AgentCPM 是清华大学、中国人民大学、面壁智能与 OpenBMB 开源社区联合开源的智能体项目。它的核心模型叫 AgentCPM-Explore,目标不是做一个普通聊天模型,而是让一个 4B 参数量的小模型能够处理长周期、多步骤、需要反复调用工具的复杂任务。
这里的关键点有两个:
- 参数量小:4B 模型更适合本地工作站、私有服务器或边缘设备部署,推理成本比 30B、70B 级模型低很多。
- Agent 能力强:它不只是回答问题,还要拆解任务、调用工具、观察结果、修正策略,并在多轮交互中保持稳定。
AgentCPM-Explore 基于 Qwen3-4B-thinking-2507 做深度后训练,在 GAIA、Xbench、BrowserComp 等多个高难度智能体评测中表现突出。公开结果显示,它在不少任务上超过同尺寸 SOTA(State of the Art,当前最优水平)模型,也能接近甚至超过部分更大规模模型在特定 Agent 任务上的表现。
端侧 Agent 到底解决什么问题
普通大语言模型更像“问答引擎”:用户输入问题,模型直接生成答案。Agent 的工作方式更接近“带工具的研究助手”:遇到复杂问题时,它不会只凭已有参数记忆回答,而是会主动搜索、浏览、计算、验证信息来源,再根据工具返回的结果继续行动。
一个典型 Agent 循环是这样的:
flowchart TD
A[用户给出任务] --> B[模型理解目标]
B --> C[拆分子任务并制定计划]
C --> D[选择工具]
D --> E[调用搜索、浏览器、代码执行等工具]
E --> F[读取工具返回结果]
F --> G{任务是否完成}
G -- 否 --> H[修正计划或更换策略]
H --> D
G -- 是 --> I[生成最终答案]
长程任务的难点在于,模型要在几十轮甚至上百轮工具交互中保持目标一致,不能重复搜索同一个无效方向,也不能因为中间结果不完整就提前给出结论。AgentCPM-Explore 的重点能力就在这里:它支持超过 100 轮的稳定环境交互,能够持续探索直到任务完成。
这类能力适合处理:
- 需要多源验证的研究问题;
- 需要访问网页、搜索资料、核对数据来源的任务;
- 需要多步推理和工具组合的复杂问答;
- 需要在失败后调整检索词、换数据源、重新组织计划的任务。
AgentCPM-Explore 的能力特点
AgentCPM-Explore 不是靠把答案背下来解决问题,而是把“如何探索”训练成一种稳定策略。它在任务执行中会表现出几个典型行为:
| 能力 | 具体表现 |
|---|---|
| 主动核查 | 不轻信单个工具结果,会继续查找更原始或更可靠的数据源 |
| 多源验证 | 对同一个结论尝试从不同网页、文档或结果中交叉确认 |
| 策略调整 | 搜索不到结果时,会改写关键词、换查询路径或缩小问题范围 |
| 长程保持 | 在多轮工具调用后仍然围绕最初目标推进 |
