OpenClaw 可以理解为一个 AI Agent(智能体)运行环境:大语言模型不只负责聊天,还能调用工具、访问网页、读写本地文件、执行定时任务,并把结果发送到外部平台。
只用命令行运行 OpenClaw 时,能力是有的,但使用体验会遇到几个问题:
| 问题 | 具体表现 |
|---|---|
| 权限分散 | 浏览器、文件系统、消息平台、API Key 都要单独配置 |
| 任务不可见 | 定时任务是否运行、是否失败,不容易直观看到 |
| 技能管理麻烦 | 安装、更新、导入 Skills 需要频繁切换命令行 |
| 安全边界模糊 | Agent 什么时候在沙箱里跑,什么时候访问本机,不够清晰 |
| 多模型切换成本高 | 复杂任务用强模型,简单任务用便宜模型,手动切换很繁琐 |
LobsterAI(有道龙虾)解决的正是这些桌面端问题。它不是简单给 OpenClaw 套一层聊天窗口,而是把模型、Skills、沙箱、定时任务、记忆和消息渠道集中到一个图形界面里。
官网和仓库地址:
https://lobsterai.youdao.com
https://github.com/netease-youdao/LobsterAI
它支持 macOS 和 Windows,也能连接钉钉、飞书、Telegram、Discord 等外部平台,适合拿来做长期运行的信息流 Agent。
LobsterAI 在 OpenClaw 体系里负责什么
桌面端的核心价值不是“让模型更聪明”,而是让 Agent 的运行过程可管理。
一个完整的信息流 Agent 通常包含这些部分:
flowchart LR
U[用户] --> D[LobsterAI 桌面端]
D --> M[模型管理]
D --> S[Skills 管理]
D --> T[定时任务]
D --> MEM[记忆与偏好]
D --> BOX[VM/本地沙箱]
D --> C[消息连接器]
M --> LLM[大语言模型]
S --> WEB[网页 / Reddit / X / GitHub / RSS]
T --> RUN[任务执行器]
MEM --> RUN
BOX --> RUN
RUN --> C
C --> FEISHU[飞书]
C --> DING[钉钉]
C --> TG[Telegram]
C --> DISCORD[Discord]
C --> EMAIL[邮箱]
桌面端把这些能力串起来之后,信息流任务就可以形成闭环:
- 定时启动任务。
- Skill 读取 Reddit、X、RSS、GitHub、搜索引擎等来源。
- 模型筛选、摘要、去重、归类。
- 结果写入本地 Markdown 或发送到 Discord、飞书、邮箱等渠道。
- 根据用户反馈更新记忆,让下一次摘要更贴近偏好。
安装后的主界面承担的是“工作台”角色:对话、模型、任务和技能都可以在同一个窗口里管理。
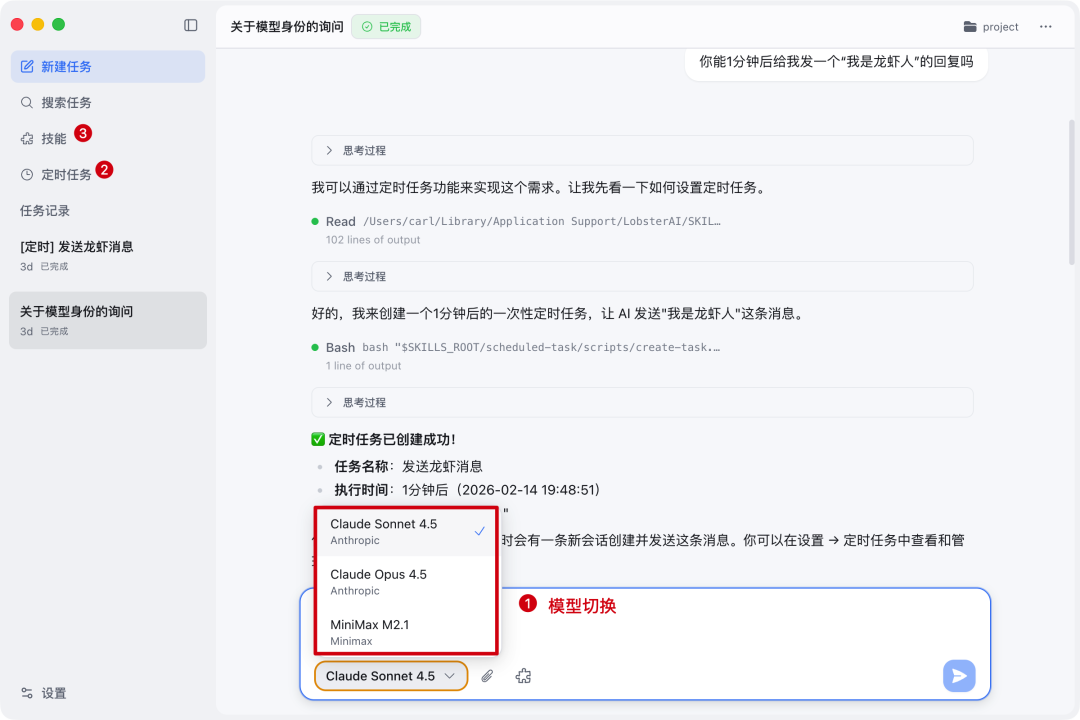
这个界面适合管理长期任务。比如同一个信息流任务里,可以让复杂分析使用 Claude Sonnet 4.6,让简单整理或格式化任务切到成本更低的模型。对话成本、任务状态和上下文都能在桌面端直接处理,不必在多个终端窗口之间切换。
连接器:把 Agent 结果发到工作流里
信息流 Agent 的输出不应该只停留在聊天窗口。每天的摘要、预警、需求分析,如果还要手动复制出来,自动化价值会下降很多。
LobsterAI 的连接器配置可以把结果推送到常用协作平台。
连接器解决的是“结果送达”问题:
