企业做人工智能应用时,模型能力只是起点。真正决定数据分析系统能不能落地的,往往是企业内部数据:指标口径、业务流程、组织权限、历史经营动作、报表体系,以及那些只有业务团队才知道的隐性知识。
数据分析 Agent 要解决的就是这个问题:让使用者不必手写 SQL(结构化查询语言)、不必熟悉复杂报表工具,也能用自然语言完成取数、分析、归因和报告生成。它不是简单的“聊天机器人接数据库”,而是一套围绕数据消费重新设计的智能分析系统。
数据分析 Agent 解决什么问题
传统 BI(Business Intelligence,商业智能)系统的使用门槛不低。一个业务问题从提出到拿到结论,通常要经过多个环节:
flowchart LR
A[业务人员提出问题] --> B[分析师理解口径]
B --> C[查找数据表和指标]
C --> D[编写 SQL 或配置报表]
D --> E[校验数据结果]
E --> F[制作图表]
F --> G[解释变化原因]
G --> H[输出报告或行动建议]
这里面有三个主要成本:
| 成本 | 典型表现 | 数据分析 Agent 的切入点 |
|---|---|---|
| 工具成本 | 不会建模型、不会配报表、不会写 SQL | 用自然语言驱动查询和可视化 |
| 语义成本 | 不知道“销售额”“成交额”“GMV”到底用哪个口径 | 引入指标语义层和业务知识库 |
| 分析成本 | 拿到数据后仍然不知道为什么变化、该做什么 | 让 Agent 拆解问题、调用工具、形成解释 |
大语言模型(Large Language Model,LLM)让自然语言理解能力大幅增强,ChatBI 让“问一句话拿到数据”成为可能;Agent 则进一步引入规划、工具调用、反思和多步骤执行能力,使系统不只回答一个数字,还能完成更长链路的数据分析任务。
可以把数据分析 Agent 理解成四类能力的组合:
flowchart TB
A[自然语言问题] --> B[智能问数 ChatBI]
A --> C[搭建助手 Copilot]
A --> D[洞察分析 Insight]
A --> E[决策智能 Decision Intelligence]
B --> B1[指标查询、明细查询、图表生成]
C --> C1[数据源连接、模型构建、报表搭建]
D --> D1[异常发现、趋势解释、归因分析]
E --> E1[预测、推演、策略建议、主动触达]
其中,ChatBI 是最基础也最关键的部分。因为任何分析结论都必须建立在正确数据之上,如果取数不准,后面的归因、总结和建议都会失去可信度。
常见概念:NL2SQL、ChatBI、DataAgent 和分析 Agent
数据分析 Agent 涉及不少相近概念,容易混在一起。它们之间的关系可以用一张表理清。
| 概念 | 含义 | 关注重点 |
|---|---|---|
| NL2SQL | Natural Language to SQL,把自然语言转换成 SQL | 让数据库能执行查询 |
| NL2DSL | Natural Language to DSL,把自然语言转换成领域特定语言(Domain-Specific Language,DSL) | 复用 BI 语义层、权限和查询引擎 |
| NL2Code / NL2Python | 把自然语言转换成代码,例如 Python 数据处理脚本 | 适合多步骤计算、统计分析、算法处理 |
