GUI(Graphical User Interface,图形用户界面)智能体要解决的问题很直接:用户不想一步步打开 App、搜索、复制、切换窗口、填写表单,而是希望把目标说出来,让智能体自己完成操作。
例如用户给出一条复合指令:
查最早从杭州西站到上海虹桥的二等座车次,在钉钉群里同步到达时间,把某个会议改到明天同一时间,并在群里 @ 同事说明原因、询问是否有空。
这类任务有几个典型难点:
- 跨 App:12306、钉钉、日历或会议系统都可能参与。
- 长流程:不是一次点击,而是连续几十步操作。
- 信息依赖:后续动作依赖前面查询到的车次和到达时间。
- 界面不稳定:弹窗、加载延迟、按钮位置变化都可能打断执行。
- 隐私敏感:短信、密码、证件号、支付确认等内容不能随便上传。
MAI-UI 的核心思路不是让模型盲目模仿人类点击,而是把 GUI 操作、结构化工具调用、本地小模型、云端大模型和动态强化学习组合起来,让智能体在真实手机环境里更稳地完成任务。
它可以概括为四个设计:
| 设计 | 解决的问题 |
|---|---|
| 主动交互 | 指令不完整时先澄清,避免模型猜错 |
| MCP 工具调用 | 能用 API 解决的部分不硬点 GUI,减少易错步骤 |
| 端云协同 | 简单任务本地做,复杂非敏感任务交给云端大模型 |
| 动态强化学习 | 在弹窗、跳转、无响应等干扰下保持任务连续性 |
MAI-UI 是什么
MAI-UI 是一个通用 GUI 智能体基座,面向手机、电脑和网页等图形界面任务。它的能力不只包括“看见按钮并点击”,还包括:
- 理解用户目标;
- 判断任务是否缺少关键信息;
- 在 GUI 操作和工具调用之间选择更合适的路径;
- 监控当前执行轨迹是否偏离目标;
- 在端侧模型无法完成时,按隐私规则触发云端模型接力;
- 通过强化学习适应真实环境中的动态干扰。
整体执行链路可以这样理解:
flowchart TD
A[用户指令] --> B[意图理解与任务规划]
B --> C{信息是否足够?}
C -- 不足 --> D[主动提问澄清]
D --> B
C -- 足够 --> E{是否适合结构化工具?}
E -- 是 --> F[MCP 工具调用]
E -- 否 --> G[GUI 视觉定位与操作]
F --> H[整合工具返回结果]
G --> I[执行轨迹监控]
H --> J[写入 App 或回复用户]
I --> K{是否偏离目标或卡住?}
K -- 否 --> J
K -- 是 --> L{是否涉及敏感信息?}
L -- 是 --> M[端侧模型继续处理]
