使用大型语言模型(LLM,Large Language Model)做应用时,Prompt 迟早会变长。
在检索增强生成(RAG,Retrieval-Augmented Generation)系统里,用户问一句话,后端可能要拼上多段检索文档;在聊天机器人里,为了保留上下文,历史对话会不断追加;在 Agent 场景里,工具说明、约束规则、中间状态也会进入 Prompt。Prompt 越长,问题越明显:
| 问题 | 具体影响 |
|---|---|
| 成本上升 | API 通常按输入 token 和输出 token 计费,输入越长越贵 |
| 延迟增加 | 模型需要处理更多上下文,首 token 时间和总响应时间都会变长 |
| 容易超上下文窗口 | 超过模型最大上下文后,请求会失败或必须截断 |
| 信息被稀释 | 大模型不一定能稳定关注长上下文里的关键位置,尤其是中间段落 |
LLMLingua 解决的是这个问题:在 Prompt 发给目标大模型之前,先做一次压缩,只保留对任务有用的信息。
它不是简单地把前半段删掉,也不是让大模型再总结一遍,而是用一个更小、更便宜的模型或专门训练出的 token 分类器,判断哪些内容可以删、哪些内容必须留。
典型调用链可以理解成这样:
flowchart LR
A[用户问题] --> B[检索文档 / 历史对话 / 工具信息]
B --> C[原始长 Prompt]
C --> D[LLMLingua Prompt 压缩器]
D --> E[压缩后的 Prompt]
E --> F[目标大模型<br/>GPT-4 / Claude / LLaMA 等]
F --> G[最终回答]
压缩发生在目标大模型之前,所以它可以减少真正昂贵的那部分输入 token。根据论文实验,LLMLingua 在一些任务上可以做到约 20 倍压缩,同时保持较小的效果损失。实际压缩比例要看任务类型、文本冗余程度、压缩模型和目标 token 数,不能只看一个固定数字。
Prompt 压缩和普通摘要有什么区别
很多人看到“压缩 Prompt”,第一反应是让一个模型先总结上下文。但 LLMLingua 的思路更接近“删冗余”,而不是“重写全文”。
两者差别很大:
| 方法 | 做法 | 风险 |
|---|---|---|
| 摘要 | 把长文本改写成短文本 | 可能改写事实、丢掉数字、改变语气或引入幻觉 |
| 截断 | 只保留前 N 个或后 N 个 token | 关键证据可能刚好被截掉 |
| Prompt 压缩 | 尽量删掉低价值 token,保留任务相关片段 | 压缩过强时仍可能丢信息,需要评估 |
LLMLingua 更适合那些“信息很长但有冗余”的输入,例如 RAG 检索结果、会议记录、长对话历史。它的目标不是生成一段漂亮的摘要,而是让目标大模型仍然能完成原任务。
LLMLingua 系列的技术演进
LLMLingua 不是一个单点方案,而是一组逐步演进的 Prompt 压缩技术。主要可以分成四条线:
timeline
title LLMLingua 系列演进
2023 : LLMLingua
: 使用小型因果语言模型估计 token 重要性
: 粗到细三层压缩框架
2024 : LongLLMLingua
: 面向长文档和 RAG
: 解决长上下文中间信息容易被忽略的问题
2024 : LLMLingua-2
: 从困惑度方法转向 token 分类
: 使用 GPT-4 蒸馏数据训练专用压缩模型
2025 : SecurityLingua
: 把安全感知压缩用于越狱攻击防御
: 通过压缩暴露提示中的真实意图
LLMLingua:粗到细的三层压缩
早期 LLMLingua 的核心思想是:用一个较小的语言模型来估计 Prompt 中每个 token 的重要性。
它使用的指标之一是困惑度(Perplexity)。如果某些 token 对小模型来说非常容易预测,说明它们通常信息量较低,删除后对整体语义影响可能较小;如果某些 token 难以预测,往往包含名称、数字、关键实体、推理条件或任务相关内容,更应该保留。
完整压缩流程不是直接按 token 排序删除,而是分成三层:
flowchart TD
A[原始 Prompt] --> B[预算控制器]
B --> C[粗粒度筛选<br/>段落 / 示例 / 文档块]
C --> D[细粒度压缩<br/>逐 token 判断保留或删除]
D --> E[压缩 Prompt]
E --> F[目标大模型]
B -.-> B1[决定总压缩率<br/>或目标 token 数]
C -.-> C1[先删明显低价值片段]
D -.-> D1[再处理句子内部冗余 token]
三层分别承担不同工作:
| 层级 | 作用 |
|---|---|
| 预算控制器 | 根据目标 token 数或压缩率,决定整体压缩强度 |
| 粗粒度筛选 | 在段落、示例、文档块级别先删掉明显不重要的部分 |
| 细粒度压缩 | 在 token 级别继续删冗余内容,尽量保留语义核心 |
这种设计比直接逐 token 删除更稳。因为长 Prompt 通常由多个结构组成,比如 instruction、few-shot 示例、检索文档、用户问题。如果不区分结构,可能会把关键问题或重要示例压坏。
