RAG(Retrieval-Augmented Generation,检索增强生成)的目标很直接:让大语言模型在回答问题前,先从外部知识库里找到可靠信息,再基于这些信息生成答案。这样可以缓解模型知识过期、幻觉、无法访问企业私有数据等问题。
但真正落地时,RAG 远不只是“向量库 + 大模型”。企业数据通常混在多种形态里:
- 文档、网页、制度、说明书这类非结构化文本;
- Excel、CSV、数据库表这类结构化数据;
- 需要多跳推理的实体关系数据,比如人物、事件、产品、地区、时间之间的关联;
- 业务问题本身还可能包含模糊表达、省略上下文、多轮追问和复杂条件。
所以,一个完整的 RAG 系统通常需要三类检索能力一起工作:
flowchart LR
Q[用户问题] --> U[问题理解与改写]
U --> S1[语义检索]
U --> S2[结构化检索 / Text2SQL]
U --> S3[GraphRAG 图检索]
S1 --> E[Embedding 粗召回]
E --> R[Reranker 重排序]
S2 --> SQL[生成 SQL]
SQL --> DB[(数据库 / 表格引擎)]
S3 --> G[(知识图谱 / 知识树)]
G --> GR[路径检索与多跳推理]
R --> C[证据融合]
DB --> C
GR --> C
C --> LLM[阅读理解与答案生成]
LLM --> A[最终回答]
从工程角度看,这套系统可以拆成四个核心层次:
- Embedding 召回层:把问题和文档编码成向量,快速从海量文本里找出候选片段。
- Reranker 精排层:对候选片段逐一判断相关性,把真正有用的证据排到前面。
- Text2SQL 结构化查询层:把自然语言问题转换成 SQL,从表格或数据库里拿到精确结果。
- GraphRAG 图推理层:把知识组织成图或树,用实体、关系、属性和路径完成复杂推理。
完整架构可以用下面这张图辅助理解:
这张架构图的关键点在于:语义检索、结构化检索和图检索不是互相替代的关系,而是分别覆盖不同类型的问题。普通事实问答适合走向量召回;涉及统计、筛选、聚合的问题适合走 Text2SQL;涉及多实体、多关系、多跳推理的问题更适合走 GraphRAG。
1. 语义检索:用 Embedding 召回,再用 Reranker 精排
语义检索的典型流程是两阶段:
sequenceDiagram
participant User as 用户
participant Emb as Embedding模型
participant Vec as 向量库
participant Rank as Reranker模型
participant LLM as 大语言模型
User->>Emb: 输入问题
Emb->>Vec: 生成查询向量并检索TopK
Vec-->>Emb: 返回候选文档
Emb->>Rank: 问题 + 候选文档
Rank-->>Emb: 相关性分数与排序
Emb->>LLM: 高相关证据
LLM-->>User: 生成答案
Embedding 模型负责“快”,Reranker 模型负责“准”。Embedding 通常采用双编码器结构,可以预先把文档离线编码成向量,查询时只需要计算问题向量并做近邻搜索;Reranker 通常把问题和文档拼接起来一起输入模型,能看到两者之间更细的交互关系,但计算成本更高。
1.1 Embedding 模型:召回质量决定 RAG 的上限
Embedding 模型把文本映射到向量空间。理想情况下,语义相关的文本向量距离更近,语义无关的文本向量距离更远。
一个典型的向量检索过程如下:
flowchart LR
D[文档集合] --> Split[切分为文本块]
Split --> EncD[离线编码文档向量]
EncD --> VDB[(向量库)]
Q[用户问题] --> EncQ[在线编码查询向量]
EncQ --> Search[近邻搜索]
VDB --> Search
Search --> TopK[候选文本块TopK]
多阶段训练:从通用语义到任务适配
基于大语言模型训练 Embedding 时,单阶段训练往往不够。比较稳妥的做法是把训练拆成多个阶段,让模型逐步获得通用语义能力、检索判别能力和任务适配能力。

这条训练管线可以理解成两层递进:
| 阶段 | 训练目标 | 核心做法 | 解决的问题 |
|---|---|---|---|
| 弱监督对比学习 | 建立基础语义空间 | 使用大规模弱标注文本对,引入批内负样本和跨设备负样本 | 让模型先学会“相关”和“不相关”的基本边界 |
| 有监督对比学习 | 适配真实检索任务 | 引入高质量正负样本、难负样本和任务指令 | 让模型能处理具体业务场景里的细粒度匹配 |
对比学习的基本思想是:给定一个查询 q、一个正样本文档 d+ 和多个负样本文档 d-,训练目标是拉近 q 与 d+ 的向量距离,拉远 q 与所有 d- 的向量距离。
工程上,负样本数量非常关键。一个 batch 内的其他样本可以作为负样本,多张 GPU 上的 batch 也可以共享负样本。这样每个查询能够看到更多反例,模型的判别边界会更清楚。
数据构造:正样本容易造,难负样本更关键
Embedding 的训练数据通常从三元组开始:
(query, positive_document, negative_document)
构造流程可以拆成两步:
flowchart TD
A[原始文档] --> B[构造问题-正样本文本对]
B --> C[开源问答数据]
B --> D[大语言模型生成问题]
C --> E[问题-正样本集合]
D --> E
E --> F[大规模语料库检索]
F --> G[挖掘难负样本]
G --> H[过滤假负样本]
H --> I[训练三元组]
