AI Agent 的能力很大程度上取决于它能调用多少外部工具。它可以读 Google Drive 文档、查 Salesforce 记录、发 Slack 消息、访问数据库、调用内部系统接口,也可以把这些工具串起来完成一个完整任务。
问题在于,工具越多,Agent 越容易被上下文窗口拖住。
大语言模型(LLM)在工作时并不是直接“记住”所有外部世界的信息,而是依赖上下文窗口。工具定义、调用参数、工具返回值、中间数据,都要以 Token 的形式放进上下文。工具数量一多,或者工具返回的数据很大,Token 成本和延迟会迅速上升,甚至直接超过模型的上下文限制。
围绕 MCP(Model Context Protocol,模型上下文协议)构建 Agent 时,这个问题会更加明显。MCP 统一了模型和外部工具之间的连接方式,但如果仍然让模型直接管理每一次工具调用,Agent 会遇到两类很重的成本:
| 成本来源 | 发生位置 | 典型后果 |
|---|---|---|
| 工具定义过载 | 任务开始前,把大量工具说明塞进上下文 | 模型还没开始解决问题,Token 已经被工具列表消耗掉 |
| 中间结果消耗 | 每次工具返回值都进入模型上下文 | 大文档、大表格、长日志会被反复传入传出,成本和延迟都很高 |
一种更工程化的做法是:不要让模型直接调用每个工具,而是让模型写代码,由代码去调用工具。
也就是说,MCP 工具不再直接暴露成一大串模型可选的 function calling 接口,而是被封装成代码 API。模型负责编写一段脚本,脚本在受控执行环境里完成工具调用、数据过滤、结果传递和状态保存。
Anthropic 给出的数据很直观:在某些任务中,这种方式可以把 Token 消耗从约 15 万降到约 2000,减少 98.7%。
传统 MCP Agent 的两个 Token 成本
工具定义过载:模型还没工作,窗口已经被占掉
传统工具调用模式通常会在任务开始前,把可用工具的定义提供给模型。一个简单工具定义大概包含名称、描述、参数、返回结构等信息。例如:
gdrive.getDocument
Description: Retrieves a document from Google Drive
Parameters:
documentId (required, string): The ID of the document to retrieve
fields (optional, string): Specific fields to return
Returns: Document object with title, body content, metadata
salesforce.updateRecord
Description: Updates a record in Salesforce
Parameters:
objectType (required, string): Type of Salesforce object
recordId (required, string): The ID of the record to update
data (required, object): Fields to update with their new values
如果 Agent 只接入十几个工具,这种方式还能接受;如果它连接了 Google Drive、Salesforce、Slack、Jira、GitHub、数据库、内部工单系统、监控系统,每个系统又有几十到几百个操作,工具定义本身就会变成一个巨大的上下文负担。
更麻烦的是,模型在具体任务中通常只需要少数几个工具。为了找到这几个工具,却要先读完大量无关工具说明,这是一种很低效的信息组织方式。
可以把它理解为:程序员只是想调用两个函数,却被迫先阅读整个公司所有服务的接口文档。
中间结果消耗:数据被模型反复搬运
第二类成本更隐蔽,也更容易把上下文打满。
假设任务是:
从 Google Drive 读取一份会议纪要,然后把纪要内容写入 Salesforce 的潜在客户记录。
传统工具调用流程大概是:
sequenceDiagram
participant User as 用户
participant Model as 模型上下文
participant GDrive as Google Drive MCP 工具
participant SF as Salesforce MCP 工具
