RAG(Retrieval-Augmented Generation,检索增强生成)的目标很直接:让大语言模型在回答问题之前,先从外部知识库里找到可靠依据,再基于这些依据生成答案。
但真正落地时,问题不会只来自一类数据。
有的问题需要查文档:
某个政策的适用条件是什么?
有的问题需要查表格:
今年第二季度华南区销售额最高的产品是哪一个?
有的问题需要跨多段材料推理:
A 公司收购 B 公司之后,哪些业务线可能受到影响?
还有的问题需要沿着实体关系链条查找:
某个项目的负责人、所属部门、依赖系统和上线风险之间有什么关系?
如果只做“文本切片 → 向量检索 → 大模型回答”,系统很快会遇到瓶颈。文档检索解决不了精确统计,SQL 查询解决不了语义补充,普通向量召回也不擅长多跳关系推理。工程级 RAG 更像一个多路检索和证据融合系统。
可以把整体架构理解成四层:
- 知识接入层:接入文档、表格文件、数据库表、知识图谱等数据。
- 索引构建层:构建向量索引、全文索引、SQL 表、图索引和摘要索引。
- 检索推理层:根据问题类型选择语义检索、Text2SQL、GraphRAG 或多路组合。
- 生成验证层:把检索结果交给大语言模型进行阅读理解、答案生成和必要的校验。
整体关系可以用下面的架构图表示。
这套结构的关键点不在于“有多少个检索器”,而在于每一种检索器都承担明确职责:语义检索负责从非结构化文本中找相关证据,Text2SQL 负责从结构化数据中拿精确结果,GraphRAG 负责围绕实体、关系和路径做复杂推理。最终,大语言模型不再凭空回答,而是在多种证据之上组织答案。
一个简化后的问答流程可以写成这样:
def answer(query: str):
plan = planner.route(query)
evidences = []
if plan.need_semantic_search:
chunks = vector_retriever.search(query, top_k=100)
chunks = reranker.rank(query, chunks, top_k=10)
evidences.extend(chunks)
if plan.need_structured_query:
sql = text2sql.generate(query, schema=plan.schema)
rows = sql_executor.safe_execute(sql)
evidences.extend(rows)
if plan.need_graph_reasoning:
sub_tasks = graph_query_parser.decompose(query)
paths = graph_retriever.retrieve(sub_tasks)
evidences.extend(paths)
return reader.generate_answer(query=query, evidences=evidences)
这段伪代码反映了 RAG 工程化的核心思想:问题先被规划,证据再被检索,答案最后生成。检索不是单一路径,而是根据问题动态选择工具。
语义检索:用 Embedding 召回,再用 Reranker 精排
语义检索主要处理非结构化文本,例如 PDF、网页、知识库文档、产品说明、客服问答、合同条款等。它通常分成两级:
flowchart LR
Q[用户问题] --> E[Embedding 模型编码]
E --> V[(向量索引)]
V --> C[召回候选文本]
C --> R[Reranker 精排]
R --> T[高相关证据]
T --> LLM[大语言模型生成答案]
Embedding 模型负责“快而广”地召回候选内容,Reranker 模型负责“慢而准”地重新排序。两者缺一不可。
Embedding 模型:把文本映射到可检索的向量空间
Embedding 模型会把问题和文档分别编码成向量,然后通过余弦相似度、点积等方式判断它们是否相关。
典型双编码器结构如下:
flowchart LR
Q[Query] --> QE[Query Encoder]
D[Document] --> DE[Document Encoder]
QE --> QV[Query Vector]
DE --> DV[Document Vector]
QV --> S[计算相似度]
DV --> S
双编码器的优势是速度快。文档向量可以提前离线算好,查询时只需要编码问题,然后在向量数据库里做近似最近邻搜索。它的缺点也很明显:问题和文档在编码阶段彼此独立,模型无法细粒度观察二者之间的交互关系。
所以,Embedding 更适合做召回,而不是最终排序。
多阶段训练:从泛化能力到业务适配逐步增强
Embedding 模型要做好检索,核心训练目标是让“问题”和“相关文档”的向量更近,让“不相关文档”的向量更远。常见做法是对比学习。
训练管线可以分成弱监督训练和有监督训练两个阶段。

这张图展示了 Embedding 模型的多阶段训练过程。弱监督阶段主要扩大数据覆盖面,让模型学习通用语义匹配能力;有监督阶段引入更高质量的正负样本和任务指令,让模型在具体检索任务上更稳定。
弱监督对比学习
弱监督阶段通常使用大规模 (query, positive_document) 文本对。正样本可以来自公开问答数据,也可以由大语言模型根据文档自动生成问题。
为了让模型学会区分相似但不相关的文本,需要大量负样本。工程上常用两种方式扩大负样本数量:
| 负样本方式 | 含义 | 作用 |
|---|---|---|
| Batch 内负样本共享 | 一个 batch 中其他 query 的正样本文档,作为当前 query 的负样本 | 几乎不增加额外计算 |
| 跨设备负样本共享 | 多张 GPU 上的样本互相作为负样本 | 在分布式训练中扩大负样本池 |
当 batch 足够大、设备数量足够多时,一个 query 可以同时面对数万级负样本。负样本越丰富,模型越容易学到清晰的语义边界。
有监督对比学习
有监督阶段更关注“难负样本”。难负样本不是完全无关的文档,而是看起来相关、实际不能回答问题的文档。
例如用户问:
2024 年新能源汽车出口量是多少?
