大语言模型(Large Language Model,LLM)驱动的 Agent 系统经常会遇到一个矛盾:我们希望一个 Agent 掌握很多能力,但一次对话通常只会用到其中很少一部分,而模型上下文窗口又是有限资源。
客服 Agent 是一个典型例子。它可能需要处理订单查询、退款申请、支付异常、产品推荐、技术支持、投诉升级等问题,可用户一次咨询大概率只涉及一个小范围场景。如果把所有业务流程、接口说明、异常处理规则都写进 System Prompt,Agent 启动时就会背上大量无关上下文,既浪费 token,也容易干扰模型判断。
Skill 机制解决的正是这个问题:让 Agent 启动时只知道“有哪些能力”,真正需要执行某个能力时,再加载对应的操作流程、参考资料和脚本。
多能力 Agent 的上下文加载困境
常见做法有三类:全量加载、多 Agent 拆分、RAG(Retrieval-Augmented Generation,检索增强生成)。它们各自能解决一部分问题,但也都有明显边界。
| 方案 | 做法 | 优点 | 主要问题 |
|---|---|---|---|
| 全量加载 | 把所有领域知识提前放进 System Prompt | 实现最简单,没有额外调度机制 | 上下文占用大,领域越多越难扩展,无关知识会干扰模型 |
| 多 Agent 架构 | 每个 Agent 负责一个专业领域,并加载自己的领域知识 | 不同领域的上下文可以隔离 | 每个子 Agent 内部仍然可能是全量加载,且需要路由、转接、协作机制 |
| RAG | 根据用户问题从知识库动态检索片段 | 灵活,适合大量非结构化知识 | 对流程性知识不友好,容易检索到碎片,漏掉前置条件或完整步骤 |
这个问题不只是“上下文太短”。更准确地说,是缺少一种介于“全量塞入”和“碎片检索”之间的加载机制。
可以从三个维度理解:
| 维度 | 需要什么能力 | 传统方案的问题 |
|---|---|---|
| 空间维度 | 区分必需知识和潜在知识 | 全量加载把暂时不用的知识也放进上下文 |
| 时间维度 | 根据任务阶段按需加载 | 很多方案只能在启动时加载,或在执行中零散检索 |
| 结构维度 | 保持流程知识的完整性 | RAG 可能只召回某几个段落,导致 SOP 被切碎 |
理想状态下,Agent 不需要一开始记住所有手册细节,只要先掌握目录:退款问题对应退款处理手册,订单问题对应订单处理手册,支付问题对应支付异常手册。等用户真的问到订单物流,再加载完整的订单处理流程;如果过程中碰到某个错误码,再进一步读取错误码对照表。
这就是渐进式披露(Progressive Disclosure)的思路。
Skill 是什么
Skill 可以理解为一个独立、可复用的能力单元。它把“什么时候用”“怎么做”“需要哪些支撑材料”封装在一起,让 Agent 可以按需加载。
一个 Skill 通常包含三类内容。
| 组成部分 | 作用 | 示例 |
|---|---|---|
| 结构化指令 | 描述触发条件、执行步骤、可用资源 | 订单查询 SOP、退款审核流程、数据分析步骤 |
| 资源文件 | 提供详细参考材料 | API 文档、错误码说明、模板文件、配置样例 |
| 可执行脚本 | 处理确定性任务 | 数据校验脚本、格式转换脚本、外部系统调用封装 |
其中,结构化指令一般写在 SKILL.md 中,内容可以用 Markdown 表达。Markdown 对模型比较友好,也方便人维护。
一个典型 Skill 目录如下:
skill-name/
├── SKILL.md # 必需:元数据和主要指令
├── references/ # 可选:详细参考文档
│ └── api-doc.md
├── scripts/ # 可选:可执行脚本
│ └── process.py
└── assets/ # 可选:模板、样例、静态资源
└── template.html