L -- 否 --> N[生成错误摘要]
N --> O[云端大模型接力恢复]
O --> J
这个流程里,GUI 操作只是动作类型之一。对智能体来说,更重要的是判断“当前任务到底应该怎么完成”。
主动交互:模糊任务不能靠猜
很多真实指令天然不完整。比如用户说“下载简历并发给同事”,至少有两个合理做法:
- 把简历作为附件发送;
- 复制简历正文内容发送。
如果智能体直接选择一种方式,可能会造成信息格式错误,甚至泄露不该发送的内容。MAI-UI 的处理方式是:当任务存在关键歧义时,先向用户提问,而不是继续执行。
图中展示的是“下载简历并发送给同事”这类任务的交互过程,智能体在发送前询问用户希望用附件还是文本内容。
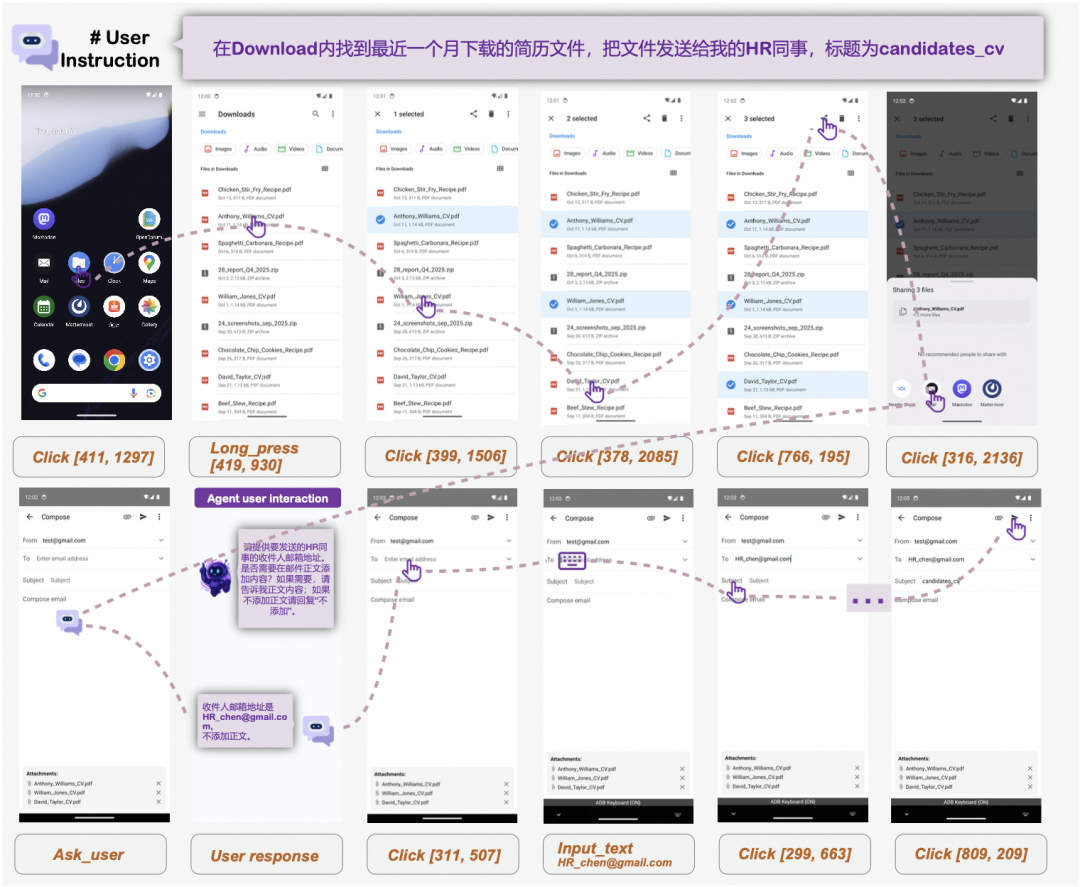
这个能力看似简单,但对 GUI 智能体非常关键。因为 GUI 操作一旦执行,很多动作很难撤销,例如发送消息、提交表单、修改日程。主动澄清可以把不确定性留在执行前,而不是让模型在执行后补救。
在 MobileWorld 评测中,MAI-UI 在“主动交互”子任务上相比端到端模型领先 18.7 个百分点。这说明真实 GUI 任务不能只考察点击能力,还要考察模型是否知道什么时候不该继续点。
MCP 工具调用:能走 API,就不要硬走 GUI
传统 GUI 智能体经常把所有任务都拆成点击、输入、滑动。这个方式在简单任务里可行,但遇到长流程就很脆弱。
假设用户给出出行规划任务:
我现在在阿里巴巴云谷园区,要去招商银行取钱,再去城西银泰城。规划公交地铁路线,选一家 4 公里以内的招商银行,两段行程总时间不超过 2 小时,把规划写到笔记里,标题为“下午行程”。
如果完全靠 GUI 操作,流程大概是:
flowchart LR
A[打开地图 App] --> B[搜索招商银行]
B --> C[滚动筛选 4 公里以内网点]
C --> D[逐个点开查看详情]
D --> E[规划云谷到银行路线]
E --> F[规划银行到银泰城路线]
F --> G[估算总耗时]
G --> H[切到笔记 App]
H --> I[输入标题和路线内容]
问题在于,每一步都可能失败:广告弹窗遮挡、定位权限弹出、地图加载慢、搜索结果顺序变化、按钮位置变化,都会让轨迹偏移。
MAI-UI 引入 MCP(Model-Callable Protocol,模型可调用协议),让模型可以在合适的时候调用结构化工具。对上面的出行任务,智能体可以把大部分不稳定 GUI 操作替换成 API(Application Programming Interface,应用程序编程接口)调用:
