大语言模型(Large Language Model,LLM)擅长总结、推理和生成文本,但它有一个天然限制:模型参数里的知识是静态的。面对“最近有哪些方法在优化长链工具调用”“某个开源项目过去三个月的技术路线如何变化”这类问题,只靠参数记忆很容易过时,也很难给出可追溯证据。
检索增强生成(Retrieval-Augmented Generation,RAG)把外部资料引入生成过程,缓解了知识过期问题。但普通 RAG 往往只是“检索 top-k 文档,再让模型回答”,对于开放研究任务仍然不够:
- 用户问题可能很模糊,需要拆成多个研究子问题;
- 单次检索很难覆盖完整证据链,需要多轮搜索和浏览;
- 网页内容质量参差不齐,需要筛选可信来源;
- 最终输出不只是一个答案,而是结构化报告、引用、对比和结论。
Deep Research 解决的正是这类问题。它把 LLM 从一次性问答器升级成自主研究智能体:先制定研究计划,再生成检索问题,主动访问网页和工具,收集证据,最后整理成结构清晰、事实可核验的研究报告。
Deep Research 的整体架构
一个完整的 Deep Research 系统通常由四个核心阶段组成:Planning、Question Developing、Web Exploration、Report Generation。
系统架构图把这四个阶段串成了一条研究流水线:用户输入不是直接送进模型生成答案,而是先进入规划器,再驱动检索、浏览、证据抽取和报告生成。
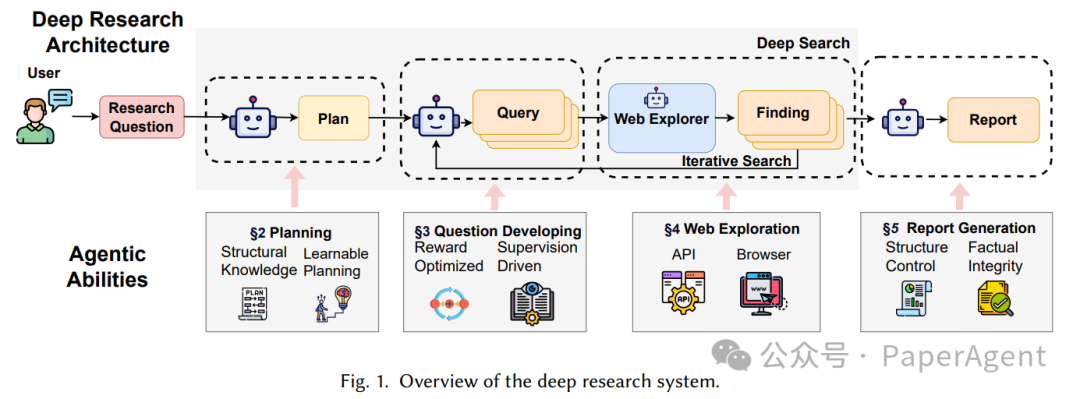
架构里的关键点不在于“调用搜索引擎”本身,而在于搜索被纳入了一个可迭代的智能体循环。系统会根据已有证据决定是否继续检索、是否改写查询、是否访问更权威来源,以及是否需要补充某个缺失维度。
可以用一个更抽象的流程表示:
flowchart TD
A[用户研究问题] --> B[Planning<br/>拆解研究目标]
B --> C[Question Developing<br/>生成检索查询]
C --> D[Web Exploration<br/>搜索/浏览/抽取]
D --> E[Evidence Store<br/>证据库]
E --> F{证据是否足够?}
F -- 否 --> C
F -- 是 --> G[Report Generation<br/>生成报告]
G --> H[引用校验/冲突检测]
H --> I[最终研究报告]
四个模块的职责可以压缩成一张表:
| 模块 | 输入 | 输出 | 核心难点 |
|---|---|---|---|
| Planning | 用户问题、约束、已有上下文 | 子目标、研究路径、检索顺序 | 如何把模糊问题变成可执行计划 |
| Question Developing | 子目标、当前证据状态 | 多个检索查询 | 如何兼顾准确性和覆盖面 |
| Web Exploration | 查询、工具状态、网页内容 | 证据片段、来源、可信度信息 | 如何过滤噪声、处理失效网页和重复内容 |
| Report Generation | 证据库、计划、大纲 | 结构化报告 | 如何保证逻辑连贯、引用真实、事实一致 |
Planning:把开放问题拆成研究计划
Planning 的目标是把一句开放问题变成可执行研究计划。比如用户问:
近期 Deep Research 系统为什么越来越多使用强化学习?