SKILL.md 至少需要包含名称和描述:
---
name: order_processing
description: 处理订单查询、订单修改、订单取消、物流状态跟踪等问题
---
# 订单处理流程
## 适用场景
当用户咨询订单状态、物流进度、订单取消、地址修改时使用。
## 查询订单
1. 提取订单号。
2. 调用订单查询接口。
3. 根据订单状态给出不同回复:
- 待支付:提示用户完成支付。
- 已发货:返回物流信息。
- 已完成:询问是否需要售后服务。
这里最关键的是 description。Agent 启动时通常不会立即加载完整的 SKILL.md,而是先读取每个 Skill 的名称和描述,用它们判断“当前任务是否需要这个 Skill”。
渐进式披露:三层上下文加载
渐进式披露把 Skill 的加载过程拆成三层:元数据、指令、资源。
图中的关键点是:Agent 不会在启动时加载所有细节,而是随着任务推进逐层展开。第一层只让模型知道有哪些 Skill;第二层在命中特定任务后加载完整 SOP;第三层只在执行到具体细节时读取参考文件或调用脚本。
flowchart TD
A[Agent 启动] --> B[加载 Skill 元数据]
B --> C{用户问题需要哪个 Skill}
C -->|命中订单处理| D[加载 order_processing 的 SKILL.md]
C -->|命中支付处理| E[加载 payment_processing 的 SKILL.md]
D --> F{执行中是否需要资源}
F -->|需要错误码说明| G[加载 references/error-codes.md]
F -->|需要校验订单号| H[执行 scripts/validate.py]
G --> I[生成回答]
H --> I
三层加载的差异可以这样理解:
| 层级 | 加载时机 | 加载内容 | 上下文成本 | 作用 |
|---|---|---|---|---|
| 第一层:元数据 | Agent 启动时 | Skill 名称、描述、标识符 | 很低 | 让 Agent 知道有哪些能力 |
| 第二层:指令 | 判断需要某个 Skill 时 | 完整 SKILL.md | 中等 | 让 Agent 掌握完整操作流程 |
| 第三层:资源 | 执行流程中按需触发 | 参考文档、模板、脚本 | 按需增加 | 补充细节或完成确定性操作 |
这种机制比全量加载节省上下文,也比普通 RAG 更适合流程性知识。因为第二层加载的是完整 SOP,而不是被向量检索切碎的若干段落。
用订单处理理解三层加载过程
订单处理场景可以很好地说明 Skill 的工作方式。
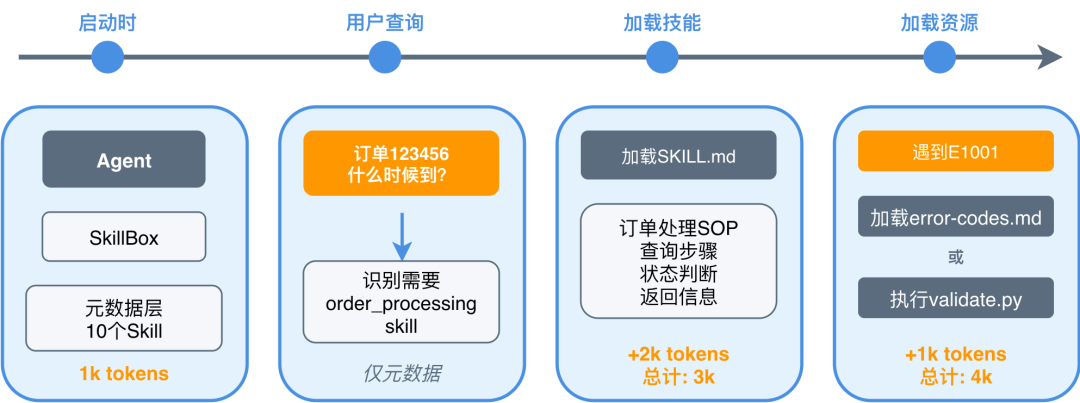
图中展示了从“知道订单处理能力存在”,到“加载订单处理流程”,再到“读取错误码说明或执行脚本”的完整链路。它不是一次性把所有订单、支付、推荐、售后知识塞给模型,而是让 Agent 跟随任务逐步扩展上下文。
第一层:启动时只加载 Skill 元数据
Agent 启动时,上下文中只放 Skill 列表:
skills:
- name: order_processing
description: 处理订单查询、订单修改、订单取消、物流状态跟踪等问题
- name: payment_processing
description: 处理支付状态查询、退款申请、支付失败排查等问题
- name: product_recommendation
description: 处理商品推荐、库存查询、相似商品对比等问题
假设每个 Skill 的元数据约 100 tokens,10 个 Skill 只需要约 1000 tokens。此时 Agent 只是知道“有哪些能力可用”,还不知道每个能力的详细执行步骤。
第二层:命中任务后加载完整指令
用户问:
订单 123456 什么时候到?