一个只提到“2024 年新能源汽车销量”的文档就可能成为难负样本。它包含相似实体和时间,但指标不同。模型如果能区分这种细微差异,检索质量会明显变好。
有监督阶段还可以加入任务指令,例如:
请检索能够回答该问题的文档:{query}
或者:
请判断两段文本的语义相似度:{sentence_a} / {sentence_b}
指令的作用是告诉模型当前任务是什么。信息检索、语义相似度、问答匹配虽然都在算文本相关性,但评价标准并不完全一样。指令感知训练可以让同一个 Embedding 模型在不同任务中采用不同匹配策略。
数据工程:训练数据比模型结构更容易决定上限
Embedding 训练数据通常经历三个步骤:
flowchart TD
A[收集原始文档] --> B[构造 Query-正样本文本对]
B --> C[构建大规模候选语料库]
C --> D[挖掘难负样本]
D --> E[过滤伪正例和伪负例]
E --> F[形成 Query-正样本-负样本三元组]
F --> G[训练 Embedding 模型]
其中最容易出问题的是负样本质量。
如果负样本太简单,例如完全不相关的广告文本,模型很快就能区分出来,训练信号不够强。如果负样本其实能够回答问题,却被误标为负例,模型会被错误监督拉偏。
为了解决这个问题,可以引入 Reranker 对训练语料进行二次筛选。
这张质量控制图的核心逻辑是用更强的相关性判断模型清洗训练样本。低分正例会被剔除,过于简单的负例会被过滤,强负例中疑似真实相关的文档会被替换或重新标注。这样做的目的不是让数据量最大,而是让每一次参数更新都尽量来自可信样本。
多任务联合训练:IR 和 STS 不能混成一锅粥
Embedding 常见任务主要有两类:
- IR(Information Retrieval,信息检索)
- STS(Semantic Textual Similarity,文本语义相似度)
二者看起来相似,训练目标却有差异。
| 任务 | 典型输入 | 评价重点 | 训练关注点 |
|---|---|---|---|
| IR | query 与候选文档 | 相关文档是否排在前面,常看 nDCG 等指标 | 正样本突出、难负样本区分 |
| STS | 两个句子 | 预测相似度排序是否接近人工标注,常看 Spearman 相关系数 | 细粒度语义差异和排序一致性 |
如果把不同领域、不同任务的数据完全随机混在一起训练,跨设备负样本共享反而会引入噪声。例如医疗问答和法律条款同时出现在一个 batch 中,很多负样本太容易区分,训练价值有限;更糟糕的是,不同任务的评价目标不同,梯度方向可能冲突。
更稳妥的做法是:
- 将数据统一成可混合加载的格式。
- 在一次 iteration 中,让多个 GPU 的样本来自同一个子数据集。
- 为不同任务设置不同 batch size、损失函数和指令模板。
- 训练结束后,对不同训练轨迹的模型做权重融合。
这种设计可以让每个 batch 提供更纯净的任务梯度,同时利用多任务数据提高泛化能力。
任务定制损失:让训练目标贴近评价指标
损失函数不能只追求“正样本比负样本分数高”。不同任务对排序的要求不同。
对于 STS,核心是顺序一致性。模型需要知道句子 A 和 B 的相似度不仅要高于 A 和 C,还要尽可能符合人工标注的细粒度排序。因此可以引入顺序性损失,让模型关注逆序对、分数差距和排序稳定性。
对于 IR,关键是把少量真正相关的文档推到前排。大多数候选文档都不相关,所以训练时需要大量负样本,并尽量拉大 query 与正样本之间的相似度差距。
可以把两类任务的训练目标概括为:
STS:更关注“排序是否一致”
IR :更关注“相关文档是否靠前”
这也是为什么同一个 Embedding 模型要同时处理榜单测试和业务检索时,数据采样、指令设计和损失函数都需要精细配置。
Reranker:用更强的交互建模做最终排序
Embedding 模型的双编码器结构适合大规模召回,但它无法在编码阶段直接比较 query 和 document 的细节。Reranker 通常采用交叉编码方式,把 query 和 document 放在一起输入模型,让模型输出相关性分数。
| 模型 | 输入方式 | 优点 | 缺点 | 适合位置 |
|---|---|---|---|---|
| Embedding 双编码器 | query 和 document 分开编码 | 快,可离线建索引 | 交互建模弱 | 第一阶段召回 |
| Reranker 交叉编码器 | query 和 document 一起输入 | 排序更准,可理解细节 | 计算成本高 | 第二阶段精排 |
检索链路通常是:
sequenceDiagram
participant U as 用户
participant E as Embedding召回
participant R as Reranker精排
participant L as 大语言模型
U->>E: 输入问题
E-->>R: 返回Top 100候选文档
R-->>L: 返回Top 5~10高相关证据
L-->>U: 基于证据生成答案
为什么 Reranker 要升级到大语言模型