| NL2Data | 自然语言到数据结果的综合路线,不限定中间形态 | 按场景选择 SQL、DSL、Python 或多工具组合 |
| ChatBI | 对话式 BI 产品形态 | 通过自然语言取数、看图、追问 |
| DataAgent | 泛数据领域智能体 | 范围很大,可能覆盖分析、营销、治理、开发等场景 |
| 分析 Agent | 聚焦数据分析任务的智能体 | 覆盖取数、理解、归因、报告和策略输出 |
| Agent 搭建平台 | 用于编排智能体流程的平台,例如 Dify、LangChain、LangGraph、Coze 等 | 快速搭建流程明确、复杂度适中的智能体 |
一个常见误区是把数据分析 Agent 等同于 NL2SQL。NL2SQL 只是“取数”链路中的一种技术实现,而数据分析 Agent 还需要处理业务语义、权限、查询性能、图表表达、非结构化知识、任务拆解和结果校验。
Agent 的基本运行模式
Agent 的核心不是“模型更会聊天”,而是让模型围绕任务进行规划,并在需要时调用外部工具。典型运行链路包括任务规划、工具选择、工具调用、子任务递归执行和最终结果生成。
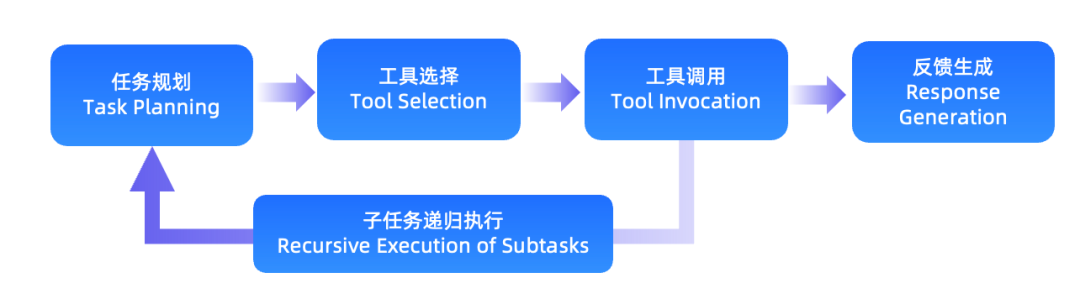
这条链路可以拆成五步:
flowchart TD
A[接收用户问题] --> B[任务规划]
B --> C{是否需要工具}
C -- 不需要 --> H[直接生成回答]
C -- 需要 --> D[选择工具]
D --> E[生成工具参数]
E --> F[调用工具并获得结果]
F --> G{是否完成任务}
G -- 否 --> B
G -- 是 --> I[整合结果]
I --> J[生成最终反馈]
在数据分析场景里,工具可以是数据库查询、指标语义检索、文档检索、图表生成、统计检验、异常检测、归因算法、报告模板生成器等。Agent 的价值在于,它能根据问题类型选择合适工具,而不是把所有问题都交给大模型直接猜。
例如,用户问:
今年华东区销售目标完成情况怎么样?哪个月份拖累最大?
这个问题至少包含三个子任务:
- 识别“华东区”“销售目标”“完成情况”的业务含义;
- 查询实际销售额、销售目标、完成率等指标;
- 按月份比较差异,找出拖累最大的时间段,并生成解释。
如果系统直接让模型生成一段 SQL,很可能会遇到表找错、指标口径错、权限绕过、SQL 方言不兼容等问题。更可靠的做法是让 Agent 先规划,再调用语义层、查询引擎和分析工具。
数据分析 Agent 的内核拆分
数据分析 Agent 可以拆成多个能力明确的子 Agent。这样做不是为了堆概念,而是为了让不同类型任务有不同处理链路。
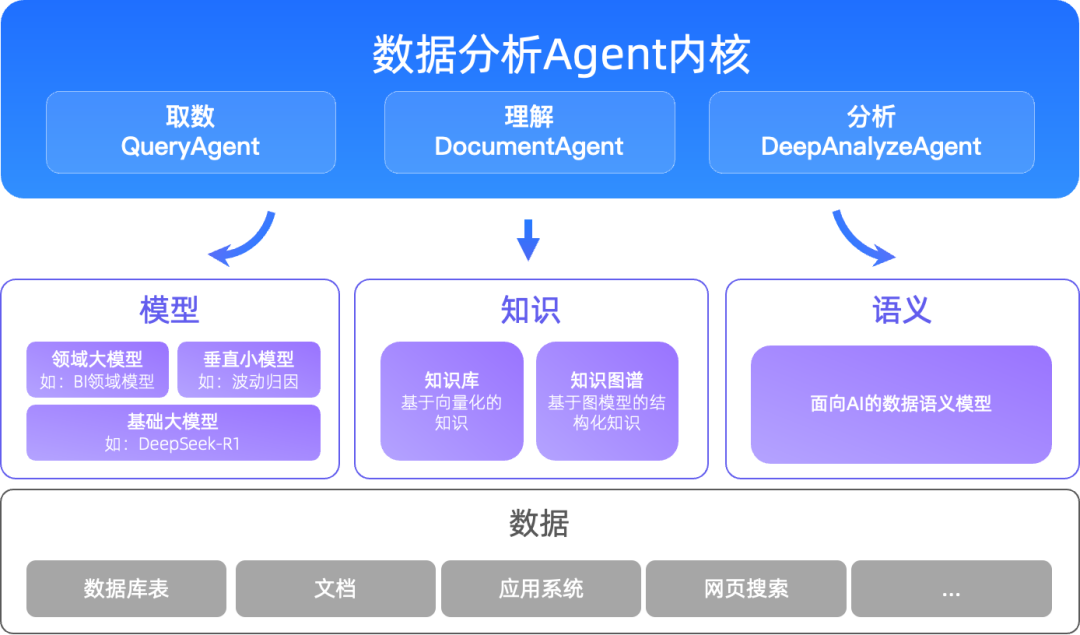
一个比较实用的拆分方式如下:
| 子 Agent | 核心职责 | 输入 | 输出 |
|---|---|---|---|
| QueryAgent | 取数、统计、图表生成 | 自然语言问题、用户上下文、指标语义 | 数据结果、图表、查询解释 |
| DocumentAgent | 理解非结构化资料 | 文档、会议纪要、经营动作、知识库 | 摘要、事实片段、业务背景 |
| DeepAnalyzeAgent | 复杂分析和报告生成 | 数据结果、文档事实、分析目标 | 归因、结论、策略、报告 |
三者之间的关系可以表示成:
flowchart LR
U[用户问题] --> DAA[DeepAnalyzeAgent]
DAA --> QA[QueryAgent]
QA --> S[语义层]
QA --> DB[(数据库 / 数仓)]
QA --> V[可视化组件]
DAA --> DA[DocumentAgent]
DA --> KB[(知识库 / 文档库)]
QA --> DAA
DA --> DAA
DAA --> R[分析结论 / 报告 / 建议]
对于简单取数问题,QueryAgent 就可以完成任务。例如:
本月订单总量和已处理订单量分别是多少?
QueryAgent 需要完成语义解析、指标匹配、查询生成、执行校验和结果展示。
对于复杂经营分析问题,DeepAnalyzeAgent 要作为总控来拆任务。例如:
生成一份本季度经营分析报告,说明销售额变化、主要原因和后续策略。
这类问题不能只查一张表。系统需要先取到销售额、订单量、客单价、转化率等指标,再结合经营动作、活动计划、渠道变化、区域策略等非结构化信息,才能形成有解释力的报告。
QueryAgent:智能问数不是直接生成 SQL
取数是数据分析 Agent 的地基。一个稳定的 QueryAgent 通常包含下面这些环节:
sequenceDiagram
participant U as 用户
participant A as QueryAgent
participant M as 语义层
participant P as 权限系统
participant E as 查询引擎
participant V as 可视化组件
U->>A: 用自然语言提问
A->>M: 识别指标、维度、过滤条件
M-->>A: 返回候选语义对象
A->>A: 澄清歧义或生成查询计划
A->>P: 校验用户权限
P-->>A: 返回可访问范围
A->>E: 提交 DSL / SQL / 查询任务
E-->>A: 返回数据结果
A->>A: 校验结果并生成解释
A->>V: 选择合适图表
V-->>U: 返回数据、图表和说明
这里有几个关键点。
语义层决定能不能理解业务问题
自然语言里的业务词不一定等于数据库字段名。比如“成交额”可能对应 pay_amount,也可能对应“支付成功且未退款订单金额”。没有语义层时,大模型只能根据表名、字段名和注释猜测,很容易出错。
语义层通常要维护这些内容:
metric:
name: 成交额
code: paid_gmv
expression: sum(pay_amount)
filters:
- pay_status = 'paid'
- refund_status != 'full_refunded'
default_time_field: pay_time
owner: 交易分析团队
dimensions:
- name: 大区
code: region_name
- name: 渠道
code: channel_name
- name: 月份
code: month
有了这层抽象,用户问“华东区本月成交额”时,Agent 不需要直接猜物理表,而是先定位指标、维度和过滤条件,再交给查询引擎执行。
权限必须在查询前介入
数据分析 Agent 不能让模型自己决定用户能看什么数据。权限应该由确定性的系统控制,包括:
- 行权限:只能看某个区域、门店、部门的数据;
- 列权限:不能看手机号、身份证号、成本价等敏感字段;