| 输出渠道 | 适合内容 |
|---|---|
| Discord | 技术新闻频道、社区趋势摘要、开源项目监控 |
| 飞书 / 钉钉 | 团队日报、竞品动态、产品反馈整理 |
| Telegram | 个人信息流、轻量提醒 |
| 邮箱 | 长摘要、结构化报告、每日汇总 |
| 本地 Markdown | 长期沉淀、后续检索、个人知识库 |
如果只是临时搜索,聊天窗口够用;如果是每天固定运行的信息流任务,最好直接把结果送到已经在使用的工作流里。
沙箱:默认隔离,必要时再访问本机
Agent 能访问网页和本地文件之后,安全边界就很重要。一个长期运行的桌面 Agent 不应该默认拿到所有本机权限。
LobsterAI 的做法是让任务优先在 VM(Virtual Machine,虚拟机)沙箱中运行。沙箱完成不了的任务,再切换到本地环境执行。
这个策略适合处理两类任务:
| 执行环境 | 适合任务 |
|---|---|
| VM 沙箱 | 网页读取、公开信息检索、临时文件处理、风险不明确的 Skill |
| 本地环境 | 读取指定本地目录、写入个人知识库、调用本机 App、使用本机密钥 |
更安全的配置方式是:默认使用沙箱,只给少数可信任务开放本地权限。这样既能跑自动化,又不会让所有 Skill 都直接接触本机文件系统。
Skills:桌面端管理比命令行更适合长期使用
Skills 可以理解为 OpenClaw 的工具包。一个 Skill 通常会封装某类能力,例如读取 Reddit、搜索 GitHub、抓取 RSS(Really Simple Syndication,简易信息聚合)、调用浏览器、发送邮件等。
在桌面端管理 Skills 的好处是导入方式更直观。LobsterAI 支持从本地文件夹、ZIP 包导入,也可以直接粘贴 GitHub 仓库地址,让它把仓库里的多个 Skills 一次性导入。
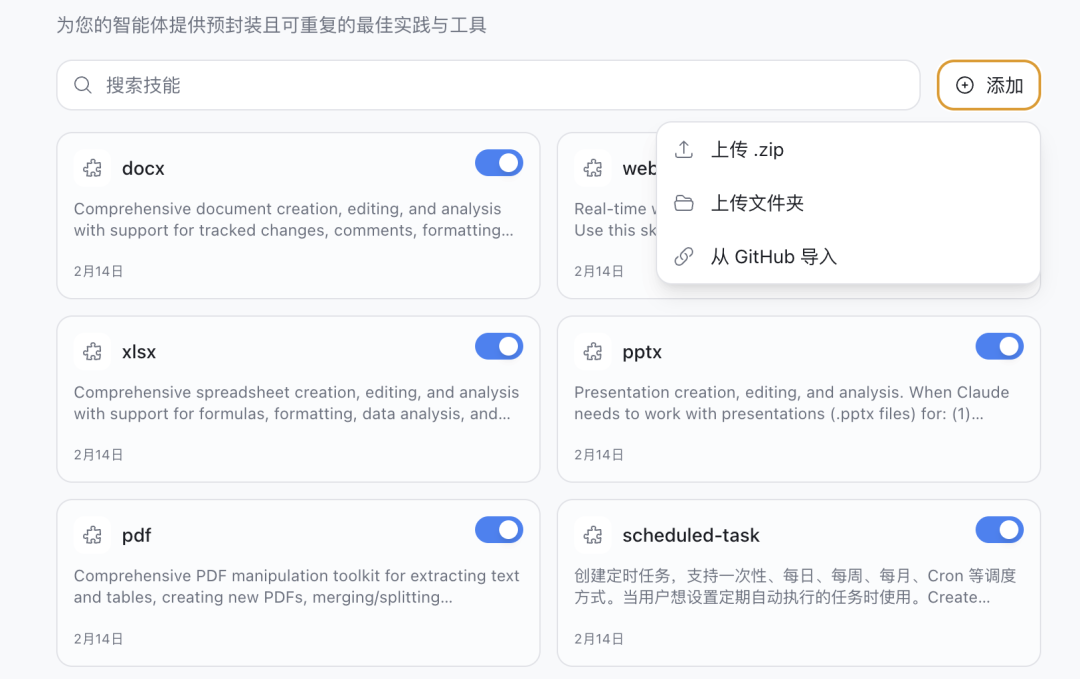
Skills 的管理方式会影响 Agent 能力扩展的成本:
| 导入方式 | 适合场景 |
|---|---|
| 本地文件夹 | 自己开发或修改过的 Skill |
| ZIP 包 | 离线分发、团队内部共享 |
| GitHub URL | 安装开源 Skill 集合 |
| ClawHub | 直接查找已有能力,减少手写工具代码 |
当信息源越来越多时,不建议把所有逻辑都塞进一个大提示词。更好的结构是:用 Skill 负责获取和标准化数据,用模型负责判断、归纳和生成结果。
场景一:每天自动整理 Reddit 高质量帖子
Reddit 的价值在评论区和细分社区里,但它的信息结构对持续跟踪并不友好。一个帖子下面可能套着大量评论,评论里又会引用其他帖子或外部链接;不同 subreddit 的规则也不同,光靠浏览推荐流很容易错过真正有价值的讨论。
适合交给 Agent 的任务是:每天固定读取指定 subreddit,挑出高质量帖子,过滤掉低价值内容,再把摘要推送出来。
可以安装 Reddit 只读 Skill,例如:
Reddit (read only - no auth)
任务提示词可以这样写:
任务:每天整理 Reddit 指定社区里的高质量帖子。
信息源:
- https://www.reddit.com/r/LocalLLaMA/
筛选要求:
- 优先选择讨论质量高、信息密度高、评论区有实质经验的帖子。
- 忽略梗图、纯情绪表达、重复新闻和低质量转发。