| 减少重复 | 不容易陷入反复调用同一个工具、查询同一个无效问题的循环 |
公开评测把 AgentCPM-Explore 放到多个 Agent 任务集上与不同规模模型对比。重点不是单个分数,而是 4B 模型在长程深度探索任务中能维持较高完成率。
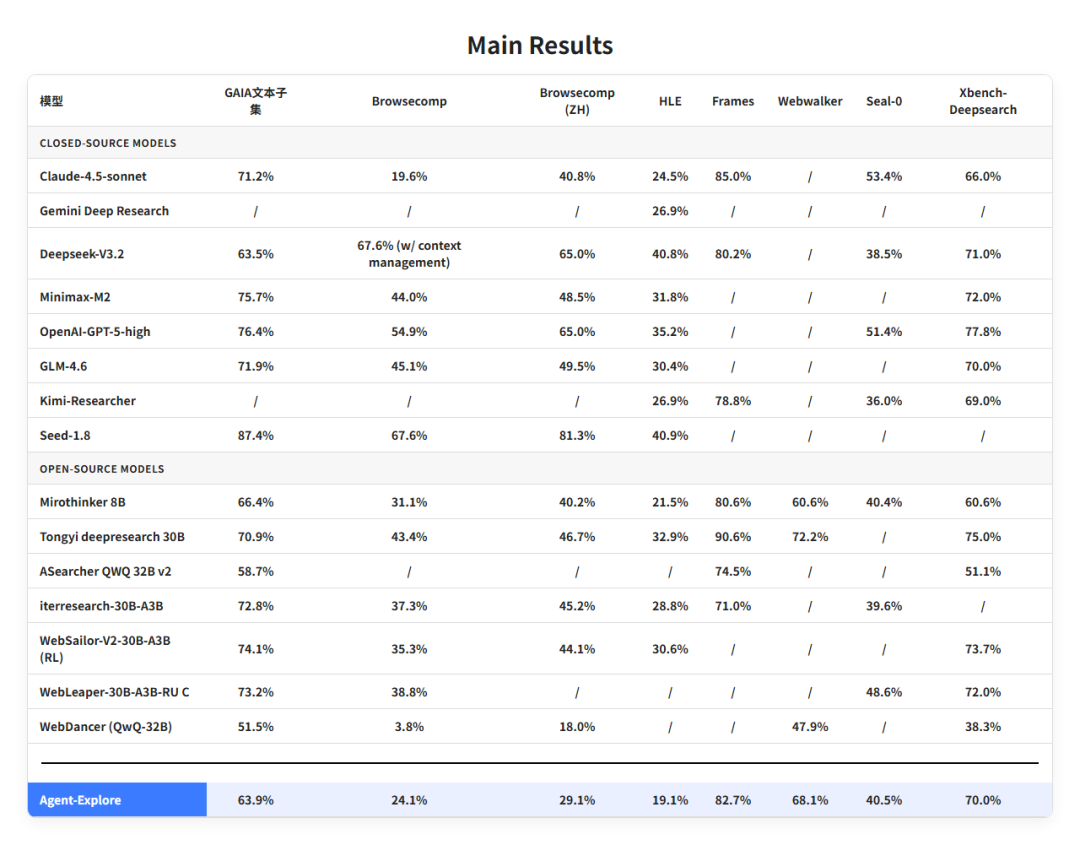
这组结果说明,Agent 能力不能只看参数量。对于需要工具交互的任务,后训练数据、环境反馈、工具调用稳定性和评测框架都会影响最终表现。AgentCPM-Explore 在 Xbench-DeepResearch 等任务上的公开成绩显示,小模型经过专门的 Agent 后训练后,可以在某些深度研究场景中追上更大模型。与此同时,评测成绩仍然会受到工具环境、题集版本、网络可访问性和重复尝试次数影响,复现时需要固定配置。
在允许重复尝试的设置下,AgentCPM-Explore 对 GAIA 文本任务的覆盖率可以达到很高水平。这个结果适合说明模型的探索能力,但生产环境不能无限重试,通常需要设置最大轮数、最大工具调用次数和超时策略。
项目整体架构
AgentCPM 不只开源模型权重,还把训练、工具沙盒和评测相关基础设施一起开放出来,方便复现、二次开发和私有化部署。
核心组件可以分成四层:
flowchart LR
U[用户任务] --> M[AgentCPM-Explore<br/>4B Agent 模型]
M --> D[AgentDock<br/>工具沙盒与调度]
D --> T1[搜索工具]
D --> T2[浏览器工具]
D --> T3[代码执行工具]
D --> T4[其他工具节点]
R[AgentRL<br/>异步强化学习框架] --> M
E[AgentToLeaP<br/>评测平台] --> M
E --> D
| 组件 | 作用 | 适用阶段 |
|---|---|---|
| AgentCPM-Explore | 执行长程探索任务的 4B Agent 模型 | 推理、部署 |
| AgentDock | 统一管理工具调用、工具节点和沙盒环境 | 推理、评测 |
| AgentRL | 强化学习(Reinforcement Learning,RL)后训练框架 | 训练、复现 |
| AgentToLeaP | 一键式 Agent 能力评测平台 | 评测、对比 |
AgentDock 很关键。Agent 需要调用外部工具,如果每个工具都由模型进程直接管理,环境依赖、权限隔离、错误恢复都会变得复杂。AgentDock 把工具调用抽象成统一服务,模型只需要通过 HTTP 接口(API,应用程序编程接口)请求工具,工具执行过程由沙盒负责。
适合用 AgentCPM-Explore 的场景