- 指标权限:部分经营指标只对特定角色开放;
- 操作权限:是否允许导出明细、下载报告、订阅推送。
权限校验应该发生在查询生成或执行前,而不是结果返回后再过滤。否则会留下敏感数据泄露风险。
结果需要校验,而不是生成后直接返回
大模型生成查询或分析解释时存在不确定性,QueryAgent 至少要做几类校验:
| 校验项 | 目的 |
|---|---|
| SQL / DSL 可执行性校验 | 避免语法错误、字段不存在、函数不兼容 |
| 指标口径校验 | 确认使用了正确指标定义 |
| 权限校验 | 防止越权访问 |
| 数据范围校验 | 避免默认时间范围或过滤条件错误 |
| 异常值校验 | 识别空结果、极端值、统计口径冲突 |
NL2SQL、NL2DSL 与 NL2Data
智能问数最常见的技术路线包括 NL2SQL、NL2DSL 和 NL2Data。它们的共同目标都是让用户用自然语言拿到数据,区别在于中间表示和工程边界不同。

三种路线可以这样理解:
flowchart TB
Q[自然语言问题]
Q --> A[NL2SQL]
A --> A1[直接生成 SQL]
A1 --> DB[(数据库)]
Q --> B[NL2DSL]
B --> B1[生成 BI DSL]
B1 --> B2[BI 引擎转换 SQL]
B2 --> DB
Q --> C[NL2Data]
C --> C1{按任务选择路径}
C1 --> C2[SQL]
C1 --> C3[DSL]
C1 --> C4[Python / 统计代码]
C1 --> C5[多工具组合]
C2 --> DB
C3 --> DB
C4 --> R[数据处理结果]
C5 --> R
NL2SQL:上手快,但企业级约束多
NL2SQL 的优势是链路短:模型把问题直接转换为 SQL,数据库执行后返回结果。对于表结构简单、权限要求不复杂、查询模式固定的场景,它能较快跑起来。
但在企业级 BI 场景中,NL2SQL 会遇到不少限制:
| 问题 | 具体表现 |
|---|---|
| 语义映射困难 | 业务问题很难直接对应物理表和字段 |
| SQL 方言差异 | MySQL、PostgreSQL、Hive、MaxCompute、ClickHouse 等语法不完全一致 |
| 复杂查询不稳定 | 多表关联、嵌套查询、窗口函数、时间同比环比容易出错 |
| 性能不可控 | 模型生成的 SQL 不一定走最优路径,可能扫描大量数据 |
| 权限能力不足 | 行列级权限、指标权限需要额外接入 |
| 可维护性弱 | 表结构变化后,提示词和样例可能需要频繁调整 |
NL2SQL 适合轻量场景,也适合作为 NL2Data 中的一种工具,但不宜把所有分析任务都压在这条路线之上。
NL2DSL:更适合复用成熟 BI 能力
NL2DSL 不让模型直接面对数据库,而是先生成 BI 系统能够理解的领域语言,再由 BI 引擎转换成 SQL 或其他查询计划。
这条路线的优势在于可以复用成熟 BI 系统已有能力:
- 指标口径管理;
- 维度建模;
- 数据源适配;
- 行列级权限;
- 查询加速;
- 缓存;
- 图表渲染;
- 钻取、联动、筛选等交互能力。
代价也很明确:团队必须拥有稳定的 BI 引擎和 DSL 体系,还要让模型理解 DSL 的语法、约束和生成规则。对于没有 BI 产品基础的团队,建设成本会比较高。
