VoxCPM 是清华大学联合面壁智能开源的一款文本转语音模型,模型规模为 0.5B,也就是大约 5 亿参数。它的定位很明确:用较小的模型尺寸完成高自然度语音合成,并支持零样本语音克隆。
所谓零样本语音克隆,指的是不需要重新训练模型,只给一小段参考音频,模型就能在新的文本上生成接近参考说话人的音色、口音和说话风格。对语音助手、有声内容制作、交互式数字人、方言合成等场景来说,这类能力比普通文本转语音更实用。
VoxCPM 的几个核心特点可以概括成四点:
| 能力 | 含义 |
|---|---|
| 0.5B 参数规模 | 模型相对轻量,部署和推理成本低于大参数语音模型 |
| 零样本语音克隆 | 上传几秒参考语音,即可生成相似音色的新语音 |
| 支持中英文与口音/方言表达 | 可处理英语口音、中文方言、不同情绪等表达方式 |
| RTF 约 0.17,支持流式输出 | 在合适硬件上能较快生成音频,适合实时交互类应用 |
RTF(Real-Time Factor,实时因子)是衡量语音生成速度的重要指标:
RTF = 生成音频所需时间 / 音频本身时长
如果生成一段 10 秒音频需要 1.7 秒,那么 RTF 就是 0.17。RTF 越低,生成越快。VoxCPM 在 RTX 4090 上的 RTF 大约为 0.17,已经能覆盖不少实时或准实时场景。
VoxCPM 解决的核心问题
传统文本转语音系统通常能把文字念出来,但要做到“像某个人在自然说话”,难点会明显增加。一个语音克隆模型至少要同时处理几件事:
- 文本内容要读准,不能漏字、错字或乱读。
- 生成语音要自然,停顿、重音、语气不能机械。
- 参考音色要还原,不能只像一个泛化出来的普通声音。
- 推理速度要足够快,否则无法用于实时对话。
- 模型不能太大,否则部署门槛会很高。
VoxCPM 的目标就是在这些指标之间做平衡:模型尺寸保持在 0.5B,同时在自然度、音色相似度、韵律和生成速度上保持较强表现。
一个典型的语音克隆使用流程是这样的:
flowchart LR
A[输入目标文本] --> C[语义理解与上下文建模]
B[上传几秒参考音频] --> D[提取音色、口音、风格信息]
C --> E[语音特征生成]
D --> E
E --> F[声学解码]
F --> G[输出合成音频]
用户输入一段新文本,再提供一小段参考语音。模型从文本中理解要说什么,从参考音频中提取“怎么说”,然后生成新的语音波形。
评测指标:WER、CER、SIM 分别看什么
语音合成模型不能只靠听感判断,还需要量化指标。VoxCPM 在 Seed-TTS-EVAL 评测中与多种主流语音合成模型做了对比,主要观察 WER、CER 和 SIM 等指标。
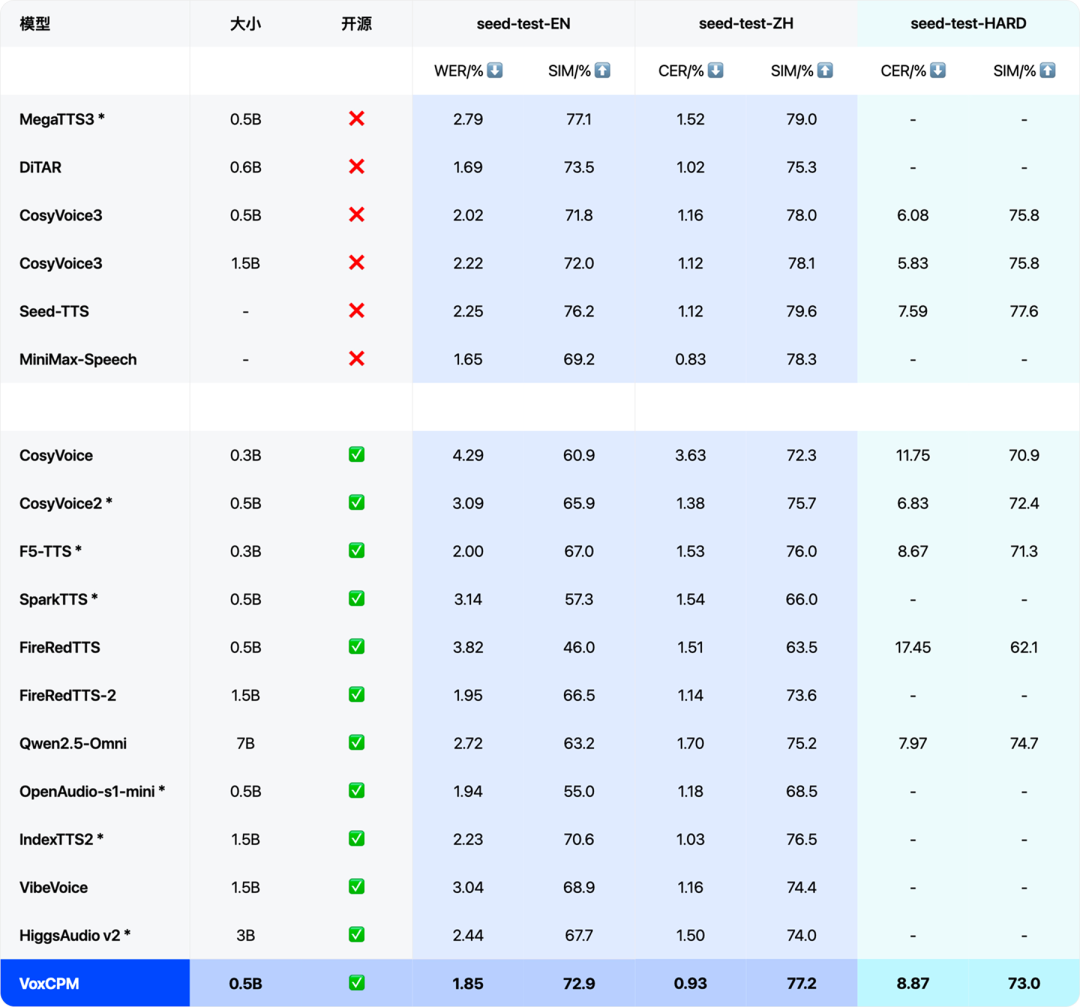
这张表把开源和闭源模型放在同一套评测维度下比较。理解这些指标时,可以按下面的方式看:
| 指标 | 全称 | 衡量内容 | 越高越好还是越低越好 |
|---|---|---|---|
| WER | Word Error Rate,词错误率 | 英文语音合成后,识别结果与目标文本的词级差异 | 越低越好 |
| CER | Character Error Rate,字错误率 | 中文语音合成后,识别结果与目标文本的字级差异 | 越低越好 |
