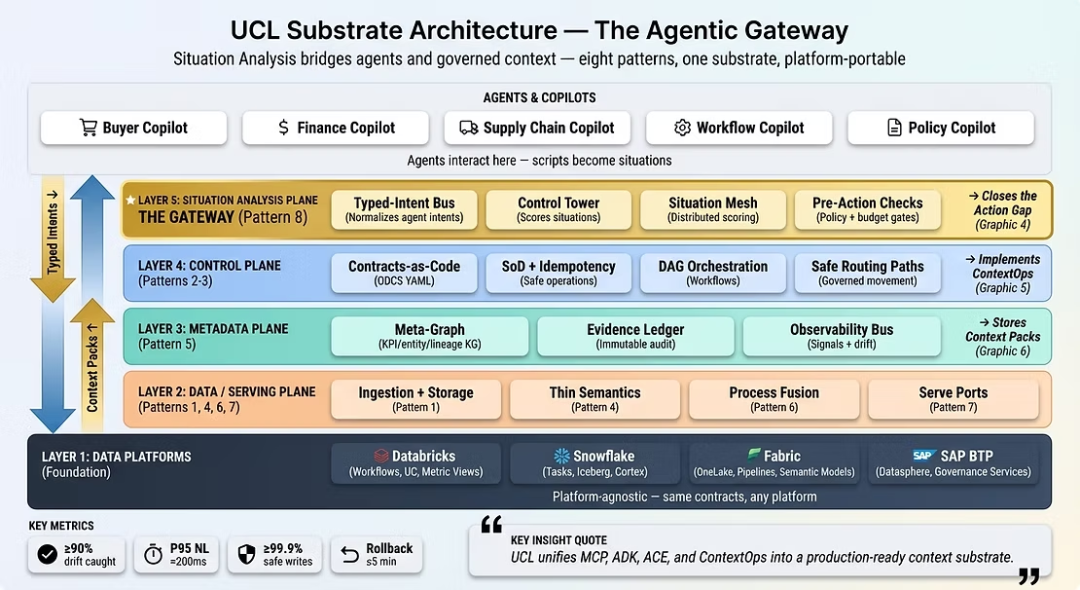
架构图把 UCL 分成数据/服务、元数据、控制和情境分析等层次。最上层的情境分析像一个智能体网关:所有 Copilot 和自动化流程都通过它获取上下文、选择动作,并把结果写回证据账本与语义图谱。
8. UCL 带来的六个范式变化
8.1 上下文从临时输入变成受管控产品
传统做法里,上下文往往是运行时临时拼接出来的字符串。UCL 中的上下文包需要版本、schema、质量指标和发布流程。
一个上下文包可以长这样:
{
"context_id": "ctx-invoice-2026-000381",
"version": "1.4.2",
"task": "invoice_exception_resolution",
"subject": {
"invoice_id": "INV-88421",
"purchase_order_id": "PO-77290",
"supplier_id": "SUP-1024"
},
"evidence": [
{
"type": "contract_clause",
"source": "contract_repo",
"id": "CLAUSE-12.3",
"confidence": 0.98
},
{
"type": "goods_receipt",
"source": "erp",
"id": "GR-66102",
"confidence": 0.99
}
],
"policies": [
"auto_release_allowed_if_difference_below_5000",
"human_approval_required_for_new_supplier"
],
"allowed_actions": [
"request_supplier_credit_note",
"adjust_po_within_tolerance",
"release_invoice_hold"
],
"eval": {
"answerable_at_5": 0.94,
"cite_at_5": 0.97,
"faithfulness": 0.96
}
}
这种结构能被测试、复用和审计,而不是每次靠工程师临时写 prompt。
8.2 异构数据源被统一到同一语义层
UCL 不要求企业推倒重来。ERP、EDW、ITSM、流程挖掘和文档库仍然保留原有职责,但它们暴露给智能体的上下文要经过统一语义映射。
这样做的好处是:财务 Copilot、供应链 Copilot、IT 运维 Copilot 不再各自维护一套“客户”“订单”“资产”“供应商”的定义。
8.3 元数据成为推理基座
元数据不再只是数据目录里的说明文字,而是智能体推理时可遍历的结构。字段含义、实体关系、血缘、权限、历史决策,都能进入上下文图谱。
8.4 一个基座服务多种消费模型
同一个 UCL 可以服务不同消费方式:
| 消费模式 | 说明 |
|---|---|
| S1:BI | 面向报表和分析 |
| S2:ML | 面向机器学习特征和预测 |
| S3:RAG | 面向问答和文档生成 |
| S4:智能体 | 面向推理、规划和工具调用 |
| 激活 | 面向业务系统写回和自动化执行 |
没有统一基座时,每种模式都要重复做数据接入、权限控制和语义定义,成本高且容易不一致。
8.5 激活闭环必须受控
企业智能体最危险的部分不是回答错,而是“带着错误去执行”。UCL 要求所有写动作都经过预验证、策略判断、职责分离、回滚计划和证据记录。
8.6 情境分析让智能体从脚本走向自主
脚本化 Copilot 只能按预设路径处理问题。真正有价值的企业智能体需要根据上下文判断当前情况,识别根因,选择动作,并在不确定性过高时升级给人。
自主不是不受限制,而是在明确边界内做动态决策。
9. UCL 的八种工程模式
UCL 可以按八种模式逐步建设,不需要一次性完成所有能力。
| 模式 | 目标 | 关键产物 |
|---|---|---|
| 1. 源系统适配 | 接入 ERP、ITSM、EDW、文档库、API | 连接器、事件流、数据血缘 |
| 2. 实体解析 | 统一客户、供应商、订单、资产等对象 | 主实体、ID 映射、置信度 |