正样本可以来自已有问答数据,也可以由 LLM(Large Language Model,大语言模型)根据文档生成问题。难点在负样本:如果负样本太简单,模型很快就能区分,训练价值有限;如果负样本看起来像负例但实际是正例,就会把模型往错误方向带。
高质量难负样本通常具备两个特点:
- 表面相似:和问题共享关键词、实体或主题;
- 语义不匹配:真正回答不了问题,或者只回答了部分条件。
为了减少假负样本,可以引入 Reranker 给训练样本打分,再根据分数分布做清洗:
flowchart LR
A[候选训练样本] --> B[Reranker相关性评分]
B --> C{样本类型判断}
C -->|正例分数过低| D[剔除伪正例]
C -->|负例分数过低| E[过滤简单负例]
C -->|负例分数过高| F[识别潜在正例并替换]
C -->|质量合格| G[进入训练集]
D --> H[高质量训练集]
E --> H
F --> H
G --> H
Reranker 的评分还可以作为软标签,用于 Embedding 模型训练中的知识蒸馏。这样做不是只告诉模型“相关 / 不相关”,而是告诉模型“相关到什么程度”。
多任务训练:IR 和 STS 不能混成一锅粥
Embedding 常见任务可以分成两类:
- IR(Information Retrieval,信息检索):给定 query,从文档库中找相关文档;
- STS(Semantic Textual Similarity,语义文本相似度):判断两段文本语义相似程度。
两类任务的评价指标不同,训练方式也不应该完全相同。
| 任务 | 关注点 | 常见指标 | 训练重点 |
|---|---|---|---|
| IR | 相关文档是否排在前面 | nDCG、Recall@K、MRR | 强化正样本与 query 的相似度,压低难负样本 |
| STS | 相似度排序是否符合人工标注 | Spearman 相关系数 | 学习细粒度语义顺序,减少逆序对 |
nDCG(normalized Discounted Cumulative Gain,归一化折损累计增益)强调高排名位置的正确性。检索任务里,用户通常只看前几个结果,所以正样本排在第 1 位和第 20 位差别很大。
STS 的核心是顺序一致性。模型不只是要判断“像不像”,还要判断“A 比 B 更像,B 比 C 更像”这种相对关系。
多任务联合训练时,不能让不同领域、不同任务的数据在同一个 batch 里随意混合。跨设备负样本共享本来是为了增加负样本数量,但如果一个 GPU 上是法律数据,另一个 GPU 上是医疗数据,强行共享可能引入噪声。更合理的做法是:一次 iteration 内,多张 GPU 取自同一子数据集,同时允许不同任务配置不同 batch size、指令和损失函数。
flowchart TD
A[多领域训练数据] --> B[按任务和领域分桶]
B --> C1[IR数据桶]
B --> C2[STS数据桶]
B --> C3[业务领域数据桶]
C1 --> D[动态采样器]
C2 --> D
C3 --> D
D --> E[同一iteration内跨GPU同源数据]
E --> F[任务特定指令]
F --> G[任务特定损失]
G --> H[Embedding模型更新]
指令也很重要。同一段文本在不同任务里可能有不同匹配标准,例如“找定义”“找相似问法”“找能回答问题的文档”并不是完全相同的目标。给输入加上任务指令,可以让模型根据任务调整匹配策略。
模型融合:把不同训练轨迹合成一个更稳的模型
训练结束后,还可以选取多个 checkpoint 做权重融合。ModelSoups 一类方法的思路是:多个模型如果都来自同一底座、训练目标相近,那么它们的权重平均或加权平均可能落在一个更平滑、更稳定的区域。
这类策略不改变推理结构,也不会增加线上推理成本,适合在精调后作为最后一道模型选择和融合步骤。
1.2 Reranker:用更重的模型换更准的排序
Embedding 召回采用双编码器:
score(q, d) = similarity(Encoder(q), Encoder(d))
这种方式快,因为文档向量可以提前算好。但它的限制也很明显:query 和 document 分别编码,模型无法充分建模两段文本之间的 token 级交互。
Reranker 通常采用交叉编码方式:
score(q, d) = Model("[query] q [document] d")
模型一次看到问题和文档,因此能判断更细的关系,例如:
- 文档是否真的回答了问题;
- 是否只是关键词重合;
- 是否遗漏了时间、地点、实体、条件;
- 是否存在语义反转或范围不一致。
从 BERT 类 Reranker 到 LLM Reranker
传统 Reranker 常基于 BERT、RoBERTa 等模型,参数量多在 110M 到 400M 之间,输入长度通常受限于 512 token。面对长文档、复杂问题、多条件查询时,理解能力和上下文长度都会成为瓶颈。
LLM Reranker 的优势主要有三点:
| 能力 | BERT 类 Reranker | LLM Reranker |
|---|---|---|
| 输入长度 | 多数为 512 token | 可扩展到 8k 或更长 |
| 复杂语义理解 | 对长逻辑链支持有限 | 更适合复杂问题和长文档 |
| 任务适配 | 主要靠微调数据 | 可结合任务指令调整评分标准 |
代价也很明确:LLM Reranker 推理成本更高,延迟更大。所以线上常见做法是让 Embedding 先召回较小的候选集,例如 Top 50 或 Top 100,再交给 Reranker 精排。
分层知识蒸馏:让浅层也能输出可用分数
Reranker 训练通常会使用两类信号:
- 对比学习损失:让相关文档得分高,不相关文档得分低;
- 知识蒸馏损失:让学生模型学习教师模型给出的相关性分数。