| SIM | Similarity,相似度 | 合成语音与参考音色之间的相似程度 | 越高越好 |
| RTF | Real-Time Factor,实时因子 | 生成速度,等于生成耗时除以音频时长 | 越低越好 |
WER 和 CER 主要看“有没有读对”,SIM 主要看“像不像参考说话人”,RTF 主要看“生成够不够快”。一个语音克隆模型如果只在其中一项表现好,实际价值会受限。例如,音色很像但经常读错字,不适合正式内容生产;读得很准但速度很慢,也很难用于实时对话。
VoxCPM 的优势在于模型规模较小,却在准确性、音色相似度和推理效率之间取得了较好的平衡,尤其适合中文语音合成和中文音色克隆场景。
模型结构:用 MiniCPM-4 理解文本,在连续空间生成语音
VoxCPM 的整体架构可以分成几个关键部分:文本理解、参考语音处理、连续语音特征生成和最终音频输出。
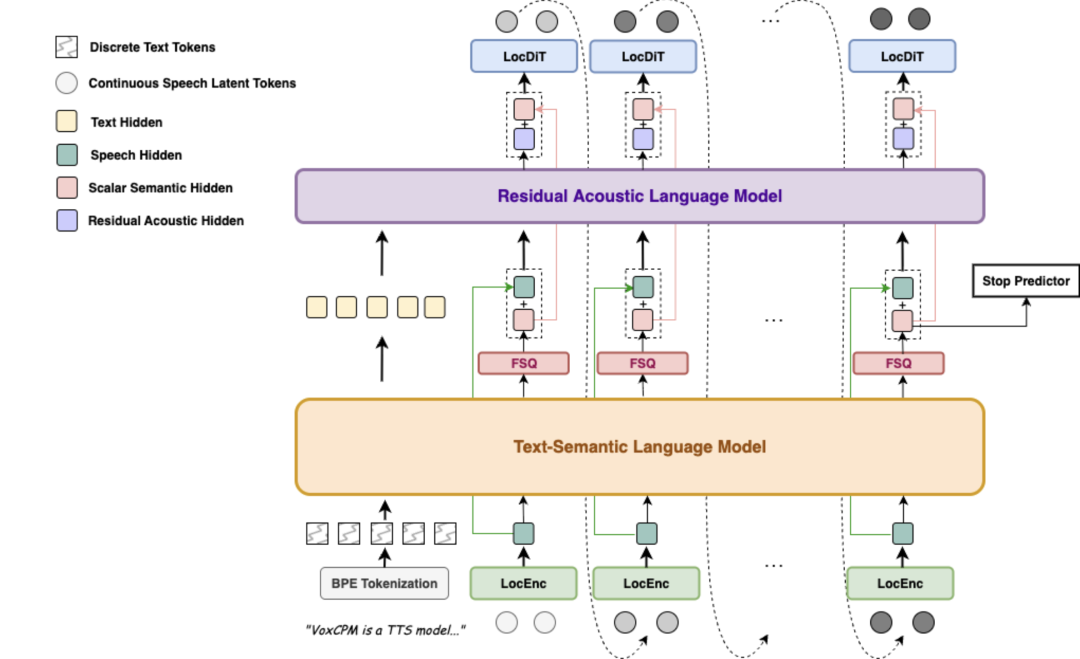
架构中的核心思路是:用 MiniCPM-4 承担文本上下文理解能力,再结合参考音频中的音色和风格信息,直接在连续空间里生成语音特征。它没有沿用一些传统方案中“先把语音离散化成 token,再生成 token,再还原语音”的完整路径,而是采用连续表示上的扩散自回归生成方式。
可以把它理解成下面这条链路:
flowchart TD
T[目标文本] --> L[MiniCPM-4 语言理解]
P[参考音频] --> A[提示音频增强与识别]
A --> S[说话人音色与风格信息]
L --> G[连续空间扩散自回归生成]
S --> G
G --> Q[FSQ 等约束进行特征解耦]
Q --> W[输出语音波形]
这里有几个关键点。
1. MiniCPM-4 负责文本上下文理解
文本转语音不是简单地把每个字转换成声音。模型需要理解句子结构、语义重心、标点停顿和上下文关系。
例如,同一句话在不同上下文里可能需要不同重音:
“你真的要现在走吗?”
这句话可以表达疑问、挽留、惊讶,也可以表达不满。文本理解能力越强,后续生成的韵律越容易自然。
VoxCPM 使用 MiniCPM-4 作为语言理解部分,相当于给语音生成模块提供更清楚的语义信息,让模型知道文本应该怎样被表达,而不只是机械地读出来。
2. 参考音频提供音色、口音和表达风格
零样本语音克隆不需要对某个说话人单独训练。用户只需要给一段参考音频,模型就从中提取说话人的特征,包括:
| 特征 | 作用 |
|---|---|
| 音色 | 决定声音听起来像谁 |
| 口音 | 决定发音习惯和语言风格 |
| 语速 | 影响整体节奏 |
| 停顿 | 影响自然度和表达方式 |
| 情绪倾向 | 影响开心、伤心、愤怒等表达效果 |
如果参考音频是一段带口音的英语,模型需要在新文本中尽量保持这种口音特征;如果参考音频是四川话或河南话,模型也需要捕捉方言发音和节奏上的差异。
3. 连续空间生成保留更多语音细节
很多语音生成系统会先把语音变成离散 token,再像语言模型生成文字一样生成这些 token。这种方式容易建模,也便于复用语言模型技术,但离散化过程可能损失细节,尤其是音色纹理、气息、细微韵律等连续变化的信息。
VoxCPM 选择在连续空间中生成语音特征,再结合扩散自回归方式逐步得到目标语音。连续表示的好处是能保留更细的声学变化,因此更适合做高相似度音色复刻和富有表现力的语音合成。