User->>Model: 请求同步会议纪要
Model->>GDrive: gdrive.getDocument(documentId)
GDrive-->>Model: 返回完整会议纪要
Model->>SF: salesforce.updateRecord(data 包含完整纪要)
SF-->>Model: 返回更新结果
Model-->>User: 任务完成
关键问题在于:完整会议纪要先从 Google Drive 返回到模型上下文,然后模型又把同一份内容放进 Salesforce 的更新参数里。也就是说,这份数据至少被模型处理了两次。
如果会议纪要只有几百字,影响不大;如果是两小时会议转写,可能有几万 Token。再加上工具定义、系统提示词、历史对话、其他中间结果,任务很容易逼近上下文窗口上限。
传统 MCP 客户端工作流可以概括为:工具结果会先回到模型,模型再决定下一次工具调用。
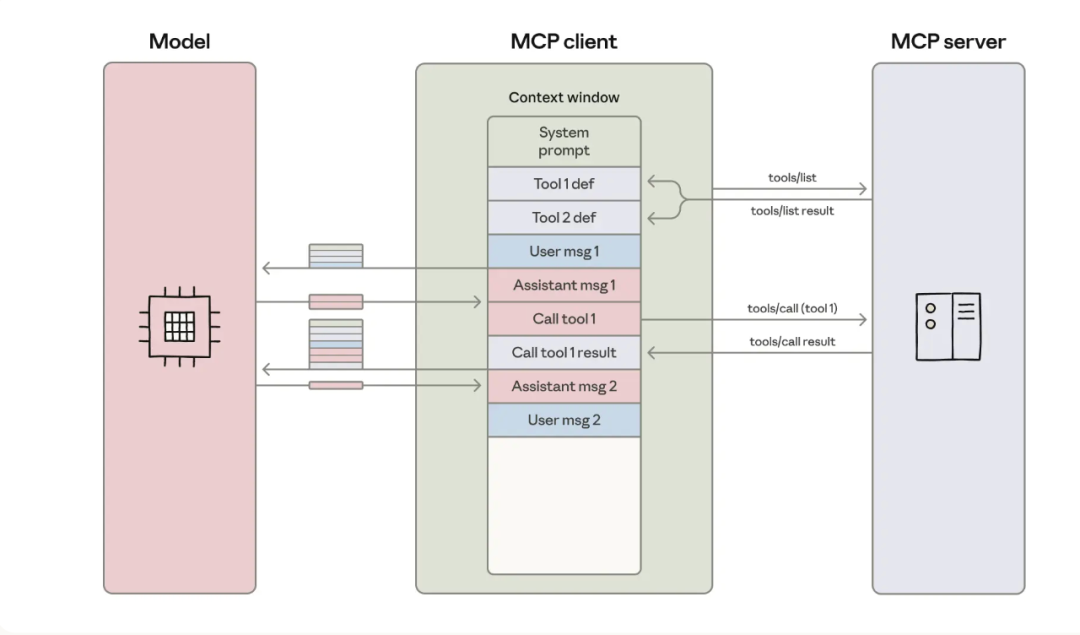
这张流程图的核心点是“模型位于所有工具调用之间”。每个工具的输入输出都要经过模型上下文,模型既负责规划,也负责搬运数据。对于小数据任务,这种设计简单直接;对于大数据任务,模型上下文会变成数据通道,Token 成本随数据量线性增长。
代码执行范式:让 Agent 写代码调用工具
代码执行范式的核心变化是:
MCP 工具仍然存在,但模型不再直接逐个调用工具,而是编写代码,由代码执行环境完成工具调用。
工具可以被组织成一个文件树。每个 MCP 工具被封装成一个模块或函数,模型可以像程序员一样按需查找、读取和调用。
例如,用 TypeScript 暴露工具时,目录可以长这样:
servers/
├── google-drive/
│ ├── getDocument.ts
│ ├── getSheet.ts
│ └── searchFiles.ts
├── salesforce/
│ ├── updateRecord.ts
│ ├── query.ts
│ └── createRecord.ts
├── slack/
│ ├── getChannelHistory.ts
│ └── sendMessage.ts
└── jira/
├── createIssue.ts
└── updateIssue.ts
模型不需要在任务开始前读取所有工具定义。它可以先查看有哪些服务:
ls ./servers
如果任务只涉及 Google Drive 和 Salesforce,它再读取对应目录下的少数文件:
ls ./servers/google-drive
ls ./servers/salesforce
然后只查看当前任务真正需要的接口说明:
cat ./servers/google-drive/getDocument.ts
cat ./servers/salesforce/updateRecord.ts
这种方式把工具发现从“一次性塞满上下文”改成了“按需读取”。上下文里只出现和当前任务有关的工具信息。
会议纪要同步任务如何改写
同样是“读取 Google Drive 会议纪要并写入 Salesforce”,传统方式需要模型先接收完整纪要,再把纪要放入下一次工具调用。
代码执行方式会生成一段脚本:
import * as gdrive from './servers/google-drive';
import * as salesforce from './servers/salesforce';
const transcript = (
await gdrive.getDocument({
documentId: 'abc123',
})
).content;
await salesforce.updateRecord({
objectType: 'SalesMeeting',
recordId: '00Q5f000001abcXYZ',
data: {
Notes: transcript,
},
});
这段代码里,transcript 是代码执行环境中的变量。会议纪要从 Google Drive 读取后,直接作为变量传给 Salesforce 更新函数,中间不需要完整进入模型上下文。
模型真正需要看到的,可能只是代码执行结果:
SalesMeeting 00Q5f000001abcXYZ updated successfully.