传统 Reranker 常基于 BERT、RoBERTa 等模型训练,参数量通常在 110M 到 400M 之间,输入长度多为 512 token。对于短文本排序,这类模型已经够用;但在复杂业务场景中,文档可能很长,问题也可能包含多条件、多实体和上下文约束。
LLM(Large Language Model,大语言模型)型 Reranker 的优势主要有三点:
- 输入长度更长:可以支持 8k 甚至更长上下文。
- 复杂语义理解更强:能处理多条件、多跳和隐含约束。
- 可以通过指令适配任务:不同业务可以使用不同排序标准。
例如同样是“相关”,客服场景可能更关注能否直接解决用户问题,金融风控场景可能更关注证据是否包含时间、金额、主体等关键实体。指令化 Reranker 可以把这些差异显式写入输入。
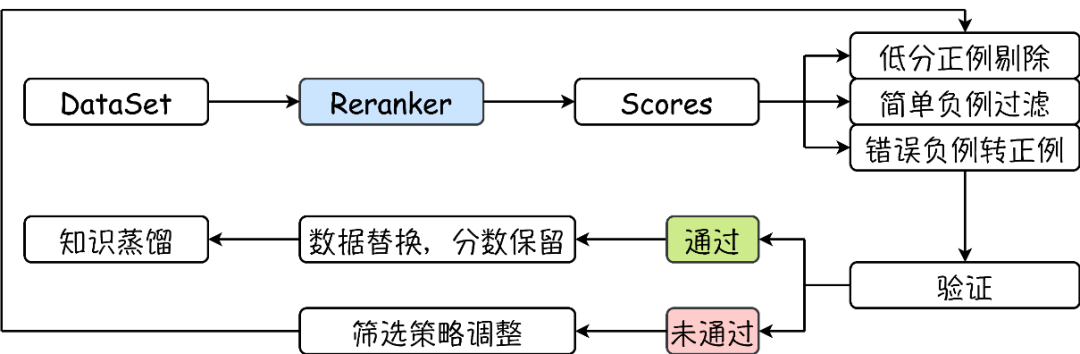
分层知识蒸馏:让不同层都能输出相关性分数
知识蒸馏的基本思路是:用更强的教师模型给 query-document 对打分,再训练较小的学生模型去拟合教师分数。这样可以在保留效果的同时降低推理成本。
分层知识蒸馏进一步把监督信号加到 Transformer 的多个中间层,而不只约束最后一层。
这张图展示了分层蒸馏的训练方式。教师模型或最终层输出提供相关性监督,中间层也被要求给出一致的相似度判断。训练完成后,模型可以在不同层提前输出分数。
这种能力很适合工程部署,因为它提供了一个可调旋钮:
| 输出层位置 | 推理速度 | 排序质量 | 适合场景 |
|---|---|---|---|
| 较浅层 | 快 | 较弱 | 高并发、低延迟 |
| 中间层 | 中等 | 中等 | 默认在线服务 |
| 较深层 | 慢 | 更强 | 高价值问题、离线评测 |
如果训练数据没有教师模型分数,也可以用模型最后一层的输出作为软标签,约束中间层向最终层靠近。这种方式虽然没有外部教师强,但依然能让模型具备层级输出能力。
业务 Reranker 数据:先实体粗筛,再精细打分
领域业务通常缺少高质量 Reranker 训练数据。直接让大语言模型给所有候选文档打相关性分数,成本高,还容易因为幻觉给出不合理分数。
更稳的流程是先做实体召回粗筛,再做文档精评分。
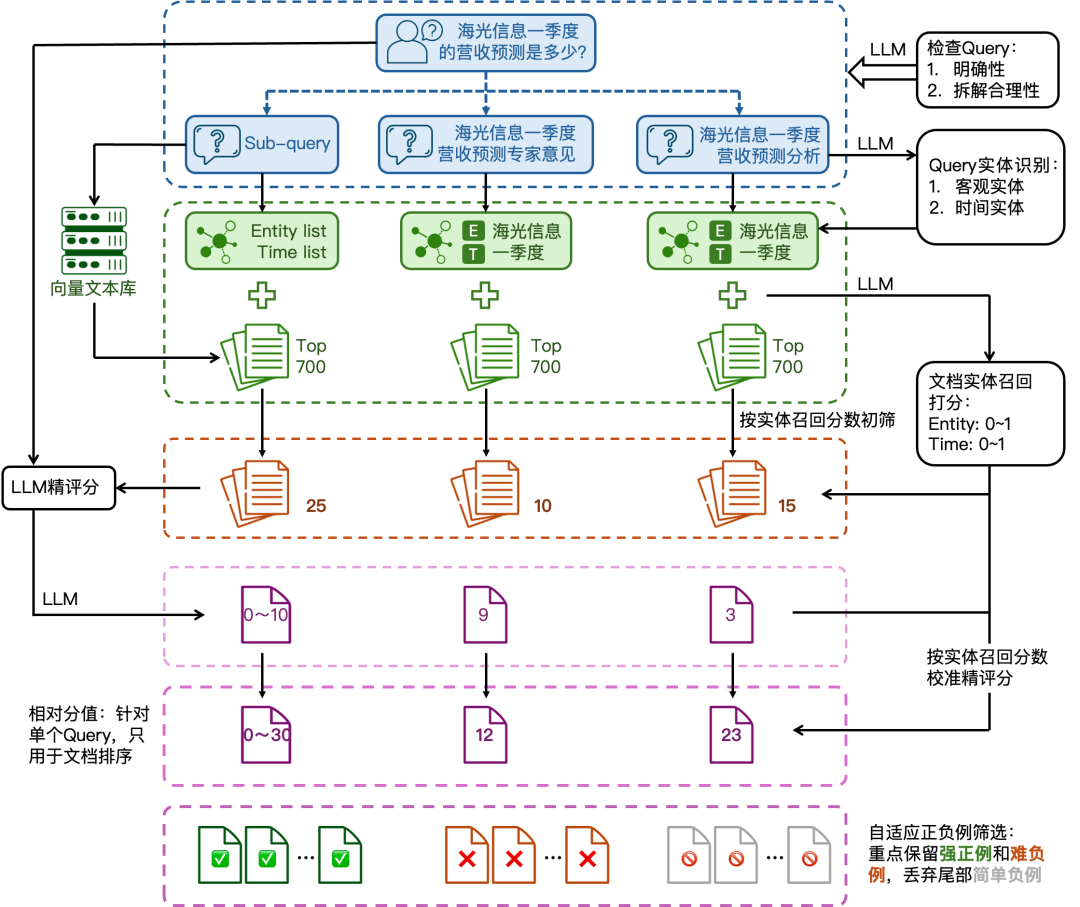
这张流程图对应的是一套自动化数据构造方案。它先识别 query 中的关键实体和时间实体,再判断候选文档是否包含这些实体。实体完全不匹配的文档可以直接作为简单负例或被过滤,剩下的候选文档再交给大语言模型做精细相关性评分。
流程可以拆成七步:
- Query 预处理:复杂问题可拆成子问题,并去除无效 query。
- 实体识别:抽取客观实体、时间实体和关键条件。
- 实体召回判断:检查候选文档是否覆盖 query 中的实体。
- 文档初筛:实体召回分数为 0 的文档不进入精评分。
- LLM 精评分:对剩余文档进行相关性打分。
- 分数校准:用实体召回结果修正大语言模型的异常评分。
- 自适应正负例采样:根据单个 query 的分数分布选择正例和难负例。
这里的关键是“校准”。如果问题问的是某个 2024 年事件,文档只讲 2023 年同名事件,大语言模型可能因为主题相近给高分;实体和时间校准可以把这类样本压下来。
结构化信息检索:RAG 与 Text2SQL 融合
结构化数据有固定字段和明确语义,例如数据库表、Excel 表、CSV 文件。它适合精确查询、过滤、聚合和计算。
非结构化文本适合解释背景和语义补充。两类数据的能力边界不同:
| 数据类型 | 例子 | 适合回答的问题 | 常用技术 |
|---|---|---|---|
| 非结构化文本 | 文档、网页、说明书 | 原因、规则、解释、流程 | 向量检索、全文检索、Reranker |
| 结构化数据 | 数据库表、Excel 表 | 数量、排名、统计、筛选 | Text2SQL、SQL 执行、表格解析 |
| 图结构数据 | 实体关系图、知识图谱 | 多跳关系、路径推理、社区分析 | GraphRAG、图检索 |
Text2SQL 的任务是把自然语言问题转换成 SQL。例如:
问题:2024 年华东区销售额最高的产品是什么?
SQL:
SELECT product_name, SUM(sales_amount) AS total_sales
FROM sales
WHERE region = '华东'
AND year = 2024
GROUP BY product_name
ORDER BY total_sales DESC
LIMIT 1;
但只返回 SQL 结果通常不够友好。更完整的方案是把 SQL 查询结果和文本切片一起交给阅读理解模型,让它生成自然语言答案。
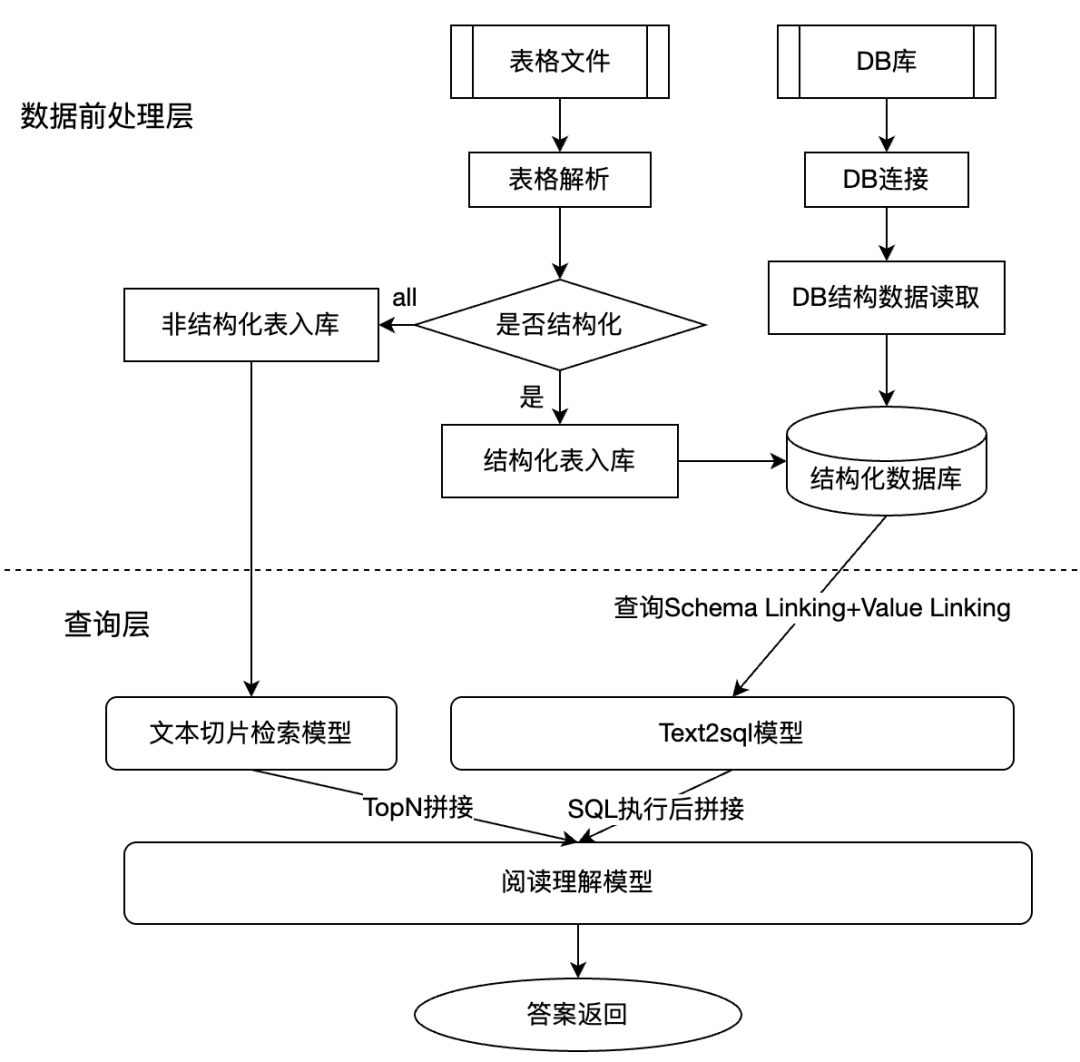
这张图展示了结构化数据和文本 RAG 的融合方式。表格或数据库通过 Text2SQL 得到精确查询结果,文档切片通过语义检索提供上下文解释,阅读理解模型综合两类证据后生成回答。
Text2SQL 数据合成:用自动化方式适配新业务