分层知识蒸馏进一步把监督信号加到多个 Transformer 层上,而不是只约束最后一层输出。
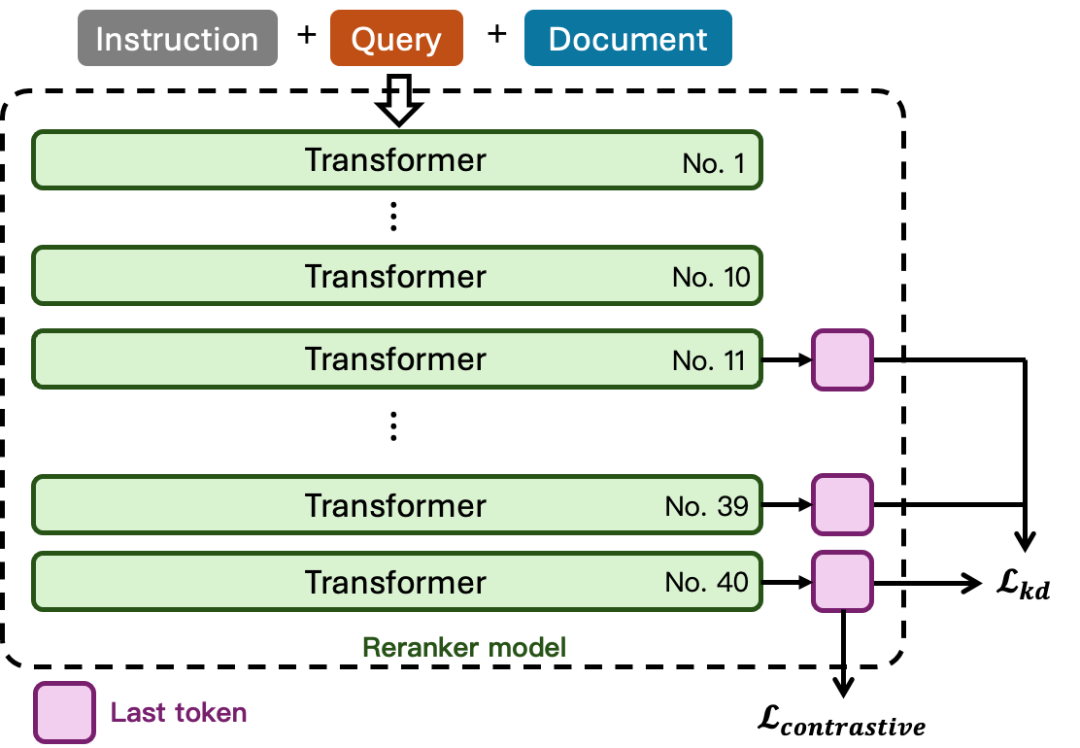
这张图展示的是 Layerwise 蒸馏思想:教师模型或最后一层输出给出目标分数,中间层也要学习输出接近目标的相关性判断。训练完成后,Reranker 不一定非要跑完整个模型才能出分,可以根据业务延迟要求选择较浅层或较深层输出。
这会带来一个实用能力:可调节精度与延迟。
| 使用层数 | 推理速度 | 排序质量 | 适合场景 |
|---|---|---|---|
| 浅层输出 | 快 | 略低 | 高并发、低延迟搜索 |
| 中层输出 | 平衡 | 中等偏高 | 常规 RAG 问答 |
| 深层输出 | 慢 | 更高 | 高价值问答、离线评测、低并发场景 |
业务训练数据:先实体粗筛,再 LLM 精评分
特定业务里,Reranker 往往缺高质量标注数据。手工标注成本高,而且很难覆盖长尾问题。一个可自动化的数据构造流程是:先用实体召回过滤明显无关文档,再用 LLM 对剩余文档精评分,最后自适应选择正负样本。
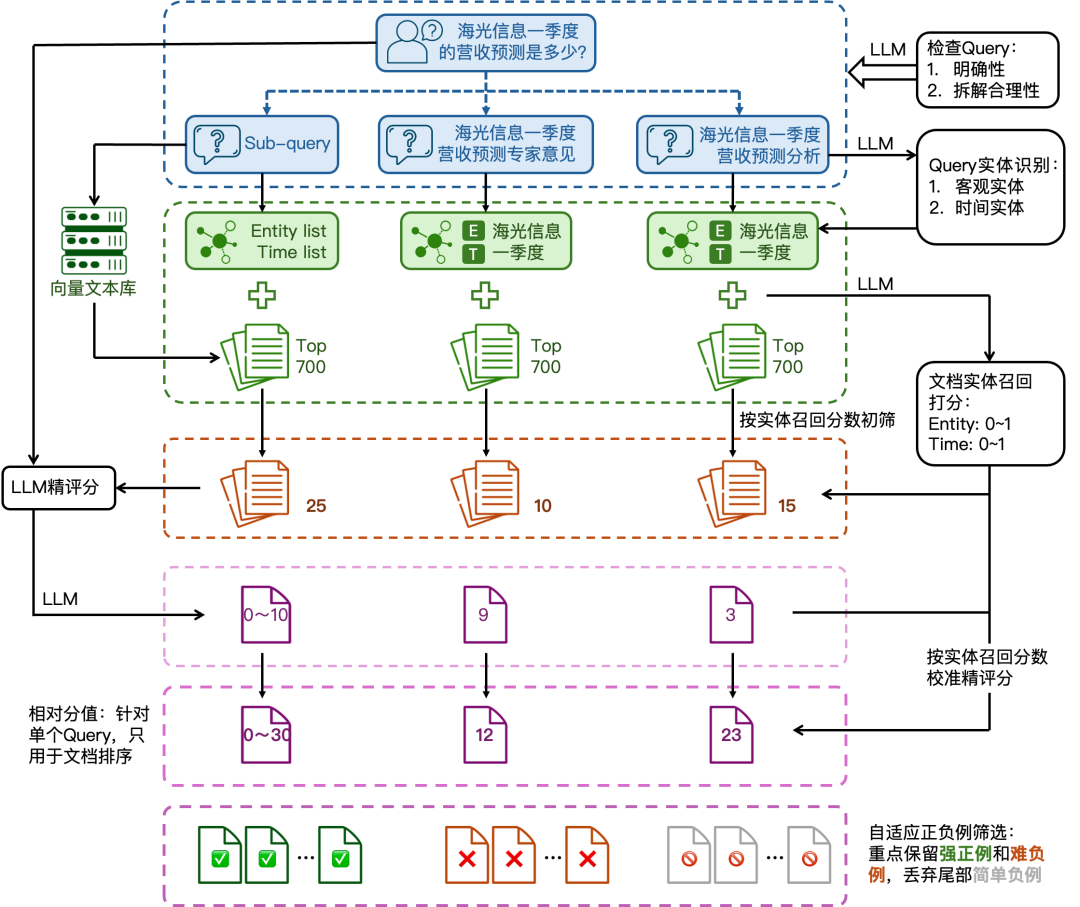
流程可以拆成七步:
flowchart TD
A[Query] --> B[可选:复杂问题拆解]
B --> C[向量召回候选文档]
A --> D[Query实体识别]
D --> E[客观实体 / 时间实体]
C --> F[文档实体召回打分]
E --> F
F --> G[过滤实体召回为0的简单负例]
G --> H[LLM相关性精评分]
H --> I[结合实体召回做分数校准]
I --> J[按分数分布自适应选正例]
J --> K[按比例补充难负例]
K --> L[Reranker训练数据]
这里有两个关键设计:
- 实体召回先行:如果问题里有明确实体或时间,而文档完全不包含这些信息,通常不需要进入昂贵的 LLM 精评分。
- 分数校准:LLM 打分可能受表达方式影响而产生误判,实体召回分数可以作为约束,纠正明显不合理的高分或低分。
正负样本选择也不能固定阈值一刀切。不同 query 的候选文档分数分布不同:有些问题只有少数高分文档,有些问题多个文档都能回答。按单个 query 的分数分布自适应选择正例,再按比例补充难负例,会比固定取 TopN 更稳。
2. 结构化信息检索:RAG 与 Text2SQL 融合
很多企业知识并不在文档里,而在数据库表、Excel、CSV 或后台系统中。对于这类数据,只做向量检索会遇到明显问题:
- “销售额最高的城市是哪一个?”需要排序和聚合;
- “2024 年 Q3 环比增长多少?”需要时间过滤和计算;
- “满足 A、B、C 三个条件的客户数量是多少?”需要精确筛选;
- “某个字段值是否存在?”需要查表,而不是找相似文本。
这时应该让 Text2SQL 参与进来。Text2SQL 的任务是把自然语言问题转换成 SQL,然后通过数据库执行获得精确结果。
2.1 多源数据:文本切片和 SQL 查询结果一起进入答案生成
结构化问答不应该完全替代文本检索。很多问题既需要精确数据,也需要解释性上下文。合理做法是同时保留两条证据链:
- 文本切片检索:提供背景、规则、说明和上下文;
- Text2SQL 查询:提供字段、统计、筛选、聚合等精确结果。
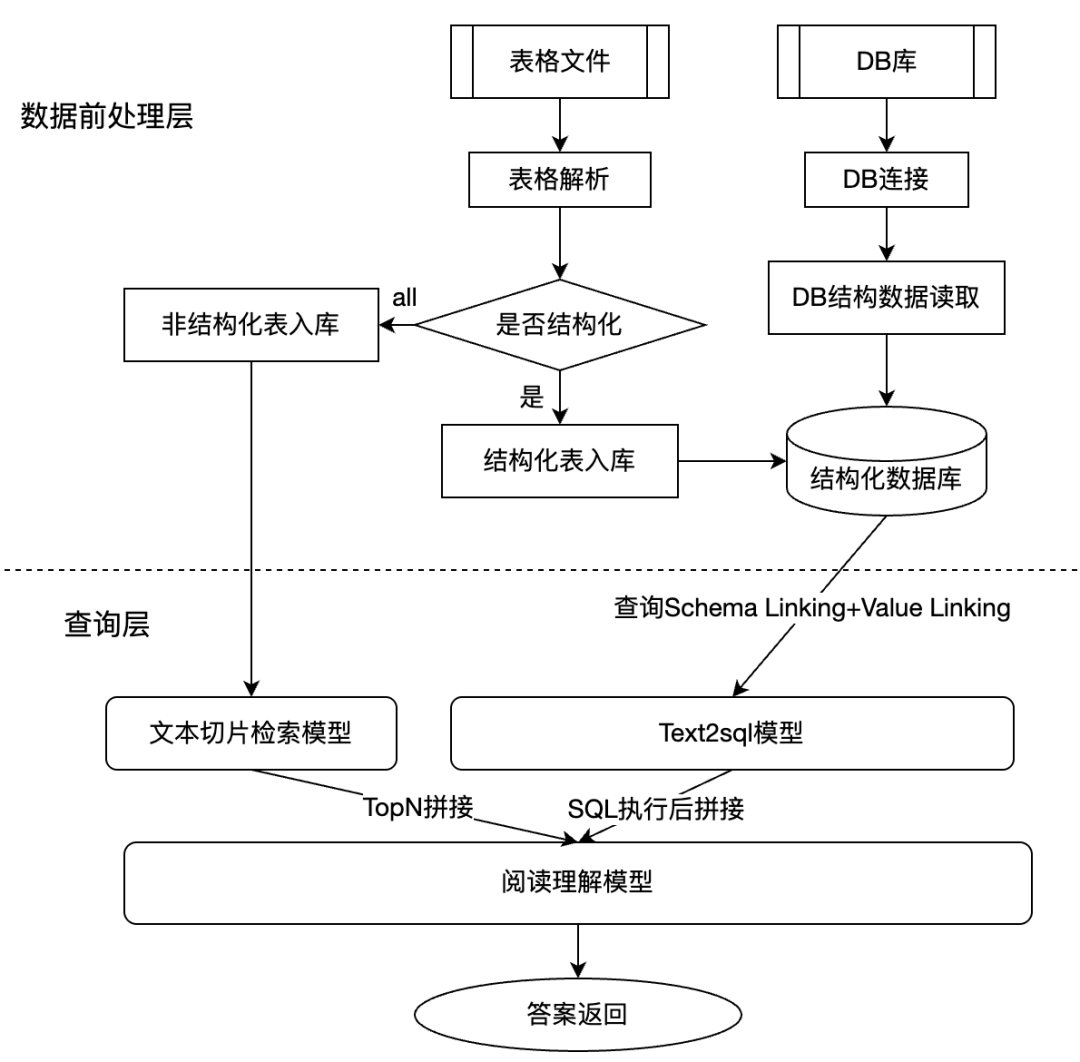
这张图表达的是多源数据接入方式:数据库表、表格文件和文本资料都进入统一问答系统。结构化数据走 SQL 查询,非结构化文本走切片检索,两类证据一起交给阅读理解模型做答案生成。
可以抽象成下面的流程:
flowchart LR
Q[用户问题] --> P[问题理解]
P --> T[文本检索]
T --> Chunks[相关文本切片]
P --> S[Text2SQL]
S --> SQL[SQL语句]
SQL --> DB[(DB / 表格引擎)]
DB --> Result[结构化查询结果]
Chunks --> Fuse[证据融合]
Result --> Fuse
Fuse --> Reader[阅读理解模型]
Reader --> Ans[自然语言答案]
2.2 Text2SQL 的数据合成:用自动化降低场景适配成本
Text2SQL 模型要学会三件事:
- 理解用户问题;
- 理解数据库 schema;
- 生成符合数据库方言的 SQL。
真实业务库千差万别,人工标注每个场景的训练数据成本很高。自动化数据合成可以批量生成:
数据库表结构 schema
自然语言问题 question
带推理过程的 SQL answer
数据库方言 dialect
例如,一个合成样本可能长这样:
{
"dialect": "mysql",
"schema": {
"tables": {
"sales_order": ["order_id", "city", "amount", "order_date"]
}
},
"question": "2024年销售额最高的城市是哪一个?",
"reasoning": "需要筛选2024年的订单,按城市分组,对amount求和,再按总额降序取第一名。",
"sql": "SELECT city, SUM(amount) AS total_amount FROM sales_order WHERE order_date >= '2024-01-01' AND order_date < '2025-01-01' GROUP BY city ORDER BY total_amount DESC LIMIT 1;"
}
带推理过程的 SQL 答案很有价值,因为模型不仅学习结果,还学习从问题到 SQL 的构造路径。面对新业务 schema 时,这种训练信号能帮助模型更快适配复杂查询逻辑。