4. FSQ 约束用于特征解耦
FSQ(Finite Scalar Quantization,有限标量量化)一类约束可以帮助模型把不同语音因素拆开处理。语音中混在一起的信息很多:文本内容、说话人音色、情绪、语速、口音都叠在同一段波形里。
特征解耦的目标是让模型尽量分清:
- 哪些信息来自文本内容;
- 哪些信息来自参考说话人;
- 哪些信息属于语气和韵律;
- 哪些信息不应该被复制,例如背景噪声。
解耦做得越好,模型越容易在“说对内容”和“保持音色”之间取得平衡。
安装与快速体验
VoxCPM 已经在 GitHub 和 Hugging Face 上开源,也提供了在线 Demo。只想先试效果,可以直接用 Hugging Face Spaces;需要集成到项目里,再本地安装和调用。
相关地址:
GitHub: https://github.com/OpenBMB/VoxCPM/
Hugging Face 模型: https://huggingface.co/openbmb/VoxCPM-0.5B
在线 Demo: https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo
音频样例: https://openbmb.github.io/VoxCPM-demopage
安装 Python 包
pip install voxcpm
安装完成后,可以直接在 Python 中加载模型。第一次运行时,模型权重通常会自动下载。
手动下载模型和辅助组件
如果希望提前准备模型文件,可以用 huggingface_hub 和 modelscope 手动下载。
from huggingface_hub import snapshot_download
from modelscope import snapshot_download as modelscope_snapshot_download
# 下载 VoxCPM-0.5B
snapshot_download("openbmb/VoxCPM-0.5B")
# 下载 ZipEnhancer
modelscope_snapshot_download("iic/speech_zipenhancer_ans_multiloss_16k_base")
# 下载 SenseVoice-Small
modelscope_snapshot_download("iic/SenseVoiceSmall")
这里涉及两个辅助组件:
| 组件 | 作用 |
|---|---|
| ZipEnhancer | 对语音提示进行增强,改善参考音频质量 |
| SenseVoice-Small | 对参考语音做 ASR(Automatic Speech Recognition,自动语音识别) |
参考音频质量会直接影响克隆效果。如果参考音频噪声很大、混响明显,或者里面有多人说话,模型提取到的音色信息会变差。
用 Python 生成语音
不做音色克隆时,只输入文本即可生成语音。
import soundfile as sf
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
wav = model.generate(
text=(