AgentCPM-Explore 的优势来自“小模型 + 长程 Agent 后训练 + 工具沙盒”。它适合的不是所有大模型任务,而是那些确实需要自主探索的任务。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 本地或私有环境部署 Agent | 适合 | 4B 模型部署成本较低,数据更容易留在内网 |
| 长程资料检索、深度研究 | 适合 | 能多轮调用工具并根据结果修正计划 |
| 自动浏览网页、核查信息源 | 适合 | AgentDock 可以统一管理浏览、搜索等工具 |
| 大规模开放域闲聊 | 不一定适合 | 聊天体验更多取决于通用对话能力,不一定需要 Agent 循环 |
| 极低延迟在线问答 | 不一定适合 | 多轮工具调用会增加耗时 |
| 需要强数学、强代码竞赛能力的任务 | 需要单独评估 | Agent 能力强不等于所有基础能力都强 |
| 无 GPU 的轻量设备 | 需要谨慎 | 4B 虽小,稳定推理仍需要足够内存和推理后端支持 |
端侧不等于只能跑在手机上。这里更准确的理解是:模型规模足够小,可以在本地工作站、私有 GPU(图形处理器)服务器或边缘计算节点上部署,不必完全依赖闭源云端模型。
本地部署 AgentCPM-Explore
部署主要分成两部分:
- 启动 AgentDock 工具沙盒;
- 在预置 Docker 环境里运行 AgentCPM-Explore。
环境建议:
| 依赖 | 说明 |
|---|---|
| Git | 拉取项目代码 |
| Docker / Docker Compose | 启动 AgentDock 和评测容器 |
| NVIDIA GPU 与驱动 | 使用 --gpus all 运行推理容器 |
| NVIDIA Container Toolkit | 让 Docker 容器访问 GPU |
| Linux 环境 | --network host 在 Linux 上行为最稳定 |
1. 克隆项目
git clone https://github.com/OpenBMB/AgentCPM.git
cd AgentCPM/AgentCPM-Explore
2. 启动 AgentDock 工具沙盒
进入 AgentDock 目录:
cd AgentDock
启动管理面板、数据库和工具节点:
docker compose up -d
确认容器是否正常运行:
docker ps
AgentDock 默认监听在本机 8000 端口,可以用健康检查接口验证:
curl http://localhost:8000/health
如果返回 JSON(JavaScript Object Notation,常用结构化数据格式)格式的健康状态信息,说明工具沙盒已经启动。常见失败原因包括端口被占用、Docker Compose 版本过旧、某个工具节点镜像拉取失败。
3. 拉取并进入预置评测环境
回到 AgentCPM-Explore 项目根目录,再拉取官方预置容器:
cd ..