这个问题不能只搜一个关键词。更合理的计划可能是:
- 明确 Deep Research 系统包含哪些环节;
- 对比监督微调、偏好优化、强化学习在工具调用任务中的差异;
- 收集强化学习用于检索、浏览、报告生成的代表方法;
- 分析奖励设计、数据构造和训练系统的工程瓶颈;
- 给出适用场景和局限。
Planning 不是简单列提纲,它还决定研究路径。不同路径会影响后续检索质量。例如先查“Deep Research survey”,再查“RL for search agent”,通常比直接搜“best deep research method”更容易得到可验证资料。
常见规划方法可以分成两类:
| 方法类型 | 思路 | 代表方向 | 适合场景 |
|---|---|---|---|
| 结构化世界知识 | 借助知识图谱、模拟环境或已有任务结构,在行动前预演 | Simulate Before Act、WebPilot | 任务有明确领域结构,或者网页操作路径可预测 |
| 可学习规划 | 用搜索、强化学习或多智能体协作优化规划策略 | AgentSquare、MindSearch | 任务空间大、步骤多、路径不固定 |
一个好的规划器至少要输出三类信息:
research_plan:
goal: "分析 Deep Research 使用强化学习的原因"
subgoals:
- "梳理 Deep Research 的系统模块"
- "比较 SFT、DPO、RL 的训练目标"
- "总结 RL 数据构造方法"
- "总结奖励设计和信用分配方法"
constraints:
- "优先使用近两年的论文和开源项目"
- "报告中保留证据来源"
stop_condition:
- "每个子目标至少有两个独立证据"
- "核心结论可被引用支持"
Planning 阶段最常见的问题是“计划看起来完整,但不可执行”。例如“全面调研所有方法”太宽泛,后续检索会失控;“找三篇论文”又可能过窄,无法覆盖工程实现。更稳妥的做法是把计划拆成可验证的子问题,并为每个子问题指定证据要求。
Question Developing:把子目标变成高质量查询
Planning 得到的是研究目标,搜索引擎需要的是查询语句。Question Developing 的任务是为每个子目标生成多样化、上下文相关的查询。
以“比较 SFT、DPO、RL 在 Deep Research 中的差异”为例,查询可以有多种形式:
deep research agents reinforcement learning survey
RL for web search agents tool use
SFT DPO RL comparison agent tool use
trajectory-level reward deep research system
这些查询覆盖了不同角度:综述、搜索智能体、训练方法对比、轨迹奖励。单一查询容易遗漏关键信息,多样化查询能提高召回率。
常见方法同样可以分为两类:
| 方法类型 | 核心做法 | 代表方向 | 主要风险 |
|---|---|---|---|
| 奖励优化类 | 用强化学习优化查询生成策略,让查询更容易带来有效证据 | DeepResearcher、R1-Searcher | 奖励设计不当时,模型可能学会刷指标 |
| 监督驱动类 | 通过规则、标注轨迹或多智能体协作生成查询 | ManuSearch、SearchAgent-X | 容易模仿训练数据,遇到新问题时泛化有限 |
高质量查询通常有三个特点:
- 明确实体:包含论文名、系统名、任务名或指标名;
- 控制范围:通过年份、领域、方法类型限制搜索空间;
- 保留探索性:不只搜结论,也搜反例、失败案例和评测基准。
查询生成还需要根据已有证据动态调整。若搜索结果多是营销页面,系统应改用更学术化的关键词;若结果过于分散,系统应增加约束词;若某个子问题证据不足,系统应继续追问。
Web Exploration:搜索、浏览、抽取和过滤
Web Exploration 是 Deep Research 和普通 RAG 差异最大的地方。普通 RAG 多数情况下只调用一次搜索或向量数据库;Deep Research 则要像研究员一样多轮探索。
sequenceDiagram
participant Agent as 研究智能体
participant Search as 搜索引擎/API
participant Browser as 浏览器工具
participant Store as 证据库
Agent->>Search: 提交查询
Search-->>Agent: 返回候选页面