- 如果帖子里出现工具、模型、论文或项目,请提取名称、链接和核心用途。
- 摘要时同时说明:帖子在讨论什么、评论区有什么关键补充、这件事为什么值得关注。
记忆要求:
- 为 Reddit 摘要建立独立记忆。
- 每次发送摘要后,询问我是否喜欢这次列表。
- 根据我的反馈更新筛选规则,例如增加或减少某类帖子。
执行时间:
- 每天下午 5 点运行一次。
输出:
- 生成 Markdown 摘要。
- 同步发送到我指定的消息渠道。
这个任务的关键不是一次性写出“完美提示词”,而是让 Agent 持续记录偏好。比如连续几次反馈“不想看梗图”“更关注本地部署经验”“少放模型发布新闻”,它就应该把这些偏好沉淀为规则。
整个流程可以画成这样:
sequenceDiagram
participant Scheduler as 定时任务
participant Skill as Reddit Skill
participant Model as 大语言模型
participant Memory as 偏好记忆
participant Channel as 消息渠道
Scheduler->>Skill: 每天下午 5 点读取 subreddit
Skill-->>Model: 返回帖子、评论、链接
Model->>Memory: 读取历史偏好
Memory-->>Model: 返回筛选规则
Model-->>Channel: 发送摘要
Channel-->>Model: 用户反馈喜欢/不喜欢
Model->>Memory: 更新偏好规则
这样跑几天之后,摘要质量会越来越接近个人口味,而不是每次都从零开始筛选。
场景二:调查最近 30 天社区需求
普通搜索更擅长找已经整理好的资料,Deep Research 更擅长围绕明确问题做长报告。社区需求挖掘不太一样,它要从近期讨论里找“反复被抱怨、反复被询问、还没有好工具解决”的问题。
这类任务可以用 skill last 30 days 这种思路来做:限定最近 30 天,读取 Reddit、X、GitHub Issue、论坛讨论等信息源,归纳社区真实需求。
示例提示词:
任务:调查最近 30 天 AI 开发者社区反复出现的问题和需求。
信息源:
- Reddit
- X
- GitHub Issues
- 基础网页搜索
分析要求:
- 找出被多次提到的问题,不要只列热门新闻。
- 每个问题需要给出证据:出现在哪些讨论里,用户具体抱怨什么。
- 判断这个问题是否适合做成小工具、网页应用或自动化脚本。
- 如果适合做产品原型,请给出最小可行功能列表。
输出格式:
1. 需求名称
2. 典型用户
3. 高频痛点
4. 证据来源
5. 可做的解决方案
6. 最小可行产品功能
7. 风险或已有竞品
这个任务的价值在于把“刷信息流”变成结构化输入。模型不是简单总结新闻,而是把社区里的碎片抱怨整理成需求清单。
如果再接一个代码生成或原型生成 Skill,就能形成更完整的链路:
flowchart TD
A[读取最近 30 天社区讨论] --> B[聚类相似问题]
B --> C[筛出高频痛点]
C --> D[生成需求报告]
D --> E{是否适合做小工具}
E -- 否 --> F[归档观察]
E -- 是 --> G[生成 MVP 功能列表]
G --> H[创建 mini app 原型]
这类任务不适合完全无人值守发布产品,但很适合做“选题雷达”。它能告诉你最近开发者在为什么事情花时间、哪里反复卡住、哪些问题已经有人愿意讨论甚至付费解决。
场景三:科技新闻聚合与去重