| 3. 语义建模 | 定义业务实体、关系、事件、状态 | 本体、元图、关系 schema |
| 4. 上下文编译 | 为不同任务生成上下文包 | 上下文模板、排序策略、裁剪规则 |
| 5. 质量评估 | 判断上下文是否足以支持回答和行动 | answerable@k、cite@k、faithfulness |
| 6. 权限治理 | 控制谁能看、谁能问、谁能调用工具 | 策略引擎、脱敏规则、审批矩阵 |
| 7. 受控激活 | 安全执行写回动作 | 预写入校验、回滚、证据账本 |
| 8. 情境分析 | 根据上下文做风险评分和动作选择 | 决策网关、路由器、升级规则 |
第 8 种模式相当于智能体网关。它不是简单转发请求,而是决定“这个任务该由哪个智能体处理、能否自动执行、需要哪些证据、失败后怎么恢复”。
10. 一个供应商延迟交货场景
假设供应商延迟交货,风险评分突然升高,客户交付截止日期临近。没有 UCL 时,流程通常是这样:
sequenceDiagram
participant Ops as 运营人员
participant ERP as ERP
participant Portal as 供应商门户
participant Risk as 风险系统
participant Mail as 邮件/会议
participant Finance as 财务系统
Ops->>ERP: 查询采购订单和库存
Ops->>Portal: 查询供应商承诺日期
Ops->>Risk: 查看风险评分
Ops->>Mail: 找历史沟通和例外审批
Ops->>Finance: 确认付款和发票状态
Ops->>Ops: 人工拼接判断
问题不在于数据不存在,而是数据分散在多个系统,且缺少统一证据链。争议处理可能需要 2 到 3 天,期间没有完整审计轨迹,也很难让智能体自主处理。
有 UCL 后,同一任务会变成受控闭环:
sequenceDiagram
participant Event as 风险信号
participant UCL as UCL 情境分析
participant Graph as 上下文图谱
participant Agent as 供应链智能体
participant ERP as ERP / 业务系统
participant Ledger as 证据账本
Event->>UCL: 供应商延期 + 风险评分升高
UCL->>Graph: 拉取订单、合同、库存、历史决策
Graph-->>UCL: 返回结构化上下文包
UCL->>UCL: 评分风险、识别根因、选择动作
UCL->>Agent: 下发受控上下文与允许动作
Agent->>ERP: 调整补货计划或触发替代供应
ERP-->>Agent: 返回执行结果
Agent->>Ledger: 写入证据、动作、理由、回滚信息
Ledger->>Graph: 更新决策痕迹
几个变化很关键:
- 智能体拿到的是结构化上下文包,不是散乱文档片段;
- 动作范围由策略控制,不允许越权调用;
- 每一步都有证据和来源;
- 执行结果会回写图谱,成为下一次决策的上下文;
- 只有超出策略边界的异常才升级给人工。
这就是从“辅助人查资料”到“在治理内自动处理”的区别。
11. 三个典型落地场景
11.1 发票例外处理
场景:发票被冻结,三方匹配失败。智能体需要拉取合同条款、采购订单、收货记录、发票信息和历史处理案例,判断根因并选择动作。
| 能力 | 没有 UCL | 有 UCL |
|---|---|---|
| 根因分析 | 财务、采购人工查多个系统 | 情境分析器聚合合同、订单、收货和发票 |
| 动作选择 | 人工判断是改订单、重开发票还是争议处理 | 根据政策和阈值选择允许动作 |
| 执行 | 人工在 ERP 中操作 | 通过受控激活调用 API |
| 审计 | 分散在邮件和系统评论中 | 证据账本记录输入、理由、动作和结果 |
适合自动处理的是低风险、规则明确、证据充分的异常。高金额、新供应商、合同争议类问题仍然应该升级人工。
11.2 OTIF 恢复
OTIF(On-Time In-Full,按时足量交付)下降时,供应链团队需要判断问题来自供应商、库存、运输、产能还是需求预测。UCL 可以融合 ERP、物流、流程挖掘和历史履约数据,找到根因并触发补救动作。