LLMLingua 还引入了对齐思路:压缩模型虽然是小模型,但压缩后的文本最终要交给目标大模型理解,因此压缩器需要尽量贴近目标大模型的语言分布。简单说,压缩器删完之后,目标大模型仍然要“看得懂”。
LongLLMLingua:面向长文档和 RAG
长上下文里有一个常见现象:模型更容易关注开头和结尾,对中间位置的信息不够稳定。这个问题常被称为 “Lost in the Middle”,也就是长上下文中间信息丢失。
RAG 场景尤其容易遇到这个问题。检索系统返回多段文档后,关键证据可能排在中间;即使这些证据没有被截断,目标大模型也可能没有充分利用。
LongLLMLingua 针对这个问题做了几件事:
| 机制 | 解决的问题 |
|---|---|
| 问题感知压缩 | 根据用户问题判断哪些文档块更相关,而不是均匀压缩所有内容 |
| 文档重排序 | 把重要内容放到更容易被模型关注的位置,例如开头或结尾 |
| 动态预算分配 | 给关键文档更多 token 预算,给弱相关文档更高压缩率 |
它的处理链路可以概括为:
flowchart LR
A[用户问题] --> B[检索到的长文档集合]
B --> C[按问题计算相关性]
C --> D[动态分配压缩预算]
D --> E[重排序重要文档]
E --> F[压缩文档内容]
F --> G[目标大模型生成答案]
LongLLMLingua 的重点不只是“压短”,而是“把有限 token 留给更可能回答问题的内容”。对于 RAG 系统,这一点比单纯追求压缩率更重要。
LLMLingua-2:从困惑度变成 token 分类
LLMLingua-2 的变化更大。它不再主要依赖因果语言模型计算困惑度,而是把压缩任务改成 token 分类任务:对输入里的每个 token 判断“保留”还是“删除”。
flowchart TD
A[原始文本] --> B[Tokenizer]
B --> C[双向编码器<br/>如 XLM-RoBERTa]
C --> D[Token 分类头]
D --> E{每个 token 是否保留}
E -->|保留| F[压缩 Prompt]
E -->|删除| G[丢弃]
这个范式有几个好处。
因果语言模型只能从左到右看上下文,而 BERT 类编码器是双向的,可以同时看到 token 的前文和后文。判断一个 token 是否重要时,双向上下文通常更有优势。例如一个数字、实体名、条件短语是否关键,很多时候要看它所在句子的完整语境。
LLMLingua-2 还使用了数据蒸馏:让 GPT-4 对大量文本生成压缩结果,再用这些结果训练较小的分类模型。这样小模型可以学习强模型的压缩偏好,但推理时成本更低。
对比三代方案可以看得更清楚:
| 方案 | 主要方法 | 适合场景 | 特点 |
|---|---|---|---|
| LLMLingua | 小型因果语言模型 + 困惑度 + 粗到细压缩 | 通用长 Prompt 压缩 | 思路直观,压缩粒度细 |
| LongLLMLingua | 问题感知压缩 + 文档重排序 + 动态预算 | RAG、长文档问答 | 更关注任务相关性和长上下文位置问题 |
| LLMLingua-2 | GPT-4 蒸馏数据 + 双向编码器 + token 分类 | 多任务通用压缩 | 模型更小,压缩速度更快,任务迁移能力更强 |
LLMLingua-2 的压缩模型参数规模可以降到数亿级别,相比 7B 级别的压缩模型更容易部署,压缩速度也更适合在线服务。
SecurityLingua:把压缩用于安全防御
Prompt 压缩还可以用于安全场景。SecurityLingua 的思路是:很多越狱提示会混入大量噪声、角色扮演、干扰性指令和绕行话术,用来掩盖真实意图。安全感知压缩可以剥离一部分噪声,让模型更容易识别用户真正想做什么。
它的防御链路大致如下:
flowchart TD
A[用户输入] --> B[安全感知 Prompt 压缩器]
B --> C[提取后的真实意图]
A --> D[原始输入]
C --> E[安全系统提示]
D --> F[目标大模型]
E --> F
F --> G[安全约束下的回答]
这种做法不是直接改写用户输入,而是额外提取一条“意图信号”,再把它提供给目标模型或安全模块。它的价值在于让隐藏在噪声里的危险请求更明显。
安全压缩不应该被理解成万能防线。它更适合作为多层防护的一部分,和内容审核、策略模型、系统提示约束、输出过滤一起使用。压缩器如果误删关键信息,也可能产生漏判或误判,所以必须用攻击样本和正常样本一起评估。
安装和基本使用
LLMLingua 已经发布到 PyPI,可以直接安装:
pip install llmlingua
最小使用示例:
from llmlingua import PromptCompressor
# 初始化压缩器
llm_lingua = PromptCompressor()
prompt = """
Sam bought a dozen boxes, each with 30 highlighter pens inside,
for $10 each box. He gave 5 boxes to his classmates and sold the rest...