Agent->>Browser: 打开高价值页面
Browser-->>Agent: 返回正文/表格/链接
Agent->>Agent: 判断可信度与相关性
Agent->>Store: 保存证据片段和来源
Agent->>Agent: 决定继续搜索或停止
探索方式主要有两种:
| 类型 | 做法 | 优点 | 代价 |
|---|---|---|---|
| Web Agent | 模拟人类浏览网页,执行点击、滚动、表单填写、页面跳转 | 能处理复杂网页和交互式内容 | 延迟高,容易受页面结构变化影响 |
| 搜索 API | 调用 Bing、Google 等搜索接口获取结构化结果 | 稳定、快速、容易批处理 | 只能拿到有限摘要,深层信息仍需浏览 |
网页探索阶段需要处理几个工程问题:
- 去重:同一新闻或论文可能被多个站点转载,不能把重复内容当成多个证据;
- 可信度判断:论文、官方文档、代码仓库、技术博客的可信度不同;
- 内容抽取:网页正文、表格、图片、代码块都可能包含证据;
- 预算控制:搜索次数、浏览次数、总耗时都要受控;
- 失败恢复:网页 404、反爬、加载失败时需要换源或改写查询。
证据最好用结构化格式保存,而不是只存一段文本:
{
"claim": "RL 更适合优化多轮工具调用任务",
"evidence": "SFT/DPO 难以利用搜索失败、网页失效、预算超限等环境反馈,RL 可以用轨迹级奖励优化端到端任务成功率。",
"source_url": "https://arxiv.org/abs/2509.06733",
"source_type": "survey_paper",
"timestamp": "2026-06-07",
"confidence": 0.86
}
这种结构方便后续生成报告、做引用校验,也方便在模型产生冲突结论时回溯来源。
Report Generation:从证据片段到可靠报告
报告生成不是把证据拼起来。一个 Deep Research 报告至少要满足四个要求:
- 结构清晰:有明确大纲、层级和结论;
- 证据对齐:关键判断能对应到具体来源;
- 冲突可见:不同来源意见不一致时要说明;
- 事实稳定:不能把证据里没有的内容扩写成确定结论。
常见做法包括:
| 方向 | 做法 | 代表方向 |
|---|---|---|
| 结构控制 | 先生成大纲,再按章节填充证据,必要时使用模板约束 | Agent Laboratory、WebThinker |
| 事实一致性 | 生成后检查引用、比对证据、检测冲突 | FaithfulRAG、DRAGged |
一个实用的生成流程可以拆成三步:
flowchart LR
A[证据库] --> B[生成报告大纲]
B --> C[按章节组织证据]
C --> D[生成草稿]
D --> E[引用校验]
E --> F[冲突检测]
F --> G[最终报告]
报告生成阶段最容易出现“语言很流畅,但引用支撑不住结论”的问题。解决办法是让模型在生成时显式绑定证据,例如每段结论后记录引用 ID,再由校验器检查引用是否真的支持该段内容。
为什么 Deep Research 需要强化学习
监督微调(Supervised Fine-Tuning,SFT)和直接偏好优化(Direct Preference Optimization,DPO)可以让模型模仿人类写出的研究轨迹,但 Deep Research 的难点不只是“生成像样文本”,而是“在交互环境中完成任务”。
搜索可能失败,网页可能失效,浏览预算可能超限,某个查询可能完全没有信息增益。这些反馈只有在智能体真的执行工具调用后才能看到。强化学习(Reinforcement Learning,RL)可以把整条研究轨迹作为优化对象,让模型学习哪些行动会让最终报告更可靠。
三类训练方法的差异很明显:
| 方法 | 优化目标 | 数据形式 | 短板 |
|---|---|---|---|
| SFT | 模仿单步输出 | (q, a) | 容易出现暴露偏差,模型执行错一步后缺少纠错能力 |
| DPO | 学习偏好排序 | (q, a⁺, a⁻) | 通常不建模环境状态,难以处理长程信用分配 |
| RL | 最大化累计回报 | (q, τ, r) | 需要可验证奖励、探索策略和稳定训练系统 |
其中 τ 表示一条完整轨迹,可能包含规划、查询、搜索、网页浏览、证据抽取、报告生成等多个步骤。
τ = [
plan_1,
query_1,
search_result_1,
browse_page_1,
extract_evidence_1,
query_2,
...