| 步骤 | UCL 的作用 |
|---|---|
| 信号捕获 | 发现 OTIF 指标异常 |
| 根因定位 | 关联订单、库存、运输节点、供应商承诺 |
| 风险评分 | 判断是否影响关键客户或高价值订单 |
| 动作执行 | 触发替代供应、加急运输、库存重分配 |
| 结果验证 | 跟踪 OTIF 是否恢复,并记录决策效果 |
11.3 重大事件拦截
IT 运维场景中,凌晨 2 点服务器延迟飙升。普通告警系统会通知值班人员,人工排查变更、日志、依赖服务和历史故障。
UCL 可以把监控告警、变更记录、服务拓扑、历史事故和回滚策略接在一起:
flowchart LR
A[延迟告警] --> B[关联服务拓扑]
B --> C[查找近期变更]
C --> D[评估爆炸半径]
D --> E{是否允许自动补救}
E -- 是 --> F[执行回滚或扩容]
E -- 否 --> G[升级值班工程师]
F --> H[记录证据与结果]
G --> H
MTTR(Mean Time To Recovery,平均恢复时间)能否从小时降到分钟,取决于系统是否提前准备好了上下文、权限和回滚路径。只有告警,没有受控行动,智能体仍然只能建议别人去处理。
12. 常见失败模式与 UCL 的防护方式
企业 GenAI(生成式人工智能)试点常见失败,往往可以归结为上下文层的问题。
| 失败模式 | 机制 | UCL 防护方式 |
|---|---|---|
| 数据孤岛 | 智能体只能看到局部系统 | 多源接入和统一语义层 |
| 检索幻觉 | 相似片段被误当成证据 | 上下文图谱、引用校验、faithfulness 评估 |
| 权限越界 | 模型拿到不该看的数据或工具 | 控制平面、最小权限、脱敏 |
| 无法行动 | 只能生成建议,不能安全写回 | 受控激活、预写入验证、回滚 |
| 无法学习 | 每次处理都从零开始 | 决策痕迹回写上下文图谱 |
| 无法审计 | 不知道模型为什么这么做 | 证据账本记录上下文、理由和动作 |
这些问题靠“换更强模型”不能根治。模型能力决定上限,上下文工程决定生产可用性。
13. 建设 UCL 的落地路径
UCL 不适合从“大一统平台”开始。更可行的方式是围绕高价值流程逐步建设。
13.1 选一个闭环场景
优先选择同时具备以下特征的场景:
- 业务价值明确;
- 数据源有限但分散;
- 有规则和历史案例可参考;
- 存在重复人工判断;
- 自动化动作可以被权限和阈值约束;
- 执行结果容易验证。
发票异常、IT 事件处理、访问权限履行、供应链异常恢复,通常比开放式战略分析更适合作为起点。
13.2 定义核心实体和关系
不要一开始建全企业知识图谱。先围绕场景定义最小上下文图谱。
以发票异常为例,最小实体包括:
entities:
- Supplier
- PurchaseOrder
- Invoice
- Contract
- GoodsReceipt
- Policy
- ExceptionCase
- Decision
relationships:
- Supplier issues Invoice
- Invoice matches PurchaseOrder
- PurchaseOrder governed_by Contract
- GoodsReceipt confirms PurchaseOrder
- ExceptionCase similar_to ExceptionCase
- Decision based_on Evidence
有了最小图谱,才谈得上上下文编译和情境分析。
13.3 设计上下文包 schema
上下文包应该稳定、可测试,不能每次临时拼接。
context_package:
task: string
subject:
entity_type: string
entity_id: string
facts:
- name: string
value: any
source: string
timestamp: datetime
confidence: number
evidence:
- id: string