"""
result = llm_lingua.compress_prompt(
prompt,
instruction="",
question="",
target_token=200,
)
print(result["compressed_prompt"])
print("origin_tokens:", result["origin_tokens"])
print("compressed_tokens:", result["compressed_tokens"])
print("ratio:", result["ratio"])
print("saving:", result.get("saving"))
返回结果通常是一个字典,结构类似:
{
"compressed_prompt": "Question: Sam bought a dozen boxes each with 30 highlighter pens...",
"origin_tokens": 2365,
"compressed_tokens": 211,
"ratio": "11.2x",
"saving": "Saving $0.1 in GPT-4."
}
几个字段的含义:
| 字段 | 含义 |
|---|---|
| compressed_prompt | 压缩后的 Prompt |
| origin_tokens | 原始 token 数 |
| compressed_tokens | 压缩后 token 数 |
| ratio | 压缩倍率 |
| saving | 按指定目标模型估算的费用节省 |
如果要指定压缩模型,可以在初始化时传入模型名称:
from llmlingua import PromptCompressor
# 使用更强的压缩模型
llm_lingua = PromptCompressor("microsoft/phi-2")
显存有限时,可以使用量化模型。量化模型通常需要额外依赖:
pip install optimum auto-gptq
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor(
"TheBloke/Llama-2-7b-Chat-GPTQ",
model_config={"revision": "main"},
)
如果使用 LLMLingua-2,通常会选择项目提供的专用压缩模型。不同版本的库参数可能略有差异,实际以安装版本和项目文档为准。常见形式如下:
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor(
model_name="microsoft/llmlingua-2-bert-base-multilingual-cased-meetingbank",
use_llmlingua2=True,
)
result = llm_lingua.compress_prompt(
prompt,
rate=0.33,
force_tokens=["\n", "?", ".", ","],
)
print(result["compressed_prompt"])
force_tokens 可以要求压缩器尽量保留某些符号或结构,对问答、列表、代码片段比较有用。
在 RAG 系统里怎么接入
RAG 里最常见的接入方式,是在检索完成之后、调用目标大模型之前压缩上下文。
sequenceDiagram
participant U as 用户
participant A as 应用服务
participant R as 检索系统
participant C as LLMLingua
participant L as 目标大模型
U->>A: 提问
A->>R: 检索相关文档
R-->>A: 返回 Top-K 文档
A->>C: 压缩文档上下文
C-->>A: 返回压缩 Prompt
A->>L: 发送 instruction + question + compressed context
L-->>A: 生成答案
A-->>U: 返回结果
示例代码:
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
instruction = "根据给定上下文回答问题。如果上下文中没有答案,直接说明无法确定。"
question = "LLMLingua 为什么适合 RAG 场景?"
docs = [
"文档 1:RAG 系统会把检索到的多个文档片段拼接进 Prompt...",
"文档 2:长上下文会增加推理成本,并可能导致模型忽略中间信息...",
"文档 3:Prompt 压缩可以在保留关键语义的同时减少 token 数...",
]
context = "\n\n".join(docs)
compressed = llm_lingua.compress_prompt(
context,
instruction=instruction,
question=question,
target_token=800,
)
final_prompt = f"""
