AI 编程工具已经从“补全几行代码”的辅助功能,变成了可以参与模块实现、测试生成、缺陷修复甚至代码重构的工程工具。它带来的问题也不再只是“生成得准不准”,而是生成代码进入真实仓库后,是否会扩大软件系统的安全风险。
一个关键判断是:功能正确不等于安全正确。代码能跑通单元测试,只能说明它满足了当前测试覆盖到的行为;如果输入校验、权限边界、数据流处理、密码学 API 使用不当,漏洞仍然可能被引入生产系统。
AI 编程能力的变化可以概括为从“局部补全”走向“上下文理解”和“任务级生成”。
这条演进路径说明,AI 不再只影响代码编辑器里的小片段,而是在需求实现、代码审查、测试补齐、缺陷修复等环节逐步参与软件生命周期。参与越深,安全责任越不能只靠开发者的直觉来兜底。
核心结论
真实项目中的 AI 生成代码呈现出几个稳定特征:
| 观察维度 | 结论 | 工程含义 |
|---|---|---|
| 使用趋势 | AI 生成代码经历了快速探索、理性回调、稳定协作三个阶段 | 团队会从“什么都让 AI 试试”转向“只在可验证场景使用 AI” |
| 语言分布 | Python、JavaScript、TypeScript 中占比更高,Rust、C++ 等系统级语言中更低 | 生态语料越多、语法越宽松、样板代码越多,AI 越容易被采纳 |
| 漏洞生命周期 | AI 既可能引入漏洞,也可能辅助修复漏洞 | 风险不在于是否使用 AI,而在于使用场景、审查方式和验证强度 |
| 漏洞类型 | 更集中在输入验证、数据处理、不安全 API 调用等局部实现问题 | 适合用静态分析、规则扫描、代码审查清单提前拦截 |
| 攻击面 | AI 引入漏洞的严重度不低于人工代码,并更容易集中在网络侧接口 | Web API、协议处理、远程调用相关代码需要更严格审核 |
AI 生成代码不是天然危险,也不是天然安全。它更像一个高产但需要约束的代码贡献者:擅长生成模式化代码,但对安全上下文、业务约束和长期维护后果缺少稳定判断。
AI 生成代码在开源生态中的演进
基于 GitHub Top 1000 项目历史 commit 的分析,AI 生成代码的渗透过程并不是一条持续上升的直线,而是经历了明显的阶段变化。