final_report
]
RL 的价值在于可以奖励“最终任务成功”,也可以奖励“中间步骤有效”。例如一次搜索找到了包含答案片段的页面,可以给即时奖励;最终报告事实正确且引用充分,可以给结果奖励。
RL 训练数据:Construct → Curate → Curriculum
Deep Research 的 RL 训练离不开高质量任务数据。数据不仅要有问题和答案,还要能支撑多步搜索、多跳推理和工具调用。
复杂度分级图展示了训练任务可以从简单检索逐步提升到多模态、多工具研究任务。
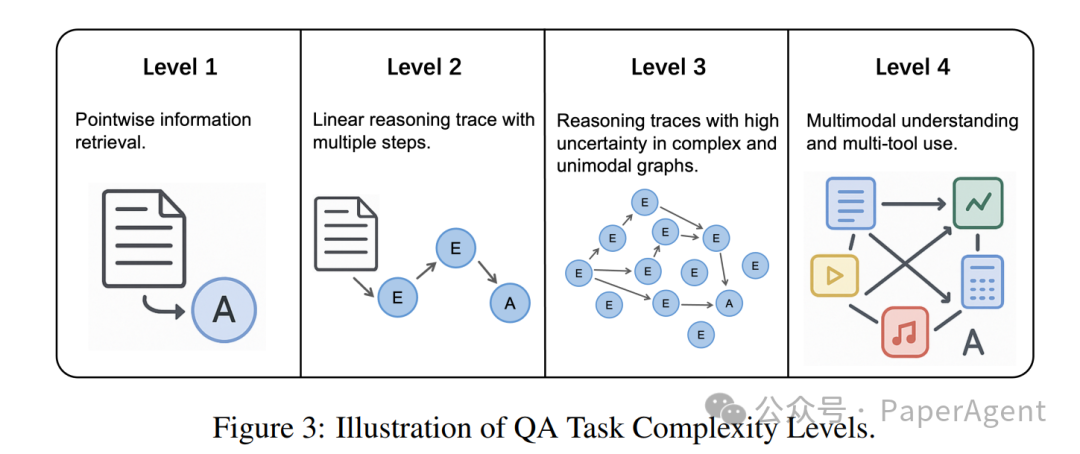
这种分级的意义在于课程学习(Curriculum Learning):先让智能体学会单点检索,再训练线性多跳,最后进入高不确定性和多工具环境。直接把模型放进最复杂任务中训练,探索成本会非常高,奖励也更稀疏。
常见数据流水线是 Construct → Curate → Curriculum。
| 阶段 | 目标 | 典型做法 |
|---|---|---|
| Construct | 构造任务 | 跨文档合成、图结构生长、难度变换 |
| Curate | 清洗任务 | 去除答案不唯一、证据不足、过期或不可验证样本 |
| Curriculum | 安排训练顺序 | 按跳数、证据密度、工具数量和不确定性分级 |
数据构造方法可以进一步拆开:
| 策略 | 核心技巧 | 适合任务 |
|---|---|---|
| 跨文档合成 | 把新鲜新闻、arXiv 论文、官方文档聚类,再生成多跳问题 | 防止模型只依赖参数记忆 |
| 图结构生长 | 从维基、GitHub 等根节点随机游走,根据路径长度生成问题 | 构造可控多跳推理任务 |
| 难度变换 | 用 LLM 给原问题增加约束,提高跳数和证据密度 | 从简单问题扩展出困难样本 |
复杂度可以按四级理解:
| Level | 任务特征 | 示例数据集 |
|---|---|---|
| L1 | 单点检索,一个证据即可回答 | SimpleQA |
| L2 | 线性多跳,需要串联多个事实 | HotpotQA |
| L3 | 高不确定性、复杂图结构,需要探索不同路径 | SailorFog-QA |
| L4 | 多模态、多工具,需要结合网页、图片、代码、OCR 等工具 | WebWatcher |
课程学习的关键不是机械地从 L1 排到 L4,而是根据模型能力动态调整。如果模型在 L2 已经能稳定完成任务,可以增加检索噪声或限制预算;如果模型在 L3 频繁迷路,应回退到更明确的图路径任务。
奖励设计:训练智能体到底奖励什么
奖励设计决定智能体会学到什么行为。奖励过粗,模型不知道哪一步有用;奖励过细,又可能被模型利用漏洞。
奖励框架图把信号分成结果奖励、步骤奖励和信用分配三部分。
结果奖励关注最终答案或报告是否正确,步骤奖励关注过程是否有效,信用分配负责把最终成败分摊给轨迹中的关键行动。
结果奖励
结果奖励只看最终输出,常见指标包括:
- EM(Exact Match,精确匹配):答案是否完全匹配标准答案;
- F1:答案与标准答案在词级别上的重合度;
- LLM-as-Judge:用另一个模型评价报告质量、事实一致性和引用质量。
Deep Research 场景下还会引入更贴近研究任务的奖励:
| 奖励 | 含义 | 作用 |
|---|---|---|
| GBR(Gain-Beyond-RAG) | 相比普通 top-k RAG 的边际提升 | 防止智能体做了很多工具调用却没有比 RAG 更好 |
| Evidence-Utility | 冻结 LLM 只看收集证据能否答对 | 检查证据本身是否有用 |
| Group 相对节俭 | 同批正确轨迹中检索次数更少者加分 | 鼓励控制工具成本 |
步骤奖励
