给一个函数生成注释并不难,把函数体丢给大语言模型(Large Language Model,LLM),让它解释参数、返回值和主要逻辑就能得到不错的结果。难的是仓库级代码文档:一个真实项目通常有成百上千个文件,模块之间互相调用,配置、启动流程、数据结构、接口边界也分散在不同位置。
CodeWiki 要解决的就是这个问题:让人工智能(Artificial Intelligence,AI)自动阅读一个大规模代码仓库,并生成类似 Wiki 的项目文档。这里的重点不是“把代码逐文件翻译成自然语言”,而是让文档能回答更高层的问题:
- 这个项目整体是做什么的?
- 核心模块有哪些,各自负责什么?
- 请求、任务或数据在系统里怎么流转?
- 某个模块依赖哪些模块,又被哪些模块调用?
- 新人要改一个功能时,应该先看哪些文件?
直接把整个仓库塞进模型上下文不可行。一方面上下文窗口有限,另一方面代码里有大量噪声:测试数据、样板代码、重复工具函数、框架生成文件都会干扰模型判断。CodeWiki 这类系统通常采用的路线是层次化模块拆解(Hierarchical Module Decomposition,HMD)。
仓库级文档生成为什么不能只靠“长上下文”
假设一个项目结构大致如下:
shop-service/
├── api/
│ ├── order_controller.py
│ └── user_controller.py
├── domain/
│ ├── order.py
│ ├── payment.py
│ └── inventory.py
├── repository/
│ ├── order_repository.py
│ └── user_repository.py
├── jobs/
│ └── order_timeout_job.py
└── config/
└── settings.py
如果让 LLM 一次性阅读所有文件,它会遇到几个典型问题。
| 问题 | 表现 | 影响 |
|---|---|---|
| 上下文过长 | 仓库内容超过模型可处理范围 | 只能截断代码,重要依赖可能丢失 |
| 信息密度低 | 很多文件只是配置、样板、重复封装 | 模型容易把细节当重点 |
| 跨文件关系复杂 | 控制器、领域模型、数据库访问分布在不同目录 | 生成的文档容易只解释局部逻辑 |
| 层级混乱 | 函数、类、模块、子系统被放在同一层描述 | 文档读起来像文件清单,不像系统说明 |
| 更新成本高 | 改一个小文件就重新生成全仓库文档 | 成本高,也容易引入不一致 |
仓库级文档的核心不是“代码越多,喂给模型越多”,而是先把代码组织成适合理解的结构。HMD 就是在做这个组织工作。
核心机制:层次化模块拆解
层次化模块拆解的做法很直接:把系统按模块关系拆成树或图,先理解最底层单元,再把底层说明逐层合并成上层说明。
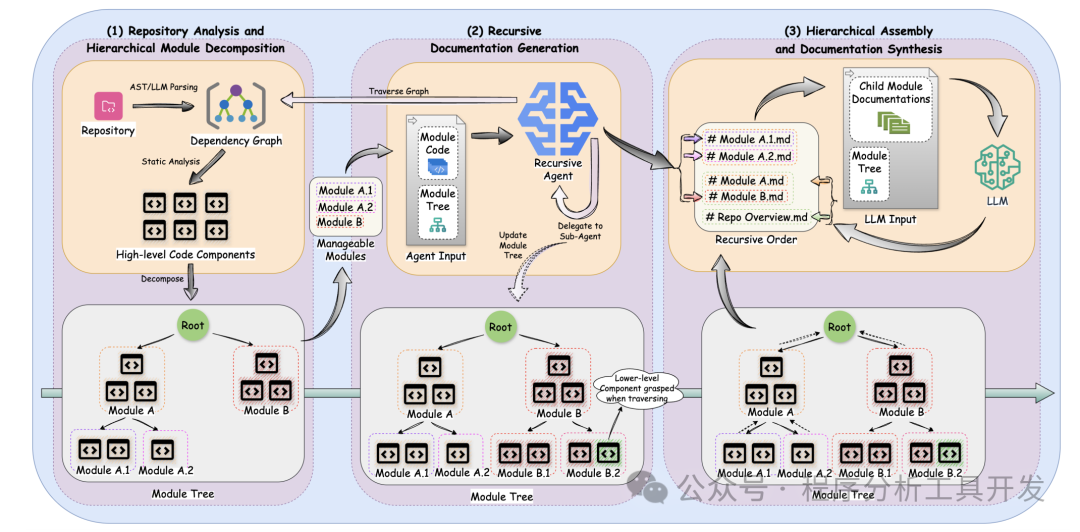
图里的关键思想可以概括成两句话:代码仓库不是一个扁平文件列表,而是由多层模块组成的系统;文档生成也不应该从“整仓库”开始,而应该从低层模块开始,逐层向上汇总。
一个常见层级是:
仓库 Repository
└── 子系统 Subsystem
└── 模块 Module
└── 文件 File
└── 类 / 函数 Class / Function
文档生成顺序与这个层级相反:
flowchart BT
F[函数 / 类说明] --> File[文件说明]
File --> M[模块说明]
M --> S[子系统说明]
S --> R[仓库总览]
D1[调用关系] --> M
D2[依赖关系] --> S
D3[配置与入口] --> R
底层文档负责准确描述局部代码,上层文档负责解释模块职责和模块关系。这样做有一个好处:模型在生成上层文档时,不需要重新读取所有源码,只需要读取下层已经压缩过、结构化过的说明,再结合依赖关系和目录结构进行汇总。
CodeWiki 的典型工作流
CodeWiki 类系统的流程可以拆成七个阶段。
flowchart LR
A[代码仓库] --> B[扫描文件与目录]
B --> C[提取语法结构和依赖关系]
C --> D[构建模块层级]
D --> E[生成底层代码说明]
E --> F[逐层汇总模块文档]
F --> G[生成 Wiki 页面]
G --> H[索引、导航和交叉引用]
1. 扫描仓库
扫描阶段要过滤掉无关文件,比如:
.git/
node_modules/
dist/
build/
target/
coverage/
*.lock
*.min.js
这些文件通常不承载业务逻辑,直接交给模型只会增加噪声。对仓库级文档来说,更有价值的是源代码、配置文件、接口定义、构建脚本和部署入口。
2. 提取结构信息
光看目录不够。很多项目的真实结构藏在代码关系里,例如:
import/require/include依赖关系;- 类继承和接口实现关系;
- 函数调用关系;
- 路由注册和控制器映射;
- 数据库模型和数据访问层关系;
- 配置项被哪些模块读取。
这些信息可以通过抽象语法树(Abstract Syntax Tree,AST)、语言服务器、静态分析工具或简单的正则规则提取。提取结果会变成后续拆解模块的依据。
3. 构建模块层级
模块边界可以来自目录结构,也可以来自依赖关系。目录结构适合大多数工程项目,因为开发者通常已经按业务或技术职责组织了代码;依赖关系适合处理目录组织混乱的大仓库。
常见拆解依据如下:
| 拆解依据 | 适合场景 | 风险 |
|---|---|---|
| 目录结构 | Web 服务、SDK、组件库 | 目录命名不规范时会误判 |
| 包 / 命名空间 | Java、Go、Python 等语言项目 | 包名可能只反映技术层,不反映业务层 |
| 依赖图 | 大型单体、历史项目 | 图过密时需要聚类算法 |
| 入口文件 | CLI、服务启动器、插件系统 | 只能覆盖运行路径附近的代码 |
| 业务关键词 | 领域模型清晰的项目 | 需要额外规则,容易受命名影响 |
4. 生成底层说明
底层说明通常围绕文件、类和函数展开,但输出不能太散。一个文件说明至少要包含这些信息:
文件路径:domain/order.py
职责:
- 定义订单领域模型
- 维护订单状态流转
- 提供订单金额计算逻辑
关键对象:
- Order
- OrderStatus
- OrderItem
对外依赖:
- payment.py
- inventory.py
被调用位置:
- api/order_controller.py
- jobs/order_timeout_job.py
这类结构化说明比普通自然语言段落更适合继续向上汇总,因为字段稳定,模型不容易漏掉关键信息。
5. 逐层汇总模块文档
当一个模块下的文件说明都生成后,模型可以基于这些说明生成模块级文档。模块级文档不应该重复所有文件细节,而应该回答模块职责、边界和协作关系。
例如 domain/ 模块的文档可以写成:
domain 模块承载核心业务规则,主要包括订单、支付和库存三个领域对象。
api 层通过 domain 模块完成业务校验和状态变更,repository 层只负责数据持久化。
order.py 是该模块的中心文件,它会调用 payment.py 和 inventory.py 完成订单支付前的校验。
这里已经从“文件解释”上升到了“模块设计解释”。
6. 生成 Wiki 页面
Wiki 页面一般不是一份长文档,而是一组页面。比较实用的页面类型有:
| 页面 | 内容 |
|---|---|
| 项目总览 | 项目用途、技术栈、启动入口、核心流程 |
| 架构说明 | 子系统划分、模块依赖、关键设计 |
| 模块文档 | 每个模块的职责、入口、主要类和函数 |
| 调用链说明 | 请求、任务、消息或数据的流转路径 |
| API(Application Programming Interface,应用程序编程接口)说明 | 路由、参数、返回值、错误码 |
| 配置说明 | 配置项含义、默认值、影响范围 |
| 开发指南 | 本地启动、测试、常见修改位置 |
CodeWiki 的价值就在于把这些页面组织起来,让读者能从总览跳到模块,再从模块跳到具体文件。
7. 建立交叉引用
自动生成的文档如果没有引用源代码位置,很快会变成“看起来正确但无法验证”的说明。更好的做法是让每个结论都尽量带上代码路径:
订单超时取消逻辑由 jobs/order_timeout_job.py 触发,
最终调用 domain/order.py 中的 cancel_order 方法完成状态变更。
这种路径引用能帮助读者快速回到源码,也能降低模型幻觉带来的风险。
为什么 HMD 适合大规模代码文档
HMD 的优势不在于让模型“更聪明”,而是让模型每次处理的信息更合适。
1. 把大问题拆成小问题