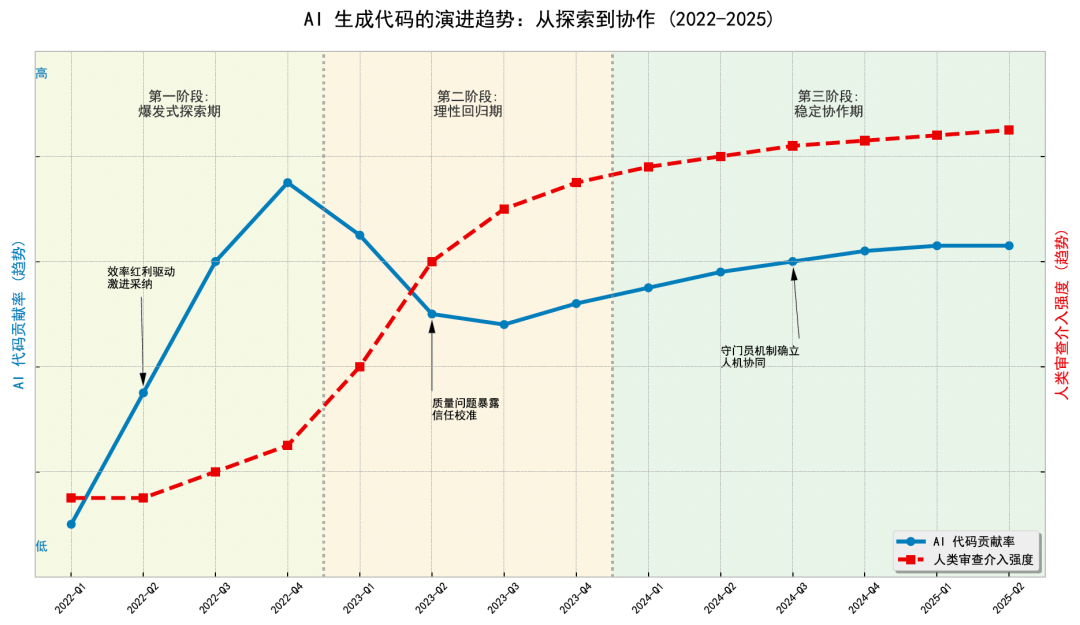
这个变化可以拆成三个阶段理解。
爆发式探索期:低门槛工具推动快速扩散
AI 编程工具以集成开发环境(Integrated Development Environment,IDE)插件、在线补全、聊天式生成等形态出现后,接入成本很低。开发者只需要在编辑器里描述需求,工具就能生成函数、类、测试用例或配置代码。
在这个阶段,AI 生成代码的占比会快速上升,原因很直接:
- 生成样板代码比手写更快;
- 常见业务逻辑有大量训练语料可参考;
- 开发者愿意尝试把重复劳动交给工具;
- 新增代码通常比维护旧代码更容易让 AI 参与。
但快速采纳也会带来一个副作用:生成结果被过度信任。代码看起来风格规范、变量命名合理,并不代表它理解了系统的权限模型、输入边界和异常路径。
理性回归期:复杂工程暴露 AI 的边界
当 AI 进入更复杂的工程场景,局限会逐渐显现。典型问题包括:
- 长上下文理解不稳定,跨文件依赖容易遗漏;
- 对业务语义理解不足,可能生成“局部正确、整体错误”的代码;
- 非功能性需求容易被忽略,例如安全、性能、可观测性、兼容性;
- 调试和维护成本可能抵消生成时节省的时间。
开发者在高风险代码上会变得谨慎,例如认证鉴权、支付、加密、网络协议解析、内存管理、核心架构改造等场景。这类代码如果出错,影响往往不是一个函数失败,而是权限绕过、数据泄露、服务不可用或远程攻击面扩大。
稳定协作期:AI 进入可验证、可审查的开发模式
近期更合理的模式是人机协作,而不是让 AI 替代开发者独立完成关键决策。AI 更适合承担高重复、模式化、容易验证的任务,例如:
| 更适合 AI 参与的任务 | 原因 |
|---|---|
| 单元测试补齐 | 输入输出边界明确,结果容易验证 |
| 文档和注释生成 | 对系统风险影响较低,审查成本可控 |
| 样板代码生成 | 模式固定,容易通过静态规则检查 |
| 简单重构 | 可借助测试回归验证行为是否变化 |
| 漏洞修复草案 | 能节省实现时间,但必须经过人工审查和安全测试 |