两种模式的差异可以用一张表概括:
| 对比项 | 直接工具调用 | 代码执行 |
|---|---|---|
| 工具发现 | 所有工具定义预先进入上下文 | 通过文件系统或搜索接口按需发现 |
| 工具组合 | 模型多轮选择工具、填写参数 | 模型写一段代码完成完整流程 |
| 中间数据 | 每次工具返回值进入模型上下文 | 大部分数据保留在执行环境变量里 |
| 大文件处理 | 容易撑爆上下文 | 可在本地过滤、切片、汇总 |
| 控制流 | 依赖多轮模型调用 | 使用普通代码的循环、条件、异常处理 |
| 状态保存 | 主要依赖对话上下文 | 可写入文件、数据库或工作目录 |
为什么代码执行能显著减少 Token
Token 降低不是因为模型“变聪明了”,而是因为数据流变了。
传统模式下,模型既是决策者,也是数据搬运通道:
flowchart LR
A[工具 A] --> B[模型上下文]
B --> C[工具 B]
C --> B
B --> D[工具 C]
代码执行模式下,模型主要负责生成程序,程序在执行环境里搬运数据:
flowchart LR
M[模型] -->|生成代码| R[代码执行环境]
R --> A[工具 A]
R --> B[工具 B]
R --> C[工具 C]
A --> R
B --> R
C --> R
R -->|摘要或最终结果| M
差别在于:大体量数据不再被迫穿过模型上下文。
以会议纪要任务为例:
| 数据 | 直接工具调用 | 代码执行 |
|---|---|---|
| 工具定义 | 大量工具说明进入上下文 | 只读取相关工具文件 |
| 会议纪要全文 | 返回给模型一次,再由模型传给 Salesforce 一次 | 留在执行环境变量中 |
| 最终反馈 | 工具返回值进入上下文 | 只返回成功状态或少量摘要 |
如果会议纪要有 5 万 Token,传统模式可能要让模型处理两遍甚至更多;代码执行模式只需要模型理解“读取文档并写入字段”这个操作结构,而不必阅读完整纪要内容。
渐进式披露:工具不用一次性暴露给模型
“渐进式披露”指的是:模型只在需要时获取必要信息。
在直接工具调用模式中,系统往往要提前告诉模型所有可用工具。工具越多,前置上下文越重。
代码执行模式可以把工具目录当作可探索环境。模型可以先查看服务列表,再定位具体工具:
// 伪代码:模型可以用文件系统探索工具
const services = await fs.readdir('./servers');
// ['google-drive', 'salesforce', 'slack', 'jira']
const gdriveTools = await fs.readdir('./servers/google-drive');
// ['getDocument.ts', 'getSheet.ts', 'searchFiles.ts']
如果还有工具搜索能力,也可以提供一个轻量级搜索接口:
const matches = await searchTools('update salesforce record');
// 返回 salesforce.updateRecord 的路径和简要描述
这种设计和软件工程中的模块化很接近:不需要把整个代码库复制进脑子里,只需要知道如何查找、如何阅读接口、如何调用。
大数据处理:先过滤,再把小结果交给模型
直接工具调用最怕大表格、大日志、大文档,因为这些数据一旦返回给模型,就会占用大量上下文。
假设有一个包含 10000 行订单的表格,任务是找出待处理订单并检查前几条。传统模式可能会这样做:
TOOL CALL: gdrive.getSheet(sheetId: 'abc123')
如果工具直接返回完整表格,10000 行数据都会进入上下文。模型可能只需要其中 5 行,但已经为全部数据支付了 Token 成本。
代码执行模式可以在执行环境里先过滤:
import * as gdrive from './servers/google-drive';
const allRows = await gdrive.getSheet({
sheetId: 'abc123',
});
const pendingOrders = allRows.filter(
row => row['Status'] === 'pending',
);
console.log(`发现 ${pendingOrders.length} 个待处理订单`);
console.log(pendingOrders.slice(0, 5));
模型最终只需要看到类似结果:
发现 238 个待处理订单
[
{ "OrderId": "A1001", "Status": "pending", "Amount": 129.5 },
{ "OrderId": "A1042", "Status": "pending", "Amount": 88.0 },
{ "OrderId": "A1088", "Status": "pending", "Amount": 299.0 },
{ "OrderId": "A1097", "Status": "pending", "Amount": 45.5 },
{ "OrderId": "A1130", "Status": "pending", "Amount": 760.0 }
]