Agent 根据描述判断需要 order_processing,再加载该 Skill 的完整 SKILL.md:
# 订单处理标准流程
## 查询订单
1. 调用 `queryOrder(orderId)` 获取订单详情。
2. 判断订单状态:
- 待支付:提供支付入口,并提醒支付时限。
- 待发货:告知预计发货时间。
- 已发货:返回物流公司、运单号和最新物流节点。
- 已完成:确认是否需要售后服务。
## 修改地址
前置条件:订单状态必须是「待发货」。
步骤:
1. 校验订单号格式。
2. 查询订单状态。
3. 校验新地址是否完整。
4. 调用地址修改接口。
5. 返回修改结果。
## 可用资源
- `references/error-codes.md`:错误码对照表。
- `scripts/validate.py`:订单号校验脚本。
这一步加载的是完整流程,因此模型不会只看到“调用订单接口”这个片段而漏掉“修改地址必须待发货”这样的前置条件。
第三层:执行中再加载参考资料或脚本
如果订单接口返回错误码 E1001,Agent 可以继续读取错误码说明:
# 错误码对照表
- E1001:订单不存在,请检查订单号。
- E1002:订单状态不允许修改。
- E1003:地址格式不正确。
如果需要做订单号格式校验,可以调用脚本,而不是让 LLM 临时生成校验逻辑:
# scripts/validate.py
def validate_order_id(order_id: str) -> dict:
if not order_id.isdigit():
return {"valid": False, "reason": "订单号只能包含数字"}
if len(order_id) not in (6, 12, 18):
return {"valid": False, "reason": "订单号长度不符合规则"}
return {"valid": True, "order_type": "standard"}
脚本执行的结果很短:
{
"valid": true,
"order_type": "standard"
}
参考文档会进入上下文,脚本本身不一定需要进入上下文,Agent 只需要拿到执行结果。这对上下文控制很重要:确定性逻辑交给代码,推理和对话交给模型。
AgentScope-Java 中的 Skill 抽象
原生 Skill 机制通常按文件系统组织。这个方式直观,但在云环境、容器环境、远程存储场景下不够灵活。如果 Agent 必须直接访问磁盘文件,Skill 的发现、加载、分发都会受部署形态限制。
AgentScope-Java 把 Skill 抽象成对象,并提供 Repository 层。文件系统仍然可以作为一种组织方式,但不再是唯一来源。Skill 内容可以来自本地目录,也可以来自数据库、对象存储或远程服务。
flowchart LR
A[文件系统 / 数据库 / 远程 API] --> B[AgentSkillRepository]
B --> C[AgentSkill]
C --> D[SkillBox]
D --> E[ReActAgent]
E --> F[System Prompt 元数据披露]
E --> G[Tool 加载 Skill 内容和资源]
创建 AgentSkill 对象
假设有一个数据分析 Skill:
data_analysis/
├── SKILL.md
├── references/
│ └── api-doc.md
└── scripts/
└── process.py
可以直接构造 AgentSkill:
AgentSkill skill = AgentSkill.builder()
.name("data_analysis")
.description("Use when analyzing tabular data, generating statistics, or creating data reports.")