不适合直接交给 AI 独立完成的任务也很清晰:
| 高风险任务 | 风险点 |
|---|---|
| 鉴权和访问控制 | 少一个边界判断就可能导致越权 |
| 密码学实现 | 容易使用过时算法或错误模式 |
| SQL、命令、模板拼接 | 输入处理不当会引入注入漏洞 |
| 网络协议解析 | 远程可触发,攻击面大 |
| C/C++ 内存操作 | 越界、释放后使用等问题后果严重 |
| 安全补丁最终决策 | 修复是否完整需要理解漏洞根因 |
不同编程语言中的 AI 生成代码分布
AI 生成代码在不同语言中的占比并不均衡,这和训练数据规模、语言特性、工程习惯都有关系。
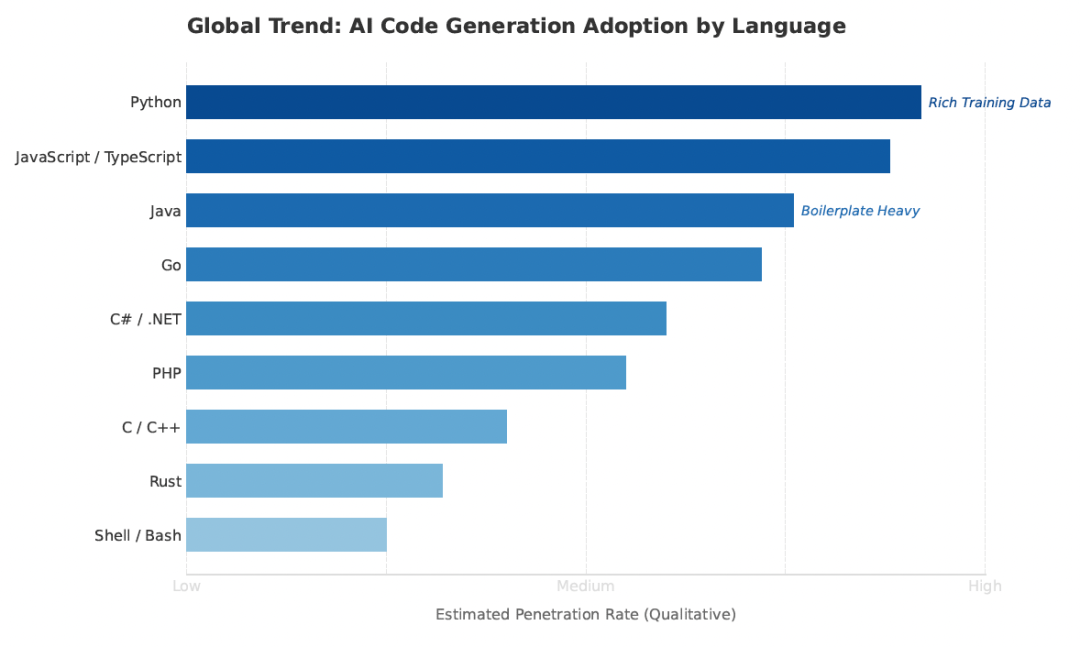
Python、JavaScript、TypeScript 这类语言占比更高,主要有三个原因:
- 开源语料充足,模型见过大量相似写法;
- 语法相对灵活,生成代码更容易通过解释器或构建工具;
- Web、脚本、数据处理等场景中有大量重复模式。
Java、Go 等语言也适合 AI 参与一部分工作,尤其是接口定义、数据传输对象、测试代码、错误处理模板等重复结构。虽然类型系统更严格,但也正因为结构稳定,AI 更容易生成符合框架风格的代码。
Rust、C++ 等系统级语言中采纳程度较低。原因并不是 AI 完全不能写,而是这些语言对生命周期、所有权、内存安全、并发模型或底层细节要求更高。开发者通常会更谨慎地审查生成结果,因为一个看似微小的错误可能导致崩溃、未定义行为或安全漏洞。
AI 在漏洞生命周期中的双重角色
AI 生成代码和漏洞之间的关系不是单向的。它既可能成为漏洞来源,也可能成为修复助手。
基于已披露 CVE(Common Vulnerabilities and Exposures,通用漏洞披露)相关修复 commit 的分析,可以观察到修复前后代码来源的变化。
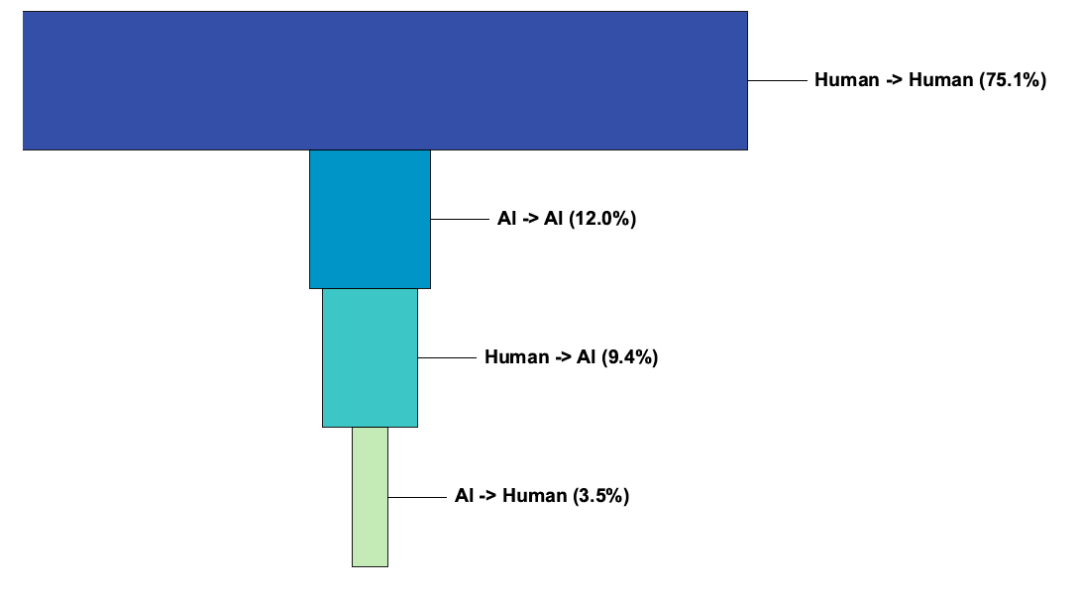
数据中有两个方向值得关注:
- 在 3.5% 的漏洞修复中,原本由 AI 生成的代码被人工代码替换;