"VoxCPM is an innovative end-to-end TTS model from ModelBest, "
"designed to generate highly expressive speech."
),
prompt_wav_path=None,
prompt_text=None,
cfg_value=2.0,
inference_timesteps=10,
normalize=True,
denoise=True,
retry_badcase=True,
retry_badcase_max_times=3,
retry_badcase_ratio_threshold=6.0,
)
sf.write("output.wav", wav, 16000)
print("saved: output.wav")
生成结果会保存到 output.wav,采样率为 16000 Hz。
加入参考音频做语音克隆
如果要克隆某段参考声音,需要传入 prompt_wav_path。如果知道参考音频对应的文字,也可以传入 prompt_text,帮助模型更准确地对齐内容和声音。
import soundfile as sf
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
wav = model.generate(
text="欢迎使用 VoxCPM,这是一段根据参考音色生成的新语音。",
prompt_wav_path="prompt.wav",
prompt_text="这里填写参考音频中实际说的内容。",
cfg_value=2.0,
inference_timesteps=10,
normalize=True,
denoise=True,
retry_badcase=True,
retry_badcase_max_times=3,
retry_badcase_ratio_threshold=6.0,
)
sf.write("cloned.wav", wav, 16000)
print("saved: cloned.wav")
几个常用参数的含义如下:
| 参数 | 作用 | 调整建议 |
|---|---|---|
text | 要合成的目标文本 | 文本尽量完整,标点会影响停顿 |
prompt_wav_path | 参考音频路径 | 做语音克隆时填写 |
prompt_text | 参考音频对应文本 | 有准确转写时建议填写 |
cfg_value | 语言模型引导强度 | 越高越贴合提示,但过高可能影响自然度 |
inference_timesteps | 扩散推理步数 | 越高质量通常越好,但速度会变慢 |
normalize | 是否启用文本规范化 | 中文数字、日期、英文缩写较多时建议开启 |
denoise | 是否启用降噪 | 参考音频质量一般时建议开启 |
retry_badcase | 是否对异常生成结果重试 | 长文本或复杂文本可开启 |
如果只追求速度,可以适当降低 inference_timesteps;如果更在意音质和稳定性,可以增加推理步数,但生成时间会变长。
启动 Web UI
如果已经克隆项目仓库并安装好依赖,可以在项目目录中启动界面:
python app.py
Web UI 更适合手动测试参考音频、文本和参数组合。批量生成或集成到业务系统时,Python API 更方便控制输入输出。
