FunctionGemma 是面向函数调用优化的 Gemma 3 270M 模型版本,适合用在智能体场景里,把用户的自然语言请求转换成可执行的 API(应用程序编程接口)调用。
普通聊天模型擅长回答问题,但智能体需要更进一步:它不仅要理解用户想做什么,还要判断应该调用哪个工具、传什么参数、什么时候不该闲聊而应该执行动作。FunctionGemma 的价值就在这里,它把“说话”推进到“行动”。
一个典型工具调用链路大致是这样:
flowchart LR
A[用户输入自然语言] --> B[FunctionGemma 理解意图]
B --> C{选择工具}
C --> D[生成函数名]
C --> E[生成函数参数]
D --> F[业务系统执行 API]
E --> F
F --> G[返回执行结果]
不过,基础模型并不会天然理解每个公司的业务规则。比如用户问“差旅餐饮的报销限额是多少?”,从语言表面看,这是一个信息查询问题;但在企业环境里,它不应该去公开搜索,而应该查内部知识库。要让模型学会这种规则,就需要对工具调用行为做微调。
为什么工具调用还需要微调
FunctionGemma 已经具备函数调用能力,但“能调用函数”和“能按业务策略正确调用函数”不是一回事。
通用模型通常从公开数据中学习语言规律,它可以推断“这个问题像搜索问题”,却不知道某些问题必须走内部系统,也不知道某些工具之间的优先级。微调的目的,就是把这些业务语境和策略写进模型行为里。
常见需求可以分成三类:
| 需求 | 例子 | 微调要解决的问题 |
|---|---|---|
| 消除工具选择歧义 | “差旅策略是什么?”应该查内部知识库,而不是搜索互联网 | 让模型在相似工具之间选择正确工具 |
| 适配专有任务 | 控制移动设备功能、解析内部 API、生成监管报告 | 让模型学习公开数据里没有的工具格式和参数规则 |
| 模型蒸馏 | 用大模型生成训练样本,再微调小模型 | 用更小、更快的模型承载固定业务流程 |
工具调用微调不是为了让模型“知道更多知识”,而是让模型在给定工具集合中学会稳定路由。
案例:在内部知识库和 Google 搜索之间做选择
假设系统里有两个搜索工具:
search_knowledge_base:查询企业内部文档search_google:查询公开互联网信息
用户输入不同,模型应该选择不同工具:
| 用户问题 | 正确工具 | 原因 |
|---|---|---|
| 使用 Python 编写简单递归函数的最佳实践是什么? | search_google | 这是公开技术知识 |
| 差旅餐饮的报销限额是多少? | search_knowledge_base | 这是内部政策 |
| 如何创建一个新的 Jira 项目? | search_knowledge_base | 这通常取决于企业内部流程 |
| 最新的 Python 版本有什么新特性? | search_google | 需要查询公开信息 |
这个任务看起来简单,但对模型来说有歧义。因为这些问题都像“搜索请求”,区别不在语法,而在业务语境。
工具路由逻辑可以画成这样:
flowchart TD
A[用户问题] --> B{是否涉及内部制度、流程、系统权限、企业工具}
B -- 是 --> C[调用 search_knowledge_base]
B -- 否 --> D{是否属于公开知识或互联网信息}
D -- 是 --> E[调用 search_google]
D -- 否 --> F[根据工具定义和上下文继续判断]
微调要做的事情,就是用足够多的样本让模型学会这条分界线。
数据集准备:让模型看到“问题”和“正确调用”
这个案例可以使用 bebechien/SimpleToolCalling 数据集。数据集中包含用户问题、工具名称和工具参数,适合训练模型在 search_knowledge_base 和 search_google 之间做选择。
训练样本需要被整理成对话格式。简化后的结构可以理解为:
{
"messages": [
{
"role": "user",
"content": "如何创建一个新的 Jira 项目?"