Text2SQL 落地的主要难点是训练数据。每个业务都有自己的表结构、字段命名、数据库方言和查询习惯,人工标注大量 (问题, SQL) 数据成本很高。
自动化数据合成可以缓解这个问题。合成数据通常包含四类信息:
- 数据库表结构。
- 自然语言问题。
- SQL 查询。
- SQL 生成的推理过程。
比如给定一张销售表:
CREATE TABLE sales (
id BIGINT,
product_name VARCHAR(128),
region VARCHAR(64),
sales_amount DECIMAL(18, 2),
sale_date DATE
);
可以自动生成训练样本:
{
"question": "2024年华南区销售额排名前三的产品有哪些?",
"reasoning": "需要筛选 sale_date 在 2024 年、region 为华南的数据,按 product_name 分组并计算 sales_amount 总和,再降序取前三。",
"sql": "SELECT product_name, SUM(sales_amount) AS total_sales FROM sales WHERE region = '华南' AND sale_date >= '2024-01-01' AND sale_date < '2025-01-01' GROUP BY product_name ORDER BY total_sales DESC LIMIT 3;"
}
合成数据的价值不只是增加样本量,还能让模型提前见到多样化 schema、查询模式和数据库方言。新业务接入时,模型不需要从零学习“字段如何组合成查询逻辑”。
Multi-Agent Text2SQL:让不同智能体负责不同环节
复杂 Text2SQL 不能只靠一次生成。一个问题可能涉及多张表、多层过滤、嵌套查询和执行错误。把任务拆给多个 Agent 更容易控制。
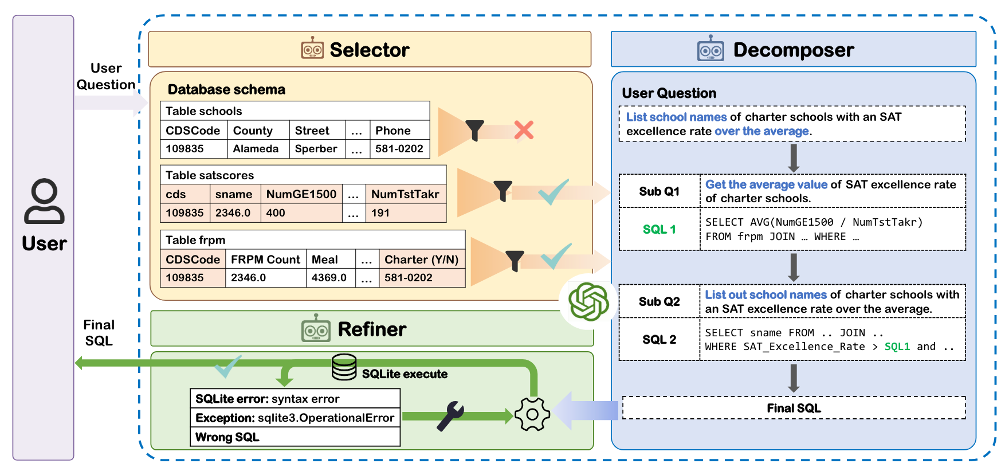
这张架构图展示了 Multi-Agent Collaborative Text-to-SQL 的核心思路:Selector 负责选表选列,Decomposer 负责拆解复杂问题,Refiner 负责执行 SQL 并根据错误反馈修正。
三个 Agent 的职责可以这样理解:
| Agent | 职责 | 解决的问题 |
|---|---|---|
| Selector | 从大量表和字段中选出相关 schema | 减少无关表干扰,降低上下文长度 |
| Decomposer | 把复杂问题拆成多个子问题 | 降低一次生成复杂 SQL 的难度 |
| Refiner | 执行 SQL,读取报错或空结果,修正 SQL | 处理语法错误、字段错误、条件不匹配 |
一个典型流程如下:
flowchart TD
Q[自然语言问题] --> S[Selector: 选择相关表和字段]
S --> D[Decomposer: 拆分复杂查询]
D --> G[生成SQL]
G --> E[执行SQL]
E -->|成功| A[返回查询结果]
E -->|失败或结果异常| R[Refiner: 根据反馈修正]
R --> G
这种架构比“让大模型直接写 SQL”更可控,因为每个环节都有明确输入输出,也更容易加规则、日志和评测。
表格文件场景:先把非标准表格变成可查询结构
Text2SQL 默认面对的是标准二维表,但真实 Excel 或文档表格往往并不标准:
- 多级表头。
- 合并单元格。
- 嵌套表格。
- 单元格中包含说明性文字。
- 表头和内容错位。
- 表格周围混有标题、备注和脚注。
如果直接把这类表送给 Text2SQL,模型很难正确理解字段含义。工程上需要先做结构化解析。
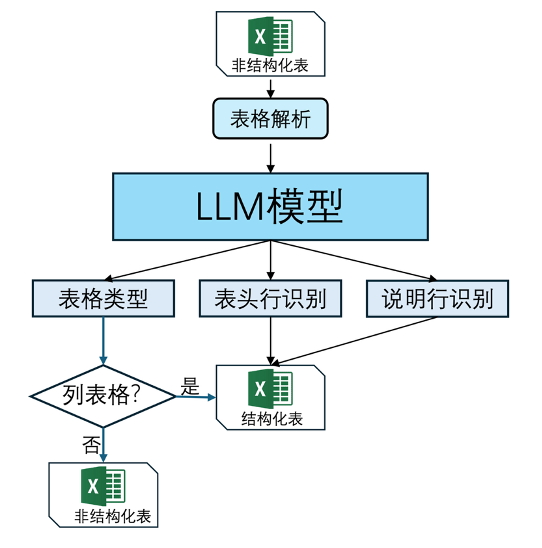
这张流程图展示了非标准表格到标准结构化表的转换过程。系统会先判断表格是否属于可结构化的知识表格,再识别表头,最后把原始表格元素整合成 Text2SQL 可查询的表结构。
可以把解析分成三层:
flowchart TD
A[原始表格文件] --> B[判断是否为知识表格]
B --> C[识别标题、表头、层级关系]
C --> D[处理合并单元格和嵌套结构]
D --> E[生成标准二维表]
E --> F[写入MySQL / Elasticsearch]
解析后的表格既可以进入 SQL 引擎,也可以切成语义片段进入文本检索。
表格语义窗口切分
表格切片不能简单按固定行数切。因为单独一行可能没有语义,必须带上表头和必要上下文。
例如原表:
| 地区 | 产品 | 2023销售额 | 2024销售额 |
|---|---|---|---|
| 华东 | A | 100 | 130 |
适合构造成这样的语义片段:
地区=华东;产品=A;2023销售额=100;2024销售额=130。
如果表头是多级结构,还需要把上级表头展开:
地区=华东;产品=A;销售额.2023=100;销售额.2024=130。
窗口大小可以按业务调整。小窗口适合精确匹配,大窗口适合保留上下文;如果问题经常跨多行比较,就需要更大的窗口或额外构建聚合索引。