- 在 9.4% 的 CVE 修复中,原本由人工编写的代码在修复后转为 AI 生成代码。
这说明 AI 在漏洞生命周期中有两种完全不同的角色。
flowchart LR
A[AI 生成实现] --> B[进入仓库]
B --> C{是否存在安全缺陷}
C -- 是 --> D[CVE 或安全问题暴露]
D --> E[人工重写高风险逻辑]
C -- 否 --> F[继续维护]
G[人工代码存在漏洞] --> H[定位漏洞根因]
H --> I[AI 辅助生成修复草案]
I --> J[人工审查与测试验证]
J --> K[合入修复]
当 AI 生成代码位于高风险逻辑中,并且缺少足够审查时,它可能成为漏洞来源。开发者在修复阶段选择人工重写,通常是为了获得更强的可控性。
另一种情况是,漏洞根因已经明确,开发者借助 AI 快速生成修复草案、补测试、调整重复逻辑。只要修复经过人工审查、静态分析和回归测试,AI 可以压缩修复周期。
关键不在于“禁止 AI”,而在于给 AI 划定边界:它可以提高实现速度,但不能替代漏洞根因分析和安全决策。
AI 生成代码更容易引入哪些漏洞
AI 引入的漏洞有比较明显的模式化特征。它们通常不是复杂业务规则理解错误,而是集中在代码片段层面的实现缺陷。
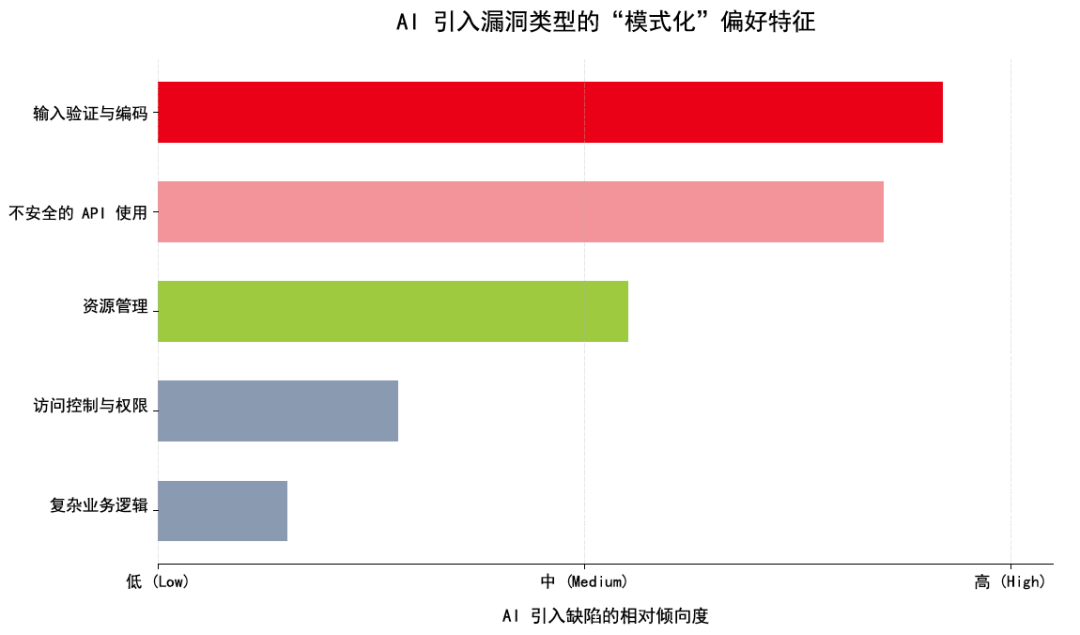
风险更容易集中在两类场景。
输入验证与数据处理不当
当代码处理外部输入时,AI 可能遗漏校验、过滤、转义、编码等安全步骤。比如生成 SQL 查询时,它可能更关注功能是否能查到数据,而不是输入是否会改变查询语义。
不安全示例:
def get_user(conn, username):
sql = f"SELECT id, username, role FROM users WHERE username = '{username}'"
return conn.execute(sql).fetchone()
更安全的写法是参数化查询:
def get_user(conn, username):
sql = "SELECT id, username, role FROM users WHERE username = ?"