仓库级文档生成的问题太大,模型容易失焦。拆成模块后,每次只处理一个文件或一个模块,任务边界清楚很多。
flowchart TD
A[生成整个仓库文档] -->|过大| B[上下文拥挤]
A -->|过大| C[细节混乱]
A -->|过大| D[依赖关系丢失]
E[按模块分层生成] --> F[局部说明更准确]
F --> G[模块说明更清晰]
G --> H[仓库总览更稳定]
2. 用底层摘要压缩上下文
底层代码说明相当于一种语义压缩。它去掉了实现细节中的噪声,只保留职责、接口、依赖和关键逻辑。上层生成时读取这些摘要,比读取原始源码更稳定。
3. 文档结构天然接近项目结构
一个真实项目本来就是分层设计的。控制器、服务、领域模型、存储层、配置层各有职责。HMD 生成的文档顺着这个结构展开,读者更容易定位信息。
4. 支持增量更新
如果某次提交只改了 domain/payment.py,理论上只需要重新生成这个文件的说明,再更新它所在模块以及更上层的文档,而不必重跑整个仓库。
一个简化的增量更新策略可以这样设计:
flowchart LR
A[文件变更] --> B[计算文件哈希]
B --> C{哈希是否变化}
C -- 否 --> D[复用旧文档]
C -- 是 --> E[重新生成文件说明]
E --> F[更新父模块文档]
F --> G[更新仓库总览]
一个简化版实现思路
如果要自己实现一个轻量版 CodeWiki,可以从最小流程开始:扫描仓库、构建模块树、生成文件说明、汇总模块说明、渲染 Markdown。
from pathlib import Path
import hashlib
IGNORE_DIRS = {".git", "node_modules", "dist", "build", "target", "__pycache__"}
def should_ignore(path: Path) -> bool:
return any(part in IGNORE_DIRS for part in path.parts)
def file_hash(path: Path) -> str:
return hashlib.sha256(path.read_bytes()).hexdigest()
def scan_source_files(repo: str):
root = Path(repo)
for path in root.rglob("*"):
if should_ignore(path):
continue
if path.suffix in {".py", ".js", ".ts", ".java", ".go", ".rs"}:
yield path
def group_by_module(files):
modules = {}
for file in files:
module = file.parent
modules.setdefault(module, []).append(file)
return modules
def summarize_file(path: Path, code: str) -> str:
"""
实际系统会在这里调用 LLM。
输入应包含文件路径、代码片段、依赖关系和必要的项目上下文。
"""
return f"文件 {path} 的结构化说明"
def summarize_module(module_path: Path, file_summaries: list[str]) -> str:
"""
实际系统会把多个文件说明合并成模块文档。
"""
return f"模块 {module_path} 的职责、关键对象和依赖关系"
def build_docs(repo: str):
files = list(scan_source_files(repo))
modules = group_by_module(files)
module_docs = {}
for module, module_files in modules.items():
file_docs = []
for file in module_files:
code = file.read_text(encoding="utf-8", errors="ignore")
file_docs.append(summarize_file(file, code))
module_docs[module] = summarize_module(module, file_docs)