2.3 Multi-Agent Text2SQL:Selector、Decomposer、Refiner 分工协作
单个 LLM 直接生成 SQL 在简单问题上可行,但复杂业务库会带来几个难题:
- 表很多,相关表和字段难以定位;
- 问题复杂,需要拆成多个子查询;
- 生成的 SQL 可能语法错、字段错、条件错;
- 执行结果为空时,不知道是数据为空还是 SQL 写错。
多智能体协作可以把 Text2SQL 拆成三个角色:
| Agent | 作用 | 输入 | 输出 |
|---|---|---|---|
| Selector | 选择相关表和字段 | 用户问题、数据库 schema | 候选表、候选列 |
| Decomposer | 拆解复杂问题 | 用户问题、候选 schema | 子问题、子 SQL 或推理步骤 |
| Refiner | 执行并修正 SQL | SQL、数据库反馈 | 修正后的 SQL |
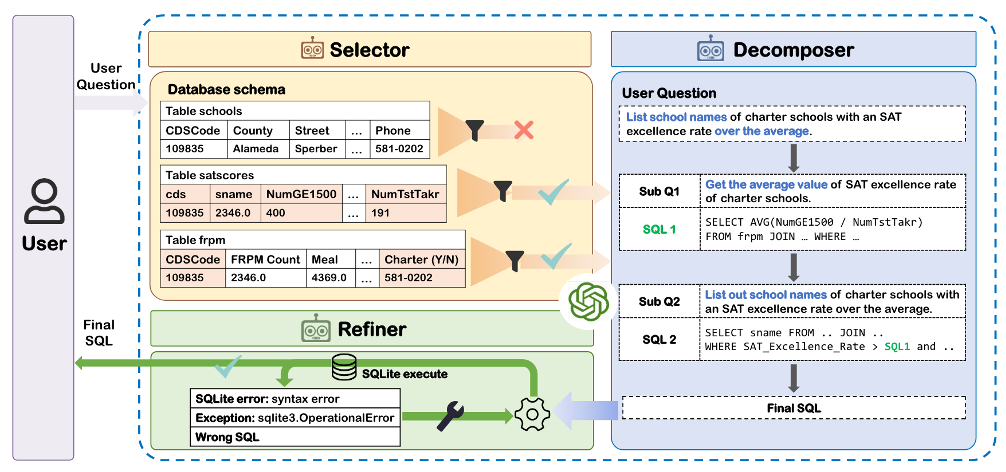
这张架构图的核心是“生成 SQL 前先缩小 schema,生成 SQL 后再用执行反馈修正”。Selector 可以减少无关表对模型的干扰,Decomposer 让复杂问题逐步求解,Refiner 则把数据库执行结果作为外部反馈,修正语法错误、字段错误或条件错误。
整体流程可以写成伪代码:
def text2sql_answer(question, database):
schema = database.load_schema()
# 1. 选择相关表和字段
selected_schema = selector(question, schema)
# 2. 拆解复杂问题
plan = decomposer(question, selected_schema)
# 3. 生成初始 SQL
sql = generate_sql(question, selected_schema, plan)
# 4. 执行并根据反馈修正
for _ in range(3):
result, error = database.execute(sql)
if error is None:
return sql, result
sql = refiner(question, selected_schema, sql, error)
raise RuntimeError("SQL generation failed after refinement")
3. 表格文件场景:先结构化解析,再查询
数据库表通常格式规范,但真实业务里经常遇到 Excel、PDF 表格、Word 表格截图等非标准数据。这类表格可能包含合并单元格、嵌套表头、多层标题、备注行、空白列。如果直接交给 Text2SQL,模型很难知道哪些是字段、哪些是值、哪些只是说明。
3.1 智能结构化解析:把非标准表格变成标准表
表格解析需要解决三个问题:
- 判断表格是否是可查询的知识表;
- 识别表头层级和字段含义;
- 把视觉或文件中的表格元素整理成标准二维表。
flowchart TD
A[原始表格文件] --> B{是否为结构化知识表}
B -->|否| C[转入文本切片或丢弃]
B -->|是| D[表头识别]
D --> E[单元格归并与层级展开]
E --> F[字段标准化]
F --> G[可被Text2SQL查询的结构化表]
非标准表格转标准表时,要尽量保留表头语义。例如多级表头:
| 地区 | 2024 年收入 | 2024 年成本 |
|---|---|---|
| 华东 | 1000 | 600 |
可以展开为:
| 地区 | 指标年份 | 收入 | 成本 |
|---|---|---|---|
| 华东 | 2024 | 1000 | 600 |
只有结构化之后,Text2SQL 才能稳定生成查询条件、聚合和排序。
3.2 语义窗口切分:表头和内容要一起保留
表格也可以做文本切片,但不能像普通文档一样按固定长度切。表格里的单元格值如果脱离表头,会失去语义。
错误切法:
华东 1000 600
华南 800 500
模型不知道 1000 是收入、销量还是人数。
更合理的切法是把表头属性和行内容组合起来:
地区=华东;年份=2024;收入=1000;成本=600
地区=华南;年份=2024;收入=800;成本=500
窗口大小可以按业务调整:
| 切分粒度 | 形式 | 适合问题 |
|---|---|---|
| 行级窗口 | 一行一段 | 查单条记录、条件筛选 |
| 多行窗口 | 多行合并 | 查相邻记录、范围解释 |
| 分组窗口 | 按类别或章节合并 | 查同一主题下的统计说明 |
3.3 双引擎查询:MySQL 管精确计算,ES 管模糊匹配
表格结构化之后,可以同时写入 MySQL 和 ES(Elasticsearch):
- MySQL 适合精确筛选、聚合、排序和数值计算;
- ES 适合全文检索、模糊匹配、同义词召回和字段值不完全匹配。
flowchart LR
Q[自然语言问题] --> SQL[Text2SQL生成SQL]
SQL --> AST[AST解析与校验]
AST --> M{查询类型}
M -->|精确过滤 / 聚合 / 排序| MySQL[(MySQL)]
M -->|模糊匹配 / 文本泛化| ES[(Elasticsearch)]
MySQL --> R[查询结果]
ES --> R
R --> LLM[答案生成]
AST(Abstract Syntax Tree,抽象语法树)在这里有两个作用:
- SQL 语法校验和自动修正:把 SQL 转成树结构,更容易定位字段、条件、函数和排序子句;
- 方言转换:把 SQL AST 转换为 ES DSL,实现同一语义在不同引擎上的执行。
例如用户问:
售卖模式为“一次性售卖与租赁模式”的产品有哪些?