return conn.execute(sql, (username,)).fetchone()
类似问题还会出现在 HTML 输出、命令执行、路径拼接、JSON/XML 解析、模板渲染等位置。AI 很容易生成“看起来能用”的代码,但没有把输入当成不可信数据处理。
不安全 API 调用
AI 可能复用训练数据中常见但已经不推荐的写法,尤其是在密码学、随机数、反序列化、文件处理等场景中。
例如,密码摘要场景中仍然可能生成 MD5:
const crypto = require("crypto");
function hashPassword(password) {
return crypto.createHash("md5").update(password).digest("hex");
}
这里的问题不是语法错误,而是安全语义错误。MD5 不适合密码存储。更合理的方向是使用带盐、可调成本的密码哈希算法,例如 bcrypt、scrypt、Argon2。
AI 的局限在于,它可能知道“怎么调用 API”,但未必知道“这个 API 在当前安全语境下是否应该调用”。
严重度和攻击面:AI 代码并不会自动降级风险
AI 引入的漏洞不是“小毛病”。从严重度分布看,它和人工代码引入漏洞的风险级别接近,同样可能覆盖高危场景。
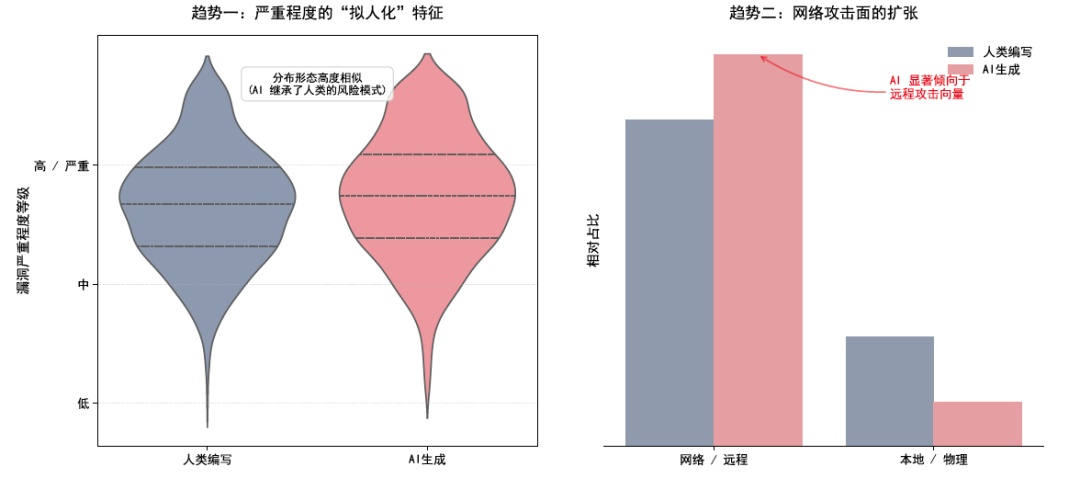
这组结果有两个工程含义。
| 维度 | 观察 | 含义 |
|---|---|---|
| 严重度 | AI 引入漏洞的严重等级分布接近人工代码 | 不能因为代码来自 AI 就降低安全审查标准 |
| 攻击向量 | 更集中在 API、Web 服务、网络协议等网络侧代码 | 远程可触发漏洞需要更严格的输入校验和动态测试 |
| 漏洞形态 | 多为局部实现缺陷 | 静态分析、CWE 规则、代码审查清单可以发挥作用 |
| 修复方式 | AI 可参与修复草案生成 | 最终合入前必须验证修复是否覆盖根因 |
CWE(Common Weakness Enumeration,通用缺陷枚举)规则在这里很有用。AI 生成代码常见问题可以映射到 CWE 分类,例如注入、路径遍历、弱加密、反序列化风险、访问控制错误等。把这些规则接入 CI(Continuous Integration,持续集成)流程,可以在合并前拦截一部分模式化漏洞。
治理 AI 生成代码,需要覆盖完整链路
单靠代码审查很难解决全部问题。AI 生成代码的风险来自模型、提示词、上下文、生成结果、工程流程和运行环境多个环节,因此治理也需要分层。
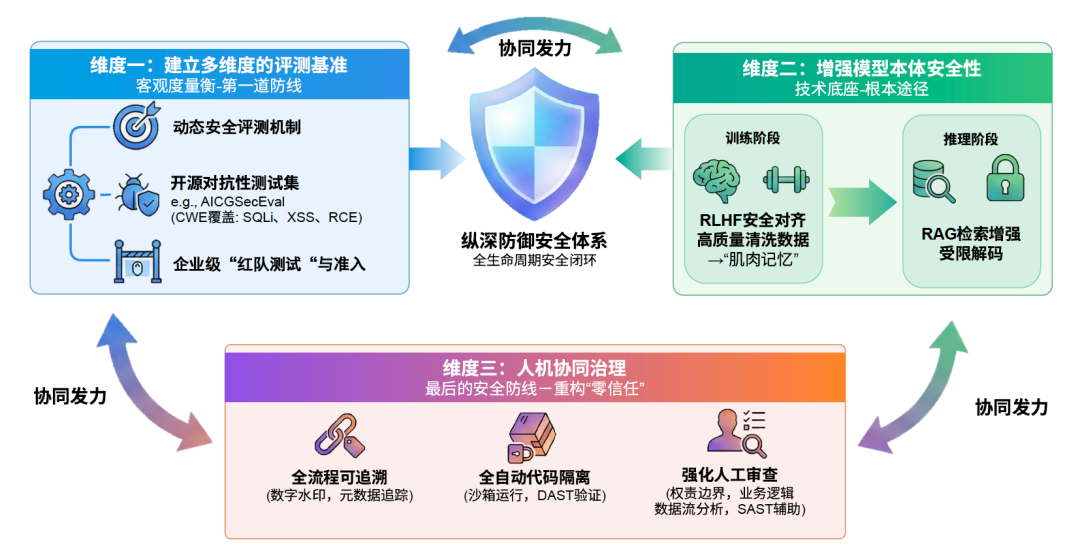
可以把治理拆成三层:模型准入评测、模型本体增强、人机协同流程。
flowchart TD
A[模型引入] --> B[安全评测与红队测试]
B --> C{是否达到准入基线}
C -- 否 --> D[拒绝上线或限制使用场景]
C -- 是 --> E[接入研发流程]
E --> F[生成代码]
F --> G[元数据标记与可追溯]
G --> H[静态分析 / SCA / Secret 扫描]
H --> I[人工安全审查]
I --> J[单元测试 / 动态测试 / 回归测试]
J --> K{是否通过}
K -- 否 --> F
K -- 是 --> L[合入与发布]
建立模型准入评测
大语言模型(Large Language Model,LLM)的输出具有概率性,同一个需求在不同时间、不同上下文下可能生成不同代码。引入模型前,需要用安全评测基准测试它在多语言、多漏洞类型、多工程上下文中的表现。