双引擎 SQL 查询:MySQL 管精确,Elasticsearch 管泛化
MySQL 擅长精确过滤、聚合和排序,但不擅长模糊文本匹配。Elasticsearch(ES,分布式搜索与分析引擎)擅长全文检索、分词匹配和近似召回,但不适合承担所有关系型计算。
双引擎架构可以把二者结合起来:
flowchart LR
Q[自然语言问题] --> T[Text2SQL生成SQL]
T --> A[AST解析与校验]
A --> C{查询类型}
C -->|精确过滤/聚合| M[(MySQL)]
C -->|模糊匹配/文本召回| E[(Elasticsearch)]
M --> R[查询结果]
E --> R
R --> L[阅读理解模型]
AST(Abstract Syntax Tree,抽象语法树)是 SQL 语法结构的树状表示。把 SQL 转成 AST 后,可以做三件事:
- 语法校验:检查 SQL 是否合法。
- 自动修正:修复部分字段名、操作符或方言问题。
- 方言转换:把 SQL AST 转换成 ES DSL 查询。
例如用户问:
售卖模式为“一次性售卖与租赁模式”的商品有哪些?
数据库里可能没有完全等于“一次性售卖与租赁模式”的值,只存了“一次性售卖模式”和“租赁模式”。如果直接执行 MySQL 精确匹配:
WHERE sale_mode = '一次性售卖与租赁模式'
结果可能为空。ES 可以把条件拆成更宽松的文本匹配,从而召回相近字段值。召回后再结合阅读理解模型和业务规则做判断,比直接返回空结果更合理。
双引擎并不是让 ES 替代数据库
需要精确计算时,仍然应该走 MySQL:
SELECT region, SUM(amount)
FROM sales
WHERE sale_date >= '2024-01-01'
GROUP BY region;
需要模糊匹配字段值时,可以走 ES:
{
"query": {
"match": {
"sale_mode": "一次性售卖 租赁"
}
}
}
更稳的策略是:SQL 负责结构化计算,ES 负责值匹配和文本泛化。如果 ES 找到了候选值,可以把候选值回填到 SQL 条件中,再由 MySQL 做最终计算。
通用数据库场景:Schema Linking 和 Value Linking 很关键
Text2SQL 的输入不只是用户问题,还必须包含数据库 schema。schema 信息给得太少,模型不知道哪些表和字段可用;给得太多,上下文变长,干扰也会增加。
常见 schema 提示有两种形式:
| 提示方式 | 内容 | 优点 | 缺点 |
|---|---|---|---|
| DDL | 表名、字段名、字段类型、主键、外键、约束 | 信息完整,适合复杂查询 | 输入长,推理慢 |
| SimpleDDL | 只给表名和字段名 | 输入短,速度快 | 缺少类型和关系信息 |
例如 DDL:
CREATE TABLE students (
student_id BIGINT PRIMARY KEY,
name VARCHAR(64),
age INT
);
CREATE TABLE courses (
course_id BIGINT PRIMARY KEY,
course_name VARCHAR(128)
);
SimpleDDL 可以压缩成:
students(student_id, name, age)
courses(course_id, course_name)
生产系统通常不会把全库 schema 全量塞给模型,而是先做 schema linking。
Schema Linking:把问题映射到表和字段
Schema Linking 负责判断问题中的词和数据库字段之间的关系。
问题:年龄大于20岁的学生有哪些?
映射:
“学生” -> students 表
“年龄” -> students.age 字段
“大于20” -> age > 20
如果问题涉及“课程名称”“选课记录”等信息,还需要进一步找到课程表和选课关系表。
Value Linking:把问题中的值映射到数据库真实取值
Value Linking 负责处理 where 条件中的具体值。它比字段映射更容易出错,因为用户表达和数据库存储经常不一致。
| 用户表达 | 数据库存储可能是 | 需要处理的问题 |
|---|---|---|
| 上个月 | 2024-05-01 至 2024-05-31 | 相对时间解析 |
| CS | Computer Science | 缩写展开 |
| 张伟 | 张伟 / Zhang Wei | 多语言或别名匹配 |
| 华南地区 | 华南 / South China | 同义词映射 |
没有 Value Linking,Text2SQL 很容易生成语法正确但结果为空的 SQL。
多轮查询:用改写信号解决上下文依赖
用户不会总是一次把问题说完整。多轮查询中经常出现省略和指代:
用户:2024年华东区销售额最高的产品是什么?
系统:A产品。
用户:那华南呢?
第二个问题“那华南呢?”依赖上一轮上下文。直接做 Text2SQL 会缺少年份、指标和排序条件。
常见处理方式是问题改写:
改写后:2024年华南区销售额最高的产品是什么?