# 伪代码:表达 MAI-UI 的工具优先思路
banks = mcp_call(
"amap_poi_search",
keyword="招商银行",
location="阿里巴巴云谷园区",
radius=4000
)
plans = []
for bank in banks:
first_leg = mcp_call(
"amap_direction",
origin="阿里巴巴云谷园区",
destination=bank["address"],
mode="transit"
)
second_leg = mcp_call(
"amap_direction",
origin=bank["address"],
destination="城西银泰城",
mode="transit"
)
total_minutes = first_leg["duration"] + second_leg["duration"]
if total_minutes <= 120:
plans.append({
"bank": bank,
"first_leg": first_leg,
"second_leg": second_leg,
"total_minutes": total_minutes
})
best_plan = sorted(plans, key=lambda x: x["total_minutes"])[0]
gui_write_note(
title="下午行程",
content=format_plan(best_plan)
)
这个流程的关键变化是:搜索、筛选、路线计算交给结构化工具,最后只把结果写回 GUI。
sequenceDiagram
participant U as 用户
participant A as MAI-UI
participant M as MCP 工具
participant N as 笔记 App
U->>A: 提出出行规划任务
A->>M: 搜索 4 公里内招商银行
M-->>A: 返回网点列表
A->>M: 计算两段公交地铁路线
M-->>A: 返回路线与耗时
A->>A: 过滤总耗时不超过 2 小时的方案
A->>N: 写入标题和规划内容
MCP 不是为了取代 GUI,而是让 GUI 智能体不要把所有事情都变成点击。能结构化求解的任务,API 通常更稳定、更快,也更容易验证结果。
图中给出了更多 MCP-GUI 混合任务:例如调用高德地图 API 比较两套房到公司的通勤距离,再把结果发送给朋友;或者调用 GitHub API 获取提交记录,整理后通过邮件发送。