.skillContent("""
# Data Analysis
## When to use
Use this Skill when the user asks for data profiling, aggregation,
visualization suggestions, or report generation.
## Steps
1. Inspect the input data schema.
2. Identify missing values and abnormal values.
3. Generate summary statistics.
4. Return conclusions with reproducible steps.
""")
.addResource("references/api-doc.md", """
# Data Analysis API
## summarize(data)
Returns row count, column count, missing value ratio,
and basic statistics for numeric columns.
""")
.addResource("scripts/process.py", """
def process(data):
return {
"rows": len(data),
"columns": list(data[0].keys()) if data else []
}
""")
.build();
这种对象化方式把 Skill 的逻辑结构和物理存储解耦。上层 Agent 不需要关心内容来自文件、数据库还是远程接口。
通过 Repository 批量加载 Skill
文件系统仍然是最常用的 Skill 管理方式,可以用 FileSystemSkillRepository 读取目录:
AgentSkillRepository fileRepo =
new FileSystemSkillRepository(Path.of("./skills"));
AgentSkill skill = fileRepo.getSkill("data_analysis");
SkillBox skillBox = new SkillBox(new Toolkit());
skillBox.registerSkill(skill);
保存 Skill 也可以走 Repository:
fileRepo.save(List.of(skill), false);
只要实现同一套 Repository 接口,后续就可以切换到其他后端存储,例如数据库或远程 API。Agent 与 Skill 存储方式之间不再强绑定。
第一层披露:通过 System Prompt 暴露元数据
在 AgentScope-Java 中,Skill 需要注册到 SkillBox,再由 Agent 持有这个 SkillBox。
Toolkit toolkit = new Toolkit();
SkillBox skillBox = new SkillBox(toolkit);
skillBox.registerSkill(skill);
ReActAgent agent = ReActAgent.builder()
.name("Assistant")
.model(model)
.skillBox(skillBox)
.toolkit(toolkit)
.build();
注册完成后,Agent 的 System Prompt 中会注入 Skill 使用说明和元数据。模型看到的是类似这样的结构:
<available_skills>
<skill>
<name>data_analysis</name>
<description>Use when analyzing tabular data, generating statistics, or creating data reports.</description>
<skill-id>data_analysis</skill-id>
</skill>
</available_skills>
这就是第一层披露。模型知道 data_analysis 存在,也知道它大概适用于什么任务,但还没有加载完整数据分析流程和资源文件。
第二层和第三层披露:通过 Tool 加载内容
当模型判断当前任务需要某个 Skill 时,会调用自动注册的 Tool,例如 load_skill_through_path。
加载主指令:
load_skill_through_path(
skillId = "data_analysis",
path = "SKILL.md"
)
加载参考文档:
load_skill_through_path(
skillId = "data_analysis",
path = "references/api-doc.md"
)
加载脚本内容:
load_skill_through_path(
skillId = "data_analysis",
path = "scripts/process.py"
)
这个设计有两个好处:
- Agent 不需要在启动时拿到所有 Skill 的完整内容。