对于更复杂的多轮交互,可以把改写信号表示成编辑操作,例如插入、替换、删除,再与表格-文本链接关系一起融合到模型注意力中。这样模型不仅知道当前问题是什么,还知道它相对历史问题改了哪里。
问答推理与润色:把 SQL 结果变成人能读懂的答案
Text2SQL 返回的是结构化结果,直接给用户通常不够自然。例如 SQL 执行结果是:
| product_name | total_sales |
|---|---|
| A产品 | 1300000 |
阅读理解模型需要把它组织成:
2024 年华东区销售额最高的产品是 A 产品,销售额为 130 万。
如果同时检索到了文本切片:
A 产品在 2024 年第二季度进行了渠道扩展,华东区新增 38 家经销商。
答案可以补充解释:
2024 年华东区销售额最高的产品是 A 产品,销售额为 130 万。相关业务材料显示,A 产品在第二季度进行了渠道扩展,这可能是销售额增长的重要背景。
这里要注意边界:SQL 结果是事实,文本切片是解释依据。模型不能把“可能背景”写成确定因果,除非证据明确说明了因果关系。
GraphRAG:用图结构处理多跳关系和复杂推理
普通向量 RAG 把文档切成 chunk,再按语义相似度召回。它适合局部语义匹配,但不擅长关系推理。
例如问题:
A 公司的创始人投资了哪些和新能源相关的企业?
这个问题至少包含几层关系:
flowchart LR
A[A公司] --> B[创始人]
B --> C[投资企业]
C --> D[行业标签: 新能源]
如果相关信息分散在多篇文档里,普通向量检索可能只召回其中一段,无法拼出完整链路。GraphRAG 的思路是先把文本中的实体、关系、属性和摘要组织成图,再围绕图结构检索和推理。
GraphRAG 常见方案对比
GraphRAG 大体可以分成两类:
| 方案 | 代表思路 | 优点 | 问题 |
|---|---|---|---|
| 知识图谱型 | 抽取实体、关系、三元组 | 细粒度关系清晰,适合路径推理 | 构图成本高,抽取质量影响大 |
| 树状摘要型 | 对文本切片分层聚类和总结 | 适合全局摘要,检索效率较高 | 细粒度实体关系不足,依赖大模型总结 |
更适合落地的方案需要同时保留两者优点:既有图的关系推理能力,又有树的层次化摘要能力。
Knowledge Tree:把实体、属性、关键词和社区组织到一张异构图里
一种可行设计是构建“知识树”式异构图。它不是单一实体图,也不是单纯摘要树,而是把多种知识粒度放在同一个结构中。
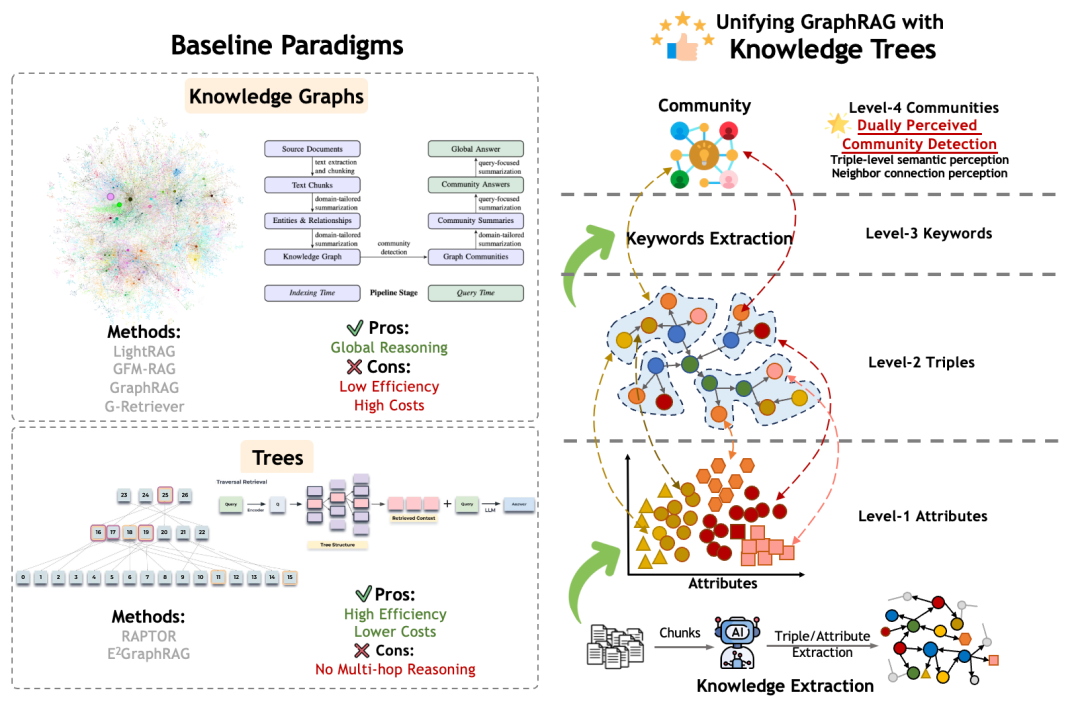
这张图展示了 Knowledge Tree 与传统图方案、树方案的差异。它将属性、三元组、关键词和社区摘要组织成多级结构,既保留细粒度关系,也保留高层摘要。
可以把节点类型分成四类:
| 节点类型 | 表示内容 | 作用 |
|---|---|---|
| 实体节点 | 人、组织、地点、产品、事件等 | 支撑关系检索和路径推理 |
| 关系节点 | 实体之间的关系 | 表达三元组结构 |
| 属性节点 | 实体的特征、时间、数值、状态 | 支撑条件过滤 |
| 社区节点 | 一组相关实体和关系的摘要 | 支撑全局理解和主题召回 |
一个简化的知识树结构可以表示为:
flowchart TD
C[社区: 新能源业务] --> K1[关键词: 电池]
C --> K2[关键词: 充电网络]
K1 --> E1[实体: A公司]
K1 --> E2[实体: B电池厂]
E1 --> R1[关系: 投资]
R1 --> E2
E2 --> P1[属性: 产能=20GWh]