这就是代码执行模式的一个重要价值:让模型处理“判断所需的信息”,而不是处理“工具能返回的全部信息”。
常见的数据缩减方式包括:
| 处理方式 | 作用 |
|---|---|
filter | 只保留符合条件的数据 |
map | 提取模型需要的字段 |
slice | 只查看前几条样本 |
count | 只返回数量 |
groupBy | 先聚合,再返回汇总 |
| 正则匹配 | 从日志或文本中提取关键片段 |
控制流:循环、条件和错误处理交给代码
多工具任务经常需要控制流。比如:
- 查询结果为空时换一个关键词;
- 调用接口失败后重试;
- 每 5 秒轮询一次部署状态;
- 对 100 条记录逐条更新;
- 某个字段缺失时跳过当前数据。
如果完全依赖模型多轮调用工具,流程会变得很长:
模型调用工具 -> 工具返回 -> 模型判断 -> 模型再次调用工具 -> 工具返回 -> 模型再判断
每一轮都会产生延迟和上下文消耗。
代码执行可以直接使用普通编程语言的控制结构。例如,等待 Slack 频道里出现部署完成消息:
import * as slack from './servers/slack';
let found = false;
while (!found) {
const messages = await slack.getChannelHistory({
channel: 'C123456',
limit: 20,
});
found = messages.some(message =>
message.text.includes('deployment complete'),
);
if (!found) {
await new Promise(resolve => setTimeout(resolve, 5000));
}
}
console.log('部署完成通知已收到');
这段逻辑不需要模型每 5 秒重新参与一次。模型生成代码后,轮询过程由执行环境完成,只有最终状态需要返回。
错误处理也是同样道理:
async function retry<T>(
fn: () => Promise<T>,
maxRetries = 3,
): Promise<T> {
let lastError: unknown;
for (let i = 0; i < maxRetries; i++) {
try {
return await fn();
} catch (error) {
lastError = error;
await new Promise(resolve => setTimeout(resolve, 1000 * (i + 1)));
}
}
throw lastError;
}
const result = await retry(() =>
salesforce.updateRecord({
objectType: 'Lead',
recordId: '00Q5f000001abcXYZ',
data: { Status: 'Contacted' },
}),
);
把重试逻辑放在代码里,比让模型多轮判断“是否要重试”更稳定,也更省 Token。
隐私保护:让敏感数据停留在执行环境
很多 Agent 任务会处理敏感信息,例如邮箱、手机号、客户姓名、合同金额、员工数据。直接工具调用模式下,只要工具返回这些字段,它们就可能进入模型上下文。
代码执行模式可以把敏感数据留在执行环境里,只让模型看到脱敏后的日志或摘要。
例如,执行环境可以在 console.log 时自动做令牌化:
const row = {
name: 'Alice Chen',
email: 'alice@example.com',
phone: '+1-555-123-4567',
};
console.log(row.email);
console.log(row.phone);
模型看到的不是原始数据,而是:
[EMAIL_1]
[PHONE_1]
真实数据仍然可以在工具之间流转:
const leads = await gdrive.getSheet({
sheetId: 'lead-sheet',
});
for (const lead of leads) {
await salesforce.createRecord({
objectType: 'Lead',
data: {
Name: lead.name,
Email: lead.email,
Phone: lead.phone,
},
});
}
在这个流程中,邮箱和手机号从 Google Sheets 进入 Salesforce,但不需要暴露给模型。模型负责写处理逻辑,执行环境负责实际数据通道。
这种设计的隐私边界更清晰:
| 数据类型 | 是否需要给模型看 | 推荐处理方式 |
|---|---|---|
| 字段结构 | 需要 | 提供 schema 或少量样例 |
| 统计结果 | 通常需要 | 返回数量、分布、汇总 |
| 敏感原文 | 通常不需要 | 留在执行环境,必要时脱敏 |
| 异常信息 | 部分需要 | 去掉密钥、Token、个人信息后返回 |
状态持久化:任务可以中断、恢复和复用
直接工具调用很依赖对话上下文。如果任务执行一半失败,状态通常散落在模型上下文里,恢复起来不方便。
代码执行环境可以使用文件系统保存中间状态。例如,从 Salesforce 导出线索数据并保存成 CSV:
import * as fs from 'node:fs/promises';
import * as salesforce from './servers/salesforce';
const leads = await salesforce.query({
soql: `
SELECT Id, Name, Email, Company
FROM Lead
WHERE Status = 'Open'
`,
});
const csvData = [
'Id,Name,Email,Company',
...leads.map(lead =>
[
lead.Id,
lead.Name,
lead.Email,
lead.Company,
].join(','),
),
].join('\n');
await fs.writeFile('./workspace/open-leads.csv', csvData);
console.log(`已导出 ${leads.length} 条线索到 ./workspace/open-leads.csv`);
如果后续任务需要继续处理这批数据,不必重新查询,也不必让模型记住完整结果,只要读取文件即可。
const csvData = await fs.readFile(
'./workspace/open-leads.csv',
'utf-8',
);
状态持久化还可以发展成“技能”。如果一段代码经常被复用,就可以保存成函数。
// ./skills/save-sheet-as-csv.ts
import * as fs from 'node:fs/promises';
import * as gdrive from '../servers/google-drive';
export async function saveSheetAsCsv(sheetId: string, outputPath: string) {
const rows = await gdrive.getSheet({ sheetId });
if (rows.length === 0) {
await fs.writeFile(outputPath, '');
return outputPath;
}
const headers = Object.keys(rows[0]);
const csv = [
headers.join(','),
...rows.map(row =>
headers.map(header => JSON.stringify(row[header] ?? '')).join(','),
),
].join('\n');
await fs.writeFile(outputPath, csv);
return outputPath;
}
以后 Agent 可以直接导入这项能力:
import { saveSheetAsCsv } from './skills/save-sheet-as-csv';
const csvPath = await saveSheetAsCsv(
'abc123',
'./workspace/orders.csv',
);
console.log(`CSV 已保存到 ${csvPath}`);
这让 Agent 的能力可以积累,而不是每次任务都从零开始写一遍相同流程。
一个可落地的代码执行架构
代码执行不是简单地给模型一个本地 shell。真正用于 Agent 的执行环境需要隔离、权限控制、资源限制和审计。
一个典型架构可以这样设计:
flowchart TD
U[用户请求] --> O[Agent 编排器]
O --> M[LLM 生成代码]
M --> O
O --> S[安全检查与策略校验]
S --> R[沙箱执行环境]
R --> FS[(工作目录)]
R --> MCP[MCP 工具适配层]
MCP --> G[Google Drive]
MCP --> SF[Salesforce]
MCP --> SL[Slack]
R --> L[日志与结果摘要]
L --> O
O --> U
各模块职责可以拆开看:
| 模块 | 职责 |
|---|---|
| Agent 编排器 | 接收任务、调用模型、管理执行轮次 |
| LLM | 生成代码、根据执行结果修正代码 |
| 安全检查 | 阻止危险 API、限制网络访问、检查敏感操作 |
| 沙箱执行环境 | 运行模型生成的代码,限制 CPU、内存、时间和文件访问 |
| MCP 工具适配层 | 把 MCP 工具封装成代码可调用的函数 |
| 工作目录 | 保存中间文件、缓存、可复用技能 |
| 日志与结果摘要 | 把必要输出返回给模型和用户 |
这种架构把“智能决策”和“数据执行”分开。模型负责理解任务和生成程序,沙箱负责执行程序,MCP 适配层负责连接外部系统。
工具 API 应该如何封装
为了让模型更容易写对代码,MCP 工具封装不能只是随便包一层函数。接口需要清晰、稳定,并且对模型友好。
一个工具文件可以包含类型定义、参数说明和示例:
// ./servers/google-drive/getDocument.ts
export interface GetDocumentInput {
/**
* Google Drive document id.