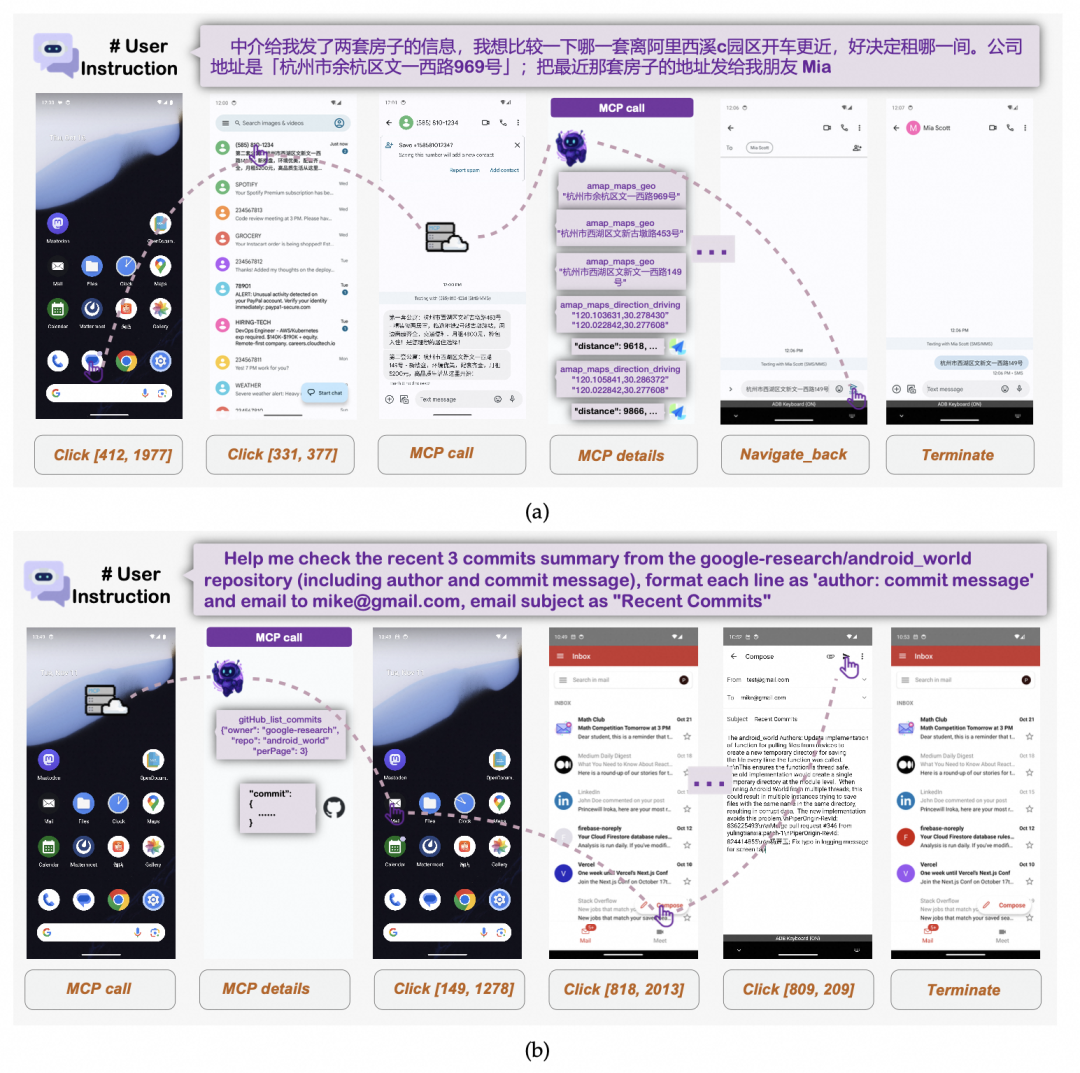
MAI-UI 的训练轨迹显式包含 mcp_call 动作,因此模型不是临时外挂工具,而是在训练阶段就学会了“什么时候点界面,什么时候调工具”。在 MobileWorld 的 MCP 工具调用子任务中,MAI-UI 达到 37.5% 成功率,比表现最好的其他 GUI agent 模型高 32.1 个百分点。
端云协同:2B 常驻本地,32B 按需接力
纯端侧方案和纯云端方案各有明显短板。
| 方案 | 优点 | 问题 |
|---|---|---|
| 纯端侧 | 隐私边界清晰,延迟低,不强依赖网络 | 小模型难以处理复杂长任务 |
| 纯云端 | 大模型规划和推理更强 | 网络依赖高,成本高,敏感上下文上传风险更大 |
| 端云协同 | 本地处理日常任务,复杂非敏感任务再上云 | 需要可靠的敏感信息判断和接力机制 |
MAI-UI 使用轻量 MAI-UI-2B 模型常驻手机端。它不只是执行简单 GUI 操作,还承担轨迹监控职责:判断当前路径是否还在朝用户目标推进。
当本地任务卡住,并且上下文不包含密码、短信、身份证号等敏感信息时,系统会触发云端 32B 模型接力。接力时,本地模型会生成一份简洁错误摘要,帮助云端模型快速理解失败原因,而不是从头重跑整个任务。
图中展示了这种端云协同方式:本地模型负责日常操作和敏感判断,非敏感复杂任务可以交给云端模型恢复,敏感操作则留在本地完成。
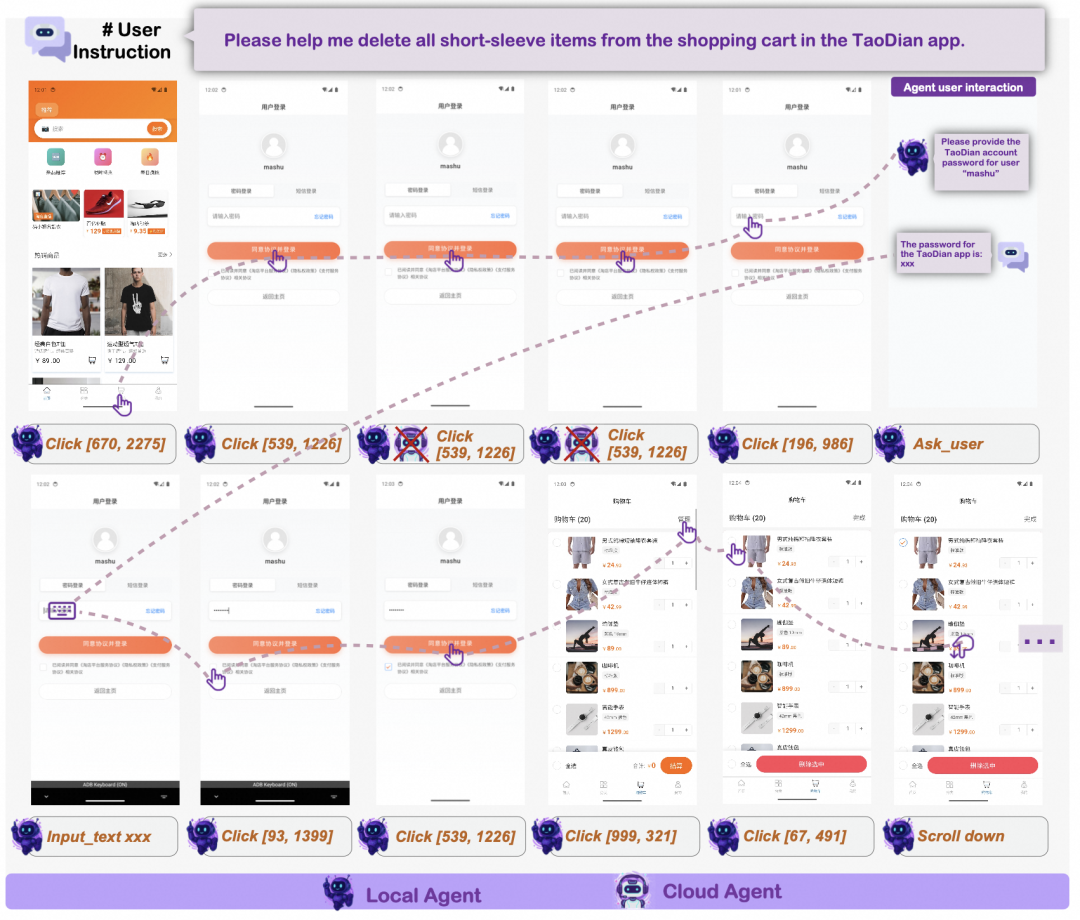
可以把端云调度抽象成下面的状态机:
flowchart TD
A[端侧 2B 模型执行任务] --> B{轨迹是否正常?}
B -- 正常 --> C[继续本地执行]
B -- 卡住或偏离 --> D{上下文是否敏感?}
D -- 敏感 --> E[保持本地执行或请求用户确认]
D -- 非敏感 --> F[生成错误摘要]
F --> G[云端 32B 模型接力]
G --> H[恢复任务上下文并继续执行]
在 AndroidWorld 评测中,这套机制让端侧任务成功率提升 33%,同时云端模型调用减少超过 40%。这个结果说明端云协同不是简单“遇到问题就上云”,而是让本地模型先承担可处理的部分,只在必要时调用更大的模型。
动态强化学习:真实环境不是静态截图
GUI 智能体如果只在静态界面上训练,很容易记住某个按钮位置,却不一定能处理真实环境里的变化。
真实手机环境里常见干扰包括:
- 权限弹窗突然出现;
- App 跳转到错误页面;
- 操作后没有响应;
- 按钮位置变化;