},
{
"role": "assistant",
"content": "<start_function_call>call:search_knowledge_base{query:<escape>Jira project creation process<escape>}<end_function_call>"
}
]
}
模型要学习的不是“Jira 是什么”,而是看到这类企业流程问题时,输出函数调用:
<start_function_call>call:search_knowledge_base{query:<escape>Jira project creation process<escape>}<end_function_call>
训练数据的处理流程如下:
flowchart LR
A[加载 SimpleToolCalling 数据集] --> B[转换为对话格式]
B --> C[划分训练集和测试集]
C --> D[训练集用于 SFT 微调]
C --> E[测试集用于评估未见样本]
D --> F[得到微调后的 FunctionGemma]
F --> E
示例代码:
from datasets import load_dataset
dataset = load_dataset("bebechien/SimpleToolCalling", split="train")
# 将原始样本转换成 FunctionGemma 所需的对话格式
dataset = dataset.map(
create_conversation,
remove_columns=dataset.features,
batched=False,
)
# 训练集和测试集各占 50%
dataset = dataset.train_test_split(
test_size=0.5,
shuffle=False,
)
这里使用 50/50 的训练集和测试集划分,是为了更明显地观察模型在大量未见样本上的变化。实际业务里更常见的是 80/20 或 90/10,具体比例取决于数据量和评估需求。
数据划分的坑:shuffle=False 不是永远安全
shuffle=False 只有在源数据已经充分混合时才适合使用。
如果数据本身已经随机分布,直接按顺序切分可以避免额外随机性,方便复现实验。但如果源数据是按类别排列的,比如前半部分全是 search_google,后半部分全是 search_knowledge_base,直接 shuffle=False 会造成严重问题:
flowchart LR
A[原始数据按类别排序] --> B[前半段 search_google]
A --> C[后半段 search_knowledge_base]
B --> D[训练集只看到 Google 搜索]
C --> E[测试集主要是内部知识库]
D --> F[模型没有学过如何区分两类工具]
F --> G[测试结果很差]
这种情况下,模型训练时没有见过完整分布,自然无法学会工具选择边界。
更稳妥的做法是:
dataset = dataset.train_test_split(
test_size=0.2,
shuffle=True,
seed=42,
)
选择是否打乱时,可以按这个表判断:
| 数据状态 | 推荐设置 | 原因 |
|---|---|---|
| 已确认预先随机混合 | shuffle=False 或 shuffle=True 都可以 | 不容易出现类别偏置 |
| 不知道数据是否混合 | shuffle=True | 更安全 |
| 明确按标签、工具、时间排序 | shuffle=True | 避免训练集和测试集分布不一致 |
| 时间序列预测任务 | 谨慎使用 shuffle=True | 时间顺序可能是任务的一部分 |
工具调用任务通常不是时间序列任务,优先保证每个工具类别都能出现在训练集中。
使用 TRL 做监督式微调
Hugging Face TRL 提供了 SFTTrainer,可以用来做 SFT(监督式微调,Supervised Fine-Tuning)。在这个任务里,监督信号非常明确:用户输入对应哪个函数调用。
训练时,模型会反复看到这样的配对:
用户:差旅餐饮的报销限额是多少?
助手:<start_function_call>call:search_knowledge_base{query:<escape>meal reimbursement limit for business travel<escape>}<end_function_call>
经过若干轮训练后,模型会调整参数,使类似问题更倾向于输出内部知识库调用,而不是泛化成普通搜索或聊天回答。
训练逻辑可以概括为:
sequenceDiagram
participant Data as 训练样本
participant Trainer as SFTTrainer
participant Model as FunctionGemma
participant Eval as 测试集评估
Data->>Trainer: 提供用户问题和目标函数调用
Trainer->>Model: 执行监督式微调
Model-->>Trainer: 返回训练损失
Trainer->>Eval: 在未见样本上测试工具选择
Eval-->>Trainer: 返回准确率和错误样本
在案例中,模型训练了 8 个周期。训练过程中的损失曲线可以用来判断模型是否正在学习新任务。
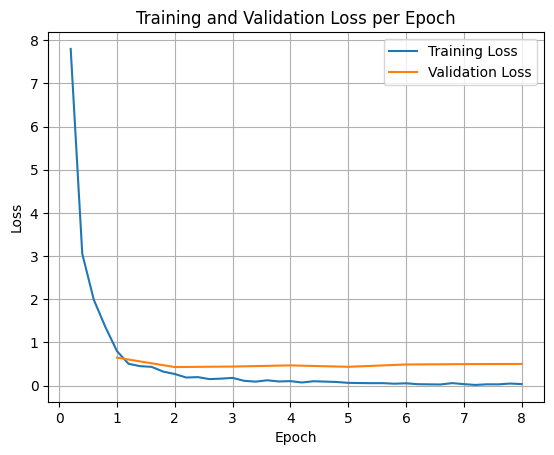
损失值在初期快速下降,说明模型很快捕捉到了新的工具路由规律。后续下降变慢则比较常见,因为模型已经学到主要模式,剩下的是对边界样本和格式细节的调整。
微调前,基础模型可能出现两类错误:
| 错误类型 | 表现 | 问题 |
|---|---|---|
| 选错工具 | 内部政策问题调用 search_google | 没有理解业务边界 |
| 不调用工具 | 直接解释“可以查看公司政策” | 没有遵守工具调用任务格式 |
微调后,当用户问:
如何创建一个新的 Jira 项目?