*/
documentId: string;
/**
* Optional list of fields to return.
* Example: ['title', 'content']
*/
fields?: string[];
}
export interface GoogleDocument {
id: string;
title: string;
content: string;
metadata: Record<string, unknown>;
}
export async function getDocument(
input: GetDocumentInput,
): Promise<GoogleDocument> {
return callMcpTool('gdrive.getDocument', input);
}
也可以提供目录级导出,方便模型导入:
// ./servers/google-drive/index.ts
export { getDocument } from './getDocument';
export { getSheet } from './getSheet';
export { searchFiles } from './searchFiles';
模型生成代码时就可以写:
import { getDocument } from './servers/google-drive';
const document = await getDocument({
documentId: 'abc123',
});
工具封装时要注意几件事:
| 设计点 | 建议 |
|---|---|
| 命名 | 使用业务含义明确的函数名,例如 getDocument、updateRecord |
| 类型 | 提供输入输出类型,减少模型猜参数 |
| 示例 | 在注释里给最小可用示例 |
| 返回值 | 避免默认返回过大数据,支持字段选择、分页、limit |
| 错误 | 返回结构化错误,便于代码重试或分支处理 |
| 权限 | 在适配层检查用户权限,而不是完全交给模型自觉 |
代码执行带来的新风险
代码执行减少了 Token 消耗,但它也把系统复杂度推到了运行时。模型生成的代码不应该在无限制环境中执行。
需要重点处理这些风险:
| 风险 | 例子 | 防护方式 |
|---|---|---|
| 越权访问 | 代码读取无关文件或调用未授权工具 | 文件系统隔离、工具白名单、按用户授权 |
| 资源滥用 | 死循环、大量请求、超大文件写入 | CPU、内存、运行时间、磁盘配额限制 |
| 数据泄露 | 打印客户邮箱、密钥、合同内容 | 日志脱敏、敏感字段令牌化、输出审计 |
| 供应链风险 | 动态安装恶意依赖 | 禁止任意安装依赖,使用预置运行时 |
| 网络风险 | 访问未知外部地址 | 网络白名单、出站请求代理 |
| 破坏性操作 | 批量删除记录、错误更新生产数据 | 人工确认、事务回滚、dry-run 模式 |
| 提示注入 | 外部文档诱导模型生成危险代码 | 工具输出分级、指令隔离、策略校验 |
沙箱至少应该具备这些限制:
sandbox:
timeoutSeconds: 30
maxMemoryMB: 512
maxCpuCores: 1
filesystem:
writablePaths:
- ./workspace
readonlyPaths:
- ./servers
- ./skills
network:
mode: allowlist
allowedHosts:
- mcp-gateway.internal
tools:
allowed:
- google-drive.getDocument
- google-drive.getSheet
- salesforce.updateRecord
- slack.getChannelHistory
logging:
redact:
- email
- phone
- api_key
- access_token
如果任务涉及高风险写操作,可以要求代码先生成执行计划:
const plan = leads.map(lead => ({
recordId: lead.Id,
changes: {
Status: 'Contacted',