docker pull yuyangfu/agenttoleap-eval:v1.0
启动容器,并把当前目录挂载到容器内:
docker run -dit \
--name agenttoleap \
--gpus all \
--network host \
-v "$(pwd)":/workspace \
yuyangfu/agenttoleap-eval:v1.0
进入容器:
docker exec -it agenttoleap /bin/bash
cd /workspace
如果使用 Windows PowerShell,目录挂载通常要改成类似写法:
docker run -dit `
--name agenttoleap `
--gpus all `
--network host `
-v ${PWD}:/workspace `
yuyangfu/agenttoleap-eval:v1.0
Docker Desktop 对 --network host 的支持和 Linux 不完全一致。如果容器访问不到宿主机的 localhost:8000,可以尝试把 AgentDock 地址改成 host.docker.internal:8000,或者使用显式端口映射。
4. 配置 quickstart.py
项目根目录下的 quickstart.py 有一个 [USER CONFIGURATION] 配置区,运行前需要确认几类信息:
| 配置项 | 作用 |
|---|---|
| 任务描述 | 要让 Agent 完成的具体任务 |
| AgentDock 地址 | 通常是 http://localhost:8000 |
| 模型路径或推理后端 | 指向 AgentCPM-Explore 权重或对应服务 |
| 最大交互轮数 | 控制工具调用和思考循环上限 |
| 输出目录 | 保存完整执行轨迹 |
可以先定位配置区:
grep -n "USER CONFIGURATION" quickstart.py
配置逻辑可以理解成这样,实际变量名以仓库文件为准:
# quickstart.py 中 [USER CONFIGURATION] 区域的配置思路
task = "查找并核对某个问题的可靠答案,要求给出信息来源"
tool_sandbox_url = "http://localhost:8000"
max_turns = 100
output_dir = "outputs/quickstart_results"
复杂任务不要写得太含糊。Agent 可以自己探索,但任务边界越清晰,工具调用越容易收敛。例如,与其写“研究某个项目”,不如写“查找某个项目的开源许可证、核心功能、最新版本,并给出来源链接”。
5. 运行任务
配置完成后直接运行:
python quickstart.py
运行时通常会看到模型的计划、工具调用、工具返回结果和最终答案。长程任务可能会持续较久,因为 Agent 会多次调用搜索、浏览器或其他工具节点。
任务结果会保存在:
outputs/quickstart_results/
其中 dialog.json 记录完整执行轨迹,包括中间计划、每次工具调用请求、工具响应和最终输出。可以直接查看:
cat outputs/quickstart_results/dialog.json
如果安装了 jq,可以更方便地检查结构:
jq . outputs/quickstart_results/dialog.json
运行时容易踩的坑
AgentDock 必须先启动
AgentCPM-Explore 依赖工具沙盒。如果 quickstart.py 运行后一直报工具连接失败,优先检查:
curl http://localhost:8000/health
docker ps
端口 8000 被其他服务占用时,需要修改 AgentDock 端口或停止冲突进程。
GPU 容器不可用
--gpus all 报错通常不是项目代码问题,而是 Docker 没有正确接入 NVIDIA GPU。可以检查:
nvidia-smi
docker run --rm --gpus all nvidia/cuda:12.0.0-base-ubuntu22.04 nvidia-smi
第二条命令如果失败,需要安装或修复 NVIDIA Container Toolkit。
长程任务要设置上限
Agent 支持超过 100 轮交互,但生产环境不能无限循环。建议设置:
- 最大轮数;
- 单个工具调用超时;
- 最大重复尝试次数;
- 最大输出长度;
- 失败后的兜底返回策略。
这样可以避免网页不可访问、搜索结果变化或工具异常导致任务长时间挂起。
评测结果不等于所有业务结果
GAIA、Xbench、BrowserComp 等基准能衡量模型在标准任务上的表现,但真实业务环境会多出很多变量:内部数据格式、权限系统、网络隔离、工具稳定性、网页反爬、任务描述质量都会影响结果。把 AgentCPM-Explore 接入业务流程前,应该用自己的任务集做小规模评测。
输出轨迹可能包含敏感信息
dialog.json 会保存完整交互记录。如果任务里包含内部链接、搜索关键词、工具返回内容或用户输入,输出目录要按敏感数据处理。私有化部署时尤其要注意日志权限、备份策略和清理周期。
二次开发思路
如果只是体验模型能力,quickstart.py 足够。要把 AgentCPM-Explore 接入自己的系统,通常会从三个方向改:
| 改造方向 | 具体做法 |
|---|---|
| 自定义工具 | 在 AgentDock 中增加内部搜索、数据库查询、文档读取等工具节点 |
| 自定义任务模板 | 把业务任务改写成稳定提示词,明确目标、约束和输出格式 |
| 自定义评测 | 用 AgentToLeaP 跑自己的任务集,统计成功率、平均轮数、工具失败率 |
AgentCPM 的价值不只是提供一个 4B 模型,而是把模型、工具沙盒、强化学习训练和评测流程放在同一个体系里。对于希望在本地或私有环境部署 Agent 的团队,AgentDock 负责工具隔离和调用,AgentCPM-Explore 负责长程探索,AgentToLeaP 负责验证效果,AgentRL 则用于继续训练和能力复现。