适合什么场景,不适合什么场景
VoxCPM 的优势不是“模型越大越好”,而是用较小模型完成高质量语音克隆,并把推理速度压到比较实用的范围内。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 在线语音 Demo | 适合 | 模型轻量,支持快速生成 |
| 语音助手 | 适合 | RTF 较低,并支持流式输出 |
| 数字人语音 | 适合 | 可以保持指定音色和表达风格 |
| 方言或口音语音合成 | 适合 | 能利用参考音频迁移口音和说话风格 |
| 有声内容样音制作 | 适合 | 便于快速生成不同音色样例 |
| 未授权声音复刻 | 不适合 | 声音属于个人身份特征,需要获得授权 |
| 极长篇幅稳定批量生产 | 需要评估 | 长文本可能带来停顿、节奏和稳定性问题 |
| 纯 CPU 实时推理 | 需要评估 | 0.5B 不等于任意设备都能实时运行 |
语音克隆模型在技术上很有用,但也很容易被误用。参考音频应该来自授权素材,生成结果也要避免冒充他人身份或制造误导性内容。
使用时容易踩的坑
参考音频不要太复杂
参考音频最好满足几个条件:
| 条件 | 建议 |
|---|---|
| 说话人数量 | 只保留一个人 |
| 背景噪声 | 尽量干净 |
| 时长 | 几秒即可,但要包含清晰发音 |
| 音量 | 不要过低或爆音 |
| 内容 | 最好有对应文本,便于传入 prompt_text |
多人同时说话、背景音乐很强、录音设备质量很差,都会影响音色提取。
文本标点会影响停顿
语音合成不是把字连续拼起来。逗号、句号、问号、感叹号都会影响模型对语气和停顿的判断。长句可以适当拆开,避免生成结果节奏混乱。
例如:
不推荐:今天我们介绍一个模型它可以合成语音还能克隆音色并且速度很快适合实时场景
推荐:今天介绍一个语音模型。它可以合成语音,也能克隆音色;在合适硬件上,生成速度足够覆盖实时场景。
RTF 要结合硬件理解
RTF 约 0.17 的结果是在 RTX 4090 上测得。换成低端显卡、CPU 或显存紧张的环境,速度会发生变化。部署前应按自己的目标硬件做一次端到端测试,包括模型加载时间、首包延迟、流式输出延迟和长文本稳定性。
不要只听一条样例就判断效果
语音合成效果会受到文本长度、语言类型、参考音频质量和参数设置影响。评估模型时,最好准备一组测试样本:
1. 短句:测试发音和响应速度
2. 长句:测试停顿和稳定性
3. 中英文混合:测试多语言处理
4. 数字、日期、金额:测试文本规范化
5. 情绪句:测试表达能力
6. 方言或口音参考音频:测试克隆迁移能力
这样更容易发现模型在真实业务里的边界。
小结
VoxCPM 是一个面向实用部署的轻量级文本转语音模型。它用 0.5B 参数规模支持零样本语音克隆,通过 MiniCPM-4 理解文本上下文,在连续空间中进行扩散自回归语音生成,并借助 FSQ 等约束改善特征解耦。
如果只是体验效果,可以直接使用 Hugging Face Spaces;如果要接入自己的应用,安装 voxcpm 后用 Python API 加载 openbmb/VoxCPM-0.5B 即可生成语音。真正部署时,需要重点关注参考音频质量、推理硬件、RTF、长文本稳定性,以及声音授权问题。