- 列表内容刷新;
- 输入框被键盘遮挡;
- 返回键把智能体带回了主屏幕。
MAI-UI 使用动态环境中的在线强化学习来增强稳健性。训练时不仅让模型看到正常轨迹,还会注入弹窗、权限提示、UI 偏移等扰动,并支持最长 50 步的超长轨迹训练。
图中展示了一个删除重复支出记录的任务。模型即使被带到错误 App、反复回到主屏幕、点击无响应,也会继续检查当前状态、回退或重新定位,最终完成目标。
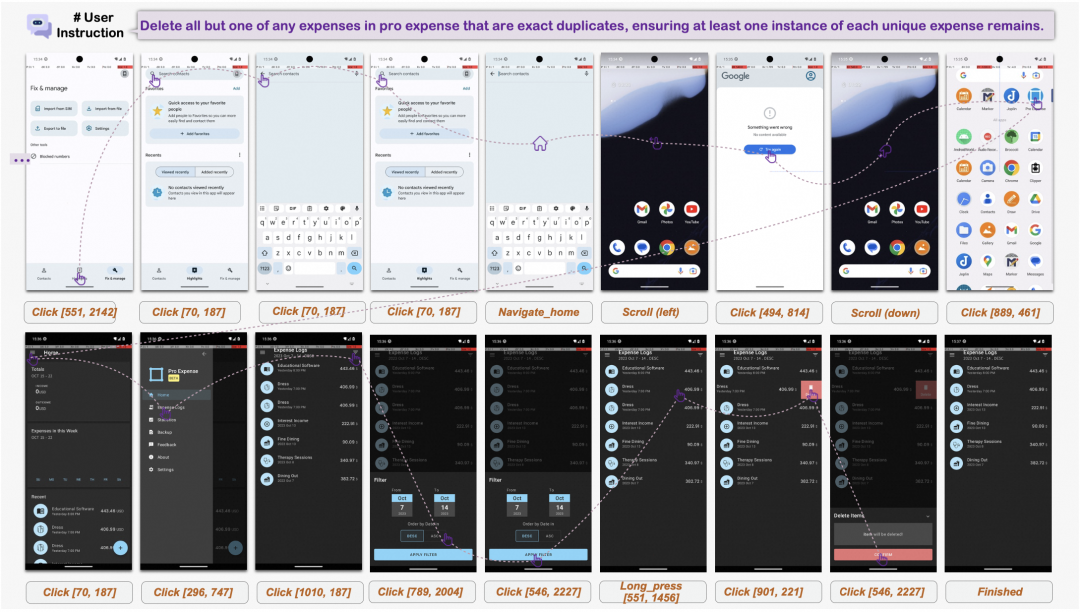
这种训练方式的重点不是让模型记住某个 App 的固定路径,而是让它学会三件事:
- 识别偏航:当前界面是否还属于目标任务路径;
- 尝试恢复:返回、重新搜索、重新定位入口;
- 验证结果:不是点完就结束,而是确认用户目标是否真的达成。
在 AndroidWorld 上,动态强化学习带来了多尺寸模型的稳定增益:
| 模型规模 | AndroidWorld 成功率变化 |
|---|---|
| 2B | +3.0 |
| 8B | +6.0 |
| 32B | +2.5 |
对 GUI 智能体来说,这类增益比单纯提高某个按钮定位准确率更重要,因为真实任务失败往往发生在第十几步之后,而不是第一步。
模型家族:从端侧到大规模规划模型
MAI-UI 覆盖多个尺寸,分别面向不同运行环境。
| 模型 | 主要定位 | 适合场景 |
|---|---|---|
| 2B | 端侧常驻模型 | 加购、查日历、基础 GUI 操作、轨迹监控、隐私场景 |
| 8B | 中等规模模型 | 更复杂的跨 App 任务,兼顾资源占用 |
| 32B | 云端接力模型 | 复杂规划、失败恢复、多步骤任务 |
| 235B-A22B | 大规模模型 | 高复杂度任务、复杂推理和规划上限探索 |
这种模型家族的价值在于:并不是所有任务都需要最大模型。端侧 2B 模型适合承担高频、低风险、隐私敏感的任务;云端模型适合处理本地模型难以规划或恢复的复杂任务。
评测结果:不只看定位,还要看任务执行
GUI 智能体通常有两类评测:
- GUI Grounding / 视觉定位:给出目标元素,让模型指出屏幕位置;
- GUI 任务执行:给出用户目标,让模型连续操作直到完成任务。
视觉定位是基础能力,但任务执行更接近真实使用。MAI-UI 在两类评测里都有较强表现。
图中汇总了 MAI-UI 在多个 GUI 视觉定位和任务执行基准上的结果,包括 ScreenSpot-Pro、UI-Vision、MMBench-GUI L2、OSWorld-G、ScreenSpot-v2、AndroidWorld 和 MobileWorld 等。