如果数据库里实际存的是:
一次性售卖模式
租赁模式
MySQL 精确匹配可能查不到结果,而 ES 可以通过分词、同义词或模糊匹配召回相关记录。双引擎的价值就在于:既保留 SQL 的精确性,又补上业务表达不一致带来的召回缺口。
4. 通用 DB 场景:Schema Linking、Value Linking 与上下文改写
面对真实数据库,Text2SQL 的难点不只是生成 SQL,而是把用户语言和数据库结构对齐。
4.1 DDL 与 SimpleDDL:提示词长度和准确性的取舍
给模型输入 schema 时,常见两种格式:
| Schema 提示格式 | 包含信息 | 优点 | 代价 |
|---|---|---|---|
| DDL | 表名、字段名、字段类型、主键、外键、约束 | 信息完整,利于复杂 SQL | 输入长,推理慢,成本高 |
| SimpleDDL | 表名、字段名 | 简洁,速度快 | 缺少类型和关系信息,复杂查询容易错 |
DDL 示例:
CREATE TABLE student (
student_id INT PRIMARY KEY,
name VARCHAR(64),
age INT
);
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(128)
);
CREATE TABLE enrollment (
student_id INT,
course_id INT,
score DECIMAL(5,2),
FOREIGN KEY (student_id) REFERENCES student(student_id),
FOREIGN KEY (course_id) REFERENCES course(course_id)
);
SimpleDDL 示例:
student(student_id, name, age)
course(course_id, course_name)
enrollment(student_id, course_id, score)
如果库很大,直接把所有 DDL 塞进提示词会浪费上下文,也会增加模型混淆概率。更稳的做法是先用语义向量做 schema 召回,只把相关表和字段放进提示词。
4.2 Schema Linking:把问题里的概念映射到表和字段
Schema Linking 指的是把自然语言问题中的概念映射到数据库 schema 元素。
例如:
查询年龄大于20岁的学生姓名
需要建立映射:
学生 -> student 表
年龄 -> student.age 字段
姓名 -> student.name 字段
这个过程可以结合关键词、字段描述、向量相似度和业务词典完成。
flowchart LR
Q[用户问题] --> E[抽取概念]
E --> V[向量召回候选表字段]
V --> L[Schema Linking]
L --> P[生成SQL提示词]
4.3 Value Linking:把问题里的条件值映射到真实存储值
Value Linking 关注的是查询条件中的值。
例如:
查 CS 专业成绩超过 90 分的学生
数据库里可能存的是:
Computer Science
这时需要把:
CS -> Computer Science
再生成 SQL:
SELECT s.name
FROM student s
JOIN enrollment e ON s.student_id = e.student_id
JOIN major m ON s.major_id = m.major_id
WHERE m.major_name = 'Computer Science'
AND e.score > 90;
Value Linking 还需要处理日期表达:
| 用户表达 | SQL 条件 |
|---|---|
| 上个月 | date >= '2026-05-01' AND date < '2026-06-01' |
| 去年 | date >= '2025-01-01' AND date < '2026-01-01' |
| 最近 7 天 | date >= CURRENT_DATE - INTERVAL 7 DAY |
4.4 多轮上下文改写:把省略问题补完整
多轮问答里,用户经常省略前文条件:
用户:2024年华东区销售额是多少?
用户:那华南呢?
用户:再看一下利润率。
第三个问题里的“利润率”需要继承“2024 年”和“华南区”。如果不做上下文改写,Text2SQL 很可能生成不完整 SQL。
一种做法是构造编辑信号,把当前问题相对于历史问题的插入、替换关系编码进模型:
flowchart TD
A[历史问题] --> C[上下文表示]
B[当前问题] --> D[编辑矩阵: 插入 / 替换]
C --> E[问题改写信号]
D --> E
E --> F[与表格-文本链接矩阵融合]
F --> G[Self-Attention]
G --> H[上下文相关SQL]
改写后的问题会变成:
查询2024年华南区的利润率。
再进入 Text2SQL,生成结果会稳定得多。
5. 答案生成:结构化结果和文本证据要一起解释
Text2SQL 的输出通常是表格、数值或 SQL 执行结果,不一定适合直接展示给用户。例如:
{
"city": "上海",
"total_amount": 12345678.90
}
一个更好的回答应该说明数据含义、筛选条件和计算口径:
按订单日期筛选 2024 年数据,并按城市汇总销售额后,上海的销售额最高,为 12,345,678.90。
如果问题涉及趋势分析,答案还需要结合文本切片里的业务说明。例如:
- 数据库给出销售额、成本、利润率;
- 文本切片给出促销活动、区域政策、产品结构变化;
- 阅读理解模型综合两类证据,生成带数据支撑的解释。
flowchart LR
SQLR[SQL查询结果] --> F[证据融合]
TXT[文本切片证据] --> F
F --> R[阅读理解模型]
R --> A[可读答案]