return module_docs
这个示例没有做 AST 分析、依赖图、缓存和质量校验,但已经体现了 HMD 的基本路线:不要一次性处理整个仓库,而是先生成局部说明,再汇总成模块说明。
Prompt 设计要点
CodeWiki 的生成质量很大程度取决于提示词设计。提示词不能只写“解释这段代码”,而要规定输出结构和关注点。
文件级说明提示词
你是代码文档生成器。请根据给定源码生成文件级说明。
输入:
- 文件路径
- 源码内容
- import 依赖
- 被哪些文件调用
输出必须包含:
1. 文件职责
2. 关键类 / 函数
3. 对外暴露的接口
4. 依赖关系
5. 可能影响上层模块理解的重要细节
要求:
- 不要逐行解释代码
- 不要编造源码中不存在的能力
- 关键结论要引用文件路径或函数名
模块级说明提示词
你是系统设计文档生成器。请根据多个文件级说明生成模块文档。
输入:
- 模块路径
- 模块内文件说明列表
- 模块与其他模块的依赖关系
输出必须包含:
1. 模块职责
2. 模块边界
3. 核心流程
4. 对外依赖
5. 被其他模块使用的方式
6. 阅读源码时建议关注的入口文件
要求:
- 合并重复信息
- 保留关键文件路径
- 用模块视角解释设计,不要堆文件清单
好的 Prompt 会强制模型按固定字段输出,后续汇总时更容易保持一致。
适合和不适合的场景
CodeWiki 适合“代码量大、模块关系复杂、文档缺失或过期”的项目,但它不是所有场景的最佳选择。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 大型后端服务 | 适合 | 模块边界、调用链、配置入口通常比较明确 |
| SDK / 框架库 | 适合 | API 文档和模块说明价值高 |
| 微服务仓库集合 | 适合,但需要额外服务依赖图 | 单仓库视角不够,需要服务间关系 |
| 小型脚本项目 | 不太需要 | 手写 README 成本更低 |
| 高度动态语言项目 | 可以用,但要加强运行时信息 | 静态分析可能漏掉动态调用 |
| 自动生成代码占比很高的项目 | 需要过滤 | 生成代码会稀释核心逻辑 |
| 安全敏感闭源项目 | 谨慎使用 | 需要确认代码不会被发送到不可信环境 |
常见坑
模块边界切错
如果模块拆解不合理,上层文档会跟着错。比如把 payment 和 order 都归到一个“大业务模块”里,模型可能会看不清支付流程和订单流程的边界。
更稳妥的做法是结合目录、依赖关系和入口调用链,而不是只看文件夹名称。
摘要层层传递后丢失细节
HMD 会带来压缩,压缩过度就会丢掉重要信息。文件级说明里要保留关键函数名、配置项、外部接口和异常分支,否则模块级文档会变得空泛。
文档没有源码引用
自动生成的文档必须能回到代码。缺少路径引用时,读者很难判断一句说明来自哪里,也无法快速定位实现。
更新机制不完善
仓库每天都在变化,如果文档生成只跑一次,很快就会过期。比较实用的方式是结合 Git 变更,只更新受影响的文件和模块。
忽略测试和配置
测试代码能暴露真实使用方式,配置文件能说明运行模式。只看业务源码会漏掉很多系统行为,尤其是启动流程、插件注册、任务调度和环境变量。
工程落地建议
要让 CodeWiki 类系统真正可用,可以把生成过程设计成一条可重复执行的流水线。
flowchart TD
A[Git 提交] --> B[识别变更文件]
B --> C[重新分析受影响模块]
C --> D[调用 LLM 生成结构化说明]
D --> E[校验路径和符号是否存在]
E --> F[渲染 Markdown Wiki]
F --> G[提交到文档站点或代码仓库]
几个细节很关键:
- 按语法单元切分代码,不要按固定行数硬切;
- 为每个文件和模块生成稳定 ID,方便增量更新;
- 缓存文件级说明,文件内容没变就不要重复调用模型;
- 文档里保留源码路径、类名、函数名和配置项;
- 对生成结果做基本校验,比如检查引用路径是否存在;
- 把测试、配置、启动脚本纳入上下文,但过滤构建产物和依赖目录;
- 对安全敏感仓库使用本地模型或私有化部署。
CodeWiki 的关键不只是“让 LLM 写文档”,而是把代码仓库整理成模型容易理解、读者也容易阅读的层次结构。HMD 让文档生成从底层代码事实出发,逐层构建模块说明和系统说明,这也是仓库级代码文档自动生成能扩展到大规模项目的主要原因。