模型可以输出:
<start_function_call>call:search_knowledge_base{query:<escape>Jira project creation process<escape>}<end_function_call>
这说明模型学到的不是某个固定问题的答案,而是“企业内部流程类问题应该走内部知识库”的路由策略。
评估时不要只看训练损失
损失曲线下降只能说明模型在训练样本上学得更好了,不能单独证明它在真实场景里可靠。工具调用模型至少要检查三类指标:
| 指标 | 检查内容 | 示例 |
|---|---|---|
| 工具选择准确率 | 函数名是否正确 | search_knowledge_base 是否被误选成 search_google |
| 参数生成质量 | 参数字段是否完整、语义是否合理 | query 是否准确概括用户意图 |
| 格式合法性 | 输出是否能被解析器识别 | 是否包含正确的 <start_function_call> 和 <end_function_call> |
评估集必须和训练集分离。否则模型可能只是记住了训练样本,而不是真正学会路由规则。
实际落地时还可以加入更细的测试集:
| 测试集类型 | 用途 |
|---|---|
| 常规样本 | 检查基本工具选择能力 |
| 边界样本 | 检查模糊问题,比如“Python 报销脚本怎么写” |
| 对抗样本 | 检查用户诱导模型绕开内部工具的情况 |
| 格式样本 | 检查函数调用字符串是否稳定可解析 |
FunctionGemma Tuning Lab:不用写训练脚本的微调界面
如果不想手写 Python 训练脚本,可以使用 FunctionGemma Tuning Lab。它托管在 Hugging Face Spaces 上,提供了一个可视化界面,用来完成函数架构定义、数据上传、训练配置和评估。
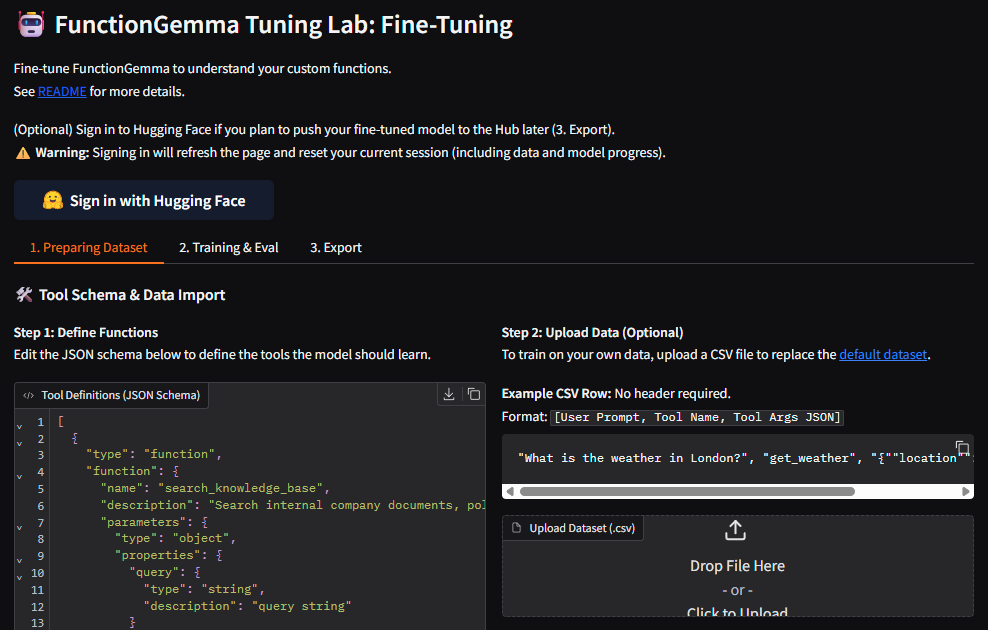
界面把微调流程拆成几个操作区:定义函数 schema、上传 CSV(逗号分隔值)训练数据、设置学习率和训练周期、启动训练、观察日志和损失曲线。对只想快速验证工具路由效果的场景来说,它可以省掉依赖安装、训练循环编写和评估脚本搭建的时间。
Tuning Lab 的核心能力如下:
| 功能 | 作用 |
|---|---|
| 无代码函数定义 | 直接用 JSON(JavaScript Object Notation)描述工具名称、参数和说明 |
| CSV 数据导入 | 上传用户提示词、目标工具名、工具参数 |
| 可视化训练配置 | 用界面设置学习率、训练周期等参数 |
| 实时训练日志 | 查看训练是否正常收敛 |
| 自动前后评估 | 对比微调前后的工具调用效果 |
一个工具 schema 可以写成类似结构:
[
{
"name": "search_knowledge_base",
"description": "Search internal company documents, policies, and procedures.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The internal knowledge base search query."
}
},
"required": ["query"]
}
},
{
"name": "search_google",
"description": "Search public web information.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The public web search query."
}
},
"required": ["query"]
}
}
]
CSV 数据可以按这种形式准备:
prompt,tool_name,arguments
"差旅餐饮的报销限额是多少?","search_knowledge_base","{""query"":""business travel meal reimbursement limit""}"
"使用 Python 编写递归函数有哪些最佳实践?","search_google","{""query"":""Python recursive function best practices""}"
"如何创建一个新的 Jira 项目?","search_knowledge_base","{""query"":""Jira project creation process""}"
这类数据不需要写成长篇回答,因为目标不是训练模型聊天,而是训练模型输出正确函数调用。
本地运行 FunctionGemma Tuning Lab
想在本地运行 Tuning Lab,可以使用 Hugging Face 的 hf CLI(命令行界面)下载 Space 代码。
安装并登录 Hugging Face CLI 后,执行:
hf download google/functiongemma-tuning-lab \
--repo-type=space \
--local-dir=functiongemma-tuning-lab
cd functiongemma-tuning-lab
pip install -r requirements.txt
python app.py
运行后,就可以在浏览器里打开本地界面,完成函数定义、数据上传和训练。
什么时候用 TRL,什么时候用 Tuning Lab
两种方式都能完成微调,但适合的场景不一样。
| 方式 | 适合场景 | 优点 | 代价 |
|---|---|---|---|
| TRL 训练脚本 | 需要接入现有训练流水线、做复杂数据处理、定制评估逻辑 | 灵活,可自动化,适合生产流程 | 需要写代码和管理依赖 |
| FunctionGemma Tuning Lab | 快速验证工具路由效果、演示、少量数据试验 | 上手快,界面直观,自带可视化 | 定制能力有限,不适合复杂训练系统 |
如果只是验证“内部知识库 vs Google 搜索”这类路由策略,Tuning Lab 足够快。
如果要接入持续训练、自动评估、版本管理和灰度发布,TRL 脚本更适合。
微调工具调用模型时需要注意的细节
1. 工具描述要写清楚边界
工具 schema 里的 description 会影响模型理解工具用途。描述不能只写“搜索”,否则两个工具看起来几乎一样。
不推荐:
{
"name": "search_knowledge_base",
"description": "Search documents."
}
更好的写法:
{
"name": "search_knowledge_base",
"description": "Search internal company documents, including policies, procedures, employee guides, and internal system instructions."
}
工具描述越能体现边界,模型越容易学会选择。
2. 训练样本要覆盖相似但答案不同的问题
如果训练集中只有明显样本,模型遇到模糊问题时仍然会不稳定。应该主动构造“长得像但工具不同”的样本。
| 问题 | 正确工具 |
|---|---|
| Python 递归函数怎么写? | search_google |
| 公司内部 Python 项目代码规范在哪里? | search_knowledge_base |
| Jira 是什么? | search_google |
| 如何在公司 Jira 里创建新项目? | search_knowledge_base |
这种对比样本比单纯堆数量更有用,因为它直接教模型区分边界。
3. 不要让测试集泄漏到训练集
如果训练集和测试集有重复样本,评估结果会虚高。工具调用任务尤其容易出现相似模板,需要去重或至少检查高度相似样本。
可以做三层检查:
flowchart TD
A[原始数据] --> B[按完全相同文本去重]
B --> C[检查近似重复问题]
C --> D[按工具类别分层划分]
D --> E[训练集]
D --> F[测试集]
4. 关注格式稳定性
函数调用结果通常要被程序解析。即使工具选对了,只要格式错了,业务系统仍然无法执行。
需要重点检查:
- 函数名是否存在;
- 参数名是否符合 schema;
- 字符串转义是否正确;
- 是否多输出了无法解析的解释文本;
- 是否遗漏起止标记。
5. 小模型更依赖高质量样本
FunctionGemma 基于小规模模型,优势是推理速度快、部署成本低,但它对训练数据质量更敏感。样本里如果工具名称混乱、参数格式不统一、同类问题标签不一致,模型很容易学到错误模式。
关键实践清单
FunctionGemma 工具调用微调可以按这个顺序落地:
flowchart TD
A[定义工具 schema] --> B[准备用户问题、工具名、参数]
B --> C[清洗和混合数据]
C --> D[划分训练集和测试集]
D --> E{选择训练方式}
E --> F[TRL 脚本微调]
E --> G[Tuning Lab 可视化微调]
F --> H[评估工具选择和格式合法性]
G --> H
H --> I[分析错误样本]
I --> J[补充边界样本继续训练]
微调的核心不是让模型背答案,而是让模型学会稳定执行业务规则。对于智能体系统来说,这一步决定了自然语言请求能否被准确路由到正确工具。FunctionGemma 适合承担这种轻量、快速、成本可控的工具调用任务;配合高质量数据和清晰工具 schema,就能把通用函数调用模型改造成面向具体业务流程的执行组件。