关键结果可以整理成表格:
| 能力方向 | 评测集 | 结果 |
|---|---|---|
| GUI 视觉定位 | ScreenSpot-Pro | MAI-UI-32B 准确率 73.5% |
| GUI 视觉定位 | UI-Vision | 32B 与 8B 相比同尺寸模型提升 10 分以上 |
| GUI 任务执行 | AndroidWorld | MAI-UI-235B-A22B 成功率 76.7% |
| 主动交互 | MobileWorld | 相比端到端模型领先 18.7 个百分点 |
| MCP 工具调用 | MobileWorld | 成功率 37.5%,领先 32.1 个百分点 |
| 动态强化学习 | AndroidWorld | 2B、8B、32B 分别提升 3.0、6.0、2.5 |
这些数字说明 MAI-UI 的能力不是只靠单点视觉定位堆出来的。主动交互、MCP 调用、端云协同和动态强化学习都在不同子任务里产生了可观差异。
MobileWorld:更接近真实手机任务的评测基准
AndroidWorld 是常见 GUI 智能体评测基准,但很多任务仍然偏短、偏静态。MobileWorld 进一步提高了任务复杂度,目标是模拟更真实的手机使用场景。
MobileWorld 的几个特征比较重要:
| 特征 | 含义 |
|---|---|
| 平均 27.8 步 | 长程任务更多,容易暴露中途偏航问题 |
| 超过 60% 任务跨 App | 需要购物、出行、办公、社交等多个 App 协作 |
| 智能体-用户交互任务 | 用户指令可能模糊,模型需要主动澄清 |
| MCP-GUI 混合任务 | 任务同时包含外部工具调用和 GUI 操作 |
| Docker 复现 | 环境更容易复现,降低评测漂移 |
| 自托管 App 生态 | 避免真实线上 App 变化导致评测不稳定 |
MobileWorld 的难度也体现在整体成功率上:当前最佳模型成功率只有 51.7%,端到端模型最高只有 20.9%。这类结果提醒我们,GUI 智能体距离“任意手机任务都能自动完成”还有明显距离,尤其是在长程、多 App、带工具调用和交互澄清的场景里。
适合什么场景,不适合什么场景
MAI-UI 这类 GUI 智能体适合处理“人平时靠界面完成,但流程又很长”的任务。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 跨 App 出行规划、写入笔记、发送消息 | 适合 | 同时需要查询、筛选、写入和沟通 |