A.S.E 这类代码生成安全评测集可以作为参考,它基于 CWE 构造安全场景,用更接近真实仓库的任务测试模型是否会生成漏洞代码。企业内部还可以增加自己的业务场景,例如:
- 鉴权中间件生成;
- SQL 查询封装;
- 文件上传处理;
- 第三方回调验签;
- 敏感信息脱敏;
- 多租户权限隔离;
- 加密密钥管理。
模型准入不应该只看“能不能完成功能”,还要看“在安全约束下是否稳定”。
一个简化的准入策略可以这样表达:
ai_code_security_gate:
benchmark:
cwe_coverage:
- injection
- broken_access_control
- insecure_deserialization
- weak_cryptography
- path_traversal
languages:
- python
- javascript
- java
- go
requirements:
critical_vulnerability_rate: 0
high_vulnerability_rate: "below_internal_threshold"
must_pass_security_prompts: true
deployment:
allowed_tasks:
- test_generation
- documentation
- boilerplate_code
- refactoring_suggestion
restricted_tasks:
- authentication
- authorization
- cryptography
- payment_logic
- network_protocol_parser
这不是固定模板,而是一种思路:把模型能力和使用边界写成可执行规则,而不是只靠口头约定。
增强模型本体安全能力
模型本体安全可以从训练和推理两个阶段入手。
训练阶段要解决“模型学到了什么”的问题。高质量安全代码、漏洞修复样本、安全编码规范、反例数据都很重要。数据清洗也不能忽略,如果训练数据里充满过时代码和错误示例,模型就会把这些模式继续生成出来。
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)可以把安全偏好纳入模型对齐过程,让模型在面对危险需求、不完整上下文或不安全 API 时,更倾向于拒绝、提醒或生成更安全的替代方案。
推理阶段要解决“模型当前知道什么”的问题。模型训练完成后,知识会滞后,安全规则、漏洞情报、库函数最佳实践都可能变化。RAG(Retrieval-Augmented Generation,检索增强生成)可以把最新安全规范、内部代码标准、漏洞情报库挂载到生成流程中,让模型在生成代码前检索相关约束。
受限解码也可以发挥作用。通过 AST(Abstract Syntax Tree,抽象语法树)级别的规则约束,可以禁止生成危险 API、强制使用安全封装库,或拦截明显不符合安全策略的代码结构。
建立人机协同审查流程
AI 生成代码必须可追溯。团队至少需要知道哪些代码由 AI 生成、由谁采纳、经过哪些检查、最终由谁承担合入责任。没有可追溯性,出了安全问题就很难定位治理缺口。
审查重点也要调整。AI 生成代码通常语法不错、格式整齐,代码风格问题反而不是重点。更应该关注这些问题:
| 审查项 | 需要确认的问题 |
|---|---|
| 输入边界 | 外部输入是否被校验、规范化、转义或参数化 |