type: string
citation: string
access_policy: string
policies:
- policy_id: string
decision: allow | deny | require_approval
allowed_actions:
- tool_name: string
constraints: object
output_schema: object
rollback_required: boolean
schema 的价值在于让上下文工程可自动化测试,也方便模型输出进入后续系统。
13.4 建立质量门禁
每次发布新的上下文模板或检索策略,都应该跑评估集。评估集可以来自历史工单、历史发票异常、历史事故等。
| 测试项 | 检查内容 |
|---|---|
| 可回答性 | 给定上下文是否包含解决任务所需证据 |
| 引用完整性 | 输出中的关键结论是否能引用证据 |
| 权限正确性 | 不同角色是否只能看到允许内容 |
| 动作合法性 | 模型是否只选择允许工具 |
| 回滚完整性 | 写动作是否有对应撤销方案 |
| 稳定性 | 同类输入是否得到一致决策 |
13.5 先半自动,再自动
企业级智能体不应该一上线就全自动。更稳妥的路径是:
flowchart LR
A[人工处理] --> B[AI 推荐 + 人工确认]
B --> C[低风险动作自动执行]
C --> D[中风险动作审批后执行]
D --> E[策略内闭环自治]
每提高一级自动化,都要增加对应的评估、权限、回滚和审计能力。
14. 容易踩的坑
14.1 把 UCL 做成另一个数据湖
UCL 不是把所有数据复制到一个地方。它的重点是语义、证据、权限和行动闭环。盲目集中数据会带来成本、同步和合规问题。
14.2 把向量库当成上下文工程
向量检索只是上下文获取方式之一。企业智能体还需要结构化实体、关系、策略、证据、工具约束和写回机制。
14.3 只做读,不做写回
如果系统不能把新决策、新案例、新关系沉淀回上下文图谱,智能体就不会真正变聪明。运行时学习不是保存聊天记录,而是把有价值的决策痕迹结构化。
14.4 工具调用缺少预验证
让模型直接调用业务 API 风险很高。每个写动作都应该有参数校验、权限校验、策略校验、幂等控制和回滚计划。
14.5 忽略职责分离
某些动作不能由同一个角色完成所有步骤。例如创建供应商、修改付款信息、释放付款,往往需要不同权限或审批链。智能体也必须遵守这些规则。
14.6 上下文越塞越多
上下文工程不是把所有相关内容都塞进模型窗口。更好的做法是基于任务、角色、风险和证据质量编译上下文。少而准的上下文通常比多而乱的上下文更可靠。
15. 判断一个智能体是否真的企业级
可以用一组问题快速判断系统成熟度:
| 问题 | 如果答案是否定的,说明什么 |
|---|---|
| 能否解释每个关键结论来自哪条证据? | 缺少证据链 |
| 不同角色看到的上下文是否不同? | 缺少权限治理 |
| 模型调用工具前是否经过策略检查? | 缺少受控激活 |
| 写回失败后能否回滚? | 不适合关键业务 |
| 新处理案例是否进入知识结构? | 缺少运行时学习 |
| 能否跨系统识别同一业务实体? | 语义层不足 |
| 能否区分推荐、审批、执行、升级? | 情境分析不足 |
只有这些问题都能回答清楚,AI 智能体才有资格进入企业核心流程。
16. UCL 的核心价值
UCL 的价值不是“再建一个中台”,而是把企业 AI 从松散应用推进到可治理的运行系统。
它把已有企业投资连接起来:ERP、EDW、ITSM、流程挖掘、文档库和业务 API 不需要被替换,而是通过统一语义和控制平面变成智能体可消费的上下文源。
它让上下文图谱从静态数据结构变成运行时系统:智能体读取图谱进行推理,执行动作后把证据和决策写回图谱,下一次任务再从更新后的图谱中获取更好的上下文。
它让自主变得可控:智能体可以在政策边界内自动处理低风险任务,在不确定性升高时升级人工,并且所有动作都能被审计和回滚。
企业级上下文工程的关键不是让模型知道更多,而是让模型在正确的时间拿到正确的证据,遵守正确的规则,调用正确的工具,并把正确的经验沉淀回来。UCL 正是围绕这个闭环建立的架构。