{instruction}
上下文:
{compressed["compressed_prompt"]}
问题:
{question}
"""
print(final_prompt)
这里有一个重要习惯:不要把用户问题和核心系统指令压得太狠。通常更稳的做法是压缩检索文档和历史对话,把系统指令、工具约束、用户最终问题保留得更完整。
Hugging Face Demo 的压缩效果
LLMLingua 提供了 Hugging Face Demo,可以直接输入长 Prompt 观察压缩前后的 token 数。下面这个示例展示了一次压缩结果:原始输入为 2428 tokens,压缩后变成 331 tokens。
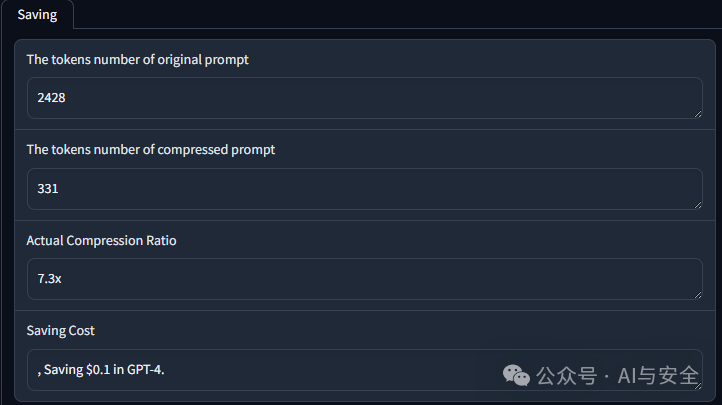
这个结果大约是 7.3 倍压缩。它说明两点:一是实际应用里确实存在大量可删冗余;二是压缩倍率不是固定值,同一套工具在不同文本、不同任务、不同目标 token 设置下会有不同结果。
适合和不适合的场景
LLMLingua 适合放在“长输入、高调用成本、允许少量信息损失”的位置。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| RAG 多文档问答 | 适合 | 检索结果通常有冗余,压缩能减少输入 token |
| 长对话历史压缩 | 适合 | 旧轮次对话可以按相关性保留 |
| 会议记录问答 | 适合 | 长文本里有大量口语填充和重复表达 |
| Agent 工具日志 | 适合 | 中间状态可能很长,很多细节不需要完整传给模型 |
| 精确引用合同条款 | 谨慎 | 删除一个否定词、金额或日期都可能改变含义 |
| 代码生成和代码审查 | 谨慎 | 标点、缩进、变量名、边界条件都可能关键 |
| 安全系统提示 | 不建议强压缩 | 安全规则丢失会直接改变模型行为 |
| 极短 Prompt | 不适合 | 压缩器本身也有开销,收益很小 |
使用时容易踩的坑
只看压缩率,不看任务效果
压缩率越高,不一定越好。真正要看的指标是下游任务效果,例如问答准确率、引用命中率、人工评审结果、拒答正确率等。
一个实用评估表可以这样设计:
| 指标 | 说明 |
|---|---|
| token 节省比例 | 输入 token 减少多少 |
| 平均延迟 | 加上压缩器后端到端耗时是否下降 |
| 回答准确率 | 压缩后答案是否仍然正确 |
| 证据覆盖率 | RAG 中关键证据是否仍在压缩 Prompt 里 |
| 失败样本类型 | 哪类问题最容易被压坏 |
如果压缩器本身耗时很高,而目标模型调用并不贵,端到端收益可能并不明显。高并发线上系统尤其要测整体链路,而不是只测目标模型输入 token。
数字、实体和否定词容易出问题
长文本压缩时,最怕删掉这些内容:
- 金额、日期、比例、单位;
- 人名、公司名、产品名;
- “不”“不能”“除非”“仅当”这类条件或否定词;
- 代码里的符号、变量名、缩进;
- 法律、医疗、金融文本中的限定范围。
对这类任务,应该降低压缩强度,或通过 force_tokens、结构化模板、字段抽取等方式保护关键信息。
RAG 文档不要平均压缩
如果 10 个检索文档里只有 2 个真正相关,平均压缩每个文档不是好策略。更合理的做法是先按问题相关性排序,再给高相关文档更多 token 预算。
这也是 LongLLMLingua 更适合 RAG 的原因:它不只是缩短文本,还会围绕用户问题调整压缩策略。
中文场景要选合适模型
如果输入主要是中文,优先选择支持多语言的压缩模型,尤其是 LLMLingua-2 中基于 multilingual BERT 或 XLM-RoBERTa 的模型。英文模型直接压中文,可能会出现 token 粒度不稳定、关键信息误删的问题。
不要压缩所有内容
一条请求里不同部分的重要性不同:
| Prompt 部分 | 建议 |
|---|---|
| system prompt | 尽量不压缩,尤其是安全和格式约束 |
| developer/tool 说明 | 谨慎压缩,保留函数名、参数、约束 |
| 用户最终问题 | 尽量不压缩 |
| 检索文档 | 适合压缩 |
| 历史对话 | 适合按相关性压缩 |
| 中间日志 | 适合压缩或摘要化 |
更稳的做法是分段处理,而不是把所有内容拼成一坨再交给压缩器。
项目和 Demo 地址
LLMLingua 开源项目:
https://github.com/microsoft/LLMLingua
Hugging Face Demo:
https://huggingface.co/spaces/microsoft/LLMLingua
https://huggingface.co/spaces/microsoft/LLMLingua-2
LLMLingua 的核心价值在于,把“长 Prompt 带来的成本和延迟”变成一个可控的工程问题。RAG、长对话和长文档问答里,如果上下文经常膨胀到几千甚至几万 token,Prompt 压缩可以作为模型调用前的一层预处理;但压缩强度、模型选择和评估指标必须结合业务任务来定,不能只追求 token 数字变小。