},
}));
console.log(JSON.stringify(plan, null, 2));
// 等待用户确认后再执行真正更新
这样可以在模型生成代码和系统执行破坏性操作之间增加一道明确的确认边界。
什么时候适合用代码执行
代码执行不是所有 Agent 场景的默认答案。它适合工具多、数据大、流程长的任务;对于简单问答或单次工具查询,直接工具调用反而更轻。
| 场景 | 更适合的方式 | 原因 |
|---|---|---|
| 查询天气、查一条记录 | 直接工具调用 | 工具少、返回小,代码执行的沙箱成本不必要 |
| 连接几十到几千个工具 | 代码执行 | 可以按需发现工具,避免工具定义占满上下文 |
| 处理大表格、长文档、日志 | 代码执行 | 可以先过滤、聚合、抽样,再返回小结果 |
| 多步骤自动化流程 | 代码执行 | 循环、条件、重试可以用代码表达 |
| 涉及敏感数据搬运 | 代码执行 | 数据可以留在执行环境,模型只看脱敏摘要 |
| 高风险生产写操作 | 谨慎使用代码执行 | 必须配合权限、审计、确认和回滚机制 |
判断是否需要代码执行,可以看三个问题:
- 工具定义是否已经明显占用大量上下文?
- 工具返回的数据是否大到模型不需要完整阅读?
- 任务是否包含循环、重试、批处理、文件保存等程序化逻辑?
如果答案里有两个是“是”,代码执行通常会比直接工具调用更合适。
实现时可以从最小版本开始
不需要一开始就构建完整平台。一个最小可用版本可以只包含四部分:
flowchart LR
A[工具封装目录] --> B[模型生成脚本]
B --> C[受限 Node.js 沙箱]
C --> D[MCP 网关]
C --> E[执行摘要]
可以按这个顺序落地:
1. 把常用 MCP 工具封装成 TypeScript API
servers/
├── google-drive/
│ ├── index.ts
│ └── getDocument.ts
└── salesforce/
├── index.ts
└── updateRecord.ts
2. 给模型提供工具目录和少量读取能力
不要把所有工具内容一次性放进上下文,只提供目录结构、搜索能力或按需读取能力。
const files = await listFiles('./servers');
const source = await readFile('./servers/google-drive/getDocument.ts');
3. 在沙箱里运行模型生成的代码
限制运行时间、内存、文件路径和可访问工具。
const result = await runInSandbox({
code,
timeoutMs: 30_000,
memoryLimitMb: 512,
writableDirectory: './workspace',
});
4. 只把必要日志返回给模型
执行环境不要把所有变量、所有工具结果都回传给模型。默认只返回:
console.log的脱敏输出;- 程序退出状态;
- 结构化错误;
- 用户需要的最终结果摘要。
{
"status": "success",
"logs": [
"发现 238 个待处理订单",
"已更新 238 条 Salesforce 记录"
]
}
核心变化:模型从数据搬运工变成程序生成器
直接工具调用让模型处在所有工具之间,工具定义和中间结果都要流经上下文。代码执行把模型从数据通道里移出来,让它专注于生成处理逻辑。
这种转变带来几个具体结果:
- 工具按需发现,减少无关工具定义占用;
- 大数据留在执行环境里处理,模型只看摘要;
- 循环、重试、批处理用代码表达,减少多轮调用;
- 敏感数据可以在工具之间流转,不必暴露给模型;
- 中间状态可以写入文件,任务更容易恢复和复用。
代价也很明确:系统必须提供安全沙箱、权限控制、资源限制、日志脱敏和操作审计。没有这些保护,代码执行会把 Agent 的风险从“模型说错话”扩大到“模型执行错操作”。
对于复杂 Agent 系统,代码执行的意义不只是省 Token。更重要的是,它把传统软件工程里成熟的抽象、模块化、控制流、状态管理和隔离机制带回了 Agent 架构。模型擅长写代码,就应该让它用代码组合工具,而不是让它在上下文里手工搬运每一份数据。