- Skill 内部资源可以继续保持目录结构,方便复用已有 Skill 生态。
调用关系可以表示为:
sequenceDiagram
participant U as 用户
participant A as Agent
participant S as SkillBox
participant T as load_skill_through_path
U->>A: 请分析这份数据并生成统计摘要
A->>A: 根据 Skill 元数据判断需要 data_analysis
A->>T: 加载 data_analysis/SKILL.md
T->>S: 读取 Skill 主指令
S-->>T: 返回 SKILL.md 内容
T-->>A: 注入数据分析流程
A->>T: 按需加载 references/api-doc.md
T-->>A: 返回 API 说明
A-->>U: 按流程生成分析结果
Tool 也可以跟随 Skill 渐进式披露
除了文档和脚本,AgentScope-Java 还支持把 Tool 绑定到 Skill。这里的 Tool 可以是 MCP(Model Context Protocol,模型上下文协议)工具,也可以是 Function Calling 工具。
关键规则是:Skill 未激活时,绑定的 Tool 不出现在 Agent 工具列表中;Skill 被激活后,相关 Tool 才对模型可见。
skillBox.registration()
.skill(dataSkill)
.tool(new DataAnalysisTool())
.apply();
这样可以减少工具列表膨胀。多能力 Agent 如果一次性暴露几十个甚至上百个 Tool,模型选择工具的难度会明显增加,也更容易误调用。把 Tool 跟 Skill 绑定后,模型只需要先选择 Skill,再在该 Skill 的上下文中使用少量相关工具。
flowchart TD
A[Agent 启动] --> B[只暴露 Skill 元数据]
B --> C{是否激活 data_analysis}
C -->|否| D[DataAnalysisTool 不可见]
C -->|是| E[加载 data_analysis 指令]
E --> F[DataAnalysisTool 自动可见]
F --> G[模型调用工具完成任务]
Skill 脚本的执行问题
AgentScope-Java 中,Skill 资源可以存储在内存里。这对分发很友好:一个 Skill 对象就能携带指令、参考资料和脚本内容。但脚本真正执行时,操作系统通常需要文件路径,例如执行:
python3 scripts/process.py
如果脚本只存在于内存,Shell 无法直接运行它。解决方式是启用 SkillBox.codeExecution(),把指定资源输出到工作目录,再通过受控 Shell 执行。
ShellCommandTool customShell = new ShellCommandTool(
null, // baseDir 会被自动设置为 workDir
Set.of("python3", "node", "npm"), // 命令白名单
command -> askUserApproval(command) // 可选:命令审批回调
);
skillBox.codeExecution()
.workDir("/path/to/workdir")
.includeFolders("scripts/", "assets/")
.includeExtensions(".py", ".js", ".sh")
.withShell(customShell)
.withRead()
.withWrite()
.enable();
这里有几个安全控制点:
| 配置 | 作用 |
|---|---|
workDir | 指定脚本和资源落盘目录 |
includeFolders | 只输出指定目录下的资源 |
includeExtensions | 只允许指定扩展名文件参与代码执行 |
| 命令白名单 | 限制可执行命令,例如只允许 python3、node |
| 审批回调 | 高风险命令执行前由外部逻辑确认 |
更安全的做法是把 workDir 指向 Docker 容器挂载的目录,让 Skill 脚本在容器内执行。这样既能保持 Skill 打包分发的便利性,又能用容器隔离降低代码执行风险。
flowchart LR
A[Skill 内存资源] --> B[写入 workDir]
B --> C[Docker 挂载卷]
C --> D[容器内执行脚本]
D --> E[返回执行结果]
E --> F[Agent 继续推理]
Skill 适合解决哪些问题
Skill 最适合处理“领域多、流程多、单次只用少量能力”的 Agent 应用。
| 场景 | Skill 的价值 |
|---|---|
| 客服系统 | 订单、退款、支付、售后等流程可以拆成多个 Skill,按用户问题加载 |
| 代码助手 | 不同框架、语言、部署平台可以各自维护 Skill |
| 数据分析助手 | 分析流程写进 SOP,复杂计算交给脚本 |
| 企业内部助理 | 报销、请假、采购、权限申请等流程经常调整,更新 Skill 文件即可 |