这种结构的好处是查询时可以从不同粒度切入。问题比较宽泛时,可以先匹配社区摘要;问题包含明确实体时,可以直接进入实体和关系路径;问题带条件时,可以用属性节点过滤。
社区检测:同时看拓扑结构和语义相似度
图构建完成后,需要把相近节点聚成社区。传统社区检测算法常依赖连接关系,例如节点之间边越密,就越可能属于同一社区。
但知识图谱来自文本抽取,边本身可能不完整。如果只按连接关系划分,容易受抽取质量影响。另一方面,大规模图上反复遍历节点并计算社区质量函数,成本也比较高。
一种改进思路是同时利用结构和语义,也就是 S2Dual-perception。
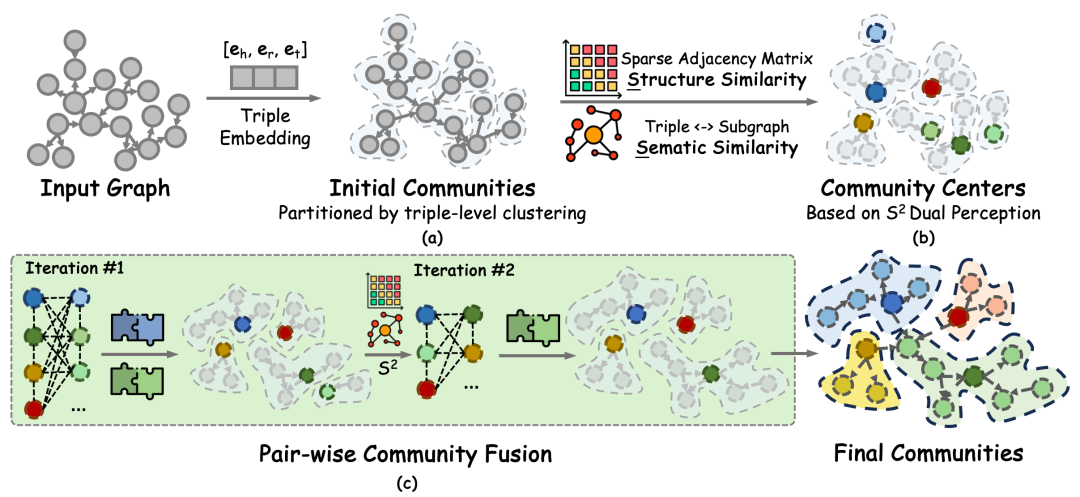
这张图展示了双感知社区检测的核心思想:一边用稀疏邻接矩阵计算结构重合度,一边编码子图语义信息计算文本相似度。社区划分不再只依赖边连接,也会考虑节点和候选社区在语义上是否接近。
结构相似度可以用 Jaccard 表示:
Jaccard(A, B) = |N(A) ∩ N(B)| / |N(A) ∪ N(B)|
其中 N(A) 表示节点 A 的邻居集合。这个指标衡量的是锚节点和候选社区之间的邻居重合程度。
语义相似度可以通过向量计算:
semantic_score = cosine(embedding(anchor_node), embedding(candidate_community))
最终社区归属可以组合两个分数:
score = alpha * structure_score + (1 - alpha) * semantic_score
alpha 控制结构和语义的权重。领域图谱边质量高时,可以加大结构权重;文本抽取噪声较多时,可以加大语义权重。
自适应图 Schema:让不同领域有不同抽取约束
图谱抽取不能只靠通用提示词。不同领域的实体、关系和属性差异很大。
| 领域 | 典型实体 | 典型关系 | 典型属性 |
|---|---|---|---|
| 人物 | 人、组织、作品 | 任职、创作、合作 | 出生时间、职位 |
| 事件 | 事件、地点、参与方 | 发生于、导致、影响 | 时间、规模、结果 |
| 概念 | 技术、产品、指标 | 包含、依赖、对比 | 参数、版本、适用范围 |
自适应图 Schema 的做法是先提供领域候选 schema,再让大语言模型根据文本内容补充或调整实体类型、关系类型和属性类型。这样可以减少人工配置,同时避免完全开放抽取带来的混乱。
一个图谱抽取提示可以写成:
你需要从文本中抽取知识图谱。
允许的实体类型:公司、产品、技术、事件、人物。
允许的关系类型:发布、投资、合作、依赖、影响。
允许的属性类型:时间、地点、金额、版本、指标。
请输出:
1. 实体列表
2. 关系三元组
3. 实体属性
schema 越清晰,抽取结果越稳定;schema 太窄,又会漏掉新类型。因此更好的方式是“预置 schema + 自动补充 + 人工审核关键类型”。
AgenticGraphQ:用图 Schema 拆解复杂问题
复杂 query 往往不是单跳问题。直接拿完整问题做向量检索,模型可能只匹配到表面相似文本,无法理解真正的实体、关系和属性约束。
GraphRAG 可以把图 schema 用到 query 理解阶段,而不只是构图阶段。
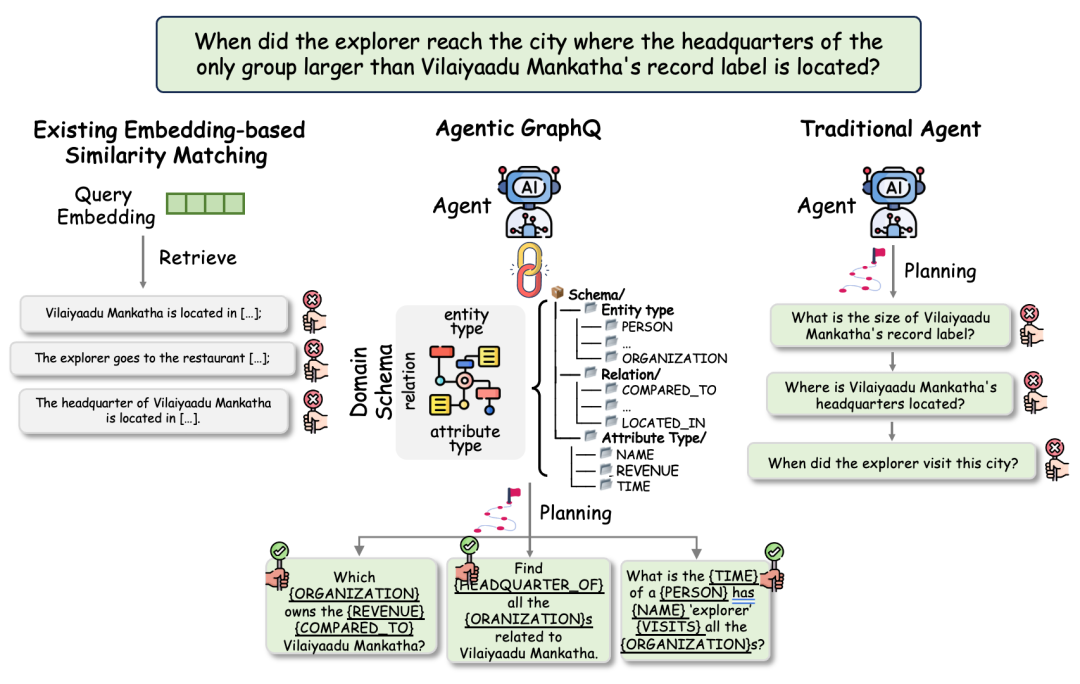
这张图展示了 schema 感知的问题拆解方式。系统会识别 query 中的实体、关系和属性,并把多跳问题拆成多个单跳子任务,再分别进行图检索和结果合并。
例如问题:
A 公司创始人参与投资的新能源企业中,哪一家在 2024 年完成了 B 轮融资?