NL2Data:按问题选择最合适的执行路径
NL2Data 更像一种综合架构思想:不要预设所有问题都必须生成 SQL 或 DSL,而是让 Agent 根据问题类型选择工具。
一个简化版调度逻辑可以写成这样:
def route_query(question: str, context: dict):
intent = classify_intent(question, context)
if intent == "simple_metric_query":
return call_tool("nl2dsl_query", question=question)
if intent == "ad_hoc_sql_query":
return call_tool("nl2sql_query", question=question)
if intent == "statistical_analysis":
data = call_tool("nl2dsl_query", question=question)
return call_tool("python_analysis", data=data, task=question)
if intent == "business_report":
plan = make_analysis_plan(question)
datasets = []
docs = []
for subtask in plan.data_tasks:
datasets.append(call_tool("query_agent", question=subtask))
for subtask in plan.document_tasks:
docs.append(call_tool("document_agent", question=subtask))
return call_tool(
"report_generator",
question=question,
datasets=datasets,
documents=docs,
)
return ask_clarification(question)
真实系统会比这复杂得多,但核心思想一致:稳定场景走 DSL,临时探索可走 SQL,需要统计建模时调用 Python,复杂报告由多个子 Agent 协作完成。
Plan-and-Act 与 ReAct:两种常见规划方式
数据分析 Agent 需要规划能力。常见方式有 Plan-and-Act 和 ReAct。
| 模式 | 工作方式 | 适合场景 | 风险 |
|---|---|---|---|
| Plan-and-Act | 先生成完整计划,再按步骤执行 | 报告生成、复杂经营分析、多数据源任务 | 初始计划错误会影响后续步骤 |
| ReAct | 边推理、边调用工具、边根据结果调整 | 探索式分析、数据不确定、需要多轮追问 | 执行路径可能变长,成本更高 |
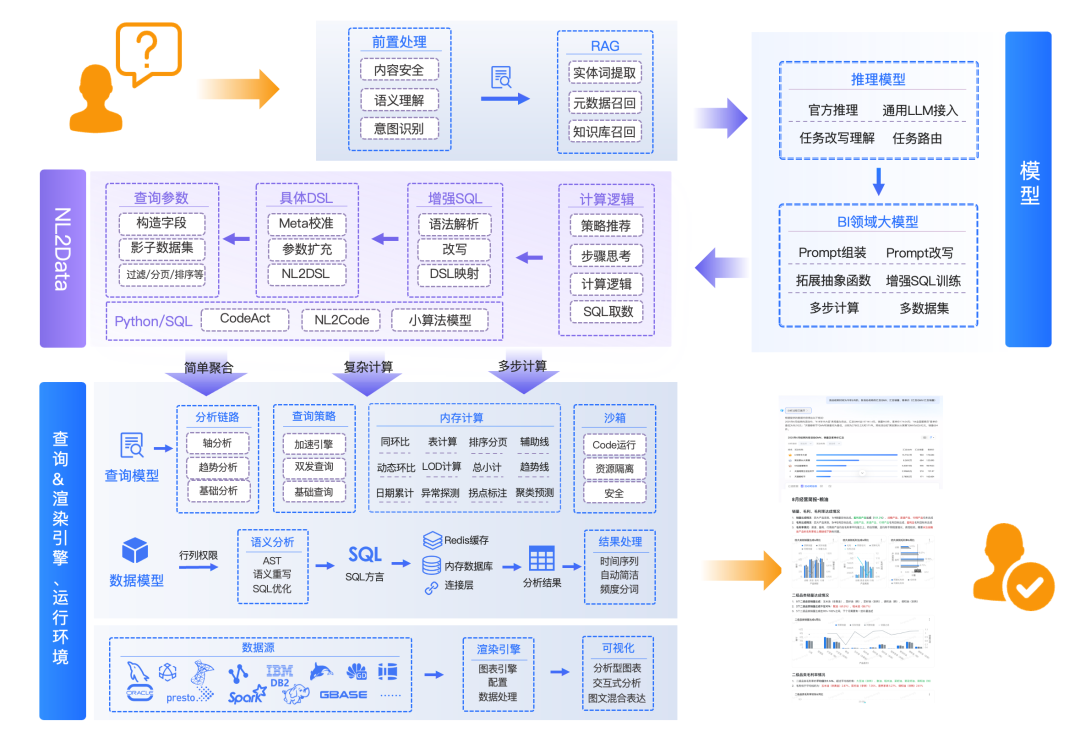
在智能问数中,规划模块通常要处理四类问题:
| 问题类型 | 处理方式 |
|---|---|
| 歧义问题 | 反问澄清,例如“销售额”有多个口径时要求选择 |
| 发散问题 | 拆成多个子任务,例如经营分析报告要拆成指标查询、趋势分析、原因归纳 |
| 收敛问题 | 判断是否在能力范围内,能执行就直接生成查询计划 |