这里要注意,答案生成模型不应该随意扩展结论。结构化结果负责事实边界,文本证据负责解释范围,两者都没有支持的信息不应出现在最终回答里。
6. GraphRAG:为复杂多跳问题组织知识
普通向量检索适合找“相似文本”,但复杂问题往往需要找“关系链”。
例如:
某位人物参与的事件中,哪些事件发生在其任职期间,并且与某个地区政策相关?
这类问题涉及人物、职位、时间、事件、地区、政策等多个实体和关系。如果只用 query 向量去匹配文本切片,可能召回到相关片段,但不一定能把关系链拼起来。
GraphRAG 的思路是把文本中的知识抽成图结构,再沿着实体和关系检索。
flowchart LR
Docs[原始文档] --> Extract[实体/关系/属性抽取]
Extract --> KG[(知识图谱)]
KG --> Community[社区摘要]
Q[复杂问题] --> QP[问题解析]
QP --> Retrieve[图检索]
KG --> Retrieve
Community --> Retrieve
Retrieve --> Reason[路径推理]
Reason --> Ans[答案生成]
6.1 GraphRAG 评测要看四个维度
只比较回答准确率不够。GraphRAG 还有构图成本、查询延迟和推理质量等问题。
| 维度 | 关注点 | 典型问题 |
|---|---|---|
| 构图成本 | 离线建图耗时和 token 消耗 | 是否需要大量 LLM 调用?大规模文档能否承受? |
| 检索效率 | 单次查询图检索耗时 | 查询是否能控制在秒级或十几秒内? |
| 回复准确率 | 最终答案是否正确 | 图检索是否找到足够证据? |
| 推理能力 | 是否给出正确理由 | 是否能完成多跳关系推导? |
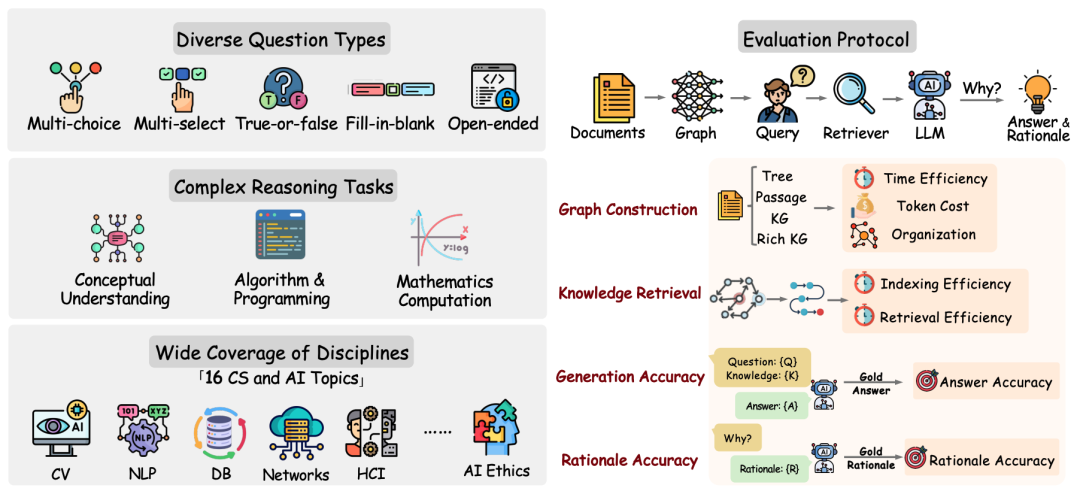
这张图展示的是 GraphRAG-Bench 的构建与评测思路:数据集需要覆盖领域知识和复杂推理问题,评估时不能只看最终答案,还要看构图成本、检索效率和推理过程。
6.2 从知识图谱和树结构,走向知识树
当前 GraphRAG 大致有两类路线:
| 路线 | 代表思路 | 优点 | 限制 |
|---|---|---|---|
| 知识图谱路线 | 抽取实体、关系、三元组 | 粒度细,适合关系推理 | 构图质量依赖抽取,图检索成本高 |
| 树结构路线 | 对文本切片层次化总结 | 摘要效率较高,适合全局概览 | 细粒度关系挖掘不足 |
知识树试图结合两者优势:保留图的细粒度关系,也保留树的层次化摘要。
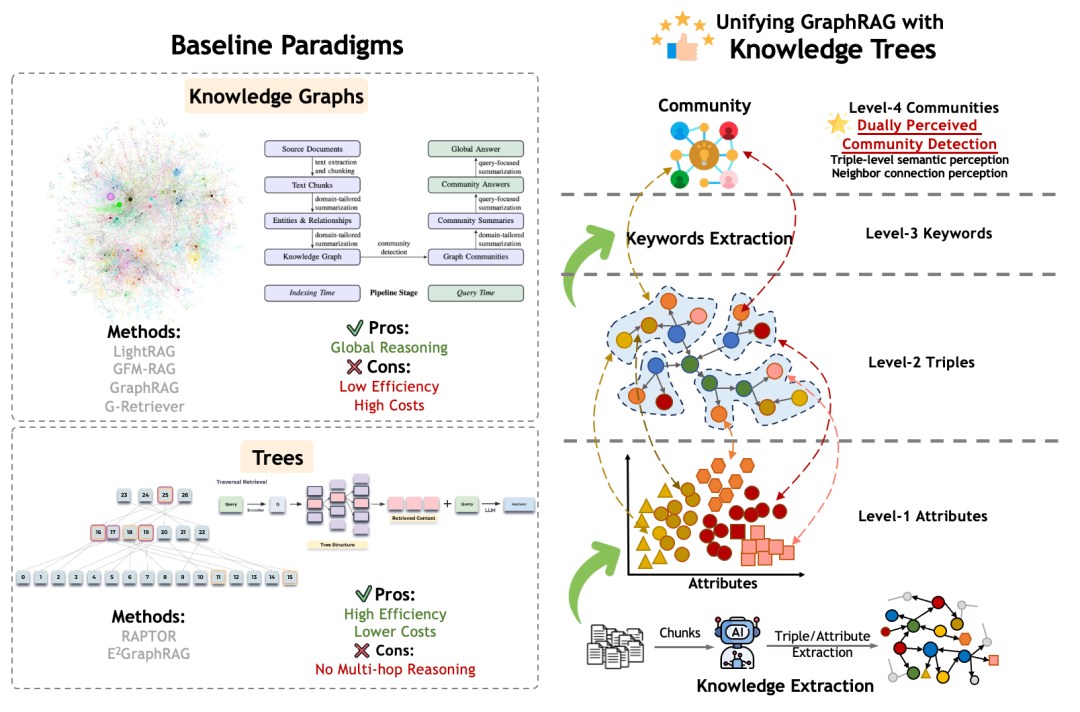
这张图的核心是异构知识组织。知识树不是只存实体节点,而是引入多层粒度:
- 属性节点:描述实体特征;
- 知识图三元组:表达实体之间的关系;
- 关键词节点:连接主题和语义单元;
- 社区节点:总结一组相关子图的核心信息。
可以把它抽象为:
flowchart TD
C[社区节点: 主题摘要]
K1[关键词节点]
K2[关键词节点]
T1[三元组: 实体A-关系-实体B]
T2[三元组: 实体B-关系-实体C]
P1[属性节点: 实体A属性]
P2[属性节点: 实体B属性]
C --> K1
C --> K2
K1 --> T1
K2 --> T2
T1 --> P1
T1 --> P2
T2 --> P2
这种结构的好处是:局部问题可以沿三元组和属性精确检索,全局问题可以先看社区摘要,再下钻到相关子图。
6.3 社区检测:同时看结构和语义
传统图社区检测算法往往依赖连接关系。如果图构建质量高,这种方法很有效;但如果实体关系抽取有缺失或噪声,单纯依赖拓扑结构就会把相关语义拆开,或者把无关节点合在一起。
更合理的社区检测应该同时考虑两类信号:
- 结构感知:节点和候选社区在邻居连接上的重合程度;
- 语义感知:节点文本特征和候选社区语义特征的相似度。
flowchart LR
A[锚节点] --> S1[结构相似度]
B[候选社区子图] --> S1
A --> S2[语义相似度]
B --> S2
S1 --> Score[综合社区归属分数]
S2 --> Score
Score --> C{是否并入社区}
结构相似度可以通过稀疏邻接矩阵计算 Jaccard 相似度,衡量锚节点邻居和社区邻居的重合度;语义相似度可以通过节点文本向量和社区子图向量计算,衡量它们是否表达相近主题。
这样做能减少两类问题:
- 关系边漏抽导致相关节点被拆散;
- 表面连接较多但语义无关的节点被强行归入同一社区。
6.4 图 Schema 自适应:让不同领域有不同抽取规则
不同领域的图谱 schema 不同。
人物领域可能关注:
人物、组织、职位、时间、事件
任职于、参与、发生于、隶属于
产品领域可能关注:
产品、型号、功能、参数、供应商
包含、依赖、适配、替代
事件领域可能关注:
事件、地点、参与方、时间、结果
发生于、导致、影响、关联
如果所有领域都用同一套实体类型和关系类型,抽取质量会受影响。更稳的做法是预置多类中英文领域 schema,并让模型在构图时根据数据内容补充和调整 schema。这样既减少人工配置,也能让图结构更贴合业务语义。
7. 复杂 Query 理解:用 Agentic GraphQ 做多跳拆解
复杂问题直接做向量匹配效果通常不好,因为一个长问题里可能包含多个实体、多个关系和多个约束。GraphRAG 如果只拿整个 query 去匹配节点或摘要,很容易漏掉关键条件。
Agentic GraphQ 的思路是:让问题理解过程感知图 schema,把复杂问题拆成多个单跳或低复杂度子任务。
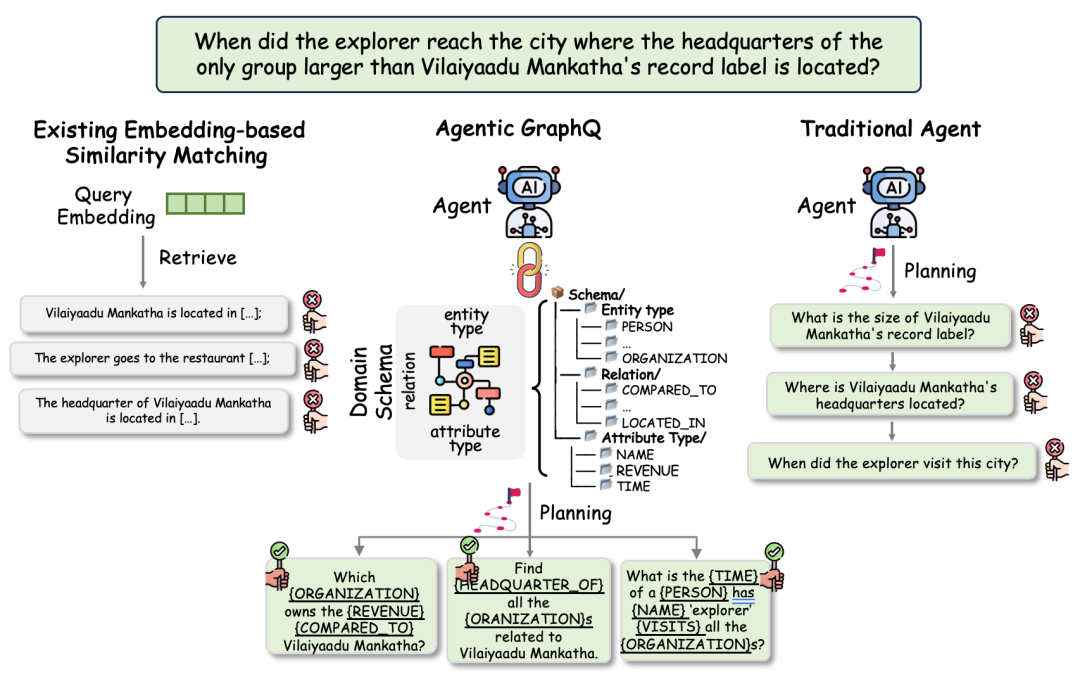
这张图表达的是 schema 感知的问题解耦过程。模型先识别 query 中的实体、关系和属性,再根据图谱 schema 推断它们之间的依赖关系,最后把多跳问题拆成可执行的子查询。
例如复杂问题:
找出参与A事件且后来加入B组织的人,并说明这些人与C政策之间的关系。
可以拆成:
子任务1:A事件有哪些参与者?