可以拆成:
子任务1:找到 A 公司的创始人。
子任务2:找到该创始人参与投资的企业。
子任务3:筛选行业为新能源的企业。
子任务4:筛选 2024 年完成 B 轮融资的企业。
对应图查询路径:
flowchart LR
A[A公司] -->|创始人| P[人物]
P -->|投资| C[企业]
C -->|行业| N[新能源]
C -->|融资事件| F[2024年B轮融资]
这种拆解有两个好处:
- 多跳问题变成多个单跳子任务,检索难度降低。
- 子任务可以被检查和修正,推理链更透明。
GraphRAG 多路检索
GraphRAG 查询通常不会只用一种检索方式。更可靠的组合包括:
| 检索方式 | 作用 |
|---|---|
| 关键词检索 | 快速定位主题词和显式实体 |
| Query-Triple 向量匹配 | 用三元组结构匹配关系语义 |
| 路径 DFS 检索 | 沿图结构查找多跳邻居 |
| 社区摘要检索 | 获取全局背景和主题解释 |
其中 Query-Triple 比 Query-Node 更适合关系查询。因为很多问题问的不是“某个实体是什么”,而是“实体之间有什么关系”。把 query 编码成三元组形式,可以同时利用结构和语义。
例如:
Query-Triple:
(创始人, 投资, 新能源企业)
比单纯匹配“创始人”“投资”“新能源企业”三个节点更接近问题意图。
GraphRAG 评测:不要只看回答是否流畅
GraphRAG 系统需要从四个维度评估:
| 维度 | 关注点 | 为什么重要 |
|---|---|---|
| 构图成本 | 离线抽取、总结、建图所需时间和 token | 决定能否处理大规模知识库 |
| 检索效率 | 单次 query 的图检索耗时 | 决定在线服务延迟 |
| 回答准确率 | 答案是否正确 | 决定可用性 |
| 推理能力 | 理由链是否正确 | 决定复杂问题可信度 |
有些方案回答看起来很完整,但证据链是错的;有些方案准确率不错,但每次查询要十几秒甚至更久,在线业务难以接受。GraphRAG 的工程评测必须同时覆盖效果、成本和延迟。
构图成本尤其容易被低估。基于大语言模型抽取实体、关系、社区摘要时,token 消耗可能非常高。生产环境需要重点优化:
- 增量构图,而不是每次全量重建。
- 对低价值文档跳过深度抽取。
- 对实体和关系抽取结果缓存。
- 对社区摘要做局部更新。
- 用小模型承担可规则化的抽取任务。
多路 RAG 系统如何组合
语义检索、Text2SQL 和 GraphRAG 不是互相替代关系,而是分别解决不同问题。
| 问题类型 | 推荐路径 |
|---|---|
| 查制度、说明、FAQ | Embedding 召回 + Reranker 精排 |
| 查统计、排名、聚合 | Text2SQL + SQL 执行 |
| 查字段值但表达模糊 | Text2SQL + ES 值匹配 |
| 查跨实体关系 | GraphRAG |
| 查复杂问题且需要解释 | 多路检索 + 阅读理解模型 |
| 多轮追问 | 上下文改写 + 对应检索路径 |
一个更完整的路由流程可以设计成:
flowchart TD
Q[用户问题] --> P[问题规划器]
P --> C1{是否需要精确计算}
P --> C2{是否需要文档证据}
P --> C3{是否需要多跳关系}
C1 -->|是| SQL[Text2SQL]
C2 -->|是| SEM[语义检索]
C3 -->|是| G[GraphRAG]
SQL --> F[证据融合]
SEM --> F
G --> F
F --> V[证据校验]
V --> A[生成答案]
这里的问题规划器可以是规则模型,也可以是大语言模型。早期系统可以用规则起步,例如:
def route(query: str):
plan = {
"need_sql": False,
"need_semantic": True,
"need_graph": False,
}
sql_keywords = ["多少", "排名", "平均", "总和", "最大", "最小", "同比", "环比"]
graph_keywords = ["关系", "影响", "依赖", "路径", "关联", "由谁", "投资", "上下游"]
if any(word in query for word in sql_keywords):
plan["need_sql"] = True
if any(word in query for word in graph_keywords):
plan["need_graph"] = True
return plan
规则不够时,再引入大语言模型做意图识别和任务拆解。
工程落地时最容易踩的坑
1. 文档切片只按长度切,导致语义断裂
固定每 500 字切一段很简单,但容易把定义、条件和结论切开。更稳的切片方式应该结合标题、段落、表格、列表和语义边界。
不推荐:每 500 字切一次
推荐:按章节、段落、表格行组、标题层级切分,再控制最大长度
2. 负样本质量差,Embedding 看起来训练了,检索仍然不准
简单负样本太多会让模型学不到细粒度区分能力。业务检索必须构建难负样本,并用 Reranker 或规则过滤伪负例。
3. Reranker 排序准,但吞吐量扛不住
Reranker 计算成本高,不能把几千个候选都丢进去排。常见做法是:
向量召回 Top 200 -> 轻量过滤 Top 100 -> Reranker Top 10 -> LLM 生成
如果延迟仍然高,可以用分层蒸馏模型的中间层输出做早退。
4. Text2SQL 只检查语法,不检查结果合理性
SQL 可以语法正确但结果为空,也可能字段匹配错了。执行后需要检查:
- 是否返回空结果。
- 是否返回异常多的数据。
- 聚合字段是否符合问题。
- where 条件值是否真实存在。
- 时间范围是否被正确解析。
5. ES 模糊匹配召回太宽,答案变得不可信
ES 能解决值匹配不准的问题,但召回过宽会引入噪声。更稳的方式是让 ES 返回候选值,再回填 SQL 做精确计算,而不是直接把所有 ES 命中文档交给模型。
6. GraphRAG 构图成本失控
GraphRAG 不适合对所有数据无差别深度抽取。可以按文档价值分层:
| 数据层级 | 处理方式 |
|---|---|
| 高频核心知识 | 深度抽取实体、关系、属性、社区 |
| 普通文档 | 抽取实体和摘要 |
| 低价值或临时文档 | 只做向量索引 |
| 过期文档 | 降权或归档 |
7. 只评估答案,不评估证据链
RAG 系统要同时评估答案和证据。一个答案如果正确但引用证据错误,在高风险场景中仍然不可接受。
评测样本可以包含:
{
"question": "A公司2024年新增的合作伙伴有哪些?",
"expected_answer": ["B公司", "C公司"],
"required_evidence": [
"合同公告第3段",
"合作新闻第2段"
],
"question_type": "multi-hop"
}
一套可落地的 RAG 配置参考
不同业务可以从轻量方案开始,再逐步引入复杂能力。
retrieval:
semantic:
enabled: true
embedding_model: apd-embedding-2b-like
top_k: 100
rerank_top_k: 10
structured:
enabled: true
text2sql:
schema_prompt: simpleddl
enable_schema_linking: true
enable_value_linking: true
safe_sql_only: true
engines:
mysql: true
elasticsearch: true
graph:
enabled: true
schema_adaptive: true
community_detection: structure_semantic
max_hops: 3
generation:
require_evidence: true
cite_sources: true
allow_uncertain_answer: true
轻量知识库问答可以只启用 semantic。如果有大量表格和数据库,再启用 structured。当问题涉及实体网络、跨文档推理和多跳路径时,再建设 graph。
RAG 的演进方向:从检索链路走向闭环智能系统
早期 RAG 是线性的:
检索 -> 生成
工程级 RAG 更接近闭环:
规划 -> 决策 -> 检索 -> 验证 -> 推理 -> 生成
其中规划负责判断问题该走哪条路径,决策负责选择工具,检索负责拿证据,验证负责检查证据是否支持答案,推理负责组织多步逻辑,生成负责输出自然语言结果。
语义检索、Text2SQL 和 GraphRAG 代表了三类关键能力:
- 语义检索解决非结构化知识定位。
- Text2SQL解决结构化数据精确查询。
- GraphRAG解决实体关系和复杂推理。
真正可用的 RAG 系统不是把所有知识都塞进向量库,而是让不同知识形态进入合适的索引和推理链路。只有这样,大语言模型才能从“会说”变成“有依据地回答”。