RSS 订阅、社交平台、GitHub Trending、公司博客、YouTube、搜索引擎,本质上都在提供信息流。问题是这些信息源之间高度重复,同一条新闻可能被多个账号、多个媒体、多个仓库同时转发。
新闻聚合 Agent 要解决三个问题:
- 多来源读取。
- 相似内容去重。
- 按主题生成可读摘要。
可以从 ClawHub 安装类似 tech-news-digest 的 Skill,然后设置每天早上运行。
任务:每天早上 9 点生成科技新闻摘要。
发送位置:
- Discord 的 #tech-news 频道
- 我的邮箱
要求:
- 合并重复新闻。
- 标出重要来源。
- 按 AI、开源、开发工具、公司动态等主题分类。
- 对每条新闻给出 2 到 4 句摘要。
这类 Skill 通常需要配置 API Key(Application Programming Interface Key,应用程序接口密钥)。例如 X、Brave Search、GitHub、邮箱发送服务等。
桌面端的配置界面能减少环境变量管理的复杂度。相比手动编辑 .env 文件,图形界面更适合检查哪些密钥缺失、哪些连接器还没授权、哪个发送渠道没有配置成功。
如果已有默认信息源,还可以继续追加自定义来源:
Add these to my tech digest sources:
- RSS: https://openai.com/news/rss.xml
- X: @aiwarts
- GitHub: LearnPrompt/LearnPrompt
新闻聚合任务适合稳定运行,但要注意 token 成本。信息源越多、去重和摘要越细,模型调用成本越高。可以用一个简单策略控制成本:
| 阶段 | 推荐模型策略 |
|---|---|
| 抓取与清洗 | 规则代码或低成本模型 |
| 去重与分类 | 中等成本模型 |
| 重要新闻解读 | 强推理模型 |
| 格式化输出 | 低成本模型 |
不要让强模型处理所有原始信息。更合理的做法是先用 Skill 和规则过滤掉明显无用内容,再把浓缩后的候选列表交给强模型分析。
LobsterAI 适合哪些任务
LobsterAI 的优势集中在“长期运行、需要工具、需要跨平台输出”的 Agent 任务上。
| 适合使用 | 原因 |
|---|---|
| 每日 Reddit / X 摘要 | 有固定信息源、固定时间、固定输出格式 |
| 技术新闻聚合 | 需要多来源读取、去重、分类和推送 |
| 社区需求挖掘 | 需要读取近期讨论并归纳高频痛点 |
| 团队信息日报 | 需要发送到飞书、钉钉、Discord 或邮箱 |
| 个人知识库更新 | 可以把结果写入本地 Markdown |
| 多模型任务编排 | 复杂分析和简单整理可以使用不同模型 |
也有一些场景不适合强行使用桌面 Agent:
| 不适合使用 | 原因 |
|---|---|
| 一次性搜索 | 直接用搜索引擎或聊天窗口更快 |
| 严格离线环境 | 多数模型和信息源依赖网络 |
| 对数据合规要求极高 | 需要先审查模型供应商、日志、密钥和本地权限 |
| 预算很低的大规模抓取 | 高频抓取和长摘要会消耗大量 token |
| 结果必须 100% 准确 | Agent 摘要仍需要人工校验关键事实 |
上手配置顺序
比较稳的配置顺序是从低风险任务开始,不要一开始就让 Agent 拿到大量本机权限。
flowchart TD
A[安装 LobsterAI] --> B[配置模型供应商]
B --> C[开启 VM 沙箱]