子任务2:这些参与者中哪些后来加入B组织?
子任务3:这些人与C政策之间有哪些关系路径?
子任务4:基于路径证据生成回答。
拆解后的检索可以走多路策略:
| 检索方式 | 作用 |
|---|---|
| 主题词或关键词检索 | 快速定位相关社区和候选节点 |
| Query-Triple 向量匹配 | 用“实体-关系-实体”结构匹配,避免只看单节点 |
| 路径 DFS 检索 | 沿图结构寻找多跳关系链 |
DFS(Depth-First Search,深度优先搜索)适合从锚点实体出发,沿关系边扩展路径。但扩展不能无限制,否则会引入大量噪声。常见约束包括:
def graph_retrieve(start_nodes, max_depth=3, max_paths=50):
paths = []
def dfs(node, path, depth):
if depth > max_depth or len(paths) >= max_paths:
return
for edge in graph.out_edges(node):
next_node = edge.target
if is_irrelevant(edge, next_node):
continue
new_path = path + [(edge, next_node)]
if is_answer_candidate(new_path):
paths.append(new_path)
dfs(next_node, new_path, depth + 1)
for node in start_nodes:
dfs(node, [], 0)
return rerank_paths(paths)
路径检索后还要做相关性剪枝和重排序,否则模型会被大量弱相关路径干扰。
8. GraphRAG 的成本和效果取舍
GraphRAG 的一个主要工程难点是成本。建图通常需要实体抽取、关系抽取、属性归纳、社区摘要等步骤,如果每一步都大量调用 LLM,成本会很快失控。
8.1 构图成本:token 消耗必须可控
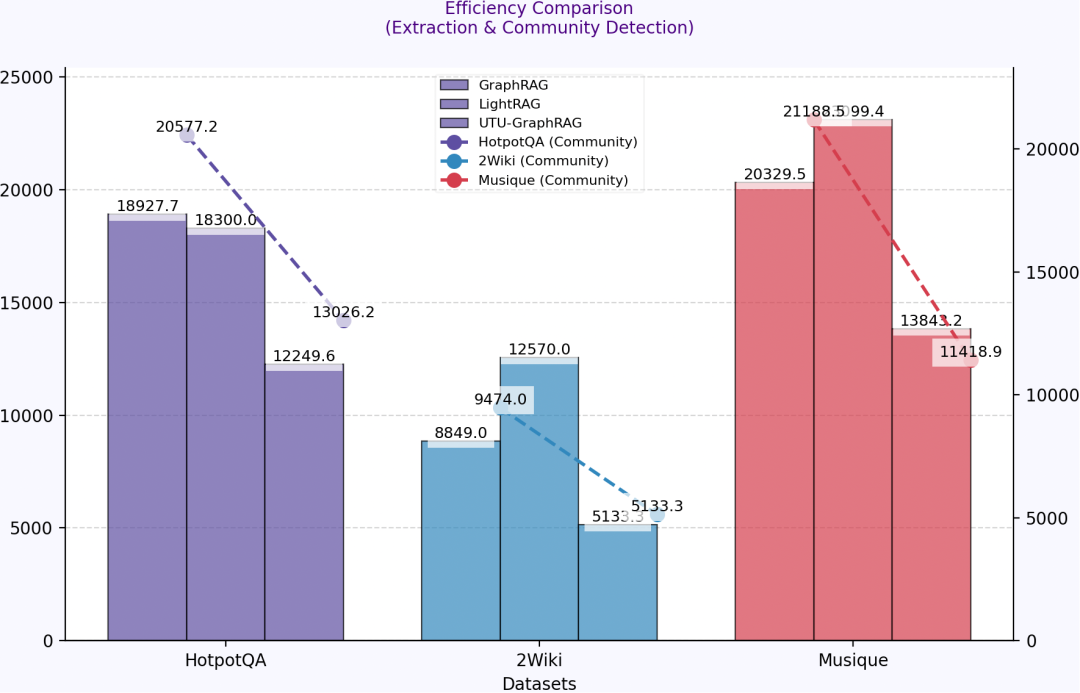
这张结果图对比了多个数据集上的构图效率。重点不是某个单点数值,而是方向:如果社区检测、schema 适配和知识组织方式更高效,GraphRAG 才能从实验走向生产环境。
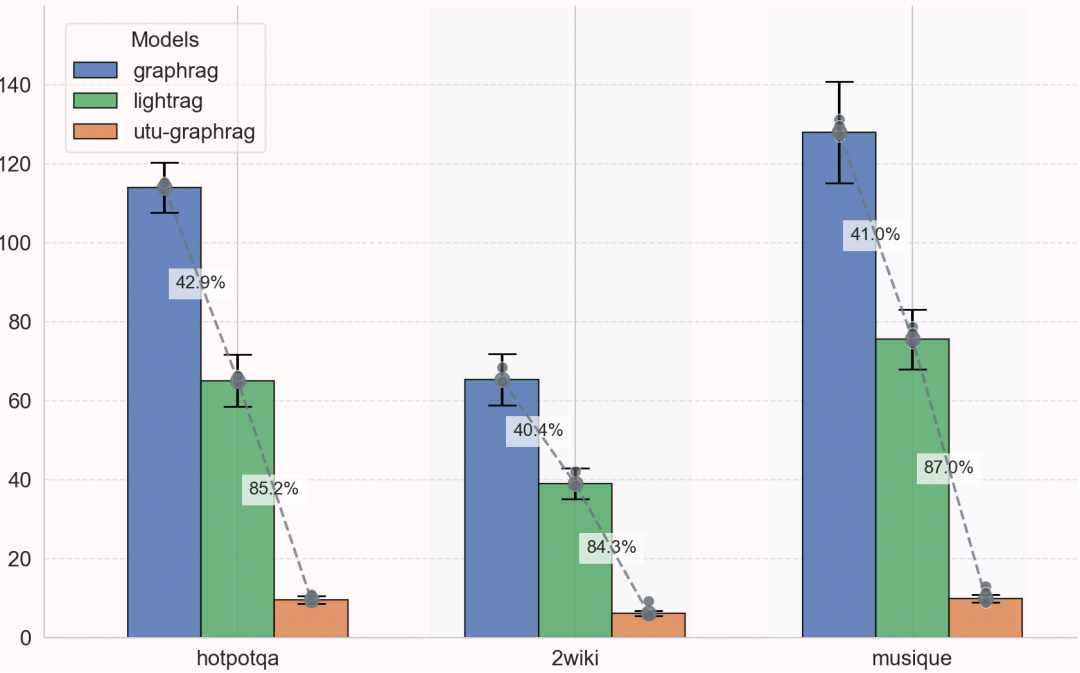
这张图展示的是构图阶段的大模型调用成本差异。GraphRAG 的落地门槛很大程度取决于离线构图 token 消耗,尤其是企业知识库需要周期性更新时,亿级 token 和百万级 token 的成本差距非常明显。
降低成本的常见手段包括:
- 使用轻量模型做初筛和候选抽取;
- 对相似文本块去重,减少重复建图;
- 增量更新图谱,而不是每次全量重建;
- 社区摘要按需更新,只重算受影响子图;
- 抽取结果缓存,避免同一文本重复调用 LLM。
8.2 检索效果:复杂推理数据集更能体现 GraphRAG 价值
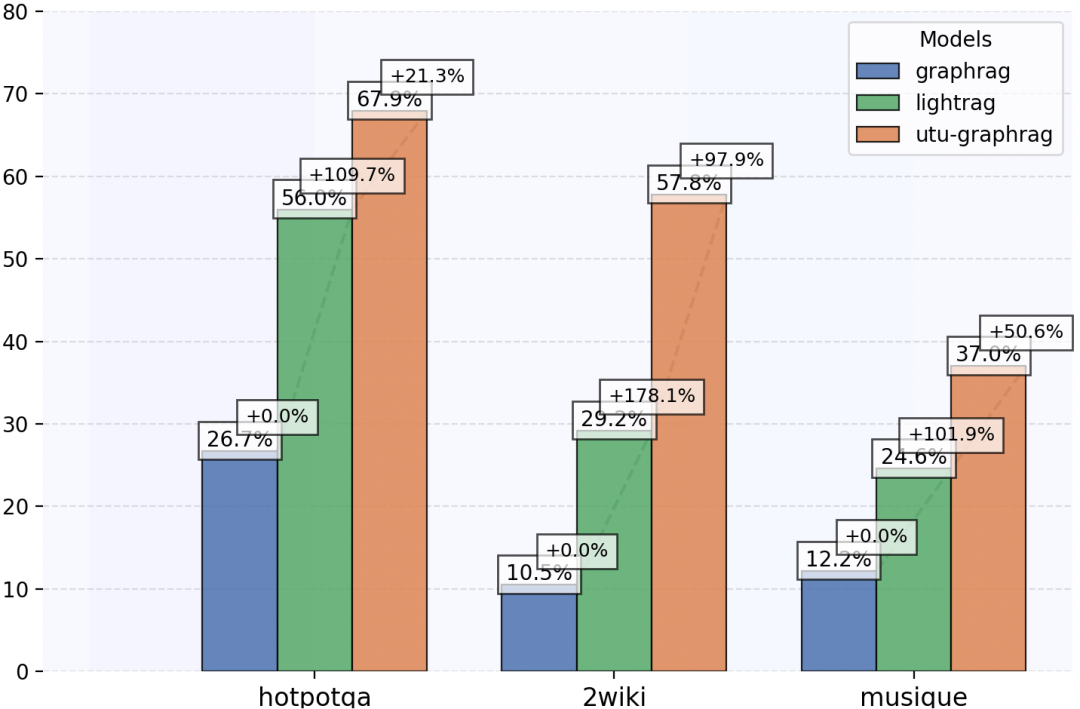
这张图对比的是复杂数据集上的回答准确率。GraphRAG 的优势通常不会在简单事实问答里完全体现,因为简单问题用普通向量检索就能解决;它真正有价值的场景是跨文档、多实体、多关系、多条件推理。
适合 GraphRAG 的问题通常长这样:
| 问题类型 | 示例 | 为什么需要图 |
|---|---|---|
| 多跳关系 | A 的上级组织参与过哪些 B 类事件? | 需要沿实体关系跳转 |
| 时间约束 | 某人在任职期间发生的相关事件有哪些? | 需要实体、职位、时间共同约束 |
| 路径解释 | X 和 Y 为什么有关联? | 需要给出关系链 |