步骤奖励关注中间行动,例如:
- 工具调用成功,并返回包含答案线索的页面;
- 当前轮证据与已有证据相比有信息增益;
- 新证据重复度低;
- 多模态任务中,图片裁剪、OCR(Optical Character Recognition,光学字符识别)、代码执行等步骤结果可用。
步骤奖励可以减少训练稀疏性。若只有最终报告正确才给奖励,模型很难知道是哪个查询、哪次浏览或哪段证据抽取带来了成功。
信用分配
信用分配解决“谁该为最终结果负责”的问题。长轨迹中,最终报告错误可能是规划错、查询错、网页源不可靠,也可能是生成阶段幻觉。
| 粒度 | 做法 | 代表方向 |
|---|---|---|
| 轨迹级 | 整条轨迹共享回报,可用 GAE(Generalized Advantage Estimation,广义优势估计) | Search-R1 |
| 回合级 | 每轮结合即时奖励和终端奖励 | MT-GRPO |
| Token 级 | 在工具调用边界或关键 token 上挂奖励 | ARTIST |
轨迹级奖励简单,但反馈粗;步骤级和 token 级奖励更细,但需要准确识别“关键动作”。工程上常用混合奖励:最终报告质量给大权重,中间搜索、证据抽取和预算控制给辅助权重。
训练系统:让长工具链真正跑起来
Deep Research 的 RL 训练比普通语言模型训练更复杂,因为每条轨迹都要调用搜索、浏览器、解析器、校验器等外部组件。长工具链会带来三个问题:
- 高延迟:一次 rollout 可能包含多次网页访问;
- 高显存占用:策略模型、价值模型、奖励模型可能同时存在;
- 策略过期:异步采样时,worker 采到的数据可能来自旧版本策略。
训练系统图展示了一个典型 RL for Deep Research 框架:策略模型负责产生动作,工具执行器负责访问环境,奖励模块评价轨迹,训练器再更新模型。
工程上可以把系统拆成几个组件:
flowchart LR
A[Policy Model<br/>策略模型] --> B[Rollout Workers<br/>轨迹采样]
B --> C[Tool Executors<br/>搜索/浏览/OCR/代码]
C --> D[Evidence Cache<br/>证据与网页缓存]
B --> E[Trajectory Store<br/>轨迹存储]
E --> F[Reward Verifier<br/>奖励与校验]
F --> G[Learner<br/>参数更新]
G --> A
几个实现细节会直接影响训练是否稳定:
| 问题 | 处理方式 |
|---|---|
| 工具调用太慢 | 异步 rollout、结果缓存、批量搜索 |
| 网页内容不稳定 | 固化快照、记录时间戳、保存正文摘要 |
| 奖励噪声大 | 多评审器投票、规则校验与模型评审结合 |
| 策略过期 | 给轨迹记录策略版本,限制最大滞后 |
| 成本过高 | 设置搜索预算、浏览预算和最大 token 数 |
如果只是做原型,可以先不训练 RL,而是实现可观测的 Deep Research loop,把每次工具调用、证据、失败原因和生成报告全部记录下来。只有轨迹可追踪,后续才有可能做 SFT、DPO 或 RL。
一个最小 Deep Research 原型
一个可运行原型不需要一开始就很复杂。核心是把“规划—检索—证据—生成”闭环跑通。
def deep_research(user_query, max_rounds=5):
plan = planner(user_query)
evidence_store = []
for round_id in range(max_rounds):
queries = query_generator(
plan=plan,
evidence=evidence_store
)