C --> D[连接一个消息渠道]
D --> E[导入只读 Skill]
E --> F[创建低风险定时任务]
F --> G[观察运行日志和输出质量]
G --> H[逐步增加本地文件权限或更多 API Key]
可操作步骤:
- 安装 LobsterAI,并确认 OpenClaw 运行环境正常。
- 配置至少两个模型:一个用于复杂分析,一个用于低成本整理。
- 默认启用 VM 沙箱。
- 先连接 Discord、Telegram、飞书、钉钉或邮箱中的一个渠道。
- 导入只读 Skill,例如 Reddit 读取或 RSS 聚合。
- 创建一个简单的定时任务,例如每天一次摘要。
- 连续观察几天,调整提示词和记忆规则。
- 再开放本地 Markdown 写入、GitHub API、搜索 API 等更高权限能力。
常见坑和处理方式
1. 不要把所有任务都交给最贵的模型
信息流任务通常分为抓取、清洗、去重、摘要、分析、格式化几个阶段。只有分析和判断阶段真正需要强模型。
更省成本的拆法:
抓取:Skill / API / 浏览器
清洗:规则代码
去重:低成本模型或相似度算法
摘要:中等模型
深度判断:强模型
格式化:低成本模型
2. 定时任务要有失败提示
长期任务一定会遇到网络失败、API 限额、登录过期、页面结构变化等问题。任务配置里最好要求 Agent 在失败时发送简短错误报告,而不是静默失败。
如果任务失败,请发送错误摘要,包含:
- 失败阶段
- 可能原因
- 是否需要我重新授权
- 下一次是否会自动重试
3. 记忆要分任务维护
Reddit 摘要、科技新闻、产品需求挖掘,不应该共用同一套偏好。否则一个任务里的偏好可能污染另一个任务。
推荐记忆拆分方式:
| 记忆名称 | 用途 |
|---|---|
| reddit_digest_preferences | Reddit 摘要偏好 |
| tech_news_sources | 科技新闻来源与分类规则 |
| product_research_rules | 需求挖掘筛选标准 |
| delivery_preferences | 输出渠道与格式要求 |
4. 本地权限要最小化
只有确实需要读写本机文件时,才给 Agent 开本地权限。能在 VM 沙箱里完成的任务,就不要切到本地运行。
一个安全边界清晰的配置通常是:
默认:VM 沙箱
允许访问:临时目录、浏览器、公开网页
禁止访问:全盘文件、系统配置、敏感目录
例外:指定知识库目录可写入 Markdown
5. 摘要任务要明确“不要什么”
很多信息流摘要质量差,不是因为模型不会总结,而是没有写清楚过滤规则。提示词里除了说明想看什么,也要明确排除什么。
例如:
不要包含:
- 梗图
- 无实质信息的转发
- 只有标题没有讨论的新闻
- 重复发布的同一项目
- 纯营销内容
- 没有链接来源的传闻
桌面 Agent 的价值在于持续运行
LobsterAI 这类桌面端工具改变的不是单次问答,而是长期任务的组织方式。过去需要手动打开 Reddit、X、RSS、GitHub、邮箱和聊天窗口,现在可以把流程拆成 Skills、定时任务、记忆、沙箱和连接器,让 Agent 按固定节奏读取信息、整理内容、推送结果,并根据反馈逐步调整筛选标准。
适合从一个小任务开始:每天整理一个 subreddit,或者每天早上生成一次科技新闻摘要。等任务稳定后,再增加更多信息源、更多输出渠道和更复杂的分析步骤。这样搭起来的信息流 Agent,才不会只是一个会聊天的窗口,而是一个能持续工作的个人信息处理系统。