| 超纲问题 | 拒绝或转人工,例如要求访问无权限数据、预测不存在的数据口径 |
一个可维护的 Agent 不应该什么都回答。它必须知道什么时候澄清、什么时候拒绝、什么时候调用工具,以及什么时候承认数据不足。
企业级落地需要补齐哪些工程能力
数据分析 Agent 的难点不止在模型层。一个能被企业长期使用的系统,还需要完整的数据工程和产品工程能力。
flowchart TB
U[用户交互层] --> A[Agent 编排层]
A --> M[模型服务层]
A --> T[工具层]
T --> S[语义层 / 指标中心]
T --> Q[查询引擎]
T --> K[知识库]
T --> V[可视化引擎]
T --> P[权限系统]
Q --> D[(数据仓库 / 数据湖 / 业务库)]
K --> DOC[(文档 / 会议纪要 / SOP)]
A --> O[观测与评测]
O --> LOG[日志、样例、准确率、成本、延迟]
语义治理:让模型说同一种业务语言
没有统一指标口径,Agent 会在不同表、不同字段、不同命名之间摇摆。语义治理要解决:
- 指标名称、别名、口径、负责人;
- 指标和维度之间的可组合关系;
- 默认时间字段和统计周期;
- 业务术语与数据库字段的映射;
- 指标变更后的版本管理。
查询加速:让自然语言分析不会变成慢查询制造机
大模型可能生成低效查询,复杂分析任务也可能触发多次查询。系统需要在查询层做控制:
- SQL 复杂度限制;
- 大表扫描防护;
- 查询缓存;
- 预聚合;
- 热点指标加速;
- 超时中断;
- 异步任务和进度反馈。
安全权限:把确定性规则放在模型之外
模型不能替代权限系统。权限控制要由确定性服务完成,并且全链路生效:
flowchart LR
U[用户身份] --> P[权限系统]
P --> A[Agent]
A --> S[语义层权限过滤]
S --> Q[查询权限过滤]
Q --> R[结果脱敏]
R --> U
敏感字段脱敏、明细导出审批、跨部门数据隔离、审计日志,这些都属于企业级数据分析 Agent 的基础能力。
可观测与评测:持续发现错误样例
数据分析 Agent 需要专门的评测体系。只看用户是否点赞不够,还要记录模型是否选对指标、是否生成正确查询、是否遵守权限、是否解释可信。
常见评测指标包括:
| 维度 | 指标示例 |
|---|---|
| 取数准确性 | 指标匹配准确率、SQL / DSL 执行成功率、结果一致率 |
| 语义理解 | 意图识别准确率、歧义澄清命中率 |
| 分析质量 | 归因覆盖度、异常解释准确率、报告事实一致性 |
| 工程表现 | 平均响应时间、查询失败率、模型调用成本 |
| 安全合规 | 越权拦截率、敏感字段暴露次数、审计完整性 |
评测集要来自真实业务问题,并且要覆盖简单取数、复杂筛选、多轮追问、权限边界、异常数据、报告生成等场景。
数据分析 Agent 的典型使用场景
不同场景对 Agent 的能力要求差异很大。
| 场景 | 示例问题 | 主要能力 |
|---|---|---|
| 即席问数 | “昨天各渠道订单量是多少?” | QueryAgent、语义层、可视化 |
| 指标追问 | “为什么华南区转化率下降?” | 指标拆解、异常检测、归因 |
| 经营报告 | “生成本月销售经营分析报告” | 多步骤规划、取数、文档理解、报告生成 |