| 领域推理 | 某政策影响了哪些产品线? | 需要跨文档聚合关系 |
不适合优先上 GraphRAG 的场景也很明确:
| 场景 | 更合适方案 |
|---|---|
| 简单 FAQ | 向量检索 + Reranker |
| 精确统计查询 | Text2SQL |
| 实时写入频繁、关系变化很快 | 轻量索引或增量图 |
| 数据规模小、关系不复杂 | 普通 RAG 足够 |
9. 一套可落地 RAG 系统的设计清单
把语义检索、结构化检索和图检索放到同一套系统里,需要明确每个模块的边界。
| 模块 | 核心目标 | 关键设计 | 常见风险 |
|---|---|---|---|
| 文档切分 | 保留语义完整性 | 按标题、段落、表格结构切分 | 切得太碎导致上下文丢失 |
| Embedding | 高召回 | 多阶段训练、难负样本、任务指令 | 只在榜单好,业务集不稳 |
| Reranker | 高精排 | LLM Reranker、分层蒸馏、业务数据精调 | 延迟过高 |
| Text2SQL | 精确查询 | Schema Linking、Value Linking、SQL Refine | 误查敏感数据、SQL 幻觉 |
| 表格解析 | 非标准表转结构表 | 表头识别、合并单元格展开 | 字段语义丢失 |
| GraphRAG | 多跳推理 | 知识树、社区检测、路径检索 | 建图成本高、图噪声大 |
| 答案生成 | 证据到自然语言 | 结构化结果 + 文本证据融合 | 模型扩展无依据结论 |
线上系统还需要加几层保护:
flowchart TD
Q[用户问题] --> Safe[权限与安全检查]
Safe --> Route[问题路由]
Route -->|文本问答| RAG[语义RAG]
Route -->|表格/统计| SQL[Text2SQL]
Route -->|复杂关系| Graph[GraphRAG]
RAG --> Evidence[证据池]
SQL --> Evidence
Graph --> Evidence
Evidence --> Verify[证据校验]
Verify --> Generate[答案生成]
Generate --> Guard[输出审查]
Guard --> A[返回答案]
特别是 Text2SQL,一定要控制权限和执行范围。比较稳的策略包括:
- 只允许只读查询;
- 禁止
DROP、DELETE、UPDATE等写操作; - 给 SQL 执行设置超时和行数限制;
- 对敏感字段做脱敏或拒答;
- 记录生成 SQL、执行结果和证据来源,方便追踪问题。
10. RAG 正在从线性流程走向闭环系统
传统 RAG 是一条线:
检索 -> 生成
生产环境里的 RAG 更像一个闭环:
规划 -> 检索 -> 验证 -> 反思 -> 再检索 -> 推理 -> 生成
Agentic RAG 的价值就在这里。对于复杂问题,系统需要先规划子任务,再调用向量检索、SQL 查询、图检索、计算工具等不同能力;拿到结果后,还要验证证据是否足够,不够就继续补检索。
可以把未来形态抽象成:
flowchart LR
Q[问题] --> Plan[任务规划]
Plan --> Tool[工具选择]
Tool --> Retrieve[检索/查询/图推理]
Retrieve --> Check[证据验证]
Check -->|不足| Plan
Check -->|足够| Reason[推理]
Reason --> Ans[生成答案]
RAG 的难点不再只是“召回多少文本”,而是系统能否根据问题类型选择正确的数据源、正确的检索方式和正确的推理路径。Embedding、Reranker、Text2SQL 和 GraphRAG 分别解决不同层面的知识获取问题,把它们组合起来,才更接近可用、可控、可解释的企业级智能问答系统。