new_evidence = []
for q in queries:
results = search_api(q)
pages = select_pages(results)
for page in pages:
content = browser_read(page.url)
evidence = extract_evidence(content, user_query, plan)
if is_useful(evidence, evidence_store):
new_evidence.append(evidence)
evidence_store.extend(new_evidence)
if evidence_is_sufficient(plan, evidence_store):
break
plan = revise_plan(plan, evidence_store)
draft = generate_report(plan, evidence_store)
report = verify_and_rewrite(draft, evidence_store)
return report
原型阶段建议优先实现这些能力:
| 能力 | 为什么重要 |
|---|---|
| 证据结构化存储 | 后续引用校验和奖励计算都依赖它 |
| 查询日志 | 能分析模型为什么搜不到信息 |
| 来源去重 | 防止重复页面制造虚假信心 |
| 引用校验 | 降低报告幻觉 |
| 预算控制 | 防止智能体无限搜索 |
常见坑和处理方式
Deep Research 系统看起来像“让模型多搜几次”,实际落地时容易踩坑。
| 问题 | 表现 | 处理方式 |
|---|---|---|
| 规划过宽 | 搜索很多,但结论松散 | 限制子目标数量,为每个子目标设置证据要求 |
| 查询同质化 | 多轮搜索返回相同页面 | 强制查询多样化,记录已访问实体和关键词 |
| 证据污染 | 低质量转载内容被当成权威证据 | 给来源类型打权重,优先论文、官方文档、代码仓库 |
| 报告幻觉 | 生成内容超出证据范围 | 每个关键结论绑定证据 ID,生成后做引用校验 |
| 工具成本失控 | 搜索次数和浏览次数过多 | 引入预算奖励和停止条件 |
| RL 奖励被钻空子 | 模型学会迎合评审器 | 组合规则指标、人工抽检和多模型评审 |
适合使用 Deep Research 的场景
Deep Research 适合开放、动态、证据密集的任务,不适合所有问答场景。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 最新论文综述 | 适合 | 需要动态检索、多源对比和引用 |
| 开源项目技术调研 | 适合 | 需要结合 README、issue、commit、release |
| 公司内部固定知识库问答 | 不一定 | 普通 RAG 可能更低成本 |
| 简单事实查询 | 不适合 | 一次搜索即可回答,Deep Research 成本过高 |
| 多模态网页分析 | 适合 | 需要浏览、图片理解、OCR 和多工具协同 |
关键结论
Deep Research 的核心不是“更长的回答”,而是把研究任务拆成可执行的智能体流程:规划目标、生成查询、探索网页、沉淀证据、生成报告并校验引用。
SFT 和 DPO 能让模型模仿已有轨迹,但很难利用真实环境反馈。RL 更适合优化 Deep Research,因为搜索失败、网页失效、预算超限、证据质量这些信号只有在交互过程中才会出现。想让系统可靠,不能只盯最终生成效果,还要同时设计任务数据、步骤奖励、结果奖励、信用分配和训练系统。
真正可用的 Deep Research 系统通常具备三个特征:研究过程可追踪,证据来源可验证,工具调用成本可控制。