| 管理驾驶舱 | “每天早上推送异常指标和原因” | 主动监控、订阅推送、异常解释 |
| 沙盘推演 | “如果客单价提升 5%,销售额会怎样?” | 假设建模、预测、策略模拟 |
| 知识问答结合数据 | “上次促销活动后复购率有什么变化?” | 文档检索、数据查询、事实融合 |
其中,即席问数最容易产品化;经营报告和沙盘推演更依赖业务知识、数据质量和分析模型;主动推送则要求系统能识别目标人群、理解业务节奏,并与办公系统、消息系统、业务流程系统打通。
常见坑:数据分析 Agent 为什么容易“不准”
数据分析 Agent 的“不准”通常不是单一原因造成的,而是多层误差叠加。
flowchart TD
A[用户问题] --> B[意图理解偏差]
B --> C[指标口径匹配错误]
C --> D[维度或过滤条件错误]
D --> E[查询生成错误]
E --> F[权限或数据范围错误]
F --> G[结果解释错误]
G --> H[最终结论不可信]
工程上要重点防这些问题:
| 坑 | 解决思路 |
|---|---|
| 把业务词直接映射到字段 | 建设语义层和指标中心 |
| 让模型自由生成任意 SQL | 使用受控 DSL、模板化查询或 SQL 校验器 |
| 忽略时间范围 | 为指标设置默认时间字段,并在问题不明确时澄清 |
| 没有权限前置校验 | 查询前注入权限约束,结果层再做脱敏 |
| 把空结果解释成业务结论 | 对空值、异常值、低样本量做显式提示 |
| 报告生成时编造原因 | 要求每个结论绑定数据证据或文档证据 |
| 只做演示样例,不做评测集 | 持续沉淀真实问题、标准答案和失败样例 |
一个实用原则是:凡是影响数据正确性的环节,尽量用确定性系统约束;凡是需要语言理解、任务拆解和表达生成的环节,再交给大模型发挥作用。
未来演进:准度、深度和广度
数据分析 Agent 的演进方向可以概括为三个关键词:数据准度、分析深度、消费广度。
数据准度:所有智能能力的前提
准度来自组合能力,而不是单靠更大的模型。可落地的做法包括:
- 建设高质量基础数据集;
- 完善指标语义层和业务知识库;
- 针对企业数据和 DSL 进行专项训练或微调;
- 对查询结果做规则校验和样例评测;
- 引入人工反馈闭环,持续修正高频错误。
分析深度:把结构化数据转成业务知识
数据表只告诉系统“发生了什么”,业务知识才能解释“为什么发生”。更深的分析需要把结构化数据和非结构化资料结合起来:
- 用预计算和指标拆解降低模型理解大规模数据的压力;
- 用统计模型、小模型或规则引擎处理趋势、异常、归因;
- 从会议纪要、活动方案、销售策略、客服记录中抽取事实;
- 将经营动作与指标变化建立关联;
- 为不同行业沉淀可复用的分析模板和指标树。
消费广度:从“人找数”走向“数找人”
更成熟的数据分析 Agent 不只是被动回答问题,还会主动发现异常并触达合适的人。例如:
flowchart LR
A[指标监控] --> B{发现异常}
B -- 是 --> C[定位影响范围]
C --> D[匹配负责人]
D --> E[生成解释和建议]
E --> F[推送到办公系统]
F --> G[跟踪处理结果]
B -- 否 --> A
这要求数据系统与组织架构、业务流程、办公应用、权限体系连接起来。只有知道“哪个指标异常、影响谁、谁负责、该怎么处理”,数据分析 Agent 才能从问答工具进化为业务行动助手。