| 权限边界 | 是否遗漏认证、鉴权、租户隔离、对象级访问控制 |
| 数据流 | 敏感数据是否进入日志、响应、异常堆栈或第三方服务 |
| API 使用 | 是否调用过时、不安全或不符合内部规范的接口 |
| 错误处理 | 异常路径是否泄露敏感信息或绕过安全逻辑 |
| 加密与随机数 | 是否使用安全算法、安全随机数和正确密钥管理 |
| 依赖风险 | 是否引入高危依赖、许可证风险或供应链风险 |
| 测试覆盖 | 是否覆盖恶意输入、边界条件和权限失败路径 |
静态分析、软件成分分析(Software Composition Analysis,SCA)、Secret 扫描、动态测试、模糊测试都可以加入这条链路。人工审查不是替代工具,而是处理工具难以判断的业务语义和安全边界。
落地建议:给 AI 代码生成划清安全边界
比较现实的做法不是“一刀切禁用 AI”,而是按风险分级管理。
| 风险等级 | 代码类型 | AI 使用策略 |
|---|---|---|
| 低风险 | 注释、文档、测试样例、格式转换 | 可以使用,合入前做常规审查 |
| 中风险 | CRUD、接口适配、数据转换、样板代码 | 可以使用,必须经过静态分析和人工 review |
| 高风险 | 鉴权、支付、加密、文件上传、网络协议、反序列化 | 只允许生成草案,禁止未经安全审查直接合入 |
| 极高风险 | 安全补丁最终逻辑、核心权限模型、密钥管理 | 人工主导,AI 只能做辅助解释、测试补齐或备选方案生成 |
AI 生成代码应当像外部贡献代码一样被审查,而不是因为它来自内部工具就被默认信任。比较稳妥的工程原则是:
- 生成代码必须可追踪:标记来源、提示词摘要、采纳人和审查记录。
- 高风险目录设置额外门禁:认证、支付、加密、网关、协议解析等目录需要更严格规则。
- 安全扫描前移到提交阶段:不要等发布前才发现注入、弱加密和密钥泄露。
- 为 AI 常见漏洞建立规则库:把输入校验、不安全 API、弱随机数等模式固化成 CI 检查。
- 修复代码必须验证根因:AI 可以生成补丁,但不能替代漏洞分析。
- 持续评估模型版本变化:模型升级后安全行为可能变化,需要重新跑基准测试。
AI 代码生成的价值在于减少重复劳动、提高修复响应速度、补齐测试和文档,但安全边界必须由工程流程来保证。把评测、模型增强、自动化检测和人工审查组合起来,才能让 AI 成为可控的代码协作者,而不是不可追踪的风险来源。
参考资料
[1] Veracode Research: AI-Generated Code Poses Major Security Risks in Nearly Half of All Development Tasks
https://www.businesswire.com/news/home/20250730694951/en/AI-Generated-Code-Poses-Major-Security-Risks-in-Nearly-Half-of-All-Development-Tasks-Veracode-Research-Reveals
[2] A.S.E: A Repository-Level Benchmark for Evaluating Security in AI-Generated Code
https://github.com/Tencent/AICGSecEval
[3] Is Vibe Coding Safe? Benchmarking Vulnerability of Agent-Generated Code in Real-World Tasks