| 办公流转,例如改会议、同步群消息 | 适合 | GUI 操作和上下文理解都很重要 |
| 地图、GitHub、Arxiv 等可工具化查询 | 适合 | MCP 可以减少大量不稳定点击 |
| 支付密码、短信验证码、证件号输入 | 谨慎 | 应留在端侧或要求用户确认 |
| 后端已有稳定 API 的批处理任务 | 不一定需要 | 直接写脚本或服务端任务通常更可靠 |
| 强验证码、反自动化限制明显的 App | 不适合 | GUI 智能体不应绕过平台安全机制 |
| 对结果必须 100% 正确的高风险操作 | 需要人工确认 | 当前评测成功率还没达到完全自动化水平 |
一个实用判断标准是:如果任务本来就可以用确定性 API 完成,优先写程序;如果任务必须穿过多个 App 的 GUI,并且还需要理解页面内容、处理异常和确认上下文,GUI 智能体才有发挥空间。
怎么上手
MAI-UI 和 MobileWorld 都已经开放仓库,可以从模型、论文和评测环境三个入口了解。
git clone https://github.com/Tongyi-MAI/MAI-UI.git
git clone https://github.com/Tongyi-MAI/MobileWorld.git
相关资源:
| 资源 | 地址 |
|---|---|
| MAI-UI GitHub | https://github.com/Tongyi-MAI/MAI-UI |
| MAI-UI Arxiv | http://arxiv.org/abs/2512.22047 |
| MobileWorld GitHub | https://github.com/Tongyi-MAI/MobileWorld |
| MobileWorld Arxiv | https://arxiv.org/abs/2512.19432 |
MobileWorld 仓库提供 Docker 复现方式和自托管 App 生态,适合用来验证 GUI 智能体在长程任务、跨 App 协作、主动澄清和 MCP-GUI 混合任务上的表现。
关键结论
MAI-UI 的价值不在于“更会点击按钮”,而在于重新定义了 GUI 智能体的执行方式:
- 指令模糊时主动问清楚;
- 可结构化求解时优先调用 MCP 工具;
- 简单和敏感任务留在端侧;
- 复杂非敏感任务再交给云端大模型;
- 通过动态强化学习适应真实环境中的弹窗、跳转和失败恢复。
GUI 智能体要进入真实手机和办公场景,单靠视觉定位准确率不够。长程任务、跨 App 协作、隐私边界、工具调用和异常恢复,才是决定它能不能稳定完成任务的关键。