| 技术支持 Agent | 故障排查步骤需要完整保留,避免被检索切碎 |
它也适合和其他技术组合:
| 组合方式 | 用法 |
|---|---|
| Skill + RAG | Skill 放结构化 SOP,RAG 查非结构化背景资料 |
| Skill + Multi-Agent | Skill 提供领域能力,多 Agent 隔离复杂运行时上下文 |
| Skill + 长上下文 | 多领域按需加载,单领域任务中再进行深度分析 |
| Skill + Tool Calling | Skill 控制工具可见性,降低工具选择噪声 |
Skill 的边界
Skill 不是所有 Agent 问题的统一解法,它主要优化的是启动上下文和流程性知识加载。
只能隔离启动上下文,不能隔离运行时上下文
多个 Skill 被加载后,内容仍然会进入同一个 Agent 的上下文窗口。如果一次任务连续激活订单、退款、支付、投诉等多个 Skill,模型推理时还是要同时面对多个领域知识。
需要强隔离时,多 Agent 架构仍然有价值。Skill 更像是让单个 Agent 的能力扩展更轻量,而不是替代所有 Agent 编排。
Skill 触发依赖模型判断
Skill 是否加载,取决于 LLM 对 description 的理解。不同模型的判断能力不同,触发准确率也会有差异。
为了提高命中率,Skill 描述应该写清楚:
description: >
Use when the user asks about order status, delivery tracking,
order cancellation, address modification before shipment,
or order-related error messages.
不要写得过于抽象:
description: Handle order things.
过短描述会让模型缺少判断依据,过长描述又会增加第一层元数据成本。比较好的方式是列出典型触发场景和边界条件。
Skill 没有天然优先级
如果多个 Skill 的描述都可能匹配用户问题,模型需要自己判断使用哪一个。业务上“更重要”或“更高频”的 Skill,不会自动获得更高优先级。
可以通过描述设计缓解冲突,例如:
name: refund_processing
description: >
Use for refund application, refund status, refund rejection,
and refund policy questions. Do not use for order cancellation
before payment; use order_processing instead.
把排除条件写进描述,有助于模型减少误选。
高频 Skill 可能不适合每次按需加载
如果某个 Skill 几乎每轮对话都会用,反复通过 Tool 加载反而会增加延迟。此时可以把高频、短小、稳定的规则压缩后直接放进 System Prompt,把低频、长尾、复杂的流程放进 Skill。
| 知识类型 | 推荐放置位置 |
|---|---|
| 高频、短小、稳定 | System Prompt |
| 低频、较长、流程性强 | Skill |
| 大量非结构化资料 | RAG 知识库 |
| 需要确定性执行 | Skill 脚本或 Tool |
对深度推理任务帮助有限
数学证明、复杂算法设计、长篇代码架构推演这类任务,核心瓶颈通常不是“流程知识太多”,而是模型需要持续保留大量中间推理状态。Skill 可以提供背景材料和工具,但不能替代长上下文或专门的推理策略。
实践建议
设计 Skill 时,可以遵循几条原则。
-
一个 Skill 只覆盖一个清晰领域
不要把订单、退款、支付、售后都塞进一个巨大 Skill。Skill 太大后,第二层加载又会变成局部全量加载。 -
description写触发条件,不写宣传语
描述应该帮助模型判断何时使用,而不是泛泛描述能力强大。 -
SOP 保持完整,参考资料按需拆分
主流程放进SKILL.md,细节资料放进references/。这样第二层能保证流程连贯,第三层又能控制上下文成本。 -
确定性逻辑交给脚本或 Tool
校验、转换、计算、外部系统调用不适合完全依赖 LLM 生成。脚本结果通常比自然语言指令更稳定。 -
为脚本执行设置边界
启用命令白名单、审批回调、工作目录隔离,并优先使用容器沙箱。 -
定期检查 Skill 命中情况
如果某些 Skill 经常被误触发,通常要调整名称、描述或拆分边界。
参考资料
- AgentScope-Java Skill 使用指南:https://java.agentscope.io/en/task/agent-skill.html
- Integrate Skills:https://agentskills.io/integrate-skills
- Equipping Agents for the Real World with Agent Skills:https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills