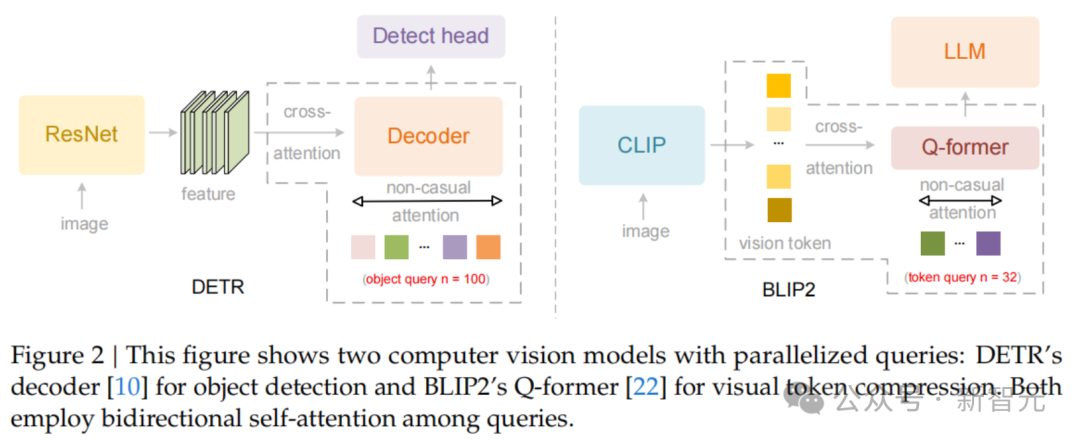
DeepSeek-OCR2 是 DeepSeek-OCR 的升级版本,核心变化不只是把 OCR(Optical Character Recognition,光学字符识别)做得更准,而是改造了视觉编码方式。
传统文档 OCR 经常把页面当成一张二维图片处理,再按照固定顺序把图像块排成一维 Token 序列。这个做法在简单单栏文档里问题不大,但遇到复杂版面时很容易出错:双栏论文、表格、脚注、图文混排、标题跨栏、阅读顺序跳转,都会让“从左到右、从上到下”的扫描顺序变得不可靠。
DeepSeek-OCR2 的关键设计是 DeepEncoder V2。它用一个小规模 LLM(Large Language Model,大语言模型)作为视觉编码器,并通过 Causal Flow Query(因果流查询)让模型在编码阶段就开始组织阅读顺序,而不是把一堆无序视觉 Token 直接交给解码器。
项目、模型和论文地址如下:
Project: https://github.com/deepseek-ai/DeepSeek-OCR-2
Model: https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
Paper: https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
OCR 模型真正难的地方:不是识字,而是按正确顺序读
对文档解析来说,识别单个字符只是基础能力。更难的是把页面中的内容按正确逻辑还原出来。
一个文档页面通常不是一条线,而是一个二维布局:
- 标题可能横跨页面顶部;
- 正文可能分成左右两栏;
- 表格要按行列关系读取;
- 图片说明、脚注、公式、页眉页脚可能穿插在正文周围;
- 扫描件或日志截图里还可能有大量非规则区域。
传统 VLM(Vision-Language Model,视觉语言模型)常用 Raster-Scan(光栅扫描)方式处理图像。光栅扫描会把二维图像块按照固定坐标顺序展开成一维序列,一般就是从左到右、从上到下。
flowchart TD
A[二维文档页面] --> B[光栅扫描]
B --> C[按坐标顺序展开成一维视觉 Token]
C --> D[LLM 解码器生成文本]
A --> E[语义阅读顺序]
E --> F[根据标题、段落、表格、分栏关系组织内容]
F --> G[更接近人类阅读路径的视觉序列]
G --> D
问题在于,页面坐标顺序不等于阅读顺序。双栏论文就是一个典型例子:光栅扫描可能会先读左栏第一行,再读右栏第一行,然后回到左栏第二行;真正的阅读顺序通常应该先读完左栏,再进入右栏。
DeepSeek-OCR2 要解决的就是这个错位:视觉编码器不再只负责把图像压成 Token,还要参与判断“这些 Token 应该按什么逻辑被读取”。
从固定扫描到因果流:DeepSeek-OCR2 的核心思想
DeepSeek-OCR2 引入了“视觉因果流”的概念。它的目标不是让模型机械地扫描图像,而是让模型用一组可学习的 Query Token 主动从视觉信息里抽取内容,并按因果顺序逐步构造视觉表示。
这里的“因果”可以理解为一种自回归式顺序约束:当前位置只能依赖已经生成或已经组织好的前文信息,不能偷看未来位置。这样一来,每个 Query Token 都必须在已有上下文基础上决定接下来要关注页面中的哪一块内容。
这张图展示了 DeepSeek-OCR2 如何把文档图像从固定扫描改造成语义驱动的阅读路径。
图中的关键对比是:传统方法把图像按坐标展平成序列,DeepSeek-OCR2 则通过查询 Token 建立更贴近语义结构的视觉序列。也就是说,模型在进入最终文本生成前,已经对页面内容做了一次“阅读顺序整理”。
这个设计带来两个直接影响:
| 处理方式 | 图像展开逻辑 | 对复杂版面的影响 |
|---|---|---|
| 光栅扫描 | 按坐标从左到右、从上到下 | 容易破坏分栏、表格、图文混排的阅读顺序 |
| 因果流查询 | Query Token 按因果约束逐步抽取视觉信息 | 更容易形成标题、正文、表格、脚注之间的逻辑顺序 |
DeepEncoder V2 的整体结构
DeepEncoder V2 可以拆成两个主要部分:
- Vision Tokenizer(视觉分词器):把图像转换成视觉 Token;
- LLM Visual Encoder(LLM 视觉编码器):用小型语言模型处理视觉 Token 和 Query Token,输出有序视觉表示。
整体流程可以画成这样:
flowchart LR
A[文档图像] --> B[Vision Tokenizer<br/>SAM-base + 卷积层]
B --> C[视觉 Token]
Q[可学习 Query Token] --> D[LLM 视觉编码器<br/>Qwen2-0.5B]
C --> D
D --> E[按因果流组织后的视觉表示]
E --> F[LLM 解码器]
F --> G[OCR 文本 / Markdown / 结构化文档]
DeepSeek-OCR2 的特别之处在于,它没有继续沿用常见的 CLIP(Contrastive Language-Image Pre-training,对比语言-图像预训练)视觉编码器路线,而是用 Qwen2-0.5B 这样的小型 LLM 承担视觉编码任务。
这意味着视觉编码阶段不再只是“提取图像特征”,还具备了更强的序列建模能力。对于文档 OCR 来说,序列建模非常重要,因为最终输出本来就是一段有顺序的文本或结构化内容。
Vision Tokenizer:先把图像压成视觉 Token
DeepEncoder V2 的第一层是 Vision Tokenizer。它沿用了 SAM-base(Segment Anything Model base,基础版分割模型)加卷积层的设计,把输入图像转换成一组视觉 Token。
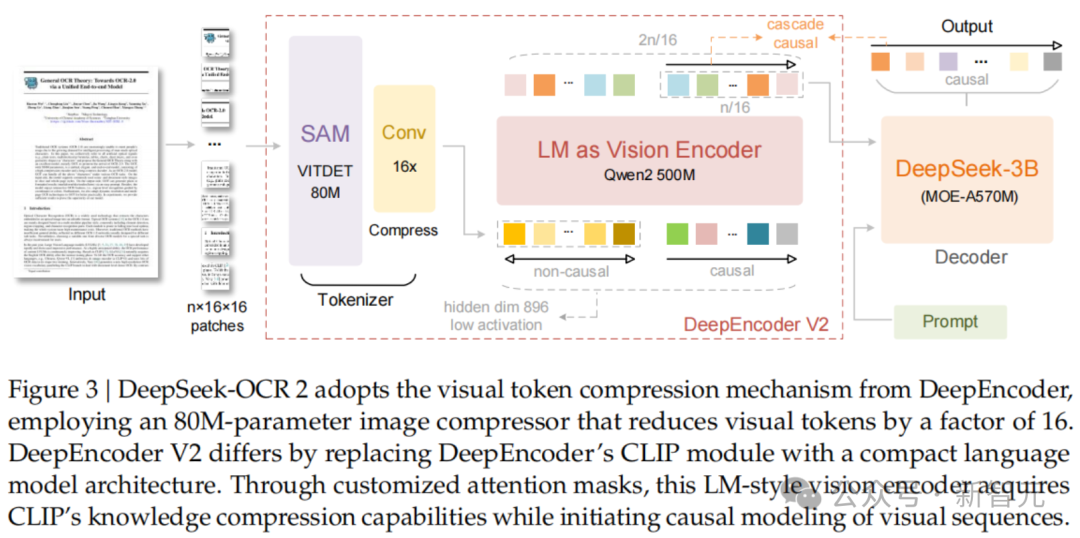
图里的 Vision Tokenizer 承担的是“视觉离散化”工作:原始页面图像不能直接送进语言模型,需要先被切分、编码、压缩成模型可以处理的 Token 表示。SAM-base 提供较强的视觉特征提取能力,卷积层则用于进一步整理和压缩这些特征。
这个阶段解决的是“看见页面”的问题,但还没有真正解决“按什么顺序读页面”的问题。阅读顺序由后面的 LLM 视觉编码器和 Query Token 来处理。
LLM 视觉编码器:让 Query Token 主动读取页面
DeepEncoder V2 的第二层是一个小型 LLM,采用 Qwen2-0.5B。它接收两类 Token:
| Token 类型 | 来源 | 作用 |
|---|---|---|
| 视觉 Token | Vision Tokenizer 输出 | 表示页面中的图像、文字、布局等视觉信息 |
| Query Token | 可学习参数 | 主动从视觉 Token 中抽取信息,并形成有序视觉表示 |
Query Token 可以理解为一组“阅读探针”。每个 Query Token 都会根据视觉内容和已有上下文决定自己应该关注什么。它们不是简单地把所有图像块按坐标搬运过去,而是在注意力机制中学习如何重排和压缩视觉信息。
DeepSeek-OCR2 的核心就在这里:Query Token 的排列不是完全并行、互不相关的,而是受到因果注意力约束。前面的查询结果会影响后面的查询过程,从而形成类似“先读标题,再读正文,再读表格”的顺序建模能力。
注意力掩码:视觉 Token 双向看,Query Token 因果看
DeepEncoder V2 的关键机制是 Attention Mask(注意力掩码)。注意力掩码决定了某个 Token 能看到哪些 Token,不能看到哪些 Token。
这张图展示了 DeepEncoder V2 中不同 Token 之间的注意力关系。
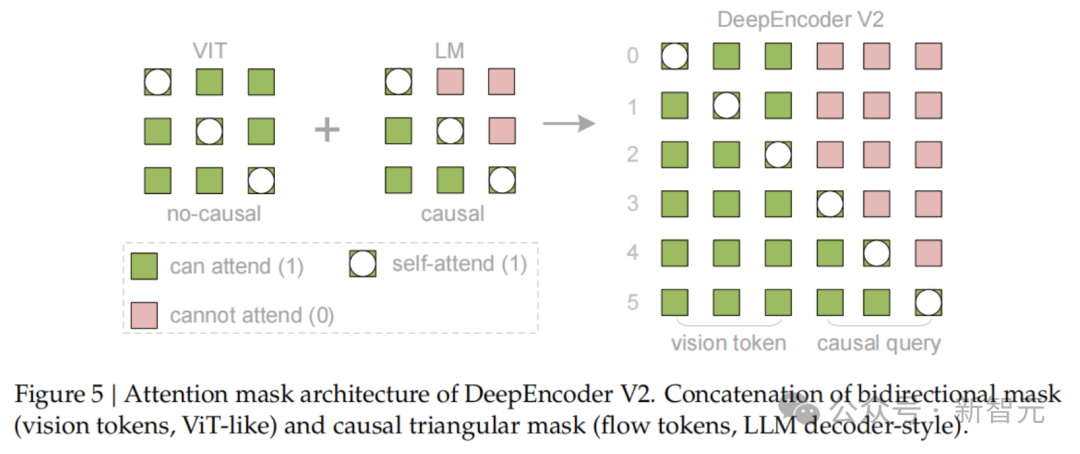
可以把它理解成两套规则:
| 区域 | 注意力方式 | 目的 |
|---|---|---|
| 视觉 Token 之间 | 双向注意力 | 保留全局视觉感知能力,让图像块之间充分交换信息 |
| Query Token 之间 | 因果注意力 | 让第 i 个查询只能依赖它之前的查询结果,形成顺序化阅读路径 |
视觉 Token 内部使用双向注意力,类似 ViT(Vision Transformer,视觉 Transformer)的做法。这样做是为了让模型理解页面整体布局,例如某个文字块和标题、表格、图片之间的位置关系。
Query Token 则使用因果注意力。第一个 Query Token 先抽取一部分信息,第二个 Query Token 在第一个的基础上继续抽取,后续 Query Token 依次推进。这样编码器输出的不是一堆无序特征,而是一条带有阅读逻辑的视觉序列。
用伪代码描述,注意力关系大致是:
for token in visual_tokens:
token.can_attend_to = all_visual_tokens
for i, query in enumerate(query_tokens):
query.can_attend_to = visual_tokens + query_tokens[: i + 1]
真实实现会更复杂,但核心思想就是:视觉区域保持全局感知,查询区域保持因果顺序。
两级因果推理:编码器先理顺,解码器再生成
DeepSeek-OCR2 的因果推理不是只发生在最终文本生成阶段,而是分成两级:
sequenceDiagram
participant I as 文档图像
participant T as Vision Tokenizer
participant E as DeepEncoder V2
participant D as LLM 解码器
participant O as OCR 输出
I->>T: 图像转视觉 Token
T->>E: 输入视觉 Token
E->>E: Query Token 按因果流抽取和重排信息
E->>D: 输出有序视觉表示
D->>O: 自回归生成文本或结构化结果
第一级发生在编码器中。DeepEncoder V2 用 Query Token 对视觉 Token 做语义抽取和顺序重排,尽量把页面内容整理成适合阅读的表示。
第二级发生在解码器中。LLM 解码器基于已经整理过的视觉表示,自回归生成 OCR 结果。
这种结构的好处是,解码器不必独自承担全部版面理解压力。复杂文档的阅读顺序已经在编码阶段被部分处理,后续生成自然更稳定。
为什么 Token 更少反而可能更准
多模态模型处理图片时,视觉 Token 数量会直接影响推理成本。Token 越多,上下文越长,计算量和显存占用通常越高。很多模型为了保留细节,会把图片切成大量视觉 Token,但这会让文档解析变慢,也会占用 LLM 的上下文窗口。
DeepSeek-OCR2 的路线不是单纯堆 Token,而是通过 DeepEncoder V2 做更强的压缩和重排。换句话说,它试图让每个视觉 Token 携带更有用的信息。
在 OmniDocBench v1.5 基准测试中,DeepSeek-OCR2 使用较少视觉 Token 就取得了较高得分。
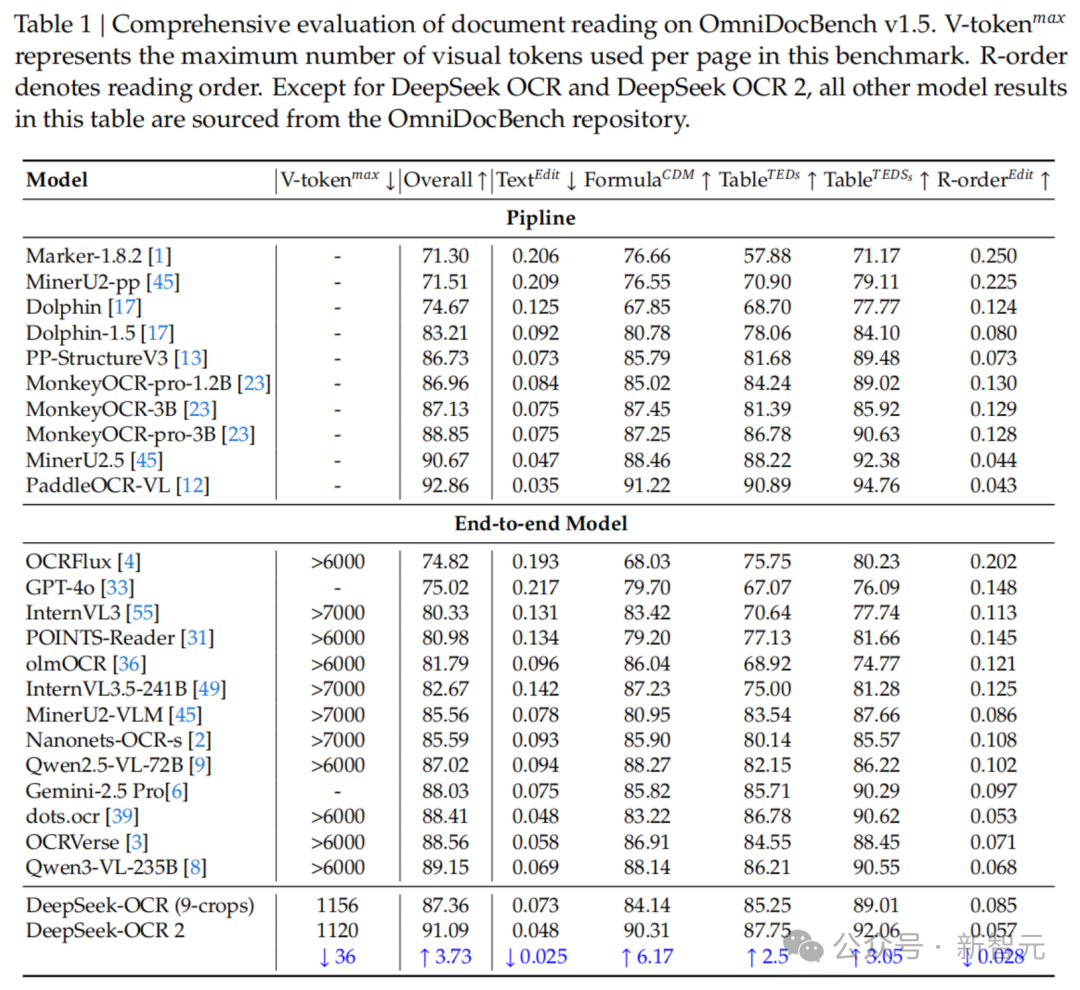
关键结果可以整理成表格:
| 指标 | DeepSeek-OCR | DeepSeek-OCR2 | 变化 |
|---|---|---|---|
| OmniDocBench v1.5 综合得分 | 约 87.36% | 91.09% | 提高 3.73 个百分点 |
| 阅读顺序 R-order 编辑距离 | 0.085 | 0.057 | 更低,阅读顺序更接近标注结果 |
| 视觉 Token 数量 | 较少 Token 设定 | 256 - 1120 | 在高压缩率下保持较好解析能力 |
编辑距离越低,表示模型输出和标准答案越接近。R-order 编辑距离专门反映阅读顺序问题,DeepSeek-OCR2 从 0.085 降到 0.057,说明因果流查询确实改善了复杂版面的顺序还原。
在与闭源强模型对比时,DeepSeek-OCR2 也表现出较强竞争力。在约 1120 个视觉 Token 的设置下,DeepSeek-OCR2 的文档解析编辑距离为 0.100,优于 Gemini-3 Pro 的 0.115。
| 模型 | 视觉 Token 数量 | 文档解析编辑距离 |
|---|---|---|
| DeepSeek-OCR2 | 约 1120 | 0.100 |
| Gemini-3 Pro | 约 1120 | 0.115 |
这组数据说明,DeepSeek-OCR2 的改进不只是“多用参数”或“多用 Token”,而是编码方式改变后,视觉信息被组织得更适合文档解析。
生产数据中的重复率下降
OCR 结果常见的一个问题是重复生成。比如同一段文字被输出两遍,或者表格、页眉、脚注被反复解析。对于人类阅读来说,这类错误很明显;对于 LLM 训练数据生产来说,它会污染语料,导致后续模型学习到重复、混乱的文本模式。
DeepSeek-OCR2 在生产数据场景中降低了重复率:
| 场景 | DeepSeek-OCR 重复率 | DeepSeek-OCR2 重复率 | 变化 |
|---|---|---|---|
| 在线用户日志图像 | 6.25% | 4.17% | 下降 2.08 个百分点 |
| PDF 数据生产 | 3.69% | 2.88% | 下降 0.81 个百分点 |
这个指标和 DeepEncoder V2 的设计目标是一致的:如果编码器能更清楚地组织视觉顺序,解码器就不容易在相同区域上反复生成内容。对于大规模数据清洗流水线来说,重复率下降意味着后处理压力更小,得到的训练语料也更干净。
DeepSeek-OCR2 适合什么场景
DeepSeek-OCR2 的优势集中在“复杂文档解析”和“高压缩视觉编码”两个方向。它并不是所有 OCR 场景都必须使用的方案。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 双栏论文、研报、扫描 PDF | 适合 | 阅读顺序复杂,因果流查询能改善内容组织 |
| 表格、图文混排文档 | 适合 | 需要理解二维布局和语义结构 |
| LLM 训练数据生产 | 适合 | OCR 结果更干净,重复率下降有利于语料清洗 |
| 日志截图、网页截图解析 | 适合 | 页面元素多,固定扫描容易破坏顺序 |
| 简单单行票据或固定模板识别 | 不一定需要 | 传统 OCR 或模板规则可能成本更低 |
| 低算力边缘设备实时识别 | 需要评估 | LLM 视觉编码器比轻量 OCR 引擎更重 |
| 只需要检测文字框坐标 | 不完全匹配 | DeepSeek-OCR2 更偏向文档内容解析和生成 |
上手路线
DeepSeek-OCR2 的代码、模型权重和论文都已经公开。一个常见的上手流程是先拉取仓库,再下载 Hugging Face 上的模型权重。
git clone https://github.com/deepseek-ai/DeepSeek-OCR-2.git
cd DeepSeek-OCR-2
python -m pip install -U huggingface_hub
huggingface-cli download deepseek-ai/DeepSeek-OCR-2 \
--local-dir ./models/DeepSeek-OCR-2
如果仓库提供 requirements.txt,可以按仓库依赖安装:
python -m pip install -r requirements.txt
运行前需要重点确认三件事:
| 检查项 | 说明 |
|---|---|
| 模型权重路径 | 推理脚本需要能找到本地模型目录或 Hugging Face 模型名 |
| GPU 显存 | 多模态模型推理通常依赖 GPU,长文档和高分辨率图片会增加显存占用 |
| 输出格式 | OCR 任务可能输出纯文本、Markdown 或结构化 JSON,数据流水线要提前统一格式 |
对于文档批处理任务,可以把 DeepSeek-OCR2 放在数据清洗链路中:
flowchart LR
A[PDF / 扫描图 / 日志截图] --> B[页面切分与预处理]
B --> C[DeepSeek-OCR2 解析]
C --> D[重复内容检测]
D --> E[格式归一化]
E --> F[高质量文本或训练语料]
这条链路里,DeepSeek-OCR2 负责把复杂视觉页面转成文本或结构化结果;后面的重复检测和格式归一化仍然有必要,因为任何 OCR 模型在真实生产数据里都可能遇到噪声、低清晰度扫描、倾斜页面和异常排版。
DeepEncoder V2 对多模态模型的意义
DeepSeek-OCR2 表面上是 OCR 模型升级,实际触及的是一个更大的问题:视觉编码器是否一定要是传统图像编码器?
过去很多多模态模型会使用 CLIP、ViT 或其他视觉骨干网络,把图片转换成视觉特征,再交给 LLM 处理。DeepEncoder V2 展示了另一条路线:直接用 LLM 结构做视觉编码器,让编码阶段具备序列建模和因果推理能力。
这种思路对原生多模态模型有启发意义。只要不同模态都能被转换成 Token,并配合合适的 Query Embedding(查询嵌入)和注意力掩码,同一类编码器就有机会处理文本、图像、音频等多种输入。
可以把它抽象成一个统一框架:
flowchart TD
A[文本 Token] --> E[统一 Token 编码器]
B[视觉 Token] --> E
C[音频 Token] --> E
D[其他模态 Token] --> E
Q1[文本 Query Embedding] --> E
Q2[视觉 Query Embedding] --> E
Q3[音频 Query Embedding] --> E
E --> O[统一语义表示]
O --> L[LLM 解码或任务头]
OCR 是这个方向里非常实用的任务,因为文档天然同时包含视觉布局和语言内容。DeepSeek-OCR2 的价值也在这里:它不只是识别文字,而是把“视觉页面如何变成有序语言序列”这个过程放进了模型结构里。对于复杂文档解析、训练数据生产和多模态系统设计来说,这个改动比单纯提高几个识别指标更关键。